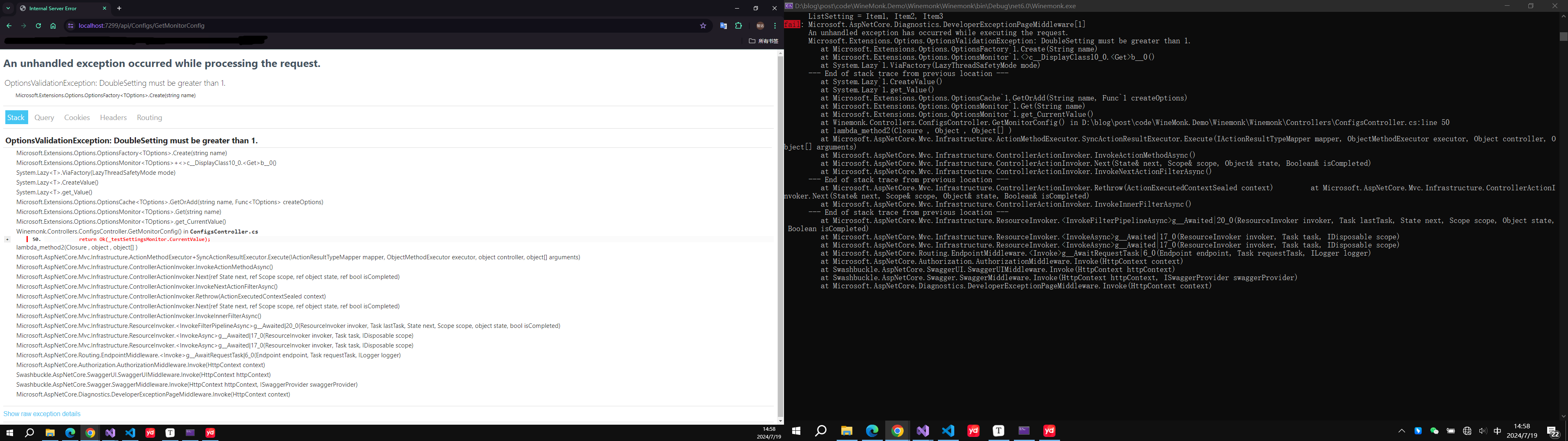
1、基本思想
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(n*logn),它也是不稳定排序。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。
每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆(此题用小顶堆)
另外要注意,堆要用数组来储存

堆排序基本思想是:
将待排序序列构造成一个小顶堆
此时,整个序列的最大值就是堆顶的根节点。
将其与末尾元素进行交换,此时末尾就为最大值。
然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了2、
2、代码实现
#include<iostream>
using namespace std;
void FelterDown(int* data, int start, int end)
{
int i = start, j = 2 * i + 1;
int tmp = data[i];
while (j <= end)
{
if (j<end && data[j]>data[j + 1])
{
j++;
}
if (tmp <= data[j]) break;
data[i] = data[j];
i = j;
j = 2 * i + 1;
}
data[i] = tmp;
}
void HeapSort(int* ar, int n)
{
int pos = (n - 2) / 2;
while (pos >= 0)
{
FelterDown(ar, pos, n - 1);
pos--;
}
int j = n - 1;
while (j >= 0)
{
swap(ar[0], ar[j]);
j--;
FelterDown(ar, 0, j);
}
}
void Print(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
cout << arr[i] << " ";
}
cout << endl;
}
int main()
{
int ar[] = { 12,34,45,67,78,8 };
int n = sizeof(ar) / sizeof(ar[0]);
HeapSort(ar, n);
Print(ar, n);
return 0;
}3、堆排序算法的常见问题
最坏情况性能:
堆排序的最坏情况时间复杂度是O(n log n),但这是在特定输入下才会发生的,例如输入数组已经是完全逆序的。在大多数实际应用中,堆排序的性能通常接近最优。
避免方法:由于堆排序的最坏情况并不常见,通常不需要特别避免。如果确实关心最坏情况性能,可以考虑使用其他算法,如快速排序或归并排序。
非稳定排序:
堆排序不是稳定的排序算法,这意味着相等的元素在排序后可能会改变它们的原始顺序。
避免方法:如果稳定性是必需的,可以考虑使用稳定的排序算法,如归并排序或插入排序。
原地排序的空间复杂度:
堆排序是原地排序算法,它不需要额外的存储空间,但需要空间来维护堆结构,这可能会对内存使用产生影响。
避免方法:如果内存使用是一个问题,可以考虑使用其他原地排序算法,如快速排序。
构建初始堆的时间开销:
在堆排序中,构建初始堆的时间复杂度是O(n),这可能会增加算法的总体时间开销。
避免方法:对于小规模数据集,构建初始堆的开销可能不是问题。对于大规模数据集,可以考虑使用其他排序算法,或者优化堆的构建过程。
递归实现的栈空间限制:
堆排序的递归实现可能会因为数据集过大而导致栈溢出。
避免方法:可以使用非递归版本的堆排序来避免这个问题,或者使用尾递归优化的版本。
数据局部性:
堆排序在操作过程中可能会破坏数据的局部性,这可能会影响缓存的性能。
避免方法:对于需要高缓存性能的应用,可以考虑使用其他具有更好数据局部性的排序算法,如插入排序或归并排序。
不适合小数据集:
由于构建堆和堆调整的开销,堆排序在小数据集上的性能可能不如一些简单的排序算法,如插入排序或选择排序。
避免方法:对于小数据集,可以使用更简单的排序算法,或者设置一个阈值,在数据集大小小于该阈值时使用简单排序算法。
代码复杂度:
堆排序的实现相对复杂,特别是对于不熟悉堆数据结构的开发者。
避免方法:可以使用标准库提供的排序函数,这些函数通常已经优化过,并且能够处理各种复杂情况。