机器学习西瓜书笔记二
- 第二章(chapter 2) 模型评估与选择 (参考机器学习西瓜书)
-
- 第一节(section 1)经验误差与过拟合
- 第二节(section 2)评估方法
-
- 留出法
- 交叉验证法
- 自助法
- 调参与最终模型
- 第三节(section 3)性能度量
-
- 错误率与精度
- 查准率与查全率
- ROC与AUC
- 代价敏感错误率与代价曲线
- 第四节(section 4)比较检验
-
- 假设检验
第二章(chapter 2) 模型评估与选择 (参考机器学习西瓜书)
第一节(section 1)经验误差与过拟合
- 错误率(error rate):分类错误的样本数占样本总数的比例称为错误率。
- 精度(accuracy):精度 = 1 - 错误率。
如果在m个样本中有a个样本分类错误,那么错误率 E = a/m,精度 = 1 - E。
更一般地,把模型的实际预测输出与样本的真实输出之间的差异称为误差(error)。在训练集上的误差称为训练误差,在新样本/测试集上的误差称为泛化/测试误差。实际所希望的,是在新样本上能表现得很好的模型,在这里引入两个重要概念:过拟合与欠拟合。
过拟合:模型把训练样本学习的太好了,已经把训练样本自身的特点当做了所有潜在样本会存在的一般性质,会导致泛化性能下降。

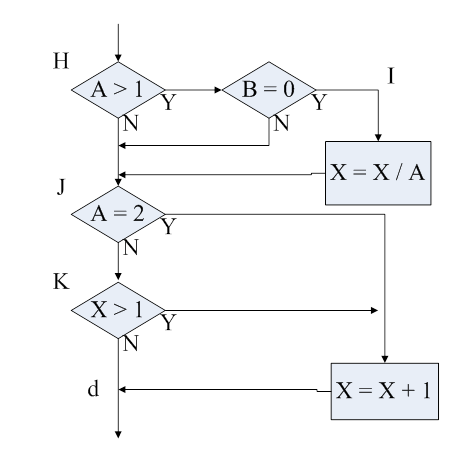
上图即为学习发现过拟合时候的情况,可以看到随着学习轮数的增加,训练误差一直在下降,然而泛化误差在经历一小段下降后却开始升高,此时便需要采用一些措施来缓解过拟合问题。
欠拟合:模型在训练集上表现不佳,泛化能力也不佳。

需要认识到,欠拟合通常是因为学习能力低下而导致的,这一点可以较容易克服,然而过拟合是无法彻底避免的,所能做的只有运用各种方法来缓解,常见的缓解过拟合的方法有正则化与dropout等。(建议参考吴恩达机器学习的调参手册)
第二节(section 2)评估方法
通常,使用一个测试集来测试学习器(模型)对新样本的判别能力,然后以测试集上的"测试误差"来作为泛化误差的近似。需要注意,测试集应与训练集互斥,即测试样本尽量不在训练集中出现或未在训练集中使用过。
很多时候,最初都会得到一个包含m个数据样本的数据集D,那么如何得到训练集S和测试集T呢?自然是选择合适的方法对D进行划分,产生出训练集S和测试集T。
以下介绍几种常见的划分方法:
留出法
直接将数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T,保证S∩T=∅且S∪T=D。
注意:训练集与测试集的划分要尽可能保证数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。
如果从采样(sampling)的角度来看待数据集的划分过程,则保留类别比例的采样方法一般称为"分层采样"(stratified sampling)。
而单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值为留出法的评估结果。
例如:进行100次随机划分,每次产生一个训练集和测试集用于实验评估,100次会得到100个结果,而留出法的返回应当是这100个结果的平均。
常见分割数据比例大约为0.6~0.8,即每次取数据集中60%-80%作为训练集,剩下的作为测试集。
交叉验证法
将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,Di∩Dj=∅(i≠j)。每个子集Di都尽可能保持数据分布的一致性,即从D中分层采样得到。然后每次用k-1个子集的并集作为训练集,剩下的那个子集作为测试集,这样就可以得到k组训练/测试集,从而进行k次训练和测试,最终返回这k次测试的均值。
显然,交叉验证法评估结果的稳定性与保真性在很大程度上取决于k的取值,为了强调这一点,通常把交叉验证法称为k折交叉验证(k-fold cross validation)。k常取值:5,10,20。与留出法相似,将D划分为k个子集有多种方法,假设k折交叉验证要随机使用不同的划分重复p次,则最终评估结果是这p次k折交叉验证结果的均值,常见有10次10折交叉验证(训练100次)。
交叉验证法也存在第一个特例:留一法(Leave-One-Out,简称LOO):假定数据集D中有m个样本,令k=m,则会发现,m个样本只有唯一的划分方法来划分为m个子集——每个子集一个样本,所以留一法的训练集与数据集D相比只差一个样本,故留一法中被实际评测的模型与期望评估的用D训练出的模型很相似,因此,留一法的评估结果往往被认为较准确。但是在数据集很大的时候,训练m个模型的开销明显是难以忍受的。故NLF定理在这里也同样适用。
自助法
在留出法和交叉验证法中,由于保留了部分样本作为测试,所以实际评估的模型中所使用的训练集比D小,而希望评估的是D训练出的模型,所以这必然会引入一些因训练样本规模不同而导致的估计偏差。自助法(bootstrapping)就是来解决这个问题。自助法以自助采样(bootstrap sampling)为基础(自助采样也叫"可重复采样"与"有放回采样"):给定包含m个样本的数据集D,对它进行采样产生数据集D’:每次从D中随机选一个样本,将其拷贝到D’中,再将其放回D中,重复m次,那么就可以得到包含m个样本的数据集D’。显然D中一部分样本会在D’中多次出现,而另一部分不出现,由一个简单的估计可以得到样本在m次采样中不被采到的概率如下:0.368。于是可以把D’当做训练集,D-D’作为测试集,这样,实际评估模型与期望评估模型都有m个训练样本,而仍然有数据总量1/3的样本用于测试,这样的测试结果,称为"包外估计"。
- 注意:自助法在数据量较少,难以有效划分训练集和测试集的时候很有用,然而自助法改变了初始数据分布,引入了估计偏差,故在数据量足够的时候,留出法和交叉验证法更常用一些。
调参与最终模型
给定包含m个样本的数据集D,在模型评估与选择过程中由于需要留出一部分数据进行评估测试,事实上只使用了一部分数据训练模型。需要注意的是,通常把学得模型在实际使用中遇到的数据称为测试数据,为了加以区分,模型评估与选择中用于评估测试的数据集称为验证集。例如,在研究对比不同算法的泛化性能时,用测试集上的判别效果来估计泛化性能,而把训练数据另外划分为测试集和验证集,基于验证集上的性能来进行模型选择和调参。
训练集:用于模型训练。
验证集:用于模型训练过程中用于评估、调参等数据。
测试集:用于验证模型泛化能力。
第三节(section 3)性能度量
对学习器的泛化能力进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)。要评估学习器f的性能,就需要把学习器预测结果f(x)同真实标记y进行比较。以下是几种评估泛化能力的标准:
- 离散均方误差 E ( f , D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f,D)=\frac{1}{m} \sum_{i=1}^{m}(f(x_i)-y_i)^2 E(f,D)=m1∑i=1m(f(xi)−yi)2
- 一般连续空间均方误差,数据分布D和概率密度p, E ( f , D ) = ∫ x ∼ D ( f ( x ) − y ) 2 p ( x ) d x E(f,D)=∫_{x\sim D}(f(x)-y)^2p(x)dx E(f,D)=∫x∼D(f(x)−y)2p(x)dx
错误率与精度
分类任务的性能度量:一般连续空间的度量公式为积分形式,由于实际应用通常为离散样本,故此后度量公式仅给出了离散情况的公式
- 错误率:分类错误的样本数占样本总数的比例。 E ( f , D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) E(f,D)=\frac{1}{m} \sum_{i=1}^{m} \mathcal{I}(f(x_i) \neq y_i) E(f,D)=m1∑i=1mI(f(xi)=yi),注 I \mathcal{I} I表示指示函数,函数括号内逻辑为真取1,否则取0。
- 精度:分类正确的样本数占样本总数的比例。 a c c ( f , D ) = 1 − E ( f , D ) acc(f,D)=1-E(f,D) acc(f,D)=1−E(f,D)
查准率与查全率
对于查准率和查全率的定义,书中有一个形象的例子:信息检索中,经常会关心"检索出的信息中有多少比例是用户感兴趣的" 、“用户感兴趣的信息中有多少被检索出来了”,“查准率”(precision)与"查全率" (recall) 是更为适用于此类需求的性能度量。对于二分类任务,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)与假反例(false negative)四种情形。分别对应为TP、FP、TN、FN。分类结果的"混淆矩阵"如下定义:

- TP:被模型预测为正类的正样本(实际为正,预测也为正)。
- TN:被模型预测为负类的负样本(实际为负,预测也为负)。
- FP:被模型预测为正类的负样本(实际为负,预测为正)。
- FN:被模型预测为负类的正样本(实际为正,预测为负)。
查准率P(准确率)与查全率R(召回率)分别定义为:
- 查准率 $P = \frac{TP}{TP+FP} $
- 查全率 R = T