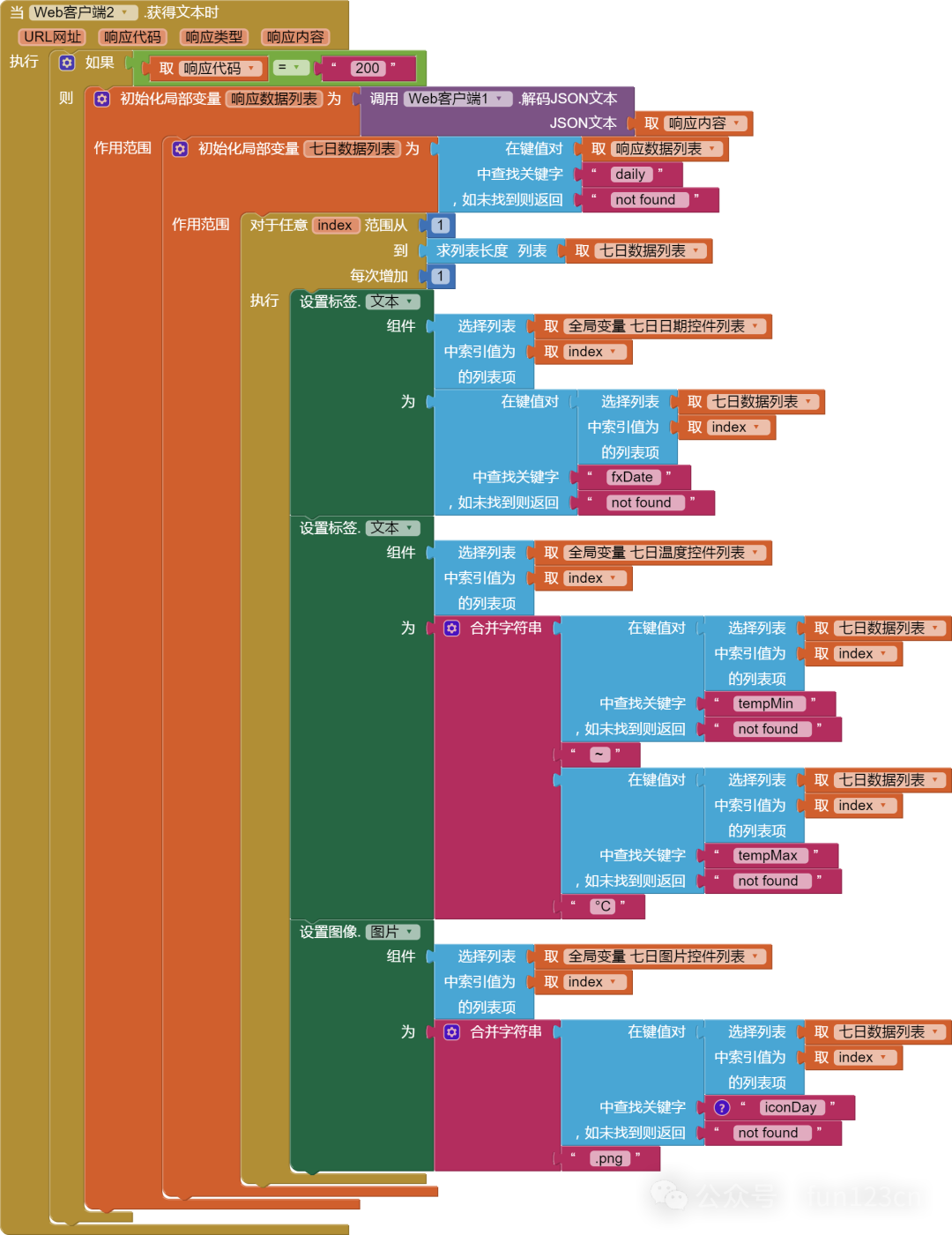
前言
最近对爬虫比较感兴趣,于是浅浅学习了一些关于爬虫的知识。爬虫可以实现很多功能,非常有意思,在这里也分享给大家。由于爬虫能实现的功能太多,而且具体的实现方式也有所不同,所以这里开辟了一个新的系列——爬虫系列,来介绍爬虫的各种用法。
什么是爬虫
爬虫,简单来说,就是通过一些代码,自动获取网络上的信息的一种手段。而爬虫一般通过python来实现。
在这个信息化的时代,数据纷繁芜杂,如何从网上获取对我们有用的数据,如何获取不带水印的数据,如何绕开VIP的限制免费获得数据,爬虫会给我们答案。
python基础
以防有人不太会python,这里简单介绍一下python基础,懂的可以直接跳过。
创建项目
1.双击打开pycharm,点击新建项目
2.项目设置
- 勾选[继承全局站点软件包]
- 勾选[可用于所有项目]
- 取消勾选[创建main.py欢迎脚本]
- 点击创建
3.项目名称右键–新建–python文件
4.输入文件名–回车
python规范
1.数字和字符串
数字正常写 字符串加引号
2.注释
注释就是对代码的解释和说明。
# 解释的文字
3.标点符号
标点符号都用英文的标点符号!
, . [] < > = ! : 英文的
,。【】《》=!: 中文的不能用!
4.变量
在程序中用来保存数据的可以变化的量!
变量 = 数据
代码示例:
name = '天涯海角'
age = 22
gender = '女装大佬'
money = 100000000000
print(name, age, gender, money)
5.加载模块
在代码下面找到“终端”,点击终端,输入
pip install 模块名
即可加载该模块。
爬取快手无水印视频
这里实现的功能是通过四行代码可以爬取任意一个快手视频,而且无水印哦。
难点:怎么找到网址!以谷歌浏览器为例。
a.点击一条视频--浏览器右上角设置菜单--更多工具--开发者工具。
b.选择网络(network)--选择媒体(media)--刷新页面(不刷新页面可能没有数据)。
c.鼠标点击一条数据进去--复制网址(注意不是网页的网址,而是右下角的视频的网址)

下面给出四行代码以及详细的代码解释。
# 引号里面放视频的网址
url="https://v2.kwaicdn.com/ksc2/1Z86LBOQcVyaER9aXs4JJfkDlrp6hUK-QPl-gd_f9Woi7p8HKRCmak--7iEqoRXqMIe9PRGrj2bleAfnzUzqqNPGIMLyovVVm8jE65mG9vt1MK13b4mAYWKoSQ9h6Pe0.mp4?pkey=AAWpBlzIENFNqxzwQIaBLoiVu5D5y25UQKpnZLZ8K5Up8ggzeIJ_BoijxP5cU72Nyen-lbR_aqVhBg6hQDSFfKJwyhbI9j4WSnMVeLxt4C5mJ3ZvvF3NoIimnAYNHhAtOl8&tag=1-1721196852-unknown-0-nhcjzzfyru-2d0290527442a5c0&clientCacheKey=3xiu5qcnkkx3ema_aab2f98f&di=IAECUFgAEAIAAAAAAAPgxA==&bp=10004&tt=hd15&ss=vp"
# 注意运行代码前要先导入requests模块
import requests
# 使用requests的get功能 获取网站的响应
res = requests.get(url)
# 打开一个空的视频(快手无水印视频.mp4) 把得到res.content丢进去 得到一个可以播放的视频
open('快手无水印视频.mp4', 'wb').write(res.content)
最后,这个新产生的视频会存在于python代码的同一文件夹下。可以在python代码界面,点击鼠标右键–打开于–Explorer,就可以看到视频了。

总结
本文运用四行代码,实现了爬虫的最最基础的功能——爬取一条数据(一个视频)。后面将介绍爬虫的一些其它更有用的功能。