Flume简介&安装配置&使用教程
1、Flume简介
一:概要
Flume 是一个可配置、可靠、高可用的大数据采集工具,主要用于将大量的数据从各种数据源(如日志文件、数据库、本地磁盘等)采集到数据存储系统(主要为Hadoop HDFS)中,用来处理日志数据,并支持在数据流中可靠、高效地移动数据。
二:Flume的基础架构
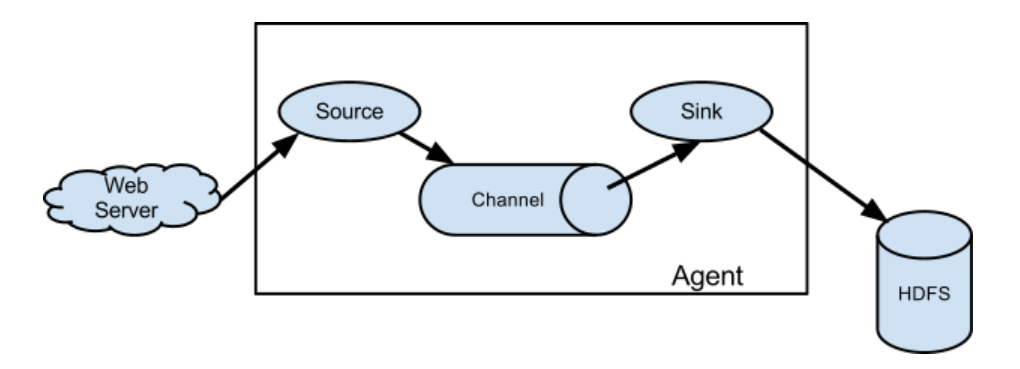
详细讲解:
Flume主要由三部分组成:Source,Channel,Sink。
1.Source:负责接收数据至 Flume Agent 组件中【入口】,常见的数据源主要有TailDir,SpoolingDir。
- SpoolingDir和TailDir都是Flume中的一个文件型数据源,可以实时监控指定目录下的新增和修改文件,并将这些文件的内容传输至Flume中。
- TailDir适用于实时监控日志文件并传输到其他系统的场景,特别是处理持续追加内容的日志文件情景,支持正则表达式匹配文件名。
- SpoolingDir适用于同步新文件(完整且不变)到Flume Sink的场景,不支持直接通过正则表达式匹配文件名。
2.Channel:位于 Source 和 Sink 之间的【缓冲区】。通常是Memory【内存中的队列】,File,Kafka。
3.Sink:负责从Channel缓冲区中获取数据并将其存储到目标存储系统中【出口】。目标存储系统一般有HDFS,Hive,Hbase,Kafka,通常将数据存放于HDFS中。
2、Flume安装配置
# 1、将安装包放置虚拟机中的/opt/download目录下
# 2、解压缩至/opt/software目录下,并改名为flume-1.9.0
解压:
cd /opt/download
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/software/
重命名:
cd /opt/software
mv apache-flume-1.9.0-bin/ flume-1.9.0
# 3、复制相关依赖操作
进入flume的lib目录中:
cd /opt/software/flume-1.9.0/lib/
# 复制 hadoop 相关依赖到flume的lib目录下
cp /opt/software/hadoop-3.1.3/share/hadoop/*/*.jar ./
# 复制 hive hcatelog 相关依赖到flume的lib目录下
cp /opt/software/hive-3.1.2/hcatalog/share/hcatalog/*.jar ./
# 复制 hive 相关依赖到flume的lib目录下
cp /opt/software/hive-3.1.2/lib/hive-*.jar ./
cp /opt/software/hive-3.1.2/lib/antlr*.jar ./
# 4、放大堆内存
进入flume的bin目录下:
cd /opt/software/flume-1.9.0/bin/
vim flume-ng
--------- 修改配置 -----------
JAVA_OPTS="-Xmx1024m"
-----------------------------
# 结束!
3、Flume使用教程——交易行为日志采集
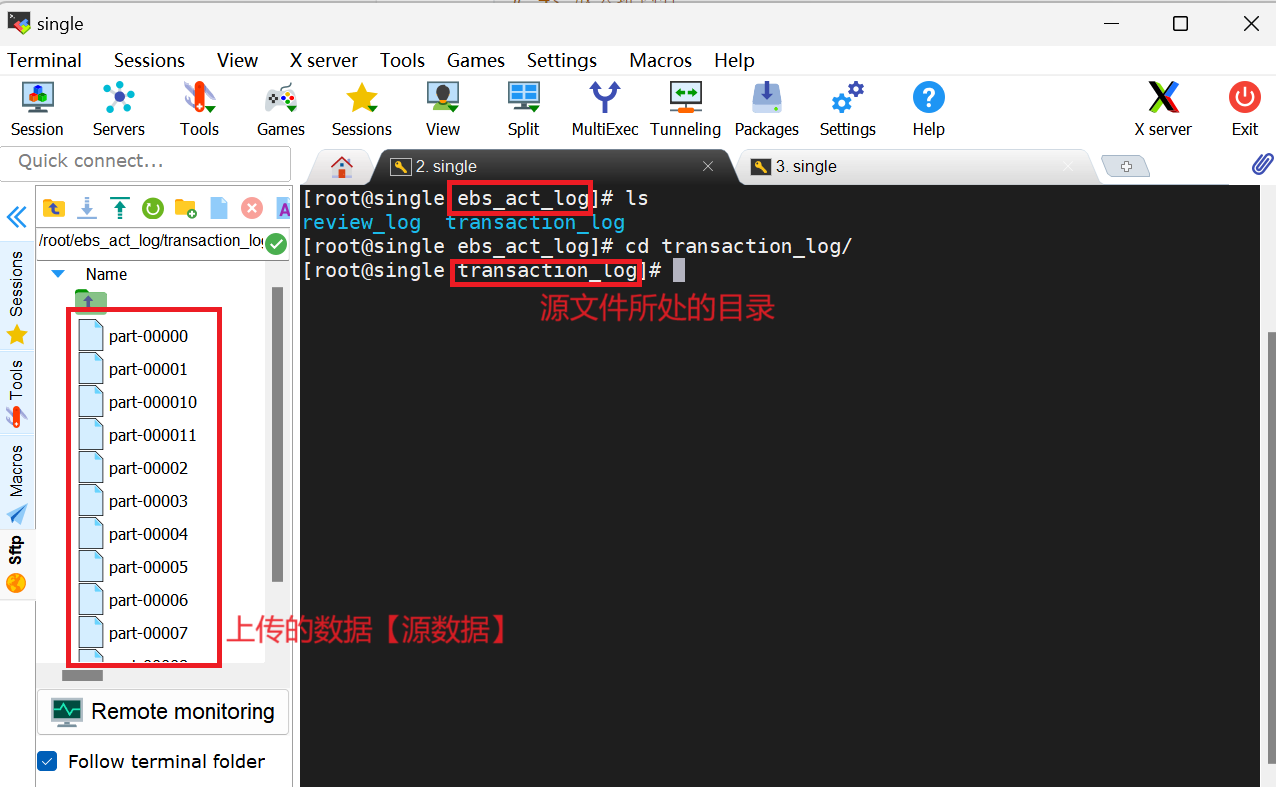
一:创建ebs_act_log目录存放源数据【入口】
此处我们的数据源是与交易相关的数据。因此,在ebs_act_log目录下创建一个transaction_log目录,用于存放与交易数据相关的文件。此处的transaction_log目录将作为【数据来源】使用,今后只需将相关数据文件放置在该目录下即可,主要用于【上传数据】
mkdir ebs_act_log
cd ebs_act_log
mkdir transaction_log
二:需在HDFS上提前创建好存放数据的目录【出口】
此处,我们将数据存放在**/external_ebs/transaction**目录下,如图所示:
三:Flume相关需求配置
为了使得构建时目录结构清晰,同时为我们之后做数仓更为便利,我将Flume相关配置统一放置在了project_ebs目录中的act_log_extract/flume_config目录下。
在flume_config目录中我们需要构建四个基本目录,分别是channel-checkpoint、channel-data、conf-file、position-file。先介绍这四个目录分别所起到的作用:
- channel-checkpoint和channel-data目录是存放任务过程文件;
- position-file目录是存放位置记录相关文件,便于下次读取数据时无需重复读取相同内容;
- conf-file目录是用于存放flume相关的配置文件。
在position-file目录中可以创建一个文件transaction_pos.log,内部可先进行以下操作【可选】:

然后,在conf-file目录下创建transaction.cnf文件【其中配置源文件source,目标文件sink,以及channel相关信息】,Flume数据采集就是通过读取此配置来实现实时监控。【◉:可修改处】
vim transaction.cnf
-----------------------------------------------------------------------
a1.sources = r1
a1.channels = c1
a1.sinks = s1
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /root/project_ebs/act_log_extract/flume_config/position-file/transaction_pos.log # 采集数据的相关位置记录:标志读取数据位置,便于下次操作时不重复读取相同内容 ◉
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/ebs_act_log/transaction_log/part-.* # 数据来源【数据名不可相同,否则会覆盖】◉
a1.sources.r1.fileHeader = false # 数据没有表头,只需填写 false 即可;若有,则true
# a1.sources.r1.headers.f1.headerKey1 = store # 数据没有表头,就无需配置
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/project_ebs/act_log_extract/flume_config/channel-checkpoint # 检查点
a1.channels.c1.dataDirs = /root/project_ebs/act_log_extract/flume_config/channel-data # 管道数据
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.fileType = DataStream # 不会压缩输出文件,若不配置会进行序列化操作
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.path = hdfs://single:9000/external_ebs/transaction # 将数据存放到hdfs中目录下【目录路径】◉
a1.sinks.s1.hdfs.filePrefix = event-
a1.sinks.s1.hdfs.fileSuffix = .json # 结果出来文件的后缀名
a1.sinks.s1.hdfs.rollInterval = 180 # 180s溢写一次
a1.sinks.s1.hdfs.rollSize = 134217728 # 128M溢写一次
a1.sinks.s1.hdfs.rollCount = 0
# 关联sources,channels,sinks
a1.sinks.s1.channel = c1
a1.sources.r1.channels = c1
-----------------------------------------------------------------------
四:启动Flume检测
说明:其中--name a1中名为a1是因为在配置中都是以a1开头进行配置的,--conf指向flume中conf文件,--conf-file指向我们所配置的transaction.cnf文件。
/opt/software/flume-1.9.0/bin/flume-ng agent \
--name a1 \
--conf /opt/software/flume-1.9.0/conf/ \
--conf-file /root/project_ebs/act_log_extract/flume_config/conf-file/transaction.cnf \ # ◉
-Dflume.root.logger=INFO,console
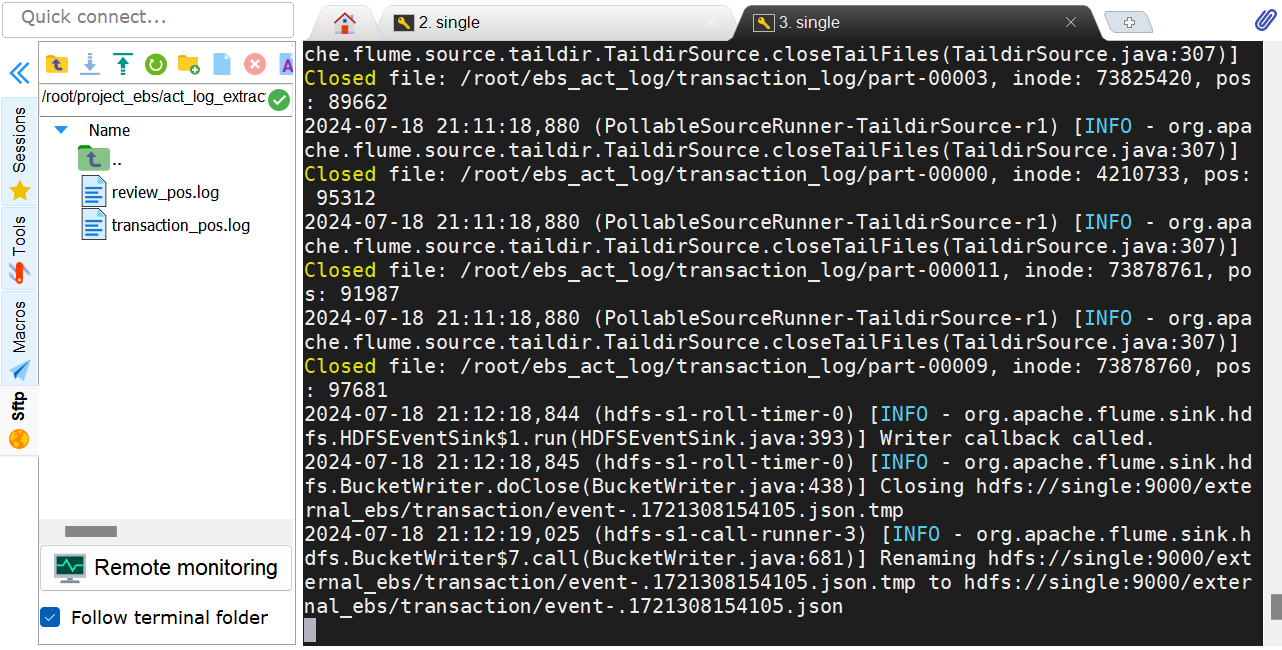
HDFS存储结果:

五:定期处理
由于channel-checkpoint和channel-data中存放与过程相关数据,可以对其进行定期的处理。
rm -rf channel-checkpoint/*
rm -rf channel-data/*