文章目录
- week47 CF-LT
- 摘要
- Abstract
- 1. 题目
- 2. Abstract
- 3. 网络结构
- 3.1 CEEMDAN(完全自适应噪声集合经验模态分解)
- 3.2 CF-LT模型结构
- 3.3 SHAP
- 4. 文献解读
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
- 5. 结论
- 6.代码复现
- 小结
- 参考文献
week47 CF-LT
摘要
本周阅读了题为Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water的论文。该文提出了一个用于 TP 预测的混合模型。文提出了一种针对TP预测的混合模型,即CF-LT模型。该模型创新地将完整集成经验模式分解(EMD)与自适应噪声处理、模糊熵分析、长短期记忆网络(LSTM)以及Transformer技术相结合。通过引入数据分频重构技术,该模型有效地解决了传统机器学习模型在处理高维数据时容易出现的过拟合和欠拟合问题。同时,注意力机制的应用使得CF-LT模型能够克服其他模型在进行长期预测时难以建立数据间长期依赖关系的局限性。预测结果显示,CF-LT模型在测试数据集上达到了0.37至0.87的决定系数(R2),相比控制模型有了0.05至0.17(即6%至85%)的显著提升。此外,CF-LT模型还展现出了最佳的峰值预测性能。
Abstract
This week’s weekly newspaper decodes the paper entitled Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water. This paper introduces a hybrid model, CF-LT, specifically for TP prediction. The model innovatively integrates Complete Ensemble Empirical Mode Decomposition (EMD) with adaptive noise processing, fuzzy entropy analysis, Long Short-Term Memory (LSTM) networks, and Transformer technology. By introducing data frequency division and reconstruction, CF-LT effectively addresses the issues of overfitting and underfitting that traditional machine learning models often encounter when dealing with high-dimensional data. Additionally, the application of the attention mechanism enables CF-LT to overcome the limitations of other models in establishing long-term dependencies between data points during long-term predictions. The prediction results demonstrate that CF-LT achieves a decision coefficient (R2) ranging from 0.37 to 0.87 on the test datasets, representing a significant improvement of 0.05 to 0.17 (or 6% to 85%) compared to the control models. Furthermore, CF-LT provides the best peak prediction performance.
1. 题目
标题:Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water
作者:Jiefu Yao, Shuai Chen, Xiaohong Ruan
发布:Journal of Hydrology Volume 629, February 2024, 130609
链接:https://www.sciencedirect.com/science/article/pii/S0022169424000039?via%3Dihub
2. Abstract
该文提出了一个用于 TP 预测的混合模型。该模型 (CF-LT) 将完整集成经验模式分解(EMD)与自适应噪声、模糊熵、长短期记忆和 Transformer相结合。数据分频重构的引入有效解决了以往机器学习模型面对高维数据时出现的过拟合和欠拟合问题,而注意力机制则克服了这些模型无法建立数据之间长期依赖关系的问题在进行长期预测。预测结果表明,CF-LT 模型在测试数据集上实现了 0.37-0.87 的决定系数 (R2),比控制模型提高了 0.05-0.17 (6%-85%)。此外,CF-LT 模型提供了最佳的峰值预测。
3. 网络结构
3.1 CEEMDAN(完全自适应噪声集合经验模态分解)
作为一种先进的时间序列分析方法,CEEMDAN通过在经验模态分解(EMD)过程中加入自适应噪声,有效减少了传统EMD中存在的模式混叠问题。它能将原始信号分解为一系列固有模态函数(IMFs),每个IMF代表信号的不同时间尺度特征,从而使得复杂信号的分析更加直观和准确。在本研究中,CEEMDAN用于处理来自泰湖三个监测站的每日水质数据,将总磷浓度与其他水质参数如水温、pH值、溶解氧等分离成不同频带的信号。
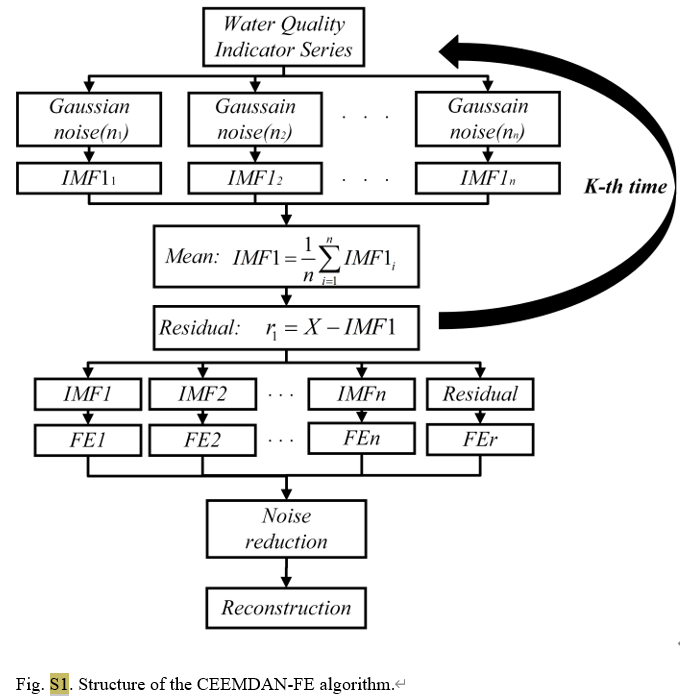
Algorithm S1: Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
- 定义运算符 E K ( ∼ ) E_K(\sim) EK(∼),该运算符生成 EMD 算法的 Kth 模式。 v t i v_t^i vti设为高斯白噪声, ϵ \epsilon ϵ为白噪声系数, i i i为添加白噪声的指数。EMD用于分解数据,并根据方程(S1)将高斯白噪声加入原始信号y(t)后,取第一本征模态函数(IMF)分量( I M F 1 ‾ \overline{IMF1} IMF1)。第一种模式使用方程(S2)计算。
y i ( t ) = y ( t ) + ϵ 0 v i ( t ) i = 1 , 2 , … , n (S1) y^{i}(t)=y(t)+\epsilon_0v^i(t)\quad i=1,2,\dots,n\tag{S1} yi(t)=y(t)+ϵ0vi(t)i=1,2,…,n(S1)
IMF1 i = E 0 ( y i ( t ) ) + r 1 i IMF1 ‾ = 1 n IMF1 i (S2) \text{IMF1}_i=E_0(y^i(t))+r^i_1\quad \overline{\text{IMF1}}=\frac1n\text{IMF1}_i\tag{S2} IMF1i=E0(yi(t))+r1iIMF1=n1IMF1i(S2)
- 使用方程(S3)计算第一个信号分解的残差。根据方程(S4)加入新的白噪声,并计算第二个IMF分量(S4)。
r 1 = y i ( t ) − IMF1 ‾ (S3) r_1=y^i(t)-\overline{\text{IMF1}}\tag{S3} r1=yi(t)−IMF1(S3)
IMF2 ‾ = 1 n ∑ i = 1 n E 1 ( r 1 + ϵ 1 E 1 ( v i ( t ) ) ) (S4) \overline{\text{IMF2}}=\frac1n\sum^n_{i=1}E_1(r_1+\epsilon_1E_1(v^i(t))) \tag{S4} IMF2=n1i=1∑nE1(r1+ϵ1E1(vi(t)))(S4)
- 重复步骤 1 和 2,直到残差r_k为单调函数。最后,应用 EMD 得到 K−1th IMF 级数,即原始级数组成,如:
y ( t ) = ∑ l = 1 K − 1 IMF1 ‾ + r K (S5) y(t)=\sum^{K-1}_{l=1}\overline{\text{IMF1}}+r_K\tag{S5} y(t)=l=1∑K−1IMF1+rK(S5)
3.2 CF-LT模型结构
对于CEEMDAN-FE部分,我们首先将原始数据集划分为训练和测试数据集,然后应用CEEMDAN将两个数据集中的每个特征分解为多个内在模式函数(IMF)。根据每个 IMF 的 FE 值的接近程度,将它们重构为高频 (IMFH)、中频 (IMFM)、低频 (IMFL) 和趋势项 (IMFT) 分量,这些分量反映了 IMF 的不同方面。
对于LSTM-Transformer部分,在编码器和解码器中,LSTM的隐藏层被Transformer位置编码代替,以建立输入数据之间的时间依赖性。具体计算过程如下(图2a)。
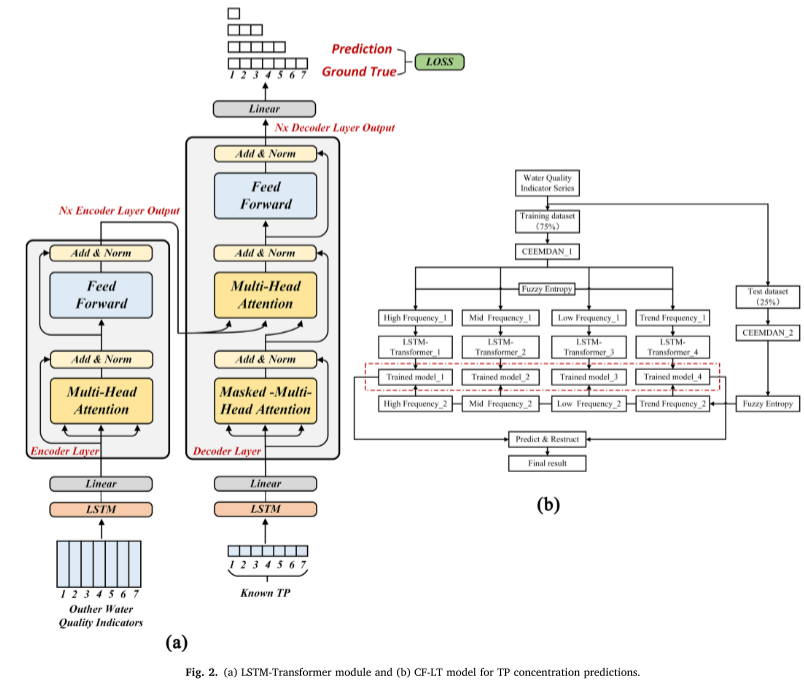
- 模型输入包含两个特征输入。本研究中,编码器层包含水温(WT)、pH(PH)、溶解氧(DO)、化学需氧量(COD)、电导率(EC)、浊度(TU)、氨氮(NH3-N) ,以及第一个预测时间点前 7 天获取的时间序列形式的总氮 (TN) 数据。解码器层包含第一个预测时间点前7天的TP时间序列。
- 经过LSTM和线性层后,两个特征数据集分别被送入编码器层和解码器层。
- 两个子层组成编码器层。多头注意力层计算输入特征的注意力矩阵,然后前馈层改变数据维度。最后,数据被输入到下一个编码器或解码器层。
- 三个子层组成解码器层。在屏蔽多头注意力层计算出输入特征的注意力矩阵之后,多头注意力层根据编码器层的输出建立注意力连接。前馈层将其传递到下一个解码器层或线性层以获得最终的模型输出。
3.3 SHAP
SHAP 是一种博弈论方法,用于解释任何 ML 模型的输出。为了确定输入特征对模型输出的影响,输入特征
z
=
[
z
1
,
.
.
.
,
z
p
]
z = [z1, ..., zp]
z=[z1,...,zp] 与训练后的深度学习模型 F 相关。
F
=
f
(
z
)
=
ϕ
0
+
∑
i
=
1
M
ϕ
i
z
i
(12)
F=f(z)=\phi_0+\sum_{i=1}^M \phi_iz_i \tag{12}
F=f(z)=ϕ0+i=1∑Mϕizi(12)
φ
i
∈
R
φ_i ∈ R
φi∈R表示每个特征对模型的贡献度,由下式给出:
ϕ
i
(
F
,
x
)
=
∑
z
≤
x
∣
z
∣
!
(
M
−
∣
z
∣
−
1
)
!
M
!
[
F
(
z
)
−
F
(
z
/
i
)
]
(13)
\phi_i(F,x)=\sum_{z\leq x}\frac{|z|!(M-|z|-1)!}{M!}[F(z)-F(z/i)] \tag{13}
ϕi(F,x)=z≤x∑M!∣z∣!(M−∣z∣−1)
4. 文献解读
4.1 Introduction
该研究提出了一种预测总磷浓度的新模型。该模型结合了 CEEM DAN、FE、LSTM 和 Transformer 技术,并使用 SHAP 来解释模型输出。该研究的主要目标是评估提出的 CEEMDAN-FE-LSTM-Transformer (CF-LT) 模型在预测太湖入口处 TP 浓度方面的性能,并应用 SHAP 来解释 CF-LT 模型的输出。这应该揭示影响该地区TP浓度的关键因素及其响应机制。
高维数据分解可能会产生大量模态分量。为了解决这个问题,模糊熵(FE)是一种计算时间复杂度的有效方法,可以与 CEEMDAN 结合起来。这种组合有效地重构了CEEMDAN分解后的子信号,从而减少了子频率模型的数量。
LSTMTransformer 模型可以捕获非相邻时间点之间的关系,同时保留输入数据的时间序列特征。
Transformer 模型使用注意机制来识别训练期间特定上下文中两个位置之间的相关性。这使得能够有效获取相关数据并减少信息冗余。
4.2 创新点
该文的主要贡献有四个方面:
- 提出的模型将模态分析与深度学习方法结合,使用模糊熵降低模态分解对时间复杂度的影响,将LSTM与Transformer结合构建数据中的长期、短期依赖关系。
- 将应用LSTM、Transformer的混合模型用于预测总磷 TP,这是在以往研究中没有做到的。
- 预测结果表明,CF-LT 模型在测试数据集上实现了 0.37-0.87 的决定系数 (R2),比控制模型提高了 0.05-0.17 (6%-85%)。此外,CF-LT 模型提供了最佳的峰值预测。
4.3 实验过程
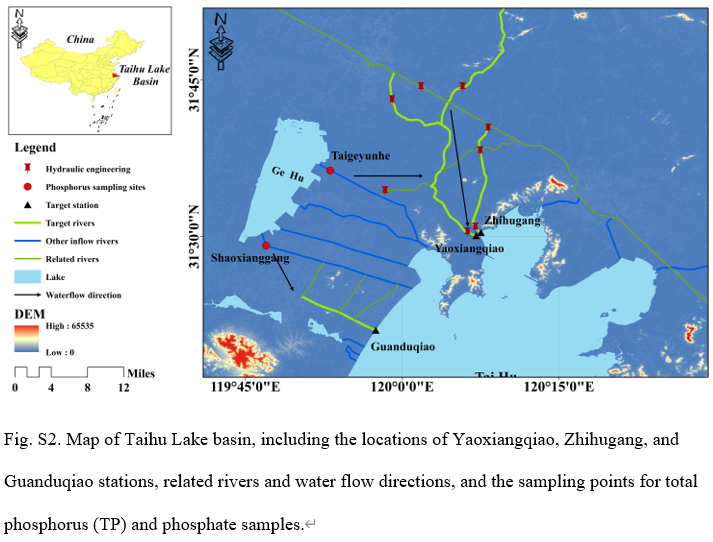
数据集:太湖流域位于长江下游,面积3.69万平方公里,河网密布,湖泊众多。太湖是典型的浅水湖。盆地具有北亚热带湿润气候特征,年平均气温15~17℃,年平均降水量1181毫米。本研究使用了药香桥站、枝虎岗站和官渡桥站的水质监测数据(图S2)。这些监测站位于国家重点水质评价断面——太湖口。数据来源于江苏省环境监测中心。
评估标准:模型的性能评估采用了几项关键指标:决定系数(R²),均方误差(MSE),以及平均绝对百分比误差(MAPE)。R²衡量模型预测值与实际值的拟合程度,接近1表示模型预测能力强;MSE衡量预测误差的平方和,值越小说明预测误差越小;MAPE则从百分比角度反映预测误差的大小,值越低意味着预测越准确。
实施细节:实验过程包括数据预处理、模型训练和测试。建立了一个完整的实验程序,以评估所提出的模型在不同的数据集和预测时间窗口的性能。首先,数据经过CEEMDAN-FE方法进行预处理,通过添加自适应噪声的完全集成经验模态分解去除信息干扰,提取多尺度信息,并利用模糊熵降低子信号的数量。接着,将处理后的数据按75%和25%的比例分为训练集和测试集。训练阶段,将预处理的训练数据集输入到LSTM-Transformer模型。使用反向传播和Adam优化器更新模型权重,并采用网格搜索来识别LSTMTransformer模块的最佳超参数,确保模型在不同预测时间窗口(7天、5天、3天、1天)下的性能最佳。
实验结果:将最佳训练模型应用于测试数据集,表总结了CF-LT、LSTM、Transformer、CF-L和CF-T模型在不同站点和不同预测时间窗下给出的TP浓度预测。所提出的CF-LT模型给出了所有三个评估指标的最佳结果。就R2而言,CF-LT模型的范围为0.37至0.87,而次佳的CF-L和CF-T模型分别为0.32-0.84和0.35-0.86。这表明,将LSTM的长期记忆与Transformer的注意力机制相结合,可以提高预测精度。将最差的LSTM和Transformer模型与CF-L和CF-T模型进行比较,MAPE的范围从8.94%-20.62%(LSTM)和8.91%-18.73%(Transformer)变为8.29%-19.56%(CF-L)和7.82%-17.55%(CF-T)。这些结果表明,数据分解和分频建模通过捕获更多隐藏在原始数据中的信息来显着提高预测准确性。
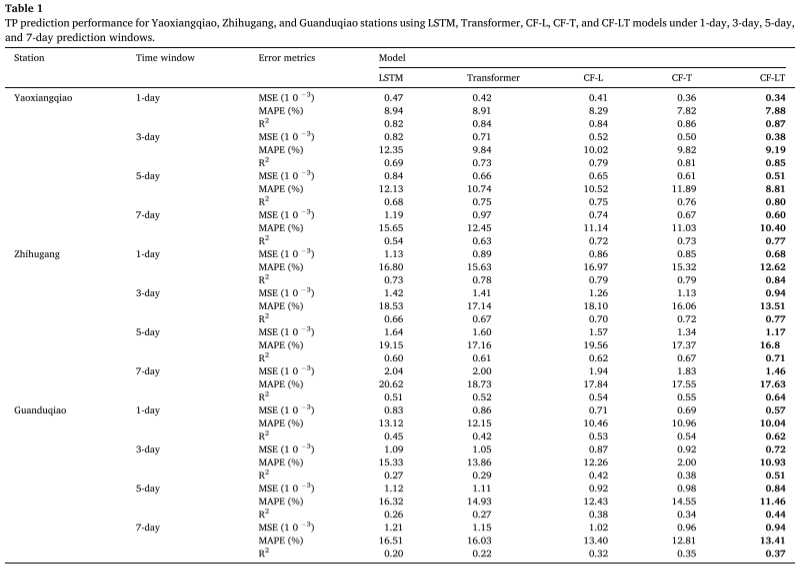
影响总磷TP浓度因素预测:
采用平均绝对SHAP值(MASV)量化输入特征(WT、PH、DO、COD、EC、TU、TN、NH3-N、TP)对TP预测结果的贡献程度,MASV越大,对模型预测结果的影响越大。研究表明,除了过去的TP浓度序列本身,总氮(TN)和浊度(TU)是影响TP预测的两个主要因素。这表明,TP的变化不仅受历史浓度的直接影响,还与非点源污染排放及水体中氮磷比相关联的藻类生长动态紧密相关。特别是,TN与TP之间的显著相关性,强调了两者在湖泊营养盐循环中的耦合效应,突显了非点源氮输入对磷浓度预测的重要性。
从这些结果中,可以得到以下观察结果:
- 就公平性指标而言,许多现有的 GNN 在所有三个数据集上的 MLP 模型都表现不佳。例如,在 Pokec-z 数据集上,MLP 的人口统计奇偶性比 GAT、GCN、SGC 和 APPNP 低 32.64%、50.46%、66.53% 和 58.72%。较高的预测偏差来自于相同敏感属性节点内的聚合和图数据中的拓扑偏差。
- FMP 在所有数据集的人口平等和机会均等方面始终实现最低的预测偏差。具体而言,与 Pokecz、Pokec-n 和 NBA 数据集中所有基线中的最低偏差相比,FMP 将人口统计均等性降低了 49.69%、56.86% 和 5.97%。同时,FMP 在 NBA 数据集中实现了最佳精度,在 Pokec-z 和 Pokec-n 数据集中达到了相当的精度。简而言之,所提出的 FMP 可以有效减轻预测偏差,同时保持预测性能。
与对抗性去偏和正则化的比较:随机划分 50%/25%/25% 用于训练、验证和测试数据集。图 2 显示了所有方法的帕累托最优曲线,其中右下角点代表理想性能(最高准确度和最低预测偏差)。
5. 结论
该文提出的 CF-LT 混合模型结合了 CEEM DAN、FE、LSTM 和 Transformer 模块,能够预测地表水中的 TP 浓度。这种混合方法解决了高维数据导致的模型过拟合和欠拟合的缺点以及在进行长期预测时无法建立数据之间的长期依赖关系。此外,SHAP 值用于解释 CF-LT 模型的输出。
该模型应用太湖流域三个水质监测站的数据,输出不同预测时间窗口的9个水质指标。采用 LSTM、Transformer、CF-L 和 CF-T 算法作为控制模型。 CF-LT 模型在测试数据集上的 R2 值为 0.37–0.87,MSE 值为 0.34 × 10−3–1.46 × 10−3,MAPE 值为 7.88 %-17.63 %,这表明所有三个指标均比LSTM、Transformer、CF-L 和 CF-T 结果。所提出的CF-LT模型也产生了最好的峰值预测结果。基于SHAP解释,我们发现TU和TN(不包括TP浓度的早期时间序列)是影响TP预测的重要因素,这表明TP的变化不仅与TP浓度的早期水平有关,而且还受到TP浓度的影响。面源污染排放与太湖入海口水生植物的N、P关系。此外,值得注意的是,TN和TU对雨季TP浓度预测的贡献更大。因此,本研究的结果表明,CF-LT模型为理解不同环境条件变化时TP的响应机制提供了额外的信息。
6.代码复现
CEEMDAN和FE数据预处理
def ceemdan_fe_preprocessing(data):
# CEEMDAN分解
imfs, residue = ceemdan(data, **ceemdan_params)
# 计算各个IMF的模糊熵
fe_values = []
for imf in imfs:
fe_values.append(fuzzy_entropy(imf)) # 假定fuzzy_entropy为计算模糊熵的函数
# 根据FE值重组IMFs
imfs_sorted = [imf for _, imf in sorted(zip(fe_values, imfs))]
imf_hf, imf_mf, imf_lf, imf_trend = imfs_sorted[:4], imfs_sorted[4:8], imfs_sorted[8:12], imfs_sorted[12:]
return np.concatenate((imf_hf, imf_mf, imf_lf, imf_trend), axis=1)
# 应用到数据上
preprocessed_data = ceemdan_fe_preprocessing(original_data)
LSTM&Transformer
def get_positional_encoding(max_len, d_model):
pe = np.zeros((max_len, d_model))
position = np.arange(0, max_len).reshape(-1, 1)
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
def transformer_encoder(inputs, d_model, num_heads, ff_dim):
x = MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(inputs, inputs)
x = LayerNormalization()(Add()([inputs, x]))
x = Dense(ff_dim, activation='relu')(x)
x = Dense(d_model)(x)
x = LayerNormalization()(Add()([inputs, x]))
return x
def transformer_decoder(inputs, encoder_outputs, d_model, num_heads, ff_dim):
return decoder_output
input_features = Input(shape=(input_shape))
lstm_out = LSTM(lstm_units)(input_features) # LSTM
pos_encodings = get_positional_encoding(max_seq_length, d_model)
transformer_in = Add()([lstm_out, pos_encodings])
transformer_encoded = transformer_encoder(transformer_in, d_model, num_heads, ff_dim)
decoder_output = transformer_decoder(decoder_input, transformer_encoded, d_model, num_heads, ff_dim)
output_layer = Dense(output_dim, activation='linear')(decoder_output)
model = Model(inputs=input_features, outputs=output_layer)
model.compile(optimizer=Adam(learning_rate), loss='mse')
小结
该研究开发了一种可解释的CEEMDAN-FE-LSTM-Transformer混合模型,针对地表水中总磷浓度预测,该模型通过先进的数据预处理技术和深度学习模型的融合,显著提高了预测精度,并通过SHAP提供了清晰的特征解释。实验结果证实了模型的有效性,尤其是对关键环境因素的识别,为水体富营养化管理和污染控制提供了有力的工具。
参考文献
[1] Jiefu Yao, Shuai Chen, Xiaohong Ruan. Interpretable CEEMDAN-FE-LSTM-transformer hybrid model for predicting total phosphorus concentrations in surface water. [J] Journal of Hydrology Volume 629, February 2024, 130609