目录标题
- 1、正则表达式介绍
- re库的主要功能函数
- Re库的match对象
- Re库的贪婪匹配和最小匹配
- 2、正则表达式案例
- 案例1:所有图片爬取
- 案例2:分页爬取
- 案例3:淘宝商品信息
- 案例4:股票数据
1、正则表达式介绍
正则表达式re:简洁表达一组字符串的表达式。通用的字符串表达框架
优势:简洁
正则表达式在文本处理中十分常用
常用操作符:
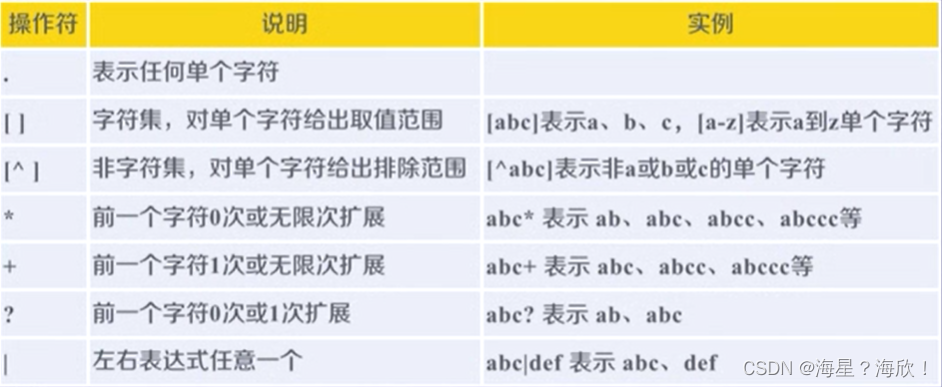
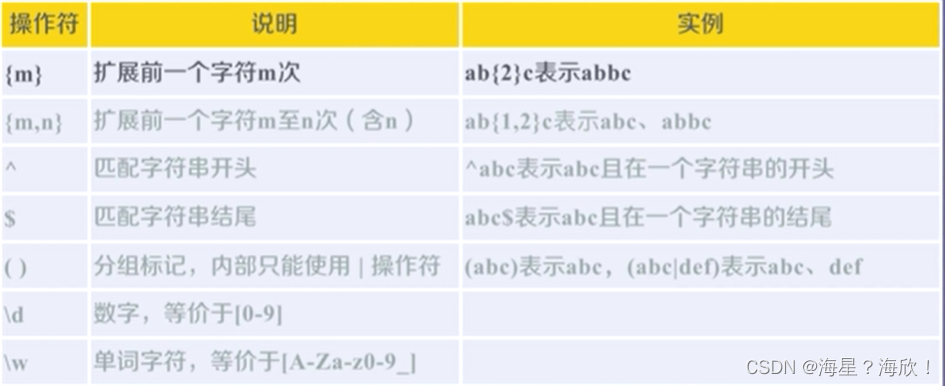
Re库
正则表达式的表示类型:
1,raw string 类型(原生字符串类型)–不含有转义字符串
2,string类型,\会理解为转义符,更繁琐
re库的主要功能函数

re.search()


search例子:
import re
match = re.search(r"[1-9]\d{5}","BIT 10081") #邮政编码
if match:
print(match.group(0)) #返回10081
re.match()

import re
match = re.match(r"[1-9]\d{5}","BIT 10081")
if match: #判断是否为空
match.group(0) #输出10081
re.findall()

import re
ls = re.findall(r"[1-9]\d{5}","BIT 10081 TSU10084")
print(ls) #输出:10081,10084
re.split()

import re
re.split(r"[1-9]\d{5}","BIT 10081 TSU10084") #输出:['BIT','TSU','']
#将一个正则表达式去匹配字符串,匹配的部分去掉,去掉之后的元素作为分割的字符串元素放在一个列表里
re.split(r"[1-9]\d{5}","BIT 10081 TSU10084",maxsplit =1) #输出['BIT','TSU10084']
#maxsplit =1造成只匹配第一个
re.finditer()

import re
for m in re.finditer(r"[1-9]\d{5}","BIT 10081 TSU10084"):
if m:
print(m.group(0))
#输出:
10081
10084
#迭代的获取每一个匹配的结果,并对其进行单独的处理
re.sbu()

import re
re.sub(r"[1-9]\d{5}",":zipcode","BIT 10081 TSU10084")
#输出:BIT :zipcode TSU:zipcode 即将匹配到的内容进行替换
re库的两种使用方法:


re.compile()


Re库的match对象
match对象:一次匹配的结果
import re
match = re.search(r"[1-9]\d{5}","BIT 10081")
if match:
print(match.group(0)) #输出10081
type(match) #输出: <class '_sre.SRE_Match'>
Match对象的属性:
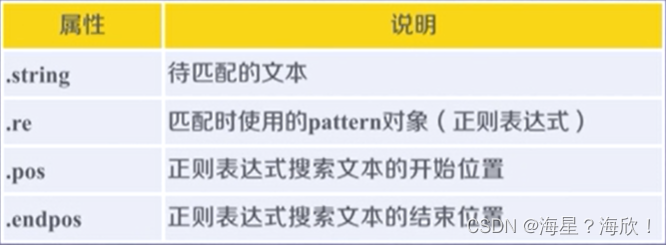
match对象常用方法:

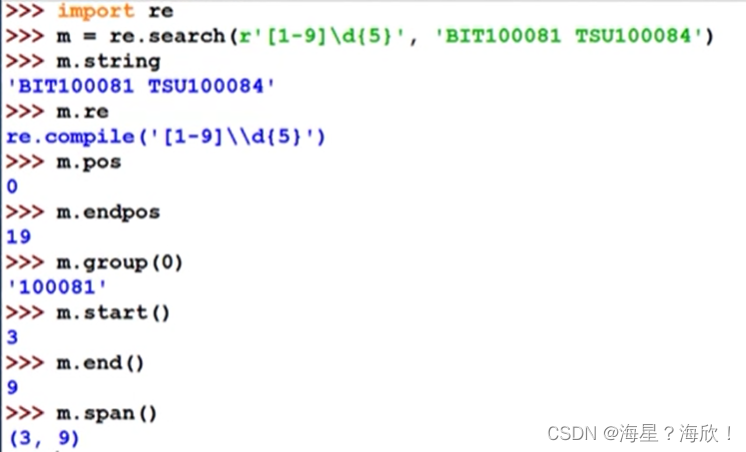
group(0)只返回第一次匹配后的结果,要全部匹配结果,使用finditer()函数
Re库的贪婪匹配和最小匹配
Re库默认采用贪婪匹配,输出匹配最长的字串
match = re.search(r"py.*n",'pyanbncndn') #'pyan','pyanbn'等等都符合要求
match.group(0) #输出:'pyanbncndn'
如何输出最短的字串?–加一个?问号
match = re.search(r"py.*?n",'pyanbncndn') #'pyan','pyanbn'等等都符合要求
match.group(0) #输出:'pyanbncndn'
最小匹配操作符

2、正则表达式案例
案例1:所有图片爬取
需求:单一图片的加载和存储
#实现:单一图片的加载和存储
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
if __name__ == "__main__":
#每个图片有对应的地址请求
url = 'https://p0.ssl.img.360kuai.com/t013fed37710ef441ad.webp' #图片地址
#content返回的是二进制形式的图片
#text(字符串) content(二进制) json(对象)
img_data= requests.get(url=url).content
with open('./giutu.jpg','wb') as fp:
fp.write(img_data)
需求::糗事百科页面下的所有图片
#实现:糗事百科页面下的所有图片
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import re
import os
if __name__ == "__main__":
#创建一个文件夹,保存所有的图片
if not os.path.exists('./giutuLibs'):
os.mkdir('./giutuLibs')
#每个图片有对应的地址请求
url = 'https://www.qiushibaike.com/pic/' #网站打不开了所以没有结果
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#使用通用爬虫对url对应的一整张页面进行爬取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫
ex = '<div class="thumb">.*?<img src="(.*?)"all.*?</div>'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
src = 'https:'+src
img_data = requests.get(url=src,headers=headers).content
#生成图片名称(从图片地址的最后一部分作为名称)
img_name = src.src.split('/')[-1]
#图片存储的路径
imgpath = './giutuLibbs'+img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
案例2:分页爬取
上例中只爬取了第一页的图片,这次我们需要实现分页功能
#实现:糗事百科页面下的所有图片
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import re
import os
if __name__ == "__main__":
#创建一个文件夹,保存所有的图片
if not os.path.exists('./giutuLibs'):
os.mkdir('./giutuLibs')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#每个图片有对应的地址请求
#设置一个通用的url模板
url = 'https://www.qiushibaike.com/pic/page/%d/?s=5184961' #%d要替换成具体的数
#pageNum=2
#取前两页
for pageNum in range(1,3):
#new_url是对应页码的url
new_url = format(url%pageNum) #pageNum会替换%d部分
#使用通用爬虫对url对应的一整张页面进行爬取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫
ex = '<div class="thumb">.*?<img src="(.*?)"all.*?</div>'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
src = 'https:'+src
img_data = requests.get(url=src,headers=headers).content
#生成图片名称(从图片地址的最后一部分作为名称)
img_name = src.src.split('/')[-1]
#图片存储的路径
imgpath = './giutuLibbs'+img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
不同页面的url只有一个页数部分不同,其他地方都一样,所以加个循环替换掉不同的地方即可
案例3:淘宝商品信息
目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
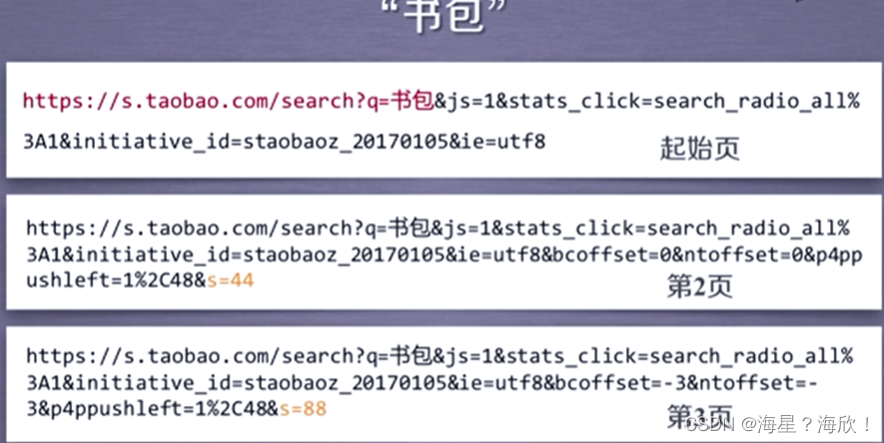
步骤:
1,提取商品搜索请求,
import requests
import re
def getHTMLText(url):#获得页面
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return " "
def parsePage(ilt,html): #对每个页面进行解析 ,参数:结果的列表ilt和HTML信息
#在查询过后发现,商品价格前面有一个参数view_price,名称前raw_title
#异常处理很重要,保证了出现问题时不会异常退出
try:
plt = re.findall(r'\"view_price\"\:"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) #按:分割后取后面的数值
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("")
def printGoodsList(ilt): #商品信息输出
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count+1
print(tplt.format(count,g[0],g[1]))
def main(): #主函数
goods = "书包"
depth = 2 #只爬取当前页和下一页
start_url = "https://s.taobao.com/scarch?q="+goods
infoList = [] #存储输出结果
for i in range(depth):
try:
url = start_url + '&s='+str(44*i) #有一个参数s,第一页为0,第二页44,后面44的倍数
html = getHtMLText(url)
parsePage(infoList,html)
except:
continue #如果出现问题,进入下一个循环
printGoodsList(infoList)
main()

案例4:股票数据
目标:获取上交所和深交所所有股票名称和交易信息,并保存到文件中
需要找到能获取股票的网站,网站也有要求:股票信息静态存在于HTML中,非js代码生成,没有robots协议限制
步骤:
1,获取股票列表
2,逐个股票信息
3,存储到文件中
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):#获得url对应页面
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return " "
def getStockList(lst,stockURL): #获得股票的信息列表,参数:列存储表,url网站
html = getHTMLText(stockURL)
soup = BeautifulSoup(html,'html.parser')
a = soup.find_all('a')#查看代码后,发现信息在a标签下
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href[0]))
except:
continue
def getStockInfo(lst,stockURL,fpath): #获取每个股票的信息,并存储在文件中,参数fpath文件路径
for stock in lst:
url = stockURL +stock+'.html'
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html,'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
except:
traceback.print_exc()
continue
def main():
stock_list_url = "http://quote.eastmoney.com/stocklist.html" #获取股票的
stock_info_url = 'https://gupiao.baidu.com/stock/'
outer_file = 'D://BaiduStockInfo.txt' #输出信息保存路径
slist = []
getStockList(slist,stock_info_url)
getStockInfo(slist,stock_info_url,outer_file)
main()