一、摘要
实际场景中各种遮挡增加了表情识别难度。为此,提出一种滑块局部加权卷积注意力和全局注意力 池化的视觉 Transformer
结合的方法来解决遮挡问题。
利用主干网络提取表情特征图,将表情特征图裁剪成 多个区域块,利用局部 Patch 注意力单元通过自适应计算局部特征的注意力权重来感知被遮挡的区域,提取 表情局部特征。同时,表情特征图转换成 Patch
块,通过
Patch
级和
Token
级注意力池化的视觉
Transformer
, 从全局角度捕获 Patch 块之间的相互作用和相关性。引导模型强调最具区别性的特征,而忽略遮挡减少不相关特征的影响。
主要贡献总结如下
:
(1) LPAPViT模型为了解决局部遮挡表情识别问题,利用局部块注意力特征和全局抗干扰自主意力来关注局部特征和全局相关性,增强面部特征的可分辨性。
(2) 局部注意力模块的设计是学习表情最相关的局部特征,通过估计它们对 FER
的重要性来调整权重,能够抵御被遮挡特征的干扰。
(3) 改进后的视觉
Transformer
用于捕获最具判别力的面部不同 Patch
块之间的全局相互作用和相关性。视觉 Transformer
中的注意力模块计算出注意力图,引导注意力池化模块选择相应的 Patch
块。选定的
Patch块展平,送入 M
个堆叠的
Token
注意力池化增强的Transformer 编码器中,并附加一个额外的可学习的类向量。引导全局特征模块将注意力转移到具有显著面部特征的未遮挡区域,而忽略遮挡。
二、网络架构
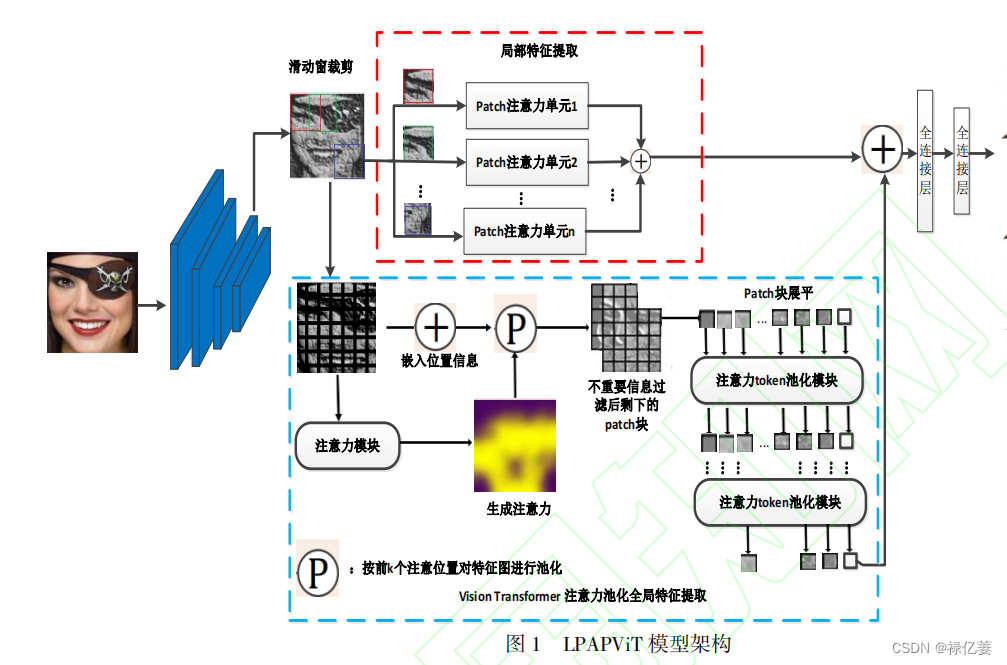
它由主干 CNN、用于局部特征提取的 LPU 模块和用于全局特征学习的 APViT 模块组成。采用预训练的前三个阶段 IR-50 作为主干提取人脸特征图。然后从特征映射中提取局部和全局特征,而不是从原始表情图像中提取。为了学习不同的局部特征,采用滑动窗口将人脸特征映射裁剪成多个小块,LPU 模块从裁剪后的小块中学习局部人脸表征。Patch 级注意力机制使 LPU 模块能够感知被遮挡的 Patch 块,并通过估计 Patch 块对面部表情识别的重要性来权衡局部特征。在全局抗干扰部分,人脸特征图嵌入位置编码再和求和绝对值注意力进行前 k 个 Patch 块选择,选定的 Patch 块展平加类别向量被联合传递 Transformer 编码器模块。它由多头自主意力和多层感知机模块的交替层组成,在全局范围内探索不同 Patch 块之间的关系。在 Transformer 模块中加入 TAP 模块,逐步减少特征图向量的数量,迫使模型注意具有判别能力的特征图向量,消除背景和遮挡的噪声向量,类别向量的最终输出作为全局特征。将局部特征与全局特征相结合进行表情预测。在损失函数的监督下更新模型的权值,并使用 Softmax 进行分类。
PAP 模块通过定位有信息的区域,删除无信息的区域来提升识别性能。
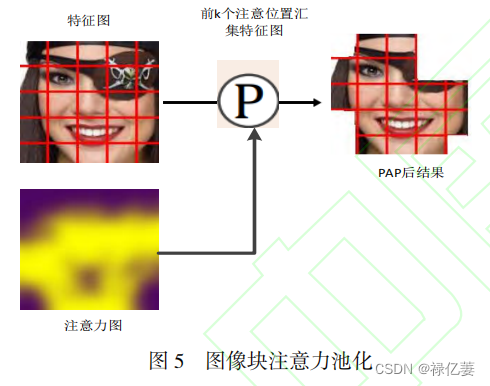
ViT-small 模型中嵌入特征图意力池化模块
PAP
找到前 k
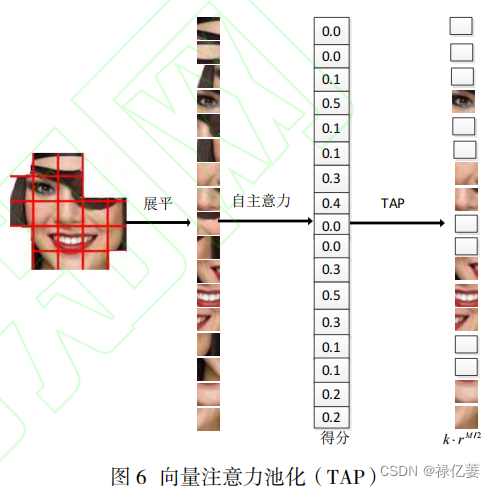
个相对特征较多的特征图块,把这些特征图块展平,加上类别向量,加上位置编码,送入 Transformer编码器,Transformer
编码器的多头自主意力机制中嵌入向量注意力池化模块 TAP
进一步查找相对特征丰富的特征块转换向量,最后得到过滤掉与表情无关或干扰的向量,得到最具表情的全局特征。PAP
模块通过注意力机制对无信息和噪声 Patch
进行了高效的池化,利用 TAP 增强的
Transformer
编码器在全局范围内探索所选特征图块之间的关系。