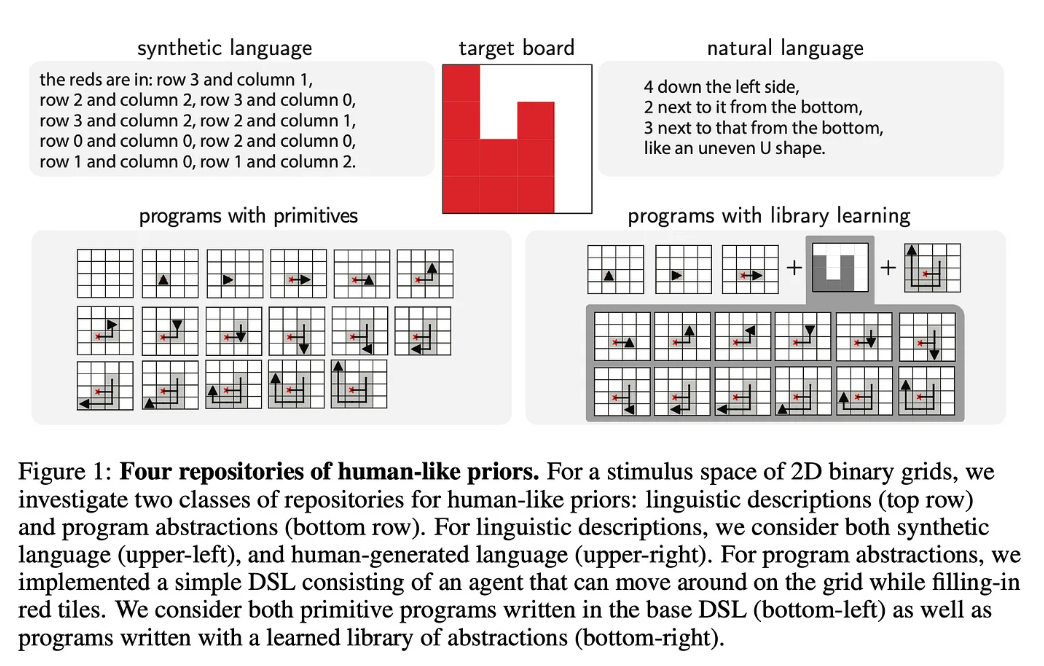
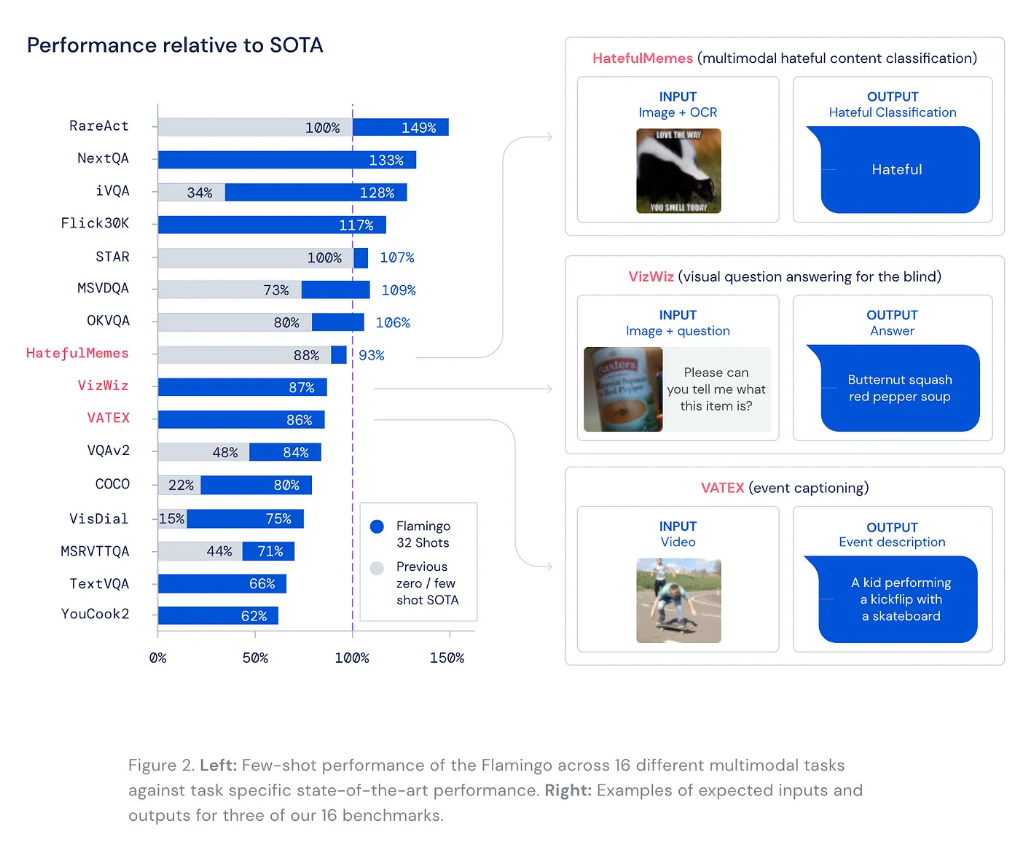
随着DALL·E 2 于 2022 年 4 月的宣布,关于2022 年初第三个 AI 冬天——或 AI 撞墙——的预言过时得很快而且效果不佳,随后出现了更多主要由扩散模型驱动的文本到图像应用程序,这是一个非常多产的领域用于计算机视觉研究及其他领域。AI 的 2022 年定义为强劲的上升趋势。
此外,大型语言模型被证明是一个更加肥沃的领域,有几篇论文显着扩展了它们的能力:检索增强、思维链提示、数学推理、推理自举。语言模型研究远未结束。它仍然在发展!
今年年的重磅炸弹无疑是OpenAI 的 ChatGPT,它再次重新定义了对 LLM 的期望,并巩固了 OpenAI 作为 LLM 即服务的全球领导者的地位。正如我们将看到的,到 2023 年,这可能会对整个技术领域产生连锁反应,因为与 OpenAI 建立了牢固合作伙伴关系的微软可能会利用它来改进他们的主流产品,包括 Bing 和 Office。
现在让我们来看看 AI 的几个关键领域:它们目前所处的位置以及我们预计它们在 2023 年的发展方向。
社区
长期以来,Twitter 一直是 AI 研究人员公开分享和讨论其工作的最大在线空间。但埃隆·马斯克臭名昭著的收购该公司已将其置于摇摇欲坠的境地。日益增长的不稳定因素、不可预测的政策变化以及马斯克的分裂政治立场导致人们强烈要求转移到Mastodon等其他地方。目前,大部分行动仍在 bluebird 网站上进行,出于政治原因一夜之间全面撤离的可能性仍然不大,但我们不能完全排除明年公司出现某种形式崩溃的可能性。
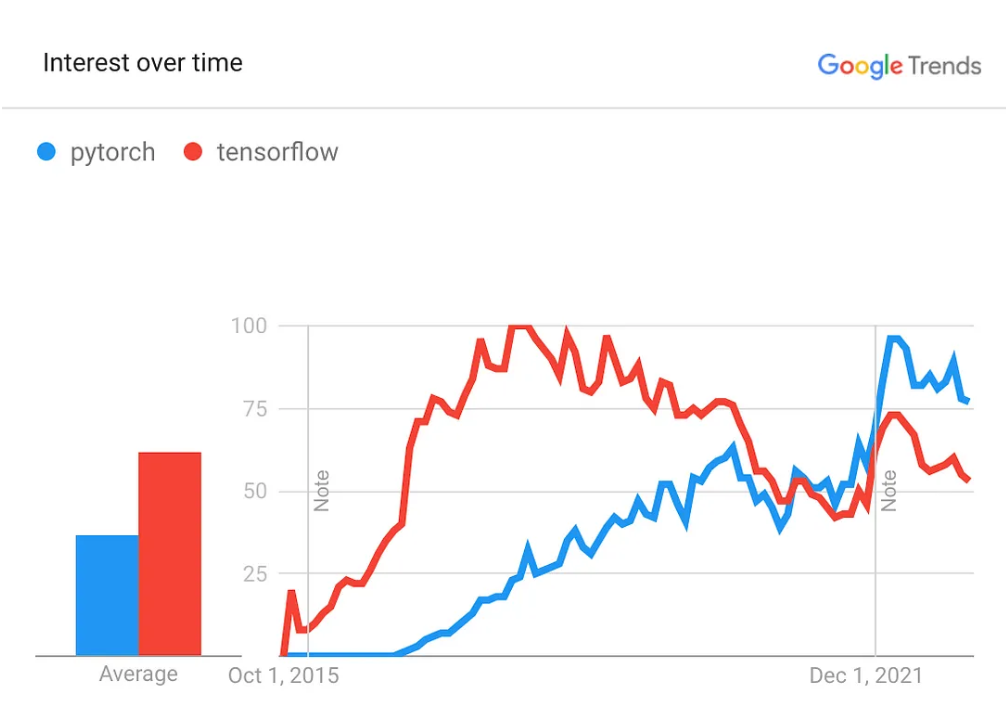
深度学习社区的另一个战场是框架。PyTorch 的采用率已经超过 TensorFlow 几年了,它是 Autograd 和神经网络最受喜爱和使用的框架。2023 年,PyTorch v2.0 将发布,其主要功能是编译器和加速。甚至谷歌也没有押注 TensorFlow 的卷土重来,而 JAX/FLAX 生态系统——已经是谷歌大脑和许多其他研究人员的最爱——仍然不够成熟,无法成为主流。
最后,行业和学术界的鸿沟继续扩大,因为 (1) 大型科技公司拥有更多可用的计算资源,以及 (2) 当前的许多轰动一时的研究都依赖于数十名世界级工程师的密切合作,而这些工程师是无法获得的普通博士生。这意味着学术研究正在转向更好地检查、理解和扩展现有模型,以及设计新的基准和理论进步。
语言模型
如果一年前 LLM 已经是 AI 领域的主角,那么现在的情况更接近于独白。萨顿的惨痛教训像美酒一样陈年。有了 ChatGPT,LLM 成为了主流——甚至我的非 AI 非技术朋友都在问这个问题——我们预计 2023 年将是这项技术真正普及的一年。微软——已经在考虑将其在 OpenAI 中的股份扩大到 49% ——而谷歌不想错过,所以这将是一场巨头的冲突。
- 规模。在过去的几年里,模型在参数方面几乎没有增长——这与许多公开的 AI 讨论相反!现有最好的可用密集 LLM 仍处于 200B 参数范围内,因为它们未得到优化,并且在该范围内仍有许多有待发现和改进的地方。然而,我们预计今年情况会有所改变,(1) 谷歌公开使用他们的 FLAN 模型系列,以及 (2) 如果克服所有优化挑战,OpenAI 和竞争者将通过备受期待的 GPT-4 进入万亿级参数计数. 由于成本原因,这些可能不会为大部分 LLM 即服务提供支持,但将成为下一个成为头条新闻的旗舰技术。
- 优化。静态文本数据训练的时代已经结束。当前的 LLM不仅仅是大型语言模型,它们的优化包括策划的、交互式的和连续的数据/文本以及代码等形式语言。我们期望在 LLM 优化方面取得进展,利用更复杂的 RL 环境(例如 L LM 作为代理),LLM 在正式环境循环中训练以学习更好的符号操作(例如Minerva v2),LLM 生成更多和越来越好的数据来训练他们自己,以及在适度硬件上廉价运行的模型上提炼更多性能的方法,导致每个 FLOP 在 LLM 即服务的经济学中都很重要。
- 语言模型的进步将继续渗透到其他人工智能领域,如计算机视觉、信息检索和强化学习(正如 2022 年已经发生的那样)。
- 代码+大型语言模型。GitHub Copilot 已经推出一年多了,它正在慢慢改变人们编写代码的方式。谷歌在 2022 年初分享了其 3% 的代码已经由 LLM 编写,我们预计代码完成 LLM 会变得更好,慢慢改变人们编写代码的方式。

强化学习和机器人
可以说,RL 在去年从基本面来看并没有取得实质性进展。相反,进步是由越来越复杂的代理的应用构成的,这些代理结合了计算机视觉、文本、语言模型、数据管理……例如CICERO、视频预训练 (VPT)、MineDojo或GATO。很大程度上受成功扩大模仿学习或离线 RL 的推动,只需少量使用古老的在线 RL 代理-环境-奖励循环。我们期望开发更多的多模态复杂代理,这些代理可以在不完整的信息下采取行动,利用基于大型神经网络和大型预训练数据的模块化组件。
到 2023 年,我们预计 LLM 和 RL 之间的共生关系将进一步发展:在 RL 环境中训练 LLM,并将 LLM 用作 RL 代理的一部分(例如,作为政策的规划者,强先验)。
最后,Zero-few shot 和极高的效率将是机器人在现实世界中互动的关键,我们期待 ML 模块化(只需插入预训练模块的能力)、few-shot 能力和因果表示的趋势学习在 2023 年在这方面提供帮助。但是,如果在传统 RL 在计算机上解决极端样本效率之前在该领域取得重大突破,我们会感到惊讶。
计算机视觉
扩散模型和文本到图像是 2022 CV 的明星。我们对通过生成图像可以实现什么的看法与我们一年前的想法大不相同。然而,图像理解远未解决。让我们更接近的关键是什么?
- 因果表征学习(通常与以对象为中心的表示学习相关)是一个不断增长的兴趣领域,它研究元素之间因果关系的学习,超出了它们的统计相关性。阻碍进步的一个关键因素是缺乏强大的标准化基准测试,我们预计 2023 年将带来 CV 基准文化的转变,将重点转移到域外泛化、稳健性和效率上,而不是域内图像分类、跟踪、分割……
- 更多的多模式模型将文本、音频和动作与视觉相结合,就像我们在Video Pretraining Transformer MineDojo中看到的那样。
- 扩散模型接管了生成文本到图像的人工智能,并被用于其他应用,如分子对接和药物设计。生成视频和 3D 场景是并将成为这些应用程序的下一个自然步骤,但我们预计连贯的长视频生成需要更长的时间。对高频数据(标记/图像)建模比收集大规模低频数据(例如新颖的叙事结构)更难。没有足够的静态数据来通过蛮力解决这个问题,因此需要更好的大型模型优化技术。
##信息检索

最后,是我们心中的话题。在过去几年中,神经 IR 的最大问题是将学术基准的成功——BM25 经常被打败——转化为现实世界的设置和广泛采用。发生这种情况的关键:
- 不需要人工相关注释。这已经是 IR 在 2022 年取得最大进展的方面之一,提出了InPars(使用 LM 生成注释)、LaPraDor(无监督对比学习)等建议。
- 方便。当前的模型可能在基准测试中表现良好,但它们不仅仅有效。我们期望在神经 IR 模型的整个开发生命周期中提高便利性,从而提高采用率。
对话式人工智能。检索增强语言模型和 ChatGPT 等强大的模型最近重新引起了人们对该领域的兴趣,因为许多人现在看到了真正的可行性。虽然标准化评估仍然具有挑战性,但我们预计人们对该领域的兴趣会增加。
除了研究之外,2023 年可能是消费者网络搜索领域发生颠覆的一年,并且只是人们对搜索引擎的期望发生了范式转变。微软与 OpenAI 的合作以及最近 ChatGPT 的巨大成功让许多人猜测 Bing 有可能发生 180° 转变,采用由有效语言模型提供支持的真正复杂的网络规模问答。 谷歌现在看到其主要业务受到挑战,今年可能是谷歌需要加强其游戏的混乱之年。
总结
最后,强调一些与研究相关性较低但仍然是人工智能在未来 内如何发展的关键的问题:
在硬件方面,Nvidia 在 AI 芯片上的垄断地位仍未动摇,只有奇迹才能在短期内改变这一局面。关于 HuggingFace 被谷歌收购并与他们的 GCP 和 TPU 紧密集成以进行托管的传言可能会增加 TPU 硬件的使用,但这听起来仍然不太可能。
欧洲人工智能法案——迄今为止最雄心勃勃、最全面的监管工作——继续取得进展,目前的估计表明它最早可能在 2023 年底生效。我们希望其他大型经济体能够注意到并效仿它发生在 GDPR 中,以确保在 AI 使用方面保护个人权利。
当前的大型技术放缓将如何影响人工智能研究——尤其是在短期行业融资方面。虽然我们希望我们在过去 12 个月中看到的强劲进展将转化为该领域的整体乐观情绪,但不能排除放缓的可能性。

![[oeasy]python0070_ 字体样式_下划线_中划线_闪动效果_反相_取消效果](https://img-blog.csdnimg.cn/img_convert/7aac12e5545e9317af986e8824d4341c.png)


![[Linux系列]linux bond详解](https://img-blog.csdnimg.cn/6a81679e694242dd81c1970eb0e7dfe9.png)