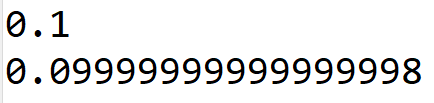文章目录
- 介绍
- 基于传统视觉方法的检测
- 基于颜色和边缘信息
- 基于背景抑制
- 基于深度学习的检测
- 特征金字塔网络(FPN)红绿灯检测
- 特征金字塔
- 自下而上
- 自上而下
- 横向连接
- 特征融合SSD红绿灯检测
- 高精度地图结合
介绍
红绿灯检测就是获取红绿灯在图像中的坐标以及它的类别。按照交通法规定:如果检测到红灯,则需要在路口等待;若检测到绿灯,则可以通过路口;如果检测到黄灯,黄灯亮时已经越过停止线的车辆可以继续通过,还未越过停止线的车辆应停车。因此,能否准确检测到红绿灯状态决定着无人驾驶汽车的安全。之前对于红绿灯的检测,大多利用颜色形状等低级特征去做,例如在颜色上使用一个阈值进行背景抑制;或者根据颜色特征进行候选框的提取,再对候选框进行分类。这类方法的准确率无法满足要求,因此迫切需要新的技术方案来解决此问题。
现在常用的目标检测的方法都是基于Faster CNN、YOLO和SSD,这些方法在提取小目标上不理想。红绿灯这类目标在图片中所占的像素较少,对于标准的卷积神经网络(VGG、ResNet、DenseNet等)来说,输出的特征一般只有图片大小的1/32。由于红绿灯像素少,细节信息丢失严重,这就增加了小目标的检测难度。如果删除特征提取网络的层数或者采样层,会导致感受野缩小,衰弱特征的语义信息,反而更影响检测效果。另外,Faster CNN和SSD这种基于候选窗口的检测算法来说,为了达到检测小目标的目的,需要增加候选窗口的数量,这会拖慢检测速度,并且增加了前背景框的分类难度。
提升小目标检测效果的最有效方法是扩大图像大小,随之而来的问题就是计算量增加,感受野的不足影响大目标的检测效果。目前针对小目标检测算法的改进,主要从提取特征网络入手,让提取的特征更加适合小目标的检测,大致有几种方法:
- 图像金字塔:较早提出对训练图片上采样出多尺度的图像金字塔。通过上采样能够加强小目标的细粒度特征,理论上可以优化小目标的定位和识别效果。但是基于图像金字塔训练卷积神经网络模型对计算能力和内存有着严苛的要求,目前的发展情况来讲,实际使用较少。
- 逐层预测:对于卷积升级网络的每层特征图输出进行一次预测,最后综合考量得出结果。这种方法会利用浅层特征去做预测,而浅层特征没有充分的语义信息,也没有较大的感受野,所以效果对于前面的特征层来说,并不会因为特征图的变大而变好。该方法对硬件的依赖也是很高的。
- 特征金字塔:参考多尺度特征图的特征信息,同时兼顾了较强的语义特征和位置特征。较大的特征图负责较小的目标检测,较小的特征图负责较大的目标检测。
- 空洞卷积:利用空洞卷积代替传统的卷积,在提升感受野和不增加额外参数的同时,不减少特征图的大小,保留了更多的信息。
- RNN思想:参考了RNN算法中的门限机制、长短期记忆等,同时记忆多层次的特征信息,但是RNN固有的缺陷是训练速度较慢。
基于传统视觉方法的检测
基于颜色和边缘信息
在传统的视觉任务里,通常使用HSV或者RGB颜色空间,但是在红绿灯检测中,往往是颜色和边缘信息更加有效。该方法的步骤如下:
该方法李庸简单的颜色和边缘信息取得了明显的效果。虽然该方法在速度上具有优势,但是健壮性不足,在一些场景下容易出现误检测。
基于背景抑制
基于背景抑制的方法是通过处理图像浅层特征来区分前景和背景,从而实现背景抑制和红绿灯候选区的获取。好的二阶段检测算法要能够提取高质量的候选框,只要候选框选取够准,则红绿灯的召回率高。该算法主要包含两部分:候选区域提取模块和识别模块。在候选区域提取模块中,该方法使用自适应背景抑制去突出前景而获取候选区。在识别模块中,每个候选区域的特征输入到识别网络中,获取候选框的类别——红灯、绿灯以及背景区。与基于颜色和边缘信息的方法相比,该方法是自适应的方法。这就决定了该方法可以适应多种场景,并且在检出率上的表现较为优秀。
基于深度学习的检测
特征金字塔网络(FPN)红绿灯检测
特征金字塔
多数的目标检测算法仅仅根据最终的特征图输出做预测,而低层的特征语义信息比较少但目标位置准确;高层的特征语义信息丰富但目标位置粗略。识别不同尺寸的目标一直是目标检测的难点,尤其是小目标。 以VGG16为例,假如stride=16,表示若原图大小是1000×600,经过卷积层后的特征图大小为60×40,可理解为特征图上一个像素点映射原图中一个16×16的图像区域;那原图中有一个小于16×16大小的物体则会检测不到。特征图金字塔网络FPN(Feature Pyramid Networks)是2017年提出的一种网络,它主要解决的是物体检测中的多尺度问题,在基本不增加原有模型计算量的情况下,通过简单的网络连接改变,大幅度提升了小物体的检测性能。

利用卷积神经网络在图片金字塔上进行特征提取,可以构建出特征金字塔。上图中左侧为图像金字塔(将图像resize成不同的大小),右侧为在图像金字塔上进行特征提取得到的特征金字塔。在得到特征金字塔后,下一步就是在特征金字塔上进行目标识别。这样的处理方式运算量巨大。

上图即为仅采用网络最后一层的特征,如Faster R-CNN一系列模型网络,包括最开头VGG16的举例。

利用低层特征和高层特征,分别在不同的层同时进行预测。像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。
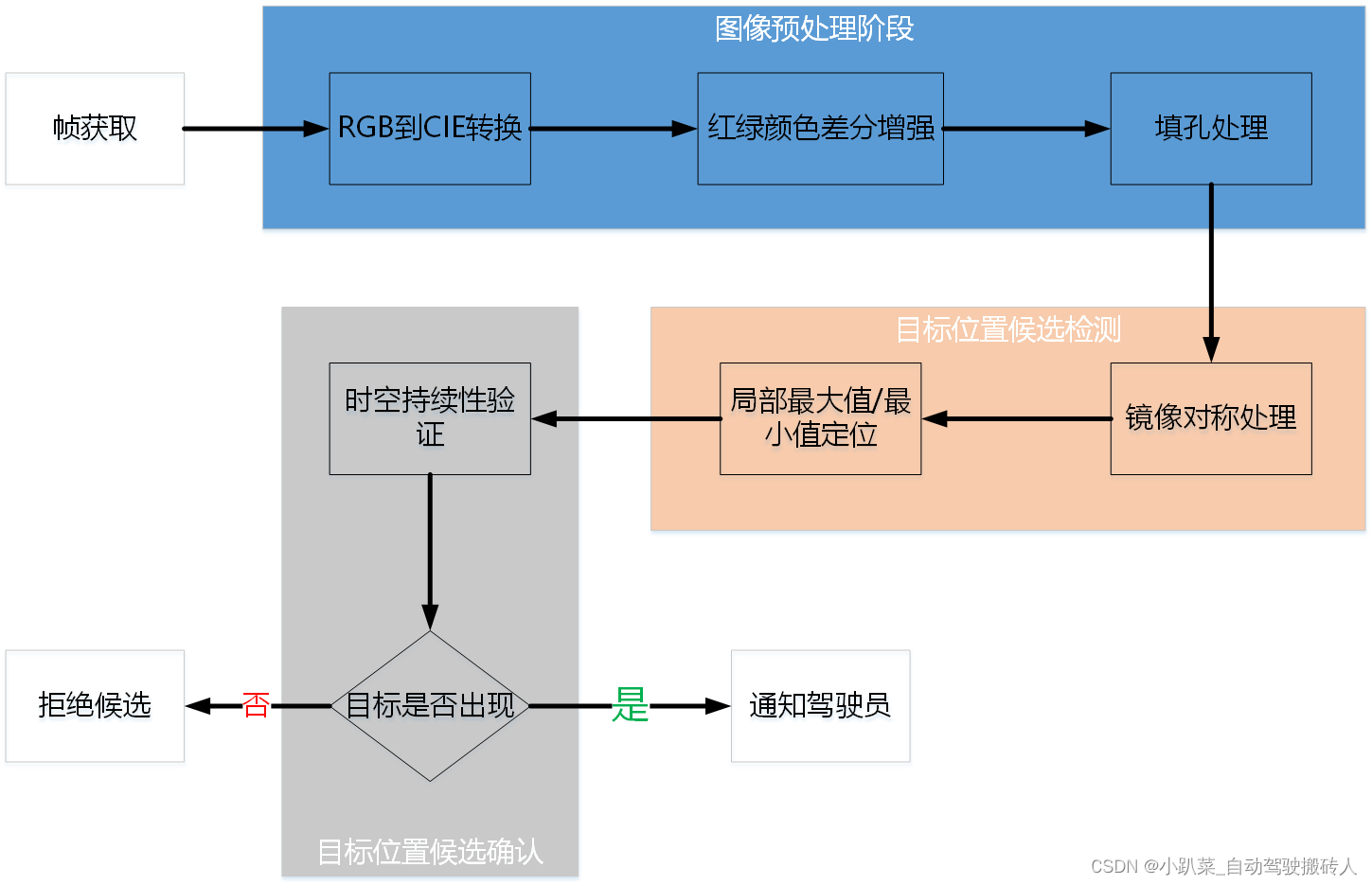
FPN网络做法很简单,把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。网络大致结构如下:一个自下向上的线路、一个自上向下的线路、横向连接(lateral connection,图中放大的区域是横向链接)
自下而上
自底向上的过程就是神经网络普通的前向传播过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变。将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自上而下
高层特征图进行上采样,然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,从而扩大原图像的大小。通过对特征图进行上采样,使得上采样后的特征图具有和下一层的特征图相同的大小,这样做主要是为了利用底层的位置细节信息。
横向连接
横向连接:前一层的特征图经过 1×1的卷积核卷积,目的为改变通道数,因为要和后一层上采样的特征图通道数相同。
连接方式:像素间的加法。重复迭代该过程,直至生成最精细的特征图。得到精细的特征图之后,用 3×3的卷积核再去卷积已经融合的特征图,目的是消除上采样的混叠效应,以生成最后需要的特征图。
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。
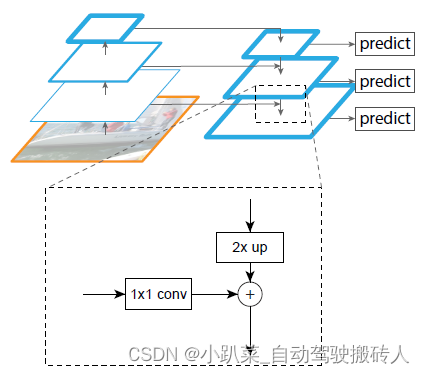
特征融合SSD红绿灯检测
上文提到的FPN是在二阶段算法基础上实现的,特征融合SSD则是在一阶段检测算法DDS基础上对小目标检测做的一些改进。该方式使用多尺度特征融合将上下文信息引入到SSD中帮助检测红绿灯。上下文信息对于检测小目标来说非常重要,红绿灯目标和背景之间的尺寸信息差异大,如果使用较小的感受野去关注物体本身的特征,则很难提取到背景中包含的全局语义信息;如果使用较大的感受野去关注背景信息,则小目标本身的特征会被丢失。因此,使用多尺度特征融合可以有效解决这一问题,浅层网络得到精细特征,高层网络通过大的感受野得到上下文信息,两者相结合,从而改善小目标检测,也不会降低大目标的检测效果。
SSD是基于VGG6的基础网络,仅是替换掉VGG16中的某些层以及增加一些网络层。SSD不使用最后一个特征映射去做预测,而是使用卷积层中的多层中的金字塔特征层次结构来预测具有不同规模的目标。使用浅层来预测较小的对象,使用深层来预测较大的对象,这样可以减少整个模型的预测负担。然而,浅层往往缺少语义信息,这事较小对象检测的重要补充,因此,将深层的语义信息传递回浅层可以提高小目标的检测性能,同时也不会引入太多的计算量。
通过将浅层和深层的特征融合,可以为小目标检测提供丰富的上下文信息。在实际的检测中,深层特征往往由于太大的感受野通常会引入大的无用背景噪声,浅层特征则因为网络不够深、没有充足的语义信息,所以该方法利用浅层和深层融合之后的特征对小目标进行预测。同时为了不降低速度,对于较大的红绿灯目标,可以不使用特征融合模块,而是直接使用较深的高层特征。在小的红绿灯检测上为了选择合适的特征融合层,利用反卷积针对不同尺寸的目标生成不同尺寸的特征。特征融合SSD是一阶段的方法,在SSD的基础上进行了针对小目标检测的优化,使卷积特征更适合在无人驾驶中的红绿灯检测,与二阶段算法相比,在满足实时性的同时也具备了不错的准确率。
高精度地图结合
上述算法只是通过图像获取红绿灯在图像中的位置,而获取红绿灯世界坐标则需要结合高精地图。高精地图是指高精度、精细化定义的地图,其精度需要达到分米级才能够区分各个车道。精细化定义则是需要格式化存储交通场景中的各种交通要素,包括传统地图的道路网数据、车道网络数据、车道线和交通标志数据。在利用计算机视觉进行红绿灯检测时,必须在整幅图像中搜索。因为计算机无法预测红绿灯出现在图像中的位置,如果接收了高精度地图信息,机器就可以通过高精度地图定位和高精度地图得到ROI(Region of Interest)。根据定位和地图的数据,控制器可以知道前方、两侧是否有交通标志牌以及红绿灯的位置,这样就可以大幅度降低算法的复杂度,减少系统的计算负荷,进而提升系统性能。高精地图与红绿灯检测的具体结合模式如下:
1. 使用检测算法,确定红绿灯在图像中的位置以及它的类别
2. 将红绿灯与高精地图上记录的红绿灯进行比对
3. 得到红绿灯的世界坐标,确定红绿灯所对应的道路,从而辅助系统做出决策。
当车辆因为遮挡或者算法的原因导致无法检测到红绿灯时,高精地图可以告知系统红绿灯的信息,从而提高行车的安全性。














![Langchain[6]-LangGraph:异步和流、图可视化、多智能体协作、LCEL代码生成](https://img-blog.csdnimg.cn/img_convert/bd924d1398459fd10b233c9156a2f7d3.png)