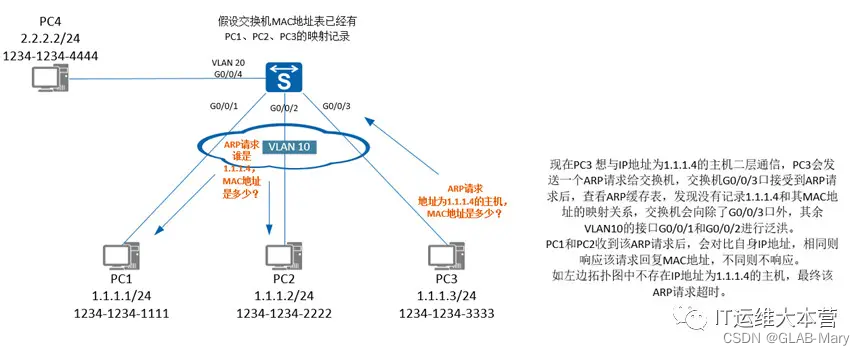
在今年 tesla 的 AI Day 给我这个业余自动驾驶爱好者给留下了深刻印象,在看过之后,通过收集资料对其中阐述的技术进行简单的了解,在这里拿出来跟大家分享一下,有点长,所以划分了一下 3 个部分。
从 BEV 到占用网络
激进无保护安全左转
有着一双手的擎天柱
先说一下我们能够从 AI Day 学到什么?
有了想写 ANet 的冲动
每一次在特斯拉的 AI Day 上,特斯拉的自动驾驶团队给出他们关于自动驾驶的解决方案,总会成为业界的风向标,随后也是大家研究的方向。那么这些方案到底有多新奇呢?其实这些解决方案所采用的技术,可以说是情理之中,意料之外,为什么这么说呢?
我们就拿去年的 AI Day 上,特斯拉关于自动驾驶的解决方案来说吧。大家都知道,想要实现自动驾驶,车辆至少要对其所在环境有一个清晰的,准确的了解。这就是少不了需要对周围环境进行 3D 重建。大多数公司借助于激光雷达来构建 3D 环境,或者直接使用高精度地图。
好,我们回过头来,看看卡帕西当时给出的解决方案是什么,就是我们熟悉 regNet、BiFPN、transformer 等这些技术,绕过传统的图像拼接技术,用 8 个摄像头采集的图像构建出了一个对周围环境映射的向量空间来实现对周围环境 3D 重建。
如果这时,大家认为这不就是一些熟知的技术堆叠吗?那你又想多了,即使现在知道了答案,也很难复现他们的效果,这也就是特斯拉厉害之处。所以对于一些技术,一定是将其原理吃透,才能将他们运用的得心应手。我想这是特斯拉技术团队成功的一点原因吧,也是我们缺乏的,需要提升的,也就是对于关键技术需要深入理解,不能仅停留在表面上。
在如何将各种技术整合和落地上,这点真的要佩服特斯拉,说特斯拉是最好的基于视觉自动驾驶公司,并非言过其词,好了这期就说到这里。
从 BEV 到占用网络
无论去年的 BEV 也好,还是今年的 occupancy network 占用网络,都是弥补特斯拉因没有安装激光雷达无法准确地还原其行驶周围 3D 场景的不足。有了激光雷达就可以比容易地,较准确地重建 3D 空间。上一集已经说环境 3D 重建对于自动驾驶的重要性。

除了激光雷达以外,还有就是通过高精度地图,自动驾驶来了解其所处环境。不过高精度地图维护成本比较高,需要频繁更新,而且即便有了高精度地图,也需要对周围动态目标进行感知。所以特斯拉更推崇实时建图方式来帮助车辆熟知周围的环境。那么今天我们来看一看特斯拉是如何做到的呢?

大家可能还记得去年的亮点,如何对 8 个摄像头采集图像进行有效融合。也就是跨过传统图像缝合技术,直接通过将所有摄像头采集图像通过矫正后,一并输入到神经网络来提取特征,然后利用基于自注意力机制的 transformer 将这些特征进行关联从而投影到一个向量空间,最终拿到一张反应周围环境的鸟瞰图。
不过这里要说一句,虽然鸟瞰图可以很好还原周围环境,提供自动驾驶所需的信息,但是毕竟还是一个 2D 图像,类似一张平面的地图。既然是 2D 的图像那么相比 3D 空间就少了一个维度,也就是说明一定会缺失一些空间高度上信息,无法真实地反应物体在 3D 空间实际占用的体积是多少。
所以 BEV 中,特斯拉更关心的是那些静止物体,例如路沿、车道线和栅栏等。所以在介绍占用网络之前,特斯拉技术团队先抛出一些现在 BEV 层面上很难解决的问题。例如一些空间目标,例如空中悬挂的交通标识牌、周围物体的一些 3D 结构,和因为遮挡而无法识别,而这些被遮挡运动物体会对随后规范有影响等等。
针对这些问题,在接下来介绍中我们将一一找到答案。在解释特斯拉如何使用占用网络前,我们简单介绍一下什么是占用网络,不会特别深入,只是为了大家更好理解接下来的内容。
占用网络
占用网络是并不什么新的随着深度神经网络的到来,基于学习的三维重建方法逐渐变得流行。不过到现在为止关于如何表示 3维空间还没有达成一致,不想我们用一个 3 维矩阵就可以很好表示图像,虽然这种方式表达 2D 图像,缺少了很多语义信息。但是这种方式已经被大家认可,并且已经证实其有效性。
但是和图像不同的是,在3D中没有规范的表示,既能高效地进行计算,又能有效地存储,同时还能表示任意拓扑的高分辨率几何图形。
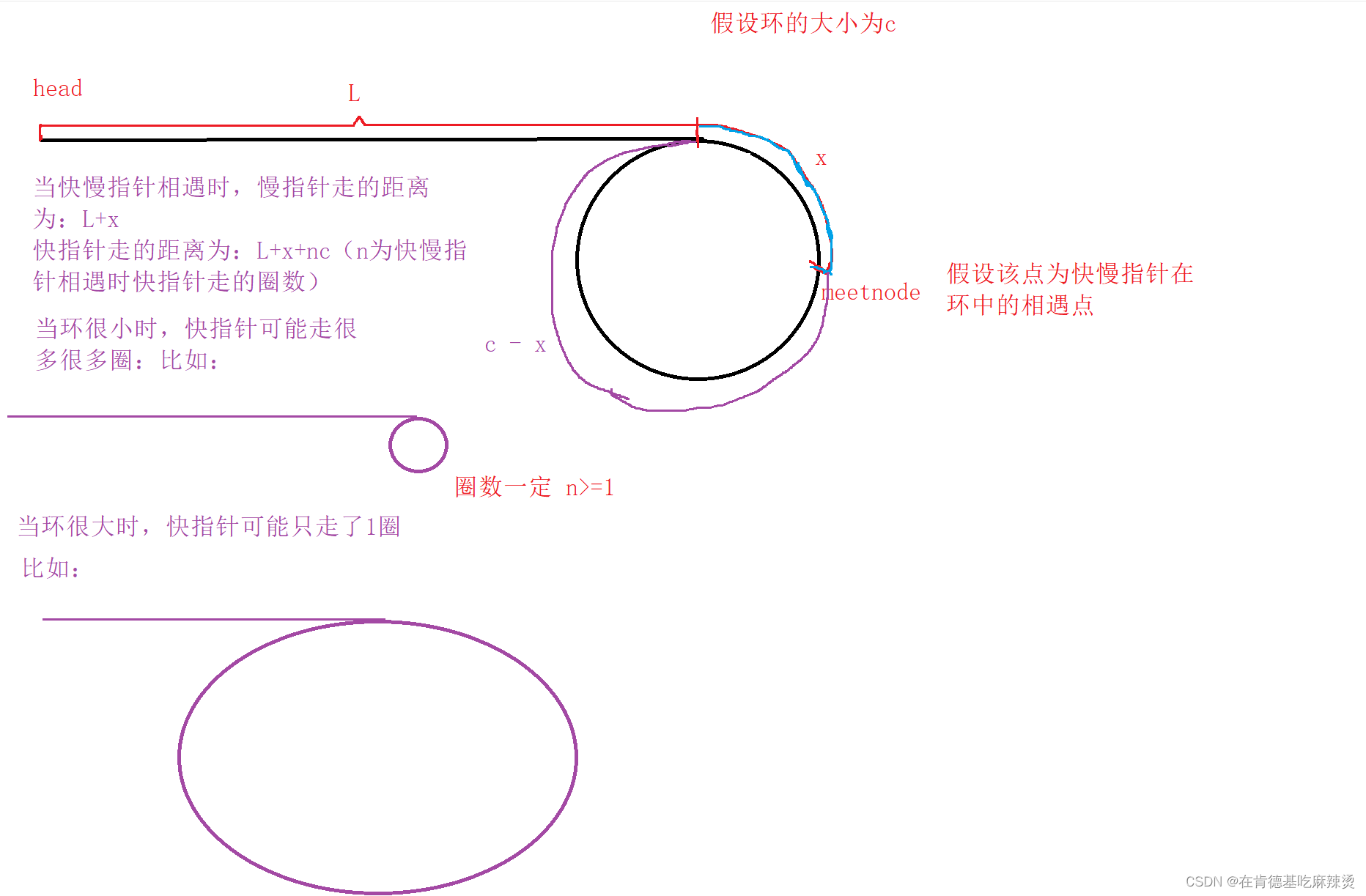
现存的表示方法能够大概分成三类:体素、网格、点云,这些 3 维表示方法在储存、结构和是否利于学习等方面。各有一些优点和不足,并不理想直到占用网络出现

作者提出了占用网格,一种新的基于学习的三维重建方法。占位网络隐式地将三维曲面表示为深度神经网络分类器的连续决策边界。
在占用网络出现之前,因为没有激光雷达提供点云数据,很难对周围环境进行 3D 重建。那么占用网络的出现就很好得解决了这个问题。


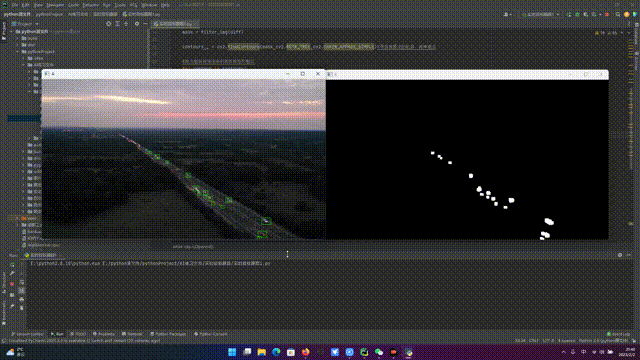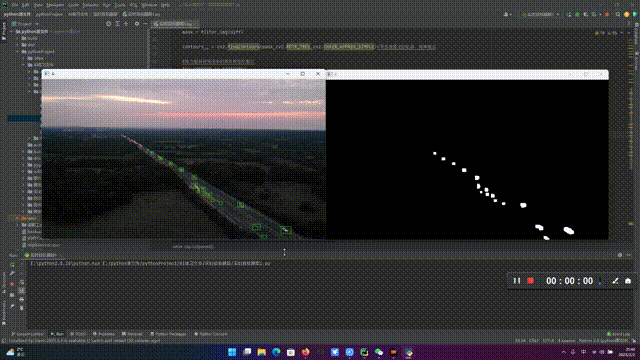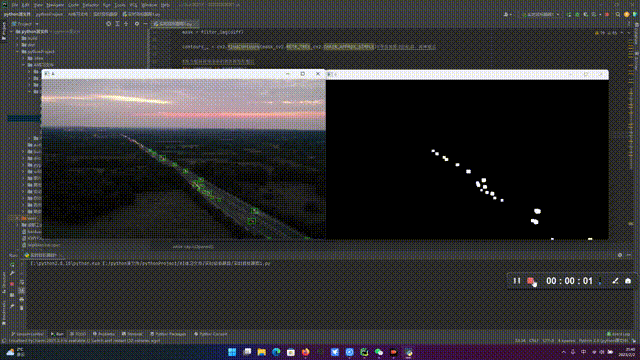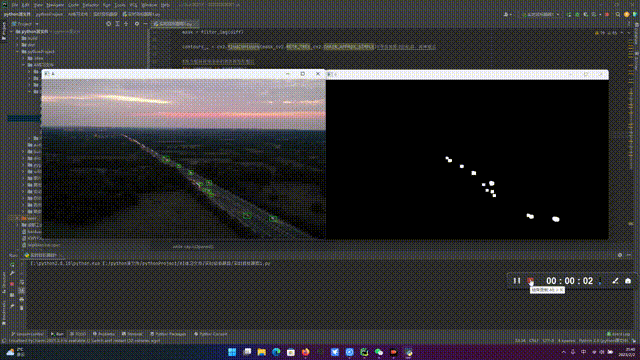
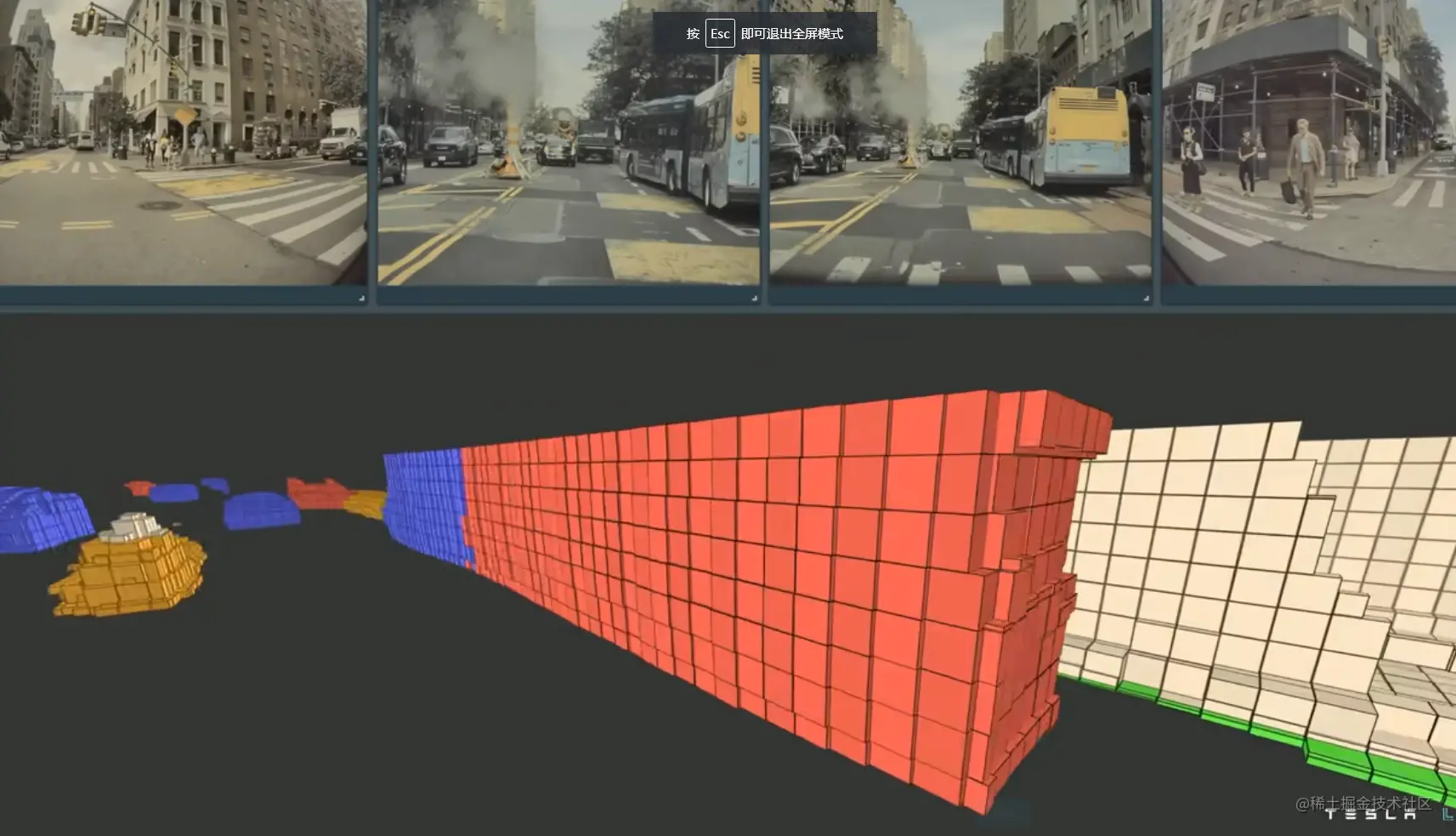
上图中浅蓝色区域为 tesla 的可视区域
蓝色小块堆叠形成物体为运动物体,在画面里不难看出这些是道路上运动的车辆和周围静止物体在占用网络中是明显区别
通过占用网络,特斯拉可以把一些当前场景下遮挡静止物体和动态物体也用体块来表示出来,这样就增加 tesla 的视野域,让特斯拉可以对接下来路径规划有了更多信息。
而且占用网络相比激光雷达的优势在于可以更好地将感知到的3D几何信息与语义信息融合,这是因为占用网络相对于激光雷达产生稀疏点云可以得到更准确 3维场景。

另外一个问题是,在计算机视觉领域,我们输出的检测模型都是使用一个标准的方方正正的矩形来表示,无论是汽车,人物,信号灯等,当计算机视觉系统检测完成后,总是按照一个矩形框来实时显示画面。但是当汽车顶上有杂物,或者卡车旁边有挂钩等,计算机视觉系统一般会屏蔽掉此部分的特性,但是在道路上面,这样的物体确实存在,若被忽略,肯定会出现车祸等问题。

关于占用网络看到这里,自己对于占用网络提取也有点感触,就是我们平时看问题和解决问题方式,大多时候总是惯性思考,有时候所谓开阔思路,也是沿着主线跳来跳去,而不是像特斯拉这样换一个角度来看问题,思考问题。
其实对于深度学习,为了让模型见多识广,不断扩张他感知领域,就需要不断将路面上可能出现目标类别添加数据集来重新训练模型,这样一来可能会带来数据不均衡很多问题,假设即便我们能够让训练收敛拿到一个比较理想模型,那么我们就能把所有类别都标注出来吗?显然是不现实的。例如从车辆上滑落不规则几何体,这样是无法标注的,可能这具体是啥,无人驾驶并不关心,自动驾驶可能只关心他位置所占空间,是静止还是运动就够了。恰恰这些占用网络给出这些答案。
Image Input
1.最左侧基于原始光子计数(Photon Count)的传感器图像作为模型输入,而没有经过ISP等常见的图像预处理方法,根据Tesla之前的分享可以强化系统在低光照可见度低的条件下提供超越人眼的感知能力。
光子计数,所谓光子技术也就是对于输入图像不要做过多预处理
这里要说的一下是在特斯拉采用12位深度 RGB 图像,包含更多丰富颜色信息
电荷耦合器件(CCD)是一种高灵敏度的光子探测器。CCD分为许多光敏小区域(称为像素),可用于构建感兴趣场景的图像。落在由一个像素定义的区域内的光子将转换为一个(或多个)电子,并且收集的电子数量将与每个像素处的场景强度成正比。CCD移出时,可以测量每个像素中的电子数量,并且可以重建场景。

相比之前进行预处理,光子计数可以提升 16 倍效率,其实这是非常非常大幅度提升

Image Featurizers
接受这些图像后,特斯拉用 RegNet 在模型空间内搜索到一个最好模型的子空间,然后再从模型子空间内拿到一个适合模型来提取特征。特征重要性不用多说,接下来一切工作都是以特征作为基础的。组合这些特征才能够准确地描述特斯拉所处环境。
这里要说的是 RegNet 在模型搜索方式上,与之前 NAS 有着本质区别,NAS 是先确定好了一个模型子空间,然后是在这个子空间内来搜索到最好一个模型,也就是说在没有开始搜索前,搜索范围就限定到了一个范围。而 RegNet
,然后在这个子空间内搜索到一个最佳模型,接下来用 BiFPN 来从 RegNet 搜索到特征网络提取不同尺度特征图通过向下或者向上融合,多个这样结构来提取到包含不同尺度特征图
Spatial Attention
从每个摄像头图像经过特征提取网络拿到特征提取出 Key 和 Value。然后这里有一个固定空间(Spatial Query)也就是用提取多个摄像头特征图来融合(构成)一个空间,也就是用多个 2D 图像构建出一个 3D 空间。作为 query,提取特征图Multicam Query Embeding
Temporal Alignment
车辆行驶轨迹在时间上进行衰减对其,在时间上衰减在许多时序问题上都是对历史数据通过加权融合当前时刻
现在鸟瞰图从 2D 经过占用网络变为 3D 空间,然后再经过 Temporal Alignment 将时间维度也融入,这样就得到了
Deconvolutions
这部分内容也就是 Deconvolution,对3D特征空间通过不断 Deconvolution 操作来得到一个高分辨率的 3D 特征空间
Volume Outputs
提供亚体像素也就是
Queryable Outputs
这里有 2 个 MLP 多层感知机分别输出位置和类别
Surface Outputs
基于高分率的,可以感知路面高低起伏。
从趋势上来看占用网络势必取代 BEV 称为 Tesla 了解环境的工具。空间中信息RNN 做记忆模块
Temporal Alignment 也就是车辆看到东西有一个时间上衰减,也就是我们