我们曾在《算法效果评估:均方根误差(RMSE)/ 标准误差》一文中介绍过评估算法效果使用的主要方法:均方根误差(RMSE),但在实际应用中,评估算法效果还有更多内容,本文我们以《Hands-On ML》一书第二章中介绍的房价预测案例,细致地介绍一下Sklearn中的度量一个算法表现/效果好坏的手段。
在模型选择阶段,我们通常会尝试不同的算法,然后评估它们的表现,并选择最好的一种算法。这个过程大致可以分为如下几步:
- 第一步:选择一个算法,使用准备好的训练数据进行训练(拟合),得到经过训练的模型(可简单理解为一个函数);
- 第二步:使用模型对数据进行预测,得到预测结果;
- 第三步:将预测结果和准备好的标注数据(labels)进行比对,比对的方法就是计算预测数据和标注数据之间的:均方根误差(RMSE),根据均方根误差的大小来度量算法优劣
然后,使用另一个算法重复上述操作,直至选出最优算法。其中,在第三步的度量过程中,人们首先会想到的做法是:直接拿训练数据做一次预测,看一下均方根误差,因为训练数据是现成的,顺手就可以完成。但是,当我们实际去这样做的时候,很快就会发现这一做法存在“巨大缺陷”,因为很多模型在预测自己的训练数据集时通常都表现得非常好,一旦应用于新数据的预测上,效果就会大幅下滑,这就是所谓的“过拟合”,如果在算法验证阶段不换用一些新数据做一下对比测试,你就无法检测出模型的过拟合问题,换句话说就是:总是使用训练数据进行预测永远无法全面可信地度量算法效果。
这个时候,你可能会想到:我们在数据预处理时不是有切分过训练数据集和测试数据集吗,这时候可以拿来用了呀?确实如此,但是在当下这个阶段(模型选择阶段),还不需要搬出测试数据集),因为仅仅依靠训练数据集1,我们一样有办法来规避这个问题,同时还能更全面有效的进行评估,这套方法的基本思路是:
将训练数据集切分成n等份,以10份为例,保留1份(10%)作为测试数据,使用另外9份(合在一起,90%)数据训练模型,训练完成后用那1份预留数据进行测试,得到一个评估结果(RMSE),作为模型本轮的得分;然后进行第二轮操作:再次保留1份(10%)测试数据(是此前没被当作测试数据的数据,也就是第一轮9份训练数据中的一份),使用其余9份数据训练模型,训练完成后用这1份预留数据进行测试,得到第二轮的评估结果(RMSE),如此反复,总共可以执行10次验证,进而会得到10个成绩(RMSE)。我们可以观察这10次测试成绩的均值和标准差,它们能更好的反应算法的效果。(注意:上述切分方方案仅限于模型选择阶段对算法效果的评估上,在模型正式的训练环节,一定是使用全部的训练数据集,已便获得最好的训练效果。)
以上给出的设计思路就是Sklearn中名为“K-fold”的模型效果交差验证功能(一个函数),K-fold就是n等份的意思,用我们的例子说就是“10等份”交叉验证。以下是《Hands-On ML》一书第二章使用K-fold交差验证法评估决策树在预测房价上的性能表现:
from sklearn.model_selection import cross_val_score
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)
其中,cv指定了切分的份数,也就决定了验证的轮数,进而决定了结果数组tree_rmses的元素数量。scoring是指定打分标准,这里选择的是“负的均方根误差”(neg指的是negtive),为什么是负的呢?因为没有正的!这里有一个Sklearn的知识点:在scoring的可选值列表中,只有neg_root_mean_squared_error,没有root_mean_squared_error,原因是:Sklearn的cross-validation期望所有的评估保持一致的风格和习惯,即:数值越大表示效果越好(greater is better,在对于按得分排序非常友好),正是出于这种约定,Sklearn只提供“负的均方根误差”,因为均方根误差都是正值,且其值越小表示算法效果越好,为了适配上述规则(也便于按分数排序),所以故意取了均方根误差的负值。实际上,Sklearn中所有值越小表示效果越好的度量值都附加了求负运算,并在名称前追加了neg前缀以示区分:
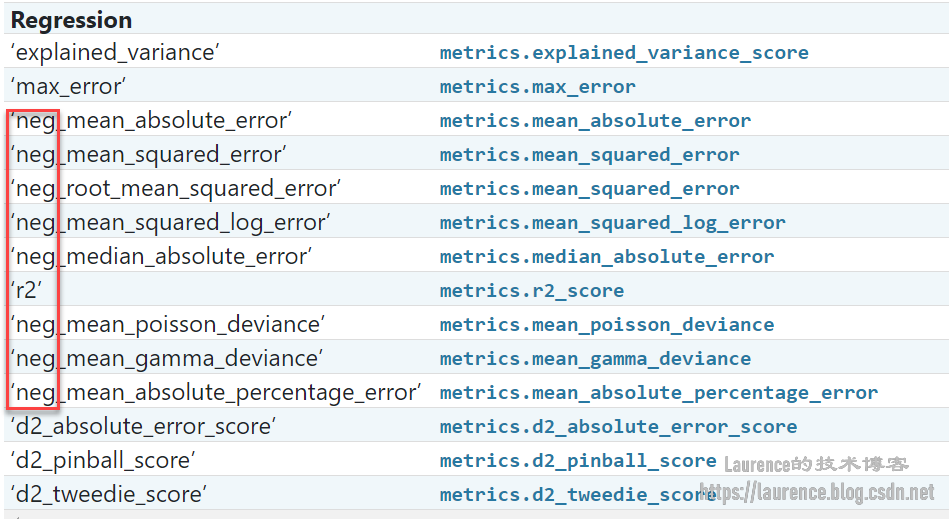
如果是输出给人看,只要简单地在负值上再做一次求负操作,负负得正,就拿到标准的均方根误差了,就像上面示例代码中那样。
《Hands-On ML》在第2版时只使用训练数据集做cross-validation,但是到了第3版就使用全体(训练+测试)数据集进行验证了,因为这只发生在验证阶段,对正式的模型训练没有影响,所以,本着数据量越大效果越好的原则,第3版使用全体(训练+测试)数据集进行验证其实是更好的 ↩︎