文章目录
- 1.前言
- 2. 基于事故现场对问题进行分析
- 2.1 日志分析
- 2.2 单独测试Topology代码试图重现问题
- 3. 源码解析
- 3.1 Client模式和Cluster模式下客户端的提交和启动过程
- 客户端提交时在两种模式下的处理逻辑
- ApplicationMaster启动时在两种模式下的处理逻辑
- 3.2 两种模式下的下层角色关系和启动以后的总体运行流程
- TaskScheduler和SchedulerBackend的创建
- DriverEndpoint的处理逻辑
- YarnSchedulerEndpoint的处理逻辑
- 3.3 SparkDriver和ApplicationMaster的通信
- ApplicationMaster的构建
- 3.4 ApplicationMaster和Yarn ResourceManager的通信
- 3.5 Executor的启动以及与Driver通信的建立
- 3.6 Spark的操作与Yarn上的Container状态的对应关系
- 3.7 动态分配的整个通信过程
- Driver根据物理执行计划生成Executor的放置的暗示信息
- Driver向ApplicationMaster发送Task的相关信息
- ApplicationMaster接收Driver的Task资源请求信息
- ApplicationMaster根据Task的请求信息向Yarn请求资源
- 启动Executor并将Task调度上去
- 3.8 Application执行结束以后关闭Executor
- 4. 事故后续处理
1.前言
我们线上一个分钟级的调度任务在正常情况下可以在1分钟之内完成。但是在最近经常超时失败,超时时间达到10min以上。从客户端看到的日志是SparkContext构造时与ApplicationMaster连接超时,似乎是连接问题导致的。后来发现并不是这样。
本文详细记录我们对该问题的处理过程,原理探究以及最后的解决方案。
抛开事故本身,我们从这次事故以及历次事故中得到的经验是:
- 找到根本原因很重要: 找出根本原因是系统越来越稳定、越来越好维护的唯一途径。
- 找到根本原因很耗时:一个开源系统,动辄几百台机器,一个错误往往处于一个很长的工作流中,涉及到很多的不同角色,这些不同的角色之间的关系需要梳理清楚,有些日志才能看懂。
- 并不总能在问题首次发生时找到原因: 在问题首次发生的时候,由于日志缺乏、现场缺乏等原因,我们往往无法定位到根本原因,这个特别正常。但是,着并不意味着我们无事可做,我们必须为在下一次问题出现的时候找到原因做好准备,比如,缩小怀疑范围的情况下添加关键日志,梳理一个问题再次发生的时候保存现场的流程(堆栈,内存dump,日志备份)等。
- 根本原因和表面的异常很可能南辕北辙:对于一个复杂的开源系统,一次事故的根本原因往往和最初呈现出来的现象不同,甚至南辕北辙;所以,在定位到根本原因以前进行合理的推测并采取行动去验证很重要,但是,不看一行日志、不看一行代码、不做一点儿测试的空对空的推测和讨论毫无意义,浪费时间。
- 即使不能找到根本原因,也可以在根本原因层面消除问题: 在我们的case中,我们没有找到机器具体发生了什么问题,但是,至少我们能确定是这台机器的问题并且关闭这台机器,那么这个操作是在根本原因层面消除了问题,也是在这个事故中我们能采取的最好的办法
- 最好能确定在第二次发生问题的时候定位到原因:在事故首次发生的时候,由于日志不足、现场丢失而无法定位根本原因,但是基于事后对代码的分析缩小了怀疑范围,通过增加的日志提供了更多信息,通过梳理好的事故处理流程来准确保存现场,我们因此能够确保在事故第二次发生的时候定位到根本原因,那么对这一次事故的处理就已经非常完美了。不苛求在事故首次发生的时候就找到根本原因,这也不现实。
- 影响稳定性的往往只有有限的几个bug:一个复杂的开源系统可能有无数的bug,但是在我们的使用场景下、工作负载下显著影响业务正常运行的bug可能并不是很多。在这些bug出现的时候准确地发现他们并解决,系统SLA可能会显著提升。
- 必须严格区分因果关系。对于一个不正常现象,比如负载变高,连接超时等等,必须清楚地区分出这是导致问题的原因还是问题导致的结果。这个区分不好,会误导我们往错误的方向越走越远,离根本原因越来越远。
2. 基于事故现场对问题进行分析
2.1 日志分析
下面讲述了我们对这个事故的分析过程。请注意,我们对整个事故的分析、定位的过程依赖了很多Spark和Yarn本身的知识,尤其是对照日志、代码进行事故定位,这些知识很多事在后来进行事故复盘的时候获取的。由此可见,解决事故和分析事故根本原因其实是两件不同的事情。
我们的分钟级Spark任务由Airflow进行调度,采用Client模式运行,即,ssh到指定的一台机器上运行Driver进程,Driver进程与ResourceManager通信,提交应用程序,Yarn会在集群中启动ApplicationMaster,然后Driver与ApplicationMaster通信,进行资源调度等等。
我们从客户端看到的问题是,SparkContext在构造的时候发生超时:
我们首先在Driver端看到的异常日志如下:
org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:47)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:62)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:58)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:76)
at org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.requestTotalExecutors(CoarseGrainedSchedulerBackend.scala:567)
at org.apache.spark.ExecutorAllocationManager.updateAndSyncNumExecutorsTarget(ExecutorAllocationManager.scala:344)
at org.apache.spark.ExecutorAllocationManager.org$apache$spark$ExecutorAllocationManager$$schedule(ExecutorAllocationManager.scala:295)
at org.apache.spark.ExecutorAllocationManager$$anon$2.run(ExecutorAllocationManager.scala:234)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [120 seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:201)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
... 11 more
...
[2024-04-25 09:00:40,857] {ssh_operator.py:133} INFO - 24/04/25 09:00:40 WARN netty.NettyRpcEnv: Ignored failure: org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply from null in 120 seconds. This timeout is controlled by spark.rpc.askTimeout
[2024-04-25 09:00:40,897] {ssh_operator.py:133} INFO - 24/04/25 09:00:40 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
[2024-04-25 09:00:55,897] {ssh_operator.py:133} INFO - 24/04/25 09:00:55 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
从日志可以看到,Driver由于2min的通信超时,启动两分钟以后就失败并退出了。
我们首先排除了Yarn本身的问题:
- SparkContext的超时问题在历史上偶尔出现,我们统计发现,只要SparkContext的构造超时,ApplicationMaster一定运行在某一台指定的机器上
- 并且, 我们运行这个关键任务的Yarn集群没有其它任务运行,是一个独立的隔离的Yarn集群,因此不会出现资源不够用、资源预留导致即使有可用资源也不给其它应用分配资源的情况
- 在事故发生的时候,我们立刻向Yarn提交了测试应用,应用正常运行并成功结束。
- 后面我们从日志可以看到,所有Container的状态都停留在ALLOCATED状态,即资源已经分配,只要ApplicationMaster进行换一次allocate()调用来认领这些已经分配的Container,这些Container的状态就会切换到ACQUIRED的预期状态。
- 如果ApplicationMaster本身没有Hang住,Driver和ApplicationMaster通信就不会Timeout
种种分析都将问题指向ApplicationMaster。
这个Driver端的RPC的默认超时时间是120s,似乎看起来是网络通信问题。但是,在很多情况下,Timeout也有可能是服务端GC导致了STW(Stop the World)从而无法响应客户端请求导致的。但是120s的STW却看起来不是特别合理。后面我们看到,这个Timeout很可能是ApplicaitionMaster的并发控制导致的,即这个RPC请求在ApplicaitonMaster端所调用的方法无法获得某个锁,而ApplicaitonMaster端获得锁的线程又出于某种原因无法结束。
在Client模式下,Driver端通过CoarseGrainedSchedulerBackend(区别Executor端的CoarseGrainedExecutorBackend)与ApplicationMaster进行通信。 我们看了一下CoarseGrainedSchedulerBackend.requestTotalExecutors()中,找到了ApplicationMaster对应的Container的日志,看看是否能有有用信息,对应日志如下所示:
24/04/25 08:57:17 INFO client.RMProxy: Connecting to ResourceManager at rccp102-8h.iad3.prod.conviva.com/10.6.6.123:8030
24/04/25 08:57:17 INFO yarn.YarnRMClient: Registering the ApplicationMaster
24/04/25 08:57:17 INFO util.Utils: Using initial executors = 112, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instan
ces
24/04/25 08:57:17 INFO yarn.YarnAllocator: Will request 112 executor container(s), each with 5 core(s) and 5940 MB memory (including 540 MB of overhead)
24/04/25 08:57:17 INFO yarn.YarnAllocator: Submitted 112 unlocalized container requests.
24/04/25 08:57:17 INFO yarn.ApplicationMaster: Started progress reporter thread with (heartbeat : 3000, initial allocation : 200) intervals
24/04/25 08:59:18 INFO yarn.ApplicationMaster$AMEndpoint: Driver terminated or disconnected! Shutting down. rccp102-8h.iad3.prod.conviva.com:43611
24/04/25 08:59:18 INFO yarn.ApplicationMaster: Final app status: SUCCEEDED, exitCode: 0
24/04/25 08:59:18 INFO yarn.ApplicationMaster$AMEndpoint: Driver terminated or disconnected! Shutting down. rccp102-8h.iad3.prod.conviva.com:43611
24/04/25 09:09:08 ERROR yarn.ApplicationMaster: RECEIVED SIGNAL TERM
24/04/25 09:09:08 INFO yarn.ApplicationMaster: Unregistering ApplicationMaster with SUCCEEDED
对于历史上成功执行的同一任务的日志如下:
24/06/12 15:10:14 INFO yarn.YarnAllocator: Submitted 112 unlocalized container requests.
24/06/12 15:10:14 INFO yarn.ApplicationMaster: Started progress reporter thread with (heartbeat : 3000, initial allocation : 200) intervals
24/06/12 15:10:15 INFO yarn.YarnAllocator: Launching container container_1715242483615_49376_01_000002 on host rccp103-10a.iad3.prod.conviva.com for executor with ID 1
24/06/12 15:10:15 INFO yarn.YarnAllocator: Launching container container_1715242483615_49376_01_000003 on host rccp103-10a.iad3.prod.conviva.com for executor with ID 2
24/06/12 15:10:15 INFO yarn.YarnAllocator: Launching container container_1715242483615_49376_01_000004 on host rccp103-10a.iad3.prod.conviva.com for executor with ID 3
对比失败应用和成功应用,可以看到,失败应用的ApplicationMaster在启动2min以后就知道了Driver已经不在了。但是随后跟ResourceManager的通信过程中有10分钟左右(08:59 ~ 09:09)没有任何的日志。正常情况下,应该打印Launching container日志正常启动Container。
这10分钟的停顿时间很容易让我们认为是Full GC导致的停顿,因此Driver在跟ApplicationMaster通信的时候也超时了。但是我们并没有为ApplicationMaster打开GC日志。凭借一般经验,发生full gc似乎也不太可能,ApplicationMaster的代码是Spark的代码,没有任何的用户业务层逻辑,因此内存消耗应该是很稳定的。
所以,此时整个事件的基本轮廓是:
-
Driver会向Yarn 提交应用,Yarn启动对应的ApplicationMaster,这个Spark 的ApplicationMaster的Class是提交应用的时候指定的,是Spark自己定制的ApplicationMaster,其定义在
org.apache.spark.deploy.yarn.ApplicationMaster中; -
随后,在ResourceManager端,我们看到这个Application的所有Container的状态都变成了ACQUIRED状态,这是Container被Kill以前的最后一个健康的状态:
2024-04-25 08:57:17,960 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1700028334993_233460_01_000035 Container Transitioned from ALLOCATED to ACQUIRED 2024-04-25 08:57:17,960 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1700028334993_233460_01_000036 Container Transitioned from ALLOCATED to ACQUIRED -
ApplicationMaster在Yarn上的某个节点启动起来以后,Driver在方法
CoarseGrainedSchedulerBackend.requestTotalExecutors()中通过RPC与ApplicationMaster通信,这个RPC请求的超时时间是2min。2min超时,通信失败,Driver自行退出。org.apache.spark.rpc.RpcTimeoutException: Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout -
2min以后,ApplicationMaster感知到了Driver的退出(底层的RPC连接断开),因此ApplicationMaster主动触发和Driver之间的断开连接:
24/04/25 08:59:18 INFO yarn.ApplicationMaster$AMEndpoint: Driver terminated or disconnected! Shutting down. rccp102-8h.iad3.prod.conviva.com:43611 -
又过了10分钟,即ApplicationMaster启动12分钟以后(距离上次的活跃时间是10min),ApplicationMaster进程也退出了。这个退出在ResourceManager端的日志如下。
2024-04-25 09:09:07,974 INFO org.apache.hadoop.yarn.util.AbstractLivelinessMonitor: Expired:appattempt_1700028334993_233460_000001 Timed out after 600 secs显然,这个退出是由于ApplicationMaster的Liveness没有了心跳,因此ResourceManager主动将这个ApplicationMaster杀死,并试图启动第二个ApplicationMaster。这个ApplicationMaster的静默时间是由
yarn.am.liveness-monitor.expiry-interval-ms配置的,默认是10min,与实际的现象吻合。
那么, 心跳是在哪里发送的呢? ApplicationMaster的Heartbeat消息并没有专门的接口发送给Yarn,而是通过以下接口进行辅助发送的:- 注册ApplicationMaster的registerApplicationMaster接口
- 用来获取资源分配结果的allocate()接口
- 结束ApplicationMaster的finishApplicationMaster()接口
由于registerApplicationMaster()和finishApplicationMaster()都只是在AM的生命周期开始和结束的时候才会调用,因此,频繁不断的心跳其实是通过allocate()接口来实现的。
allocate()接口是ApplicationMaster用来将相应的资源请求发送给Yarn,Yarn会将该调用视为一次心跳,同时在响应中放置新分配的Container的信息给ApplicationMaster。可以看出来,allocate()接口的调用是可以随时、随意进行的,也可以不携带任何资源请求信息,但是必须独立、不断调用以维持自己在ResourceManager中的liveness。
ResourceManager用来监控ApplicationMaster的存活,是在AbstractLivelinessMonitor中实现的,一个独立线程,不断检查所有的ApplicationMaster的最近心跳是否超过配置时间,查过了则会Kill这个ApplicationMaster。心跳的更新是通过receivedPing()方法进行的:
public synchronized void receivedPing(O ob) { //only put for the registered objects if (running.containsKey(ob)) { running.put(ob, clock.getTime()); } }在allocate()方法被调用的时候,会调用receivePing()方法来更新最近的心跳时间:
@Override public AllocateResponse allocate(AllocateRequest request) throws YarnException, IOException { ........ this.amLivelinessMonitor.receivedPing(appAttemptId);所以,我们可以看到,从Driver这一端,因为连接到ApplicationMaster而无法响应,从而在2min以后就退出了。从ResourceManager这一端,同样因为10min都没有再收到ApplicationMaster的心跳而认为ApplicationMaster不再存活,因此将ApplicationMaster kill掉。所以基本可以认为ApplicationMaster的代码在某个位置hang住了。
后面我们会讲到,ApplicationMaster通过调用YarnAllocator. allocateResources() 进行资源请求的生成和申请,以及从Yarn中获取资源分配的结果:
--------------------------------------- YarnAllocator ------------------------------------
def allocateResources(): Unit = synchronized {
/**
* 这个方法没有任何返回值,主要是通过YarnClient发送amClient.addContainerRequest,这个请求里面的ContainerRequerst是根据当前的本地性要求的统计带有locality信息的。
* 真正获取container分配结果的是方法 amClient.allocate
*/
updateResourceRequests() // 这个方法会打印日志 Submitted 112 unlocalized container requests,在出问题的机器上打印了
val progressIndicator = 0.1f
/**
* 在updateResourceRequests()方法中调用了addContainerRequest()以后,会调用allocate()方法
* 调用了allocate()以后,RM端container的状态会变成acquired的状态
*/
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
// 这会打印日志 Launching container 和 Received %d containers from YARN, launching executors on
// 在出问题的机器上都没打印
handleAllocatedContainers(allocatedContainers.asScala)
}
- YarnAllocator. allocateResources() 会先通过
YarnAllocator.updateResourceRequests()来生成对应的资源请求,但是这些请求会暂存在AMRMClient, - 随后,Spark端的
YarnAllocator. allocateResources()中会调用Yarn的APIAMRMClient.allocate()进行资源的请求 AMRMClient.allocate()方法调用发送资源请求以后,Yarn会在对应的response中返回新分配的Container,这些Container的状态都会因此从ALLOCATED进入ACQUIRED状态,代表这个Container已经被ApplicationMaster确认。- Spark随后从
AMRMClient.allocate()的Response中取出已经分配了资源的Container(对应了Yarn端已经进入ACQUIRED状态的Container),和Container对应的NodeManager通信,启动对应的Container:handleAllocatedContainers(allocatedContainers.asScala)
但是事故发生的时候,所有CONTAINER的状态停留在ACQUIRED状态,无法正常进入RUNNING状态,我们据此基本上可以认为,allocate()由于ApplicationMaster端被阻塞在某个地方,而没有完成handleAllocatedContainers()方法的调用以在NodeManager上启动Container。
关于ApplicationMaster的allocateResources()的调用时机,该方法会在ApplicationMaster启动的时候被调用一次,随后就会有一个专门的ReporterThread定期反复调用allocateResources()。
下面的日志说明,在ApplicationMaster启动的时候,YarnAllocator. allocateResources() -> YarnAllocator.updateResourceRequests() -> YarnAllocator.updateResourceRequests()方法的确调用了一次。
24/04/25 08:57:17 INFO yarn.YarnAllocator: Submitted 112 unlocalized container requests.
同时,所有的Container都进入了ACQUIRED状态,说明Spark的ApplicationMaster在启动的时候已经通过调用AMRMClient.allocate()方法将资源请求发送给了Yarn。因为这时候的ApplicationMaster刚启动,由于Yarn这一端的资源分配是异步的,所以即使立刻调用了allocate()方法,肯定也不会有Container已经分配成功从而进入ACQUIRED状态。所以,我们断定,所有Container既然能够进入ACQUIRED状态,说明后来的ReporterThread启动成功,并且调用成功过一次AMRMClient.allocate()。的确,下面的日志说明, ReporterThread线程的确正常启动:
24/04/25 08:57:17 INFO yarn.ApplicationMaster: Started progress reporter thread with (heartbeat : 3000, initial allocation : 200) intervals
在allocateResources()方法中,会先通过updateResourceRequests()方法生成对应的Resource Request请求,这些请求会保存在Yarn的AMRMClient的本地暂存,然后,通过调用Yarn的allocate()方法,会将暂存的Resource Request发送给Yarn:
def allocateResources(): Unit = synchronized {
updateResourceRequests() // 这个方法会打印日志 Submitted 112 unlocalized container requests,在出问题的机器上打印了
val progressIndicator = 0.1
val allocateResponse = amClient.allocate(progressIndicator)
从这段代码我们可以得到一个重要信息:amClient.allocate() 的调用与updateResourceRequests()无关,即:无论updateResourceRequests()是否生成了新的资源请求放在amClient的本地缓存中,amClient.allocate() 都会被调用。这意味着:即使集群当前没有资源请求,amClient.allocate()也会不断被调用,因为,即使没有资源请求,ApplicationMaster也需要持续保持心跳。
在我们无法梳理清楚Driver端和ApplicationMaster通信的2min超时和所有Container无法从ACQUIRED状态进入RUNNING状态的关联关系的时候,我们突然惊讶地发现了synchronized关键字,即allocateResources()方法是一个同步方法。那么,如果allocateResources()方法出于某种原因Hang住,并且Driver端的调用也会触发这个ApplicationMaster对象的某一个synchronized方法,Driver端就会超时。
通过查看代码,我们确认,Driver端在hang住的API调用的位置,对应在ApplicationMaster上的确和allocateResources()会争抢同一把锁:
Driver端通过RequestExecutors消息向ApplicationMaster请求资源。ApplicationMaster收到RequestExecutors消息以后,会调用requestTotalExecutorsWithPreferredLocalities()方法,并且,这个方法的确是同步方法:
------------------------------------- ApplicationMaster --------------------------------------------
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case r: RequestExecutors => // 申请Executor的请求在这里接收
Option(allocator) match { // 如果已经构建了allocator
case Some(a) => // 只要一收到请求,requestTotalExecutorsWithPreferredLocalities
// 方法理就应该打印日志Driver requested a total number of
if (a.requestTotalExecutorsWithPreferredLocalities(r.requestedTotal,
r.localityAwareTasks, r.hostToLocalTaskCount, r.nodeBlacklist)) {
------------------------------------- ApplicationMaster --------------------------------------------
def requestTotalExecutorsWithPreferredLocalities(
requestedTotal: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int],
nodeBlacklist: Set[String]): Boolean = synchronized {
所以,整个hang住的流程基本就锁定在ApplicationMaster这一端的allocateResources()方法,这个synchronized方法的无法退出,可以全部合理解释下面的问题:
- 为什么所有的Container的状态停留在ACQUIRED状态,无法进入RUNNING状态,即,为什么allocateResources()方法中val allocateResponse = amClient.allocate(progressIndicator)这一行代码被调用以后的代码比如handleAllocatedContainers()似乎hang住了导致allocateResources()无法退出;
- 为什么allocateResources()无法退出会导致Driver连接ApplicationMaster超时,因为ApplicationMaster端处理Driver连接的线程显然跟ReporterThread线程不是同一个线程。
在TODO这篇文章中,我们详细分析了以allocateResources()方法为入口的ApplicationMaster进行资源调度的基本流程。由于日志的缺失,我们根本无从断定ApplicationMaster在方法allocateResources()中hang住的具体位置,但是在分析了allocateResources()整个代码,我们强烈怀疑故障发生在处理分配成功的Container和我们的请求进行匹配比对的过程:
---------------------------------------- YarnAllocator ---------------------------------------
/**
* Handle containers granted by the RM by launching executors on them.
*
* Due to the way the YARN allocation protocol works, certain healthy race conditions can result
* in YARN granting containers that we no longer need. In this case, we release them.
*
* Visible for testing.
* 在这里会打印 Launching container container_1714042499037_5294_01_000002 on host
*/
def handleAllocatedContainers(allocatedContainers: Seq[Container]): Unit = {
val containersToUse = new ArrayBuffer[Container](allocatedContainers.size)
// Match incoming requests by host
.........
// Match remaining by rack
val remainingAfterRackMatches = new ArrayBuffer[Container]
for (allocatedContainer <- remainingAfterHostMatches) {
/**
* SparkRackResolver.
*/
val rack = resolver.resolve(conf, allocatedContainer.getNodeId.getHost)
matchContainerToRequest(allocatedContainer, rack, containersToUse,
remainingAfterRackMatches)
}
......
// Assign remaining that are neither node-local nor rack-local
/**
* 如果Container分配成功,运行到这里,会打印 Launching container container_1714042499037_5294_01_000002 on host。但是失败的应用没有打印这个日志
*/
runAllocatedContainers(containersToUse)
}
这行代码的调用堆栈是YarnAllocator. allocateResources() -> YarnAllocator.handleAllocatedContainers(),即发生在已经通过Yarn的API AMRMClient.allocate() 获取了成功分配的Container以后对这个Container的处理过程,这个过程发生在方法handleAllocatedContainers()中,主要包括:
- 将Yarn分配的Container和我们的资源请求进行一次比对,以确定这些Container是分配给我们那些资源请求的,比对成功的(即这个Container对应了我们的这个资源请求),就可以删除这个资源请求避免重复申请。
- 对于比对成功的Container,ApplicationMaster就可以与这个Container对应的NodeManager通信以启动这个Container。
这个比对的过程是逐渐降级进行的,即先对比Host上匹配的Host-Local Request ,然后比对Rack上匹配的Rack-Local Request,最后再比对没有locality需求的资源请求。在Rack层的比对需要依赖系统的拓扑图解析出Rack信息。
我们怀疑这里的原因是,这个过程会涉及到读取系统的拓扑文件topology.map,我司的DevOps后来发现Ubuntu 16(这台机器的)的一个普遍的bug,这个bug的表现是系统长时间运行会导致系统读写文件变满,通过dd命令进行测试,能够确认读写文件不正常,但是由于我不是操作系统和硬件专家,因此并不清楚这个问题是否是导致ApplicationMaster hang住。下文会详细介绍Spark端对系统拓扑结构进行分析的基本流程。
2.2 单独测试Topology代码试图重现问题
为了确认是否是系统的拓扑脚本导致的超时,我们单独提取了Spark中获取集群拓扑的解析过程的代码,在事发机器上单独运行看看是否会block住。我们查看了这一块儿的Spark逻辑,看到,在这块代码里,Spark作为调用者,其实是使用了Yarn的Library来完成的。因为Yarn在资源分配的时候其实也是Topology-Aware 的 。
SparkResolver的resolve()方法是调用Yarn的RackResolver来分析整个的系统拓扑,这里主要是为了获取这个host的rack:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.yarn.util.RackResolver
import org.apache.log4j.{Level, Logger}
/**
* Wrapper around YARN's [[RackResolver]]. This allows Spark tests to easily override the
* default behavior, since YARN's class self-initializes the first time it's called, and
* future calls all use the initial configuration.
*/
private[yarn] class SparkRackResolver {
def resolve(conf: Configuration, hostName: String): String = {
RackResolver.resolve(conf, hostName).getNetworkLocation()
}
在Yarn这一端,系统的拓扑解析过程需要实现接口 DNSToSwitchMapping,其中最重要的接口是resolve(),传入一系列的主机(或者IP)名称,返回这些主机(IP)的网路位置信息:
public interface DNSToSwitchMapping {
public List<String> resolve(List<String> names);
public void reloadCachedMappings();
public void reloadCachedMappings(List<String> names);
}
在Yarn中,DNSToSwitchMapping的实现类是通过net.topology.node.switch.mapping.impl配置的,默认情况下,Yarn提供的内置实现是ScriptBasedMapping:
package org.apache.hadoop.yarn.util;
......
import com.google.common.annotations.VisibleForTesting;
@InterfaceAudience.LimitedPrivate({"YARN", "MAPREDUCE"})
public class RackResolver {
....
public synchronized static void init(Configuration conf) {
....
Class<? extends DNSToSwitchMapping> dnsToSwitchMappingClass =
conf.getClass(
CommonConfigurationKeysPublic.NET_TOPOLOGY_NODE_SWITCH_MAPPING_IMPL_KEY,
ScriptBasedMapping.class, // 默认的DNSToSwitchMapping实现类
DNSToSwitchMapping.class);
ScriptBasedMapping的行为,是通过在java中执行net.topology.script.file.name所配置的外部脚本文件,来返回系统的拓扑关系。这个配置没有默认值,但是在Cloudera的Yarn中,net.topology.script.file.name配置为topology.py,这个脚本输入对应的hostname的list,返回这些hostname的网络信息。
实际上,ClouderaManager是根据用户配置的集群拓扑关系,生成集群拓扑描述文件topology.map,一个记录了所有Host/IP的rack信息的XML文件,如下所示。在某个Host无法在拓扑描述文件中找到对应信息的情况下,会返回default:
<?xml version="1.0" encoding="UTF-8"?>
<!--Autogenerated by Cloudera Manager-->
<topology>
<node name="lashadoop-17-rack17.hadoop.prod.com" rack="/rack17"/>
<node name="10.72.2.22" rack="/default"/>
<node name="lashadoop-17-rack18.hadoop.prod.com" rack="/rack18"/>
<node name="10.72.1.33" rack="/default"/>
</topology>
我们在下面的代码中调用了Yarn的RackResolver的API,这个API的输入是集群中的hostname,然后输出这个hostname的机架信息等拓扑信息,用来进行rack-awareness 或者 host-awareness的资源分配。这个API背后是调用topology.py这个python脚本来解析topology.map文件来完成的。在Yarn服务器上,这个topology.py和topology.map都位于配置文件目录下。
public class TestRackTopology {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
File configDir = new File(args[0]); // *-site.xml的配置文件目录
String inputPath = args[1]; // 需要进行拓扑解析的host列表,一行一个hostname
File[] configs = configDir.listFiles((dir, name) -> name.toLowerCase().endsWith(".xml"));
// 逐个加载配置文件
for (File file : configs) {
conf.addResource(file.getAbsolutePath());
}
List<String> lines = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader(inputPath));
String line;
while ((line = br.readLine()) != null) {
lines.add(line);
}
for(int i = 0;i < lines.size();i++){
System.out.println("Resolving " + lines.get(i));
System.out.println(RackResolver.resolve(conf, lines.get(i)).getNetworkLocation());
}
}
}
我们把这个代码打包,放到目标机器上运行如下。其中,/tmp/conf.cloudera.yarn2是存放了我们的Yarn集群的配置文件目录,/tmp/hostfile文件存放了整个yarn集群的host列表
java -cp /tmp/JavaTestProject-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.TestRack /tmp/conf.cloudera.yarn2 /tmp/hostfile
输出结果如下:
Resolving dcp210-5a.iad4.prod.mycorp.com
/default-rack
Resolving dcp106-1c.iad5.prod.mycorp.com
/default-rack
........
3. 源码解析
3.1 Client模式和Cluster模式下客户端的提交和启动过程
目前,我们能够获取的日志主要来自四个角色, Driver,ApplicationMaster,Yarn ResourceManager, Yarn NodeManager。
上面已经展示了Driver和ApplicationMaster的日志。
用户通过spark-submit提交应用的时候,都是通过 SparkSubmit()的main()方法进入的。
根据Client模式还是Cluster模式,会确定客户端的这个Main Class:
---------------------------------------- SparkSubmit -------------------------------------
private[deploy] def prepareSubmitEnvironment(
args: SparkSubmitArguments,
conf: Option[HadoopConfiguration] = None)
: (Seq[String], Seq[String], SparkConf, String) = {
if (deployMode == CLIENT) {
childMainClass = args.mainClass //这里的args.mainClass是用户的Spark应用的Main class
}
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
......
}
}
从上面的代码可以看到
- Client模式下,客户端会运行用户的业务逻辑(Driver),其main方法的入口是用户提交的Spark应用的Main Class。用户代码中会构造SparkContext,SparkContext的构造就是Driver的构造过程。
- Cluster模式下,客户端不会运行用户的业务逻辑,其main方法的入口是
YARN_CLUSTER_SUBMIT_CLASS,这里的类是org.apache.spark.deploy.yarn.YarnClusterApplication
由于我们看到的第一个日志是Driver端的日志,日志显式连接到ApplicationMaster超时。同时,在ResourceManager端的代码也证明,ApplicationMaster此时处于某种hang住的状态,所以,我们需要结合代码,详细分析Spark ApplicationMaster的执行过程,推测或者断定hang住的位置。
客户端提交时在两种模式下的处理逻辑
Cluster模式下的启动主要包含了用户应用的启动(SparkContext的构造)等,在SparkContext构造完成以后,会启动对应的AMEndpoint,然后,向Driver注册ApplicationMaster。显然,在Cluster模式下,这个注册其实是同一进程内的通信。
无论是什么模式,客户端的Main Class都是都是SparkSubmit.scala,即都是通过运行SparkSubmit的main()方法进行的,即我们在客户端通过诸如ps命令看到的进程中的Java Class都是SparkSubmit这个Main Class。
SparkSubmit会通过调用对应的SparkApplication这个trait实现类的start()方法来启动这个Application:
- 在Cluster模式下,用户代码并不在客户端运行,这时候SparkApplication的实现类是Spark自定义的YarnClusterApplication。
- 在Client模式下,用户代码直接在客户端运行,这时候SparkApplication的实现类是JavaMainApplication,JavaMainApplication对用户代码的运行进行了封装,本质上是调用的是用户的Main Class的main()方法。
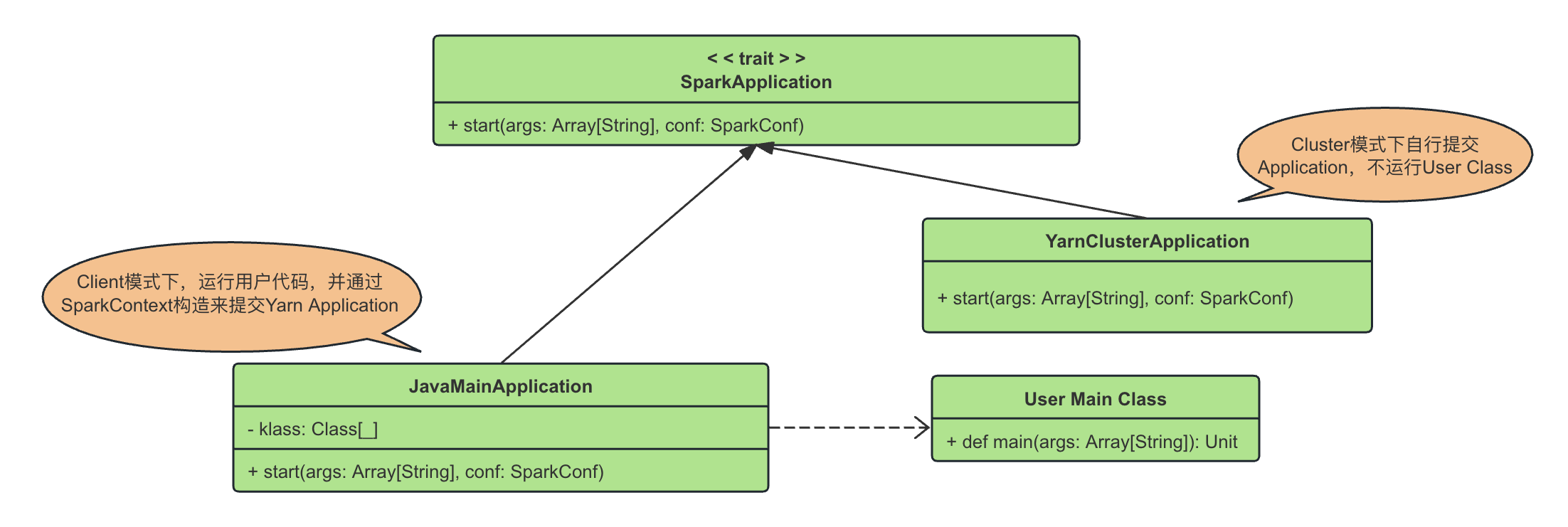
具体来说:
- 在Cluster模式下,这个用户端 User Main Class是运行在ApplicationMaster上的,客户端不需要关心User Class,因此这个childMainClass是Yarn自己定义的org.apache.spark.deploy.yarn.YarnClusterApplication:
// Following constants are visible for testing.
private[deploy] val YARN_CLUSTER_SUBMIT_CLASS =
"org.apache.spark.deploy.yarn.YarnClusterApplication"
// In yarn-cluster mode, use yarn.Client as a wrapper around the user class
if (isYarnCluster) {
childMainClass = YARN_CLUSTER_SUBMIT_CLASS //
.....
childArgs += ("--class", args.mainClass) // User class只是作为YARN_CLUSTER_SUBMIT_CLASS的一个参数
YarnClusterApplication的start()方法很简单,主要职责就是提交这个Application到Yarn,当然,相应参数已经组装好了,比如,用户的main class 是什么(–class …)以及其他参数:
private[spark] class YarnClusterApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
........
new Client(new ClientArguments(args), conf).run() // args携带了spark-submit的时候的main class等等信息
}
}
def run(): Unit = {
this.appId = submitApplication() // 提交Application
.....
- 但是在Client模式下,用户自己的 User Main Class是直接在客户端加载的,因此childMainClass就是用户通过spark-submit.sh传入进来的自己的Main Class:
if (deployMode == CLIENT) {
childMainClass = args.mainClass
.......
}
在确定了clildMainClass以后,就可以运行了,上面讲过,本质上是运行SparkApplication这个trait的start()方法。但是在Client模式下是直接运行用户代码,而用户代码没有实现SparkApplication,因此,其处理逻辑是通过JavaMainApplication对用户代码的main()方法的调用进行封装:
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sparkConf: SparkConf,
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off println
...
var mainClass: Class[_] = null
mainClass = Utils.classForName(childMainClass)
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.newInstance().asInstanceOf[SparkApplication] // Cluster模式下,是YarnClusterApplication
} else {
new JavaMainApplication(mainClass) // Client模式下,封装为JavaMainApplication
}
app.start(childArgs.toArray, sparkConf)
}
在Cluster模式下,由于这个主入口类是Spark定义的,因此有对应的Application提交逻辑。但是在Client模式下,childMainClass直接就是用户定义的类。那么,应用什么时候提交呢?是在YarnClientSchedulerBackend中进行的,即用户的应用程序在构造SparkContext过程中,会构造TaskScheduler以及对应的SchedulerBackend。我们下文会讲,SchedulerBackend是跟具体的运行平台强绑定(Mesos, K8S, Yarn等),因此在Yarn的场景下,根据Client模式还是Cluster模式,具体实现成YarnClientSchedulerBackend和YarnClusterSchedulerBackend。在Client模式下,YarnClientSchedulerBackend构造的时候,会负责提交Application到Yarn:
override def start() {
.......
val args = new ClientArguments(argsArrayBuf.toArray)
totalExpectedExecutors = SchedulerBackendUtils.getInitialTargetExecutorNumber(conf)
client = new Client(args, conf)
bindToYarn(client.submitApplication(), None) // 提交application给yarn
无论是什么模式,客户端在提交Application到Yarn的时候,根据Yarn的API,需要向Yarn指定ApplicationMaster的Main Class(随后启动的非ApplicationMaster的普通的Container用什么Main Class则是ApplicationMaster内部具体负责),即包含一个main入口方法的Class:
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
可以看到,对于Cluster模式,提交给Yarn的Main Class是ApplicationMaster,对于Client模式,提交给Yarn的Main Class是ExecutorLauncher,二者有什么区别呢?
没有任何本质区别,Spark这样做只是为了进程名称上方便区分。其实ExecutorLauncher只是对ApplicationMaster的main的直接封装,没有任何其他不同操作,主要是为了方便在进程的名称中区分开是Client模式还是Cluster模式提交的Application的ApplicationMaster,用户可以方便通过诸如ps命令看出来是哪种提交模式:
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}
ApplicationMaster启动时在两种模式下的处理逻辑
从客户端向Yarn提交的时候指定的Main Class可以看到,虽然main class在两种模式下不同,但是本质都是运行ApplicationMaster的main()方法。因此,ApplicationMaster会继续根据当前是Client还是Cluster模式进行区别判断,至少,两种模式下,Cluster模式需要运行用户代码和SparkContext的初始化,Client模式则不需要。
ApplicationMaster在两种模式下的构造逻辑如下图所示:
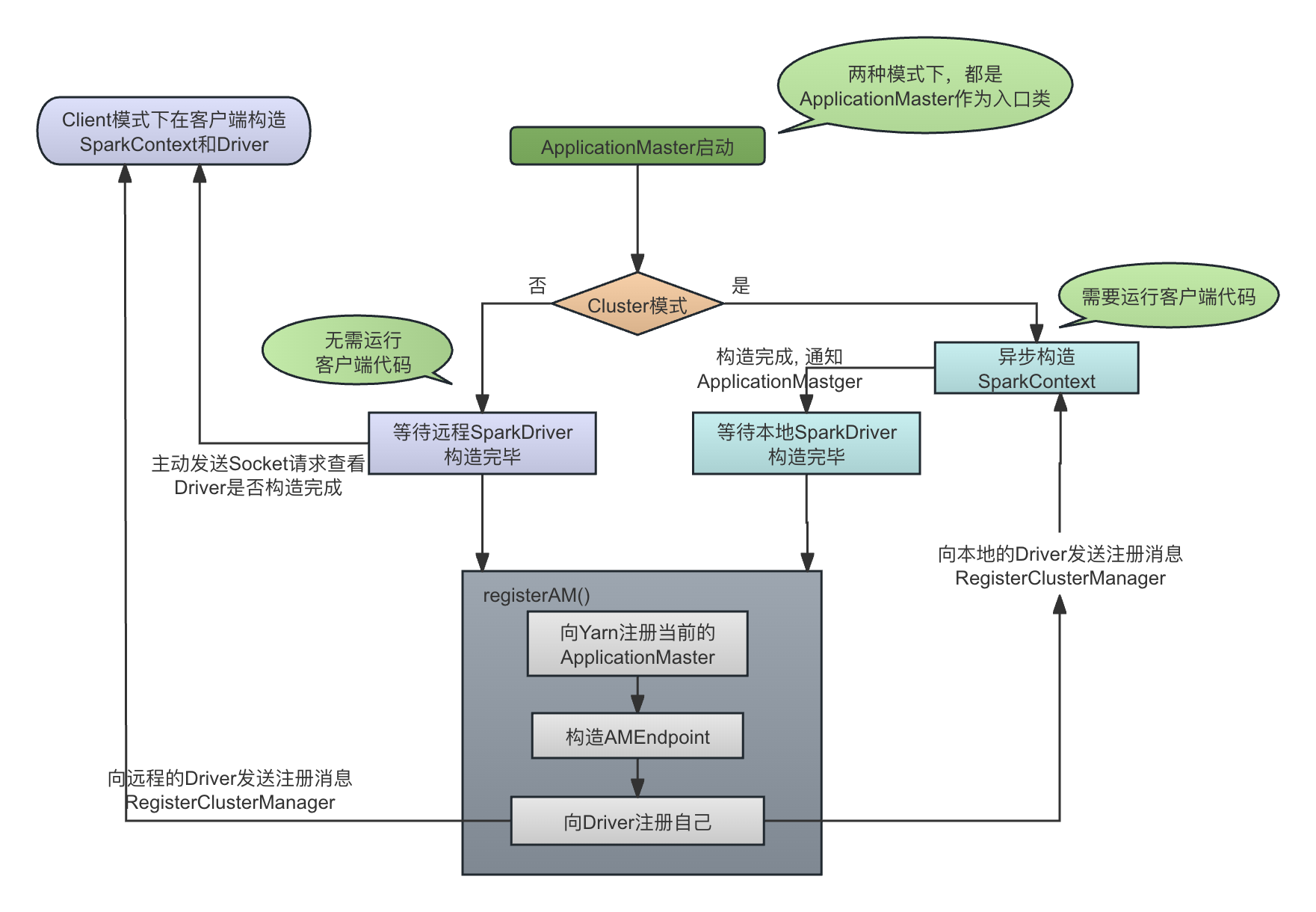
-
Cluster模式:
ApplicationMaster启动的时候,其调用堆栈如下图所示。显然,ApplicationMaster也是从Executor中启动的,因为ApplicationMaster其实是第一个启动的、特殊的Executor:
上面我们说过,Client模式下虽然amClass是org.apache.spark.deploy.yarn.ExecutorLauncher,但是和Cluster模式一样,下层将会调用的都是org.apache.spark.deploy.yarn.ApplicationMaster。因此,在ApplicationMaster的具体运行时,需要对当前是Cluster模式还是Client模式进行具体判断并区分运行。
在ApplicationMaster.runImpl()中,根据当前是Client模式还是Master模式,开始区别处理,如果是Cluster模式(Driver也在Yarn集群中运行),则调用runDriver(),如果是Client模式,则调用runExecutorLauncher()。这是因为在Client模式下(我们使用的是Client模式),Driver是在Yarn集群外面已经独立启动了,独立运行的ApplicationMaster需要runExecutorLauncher()来进行Executor资源的调度:private def runImpl(): Unit = { try { ..... if (isClusterMode) { // Cluster模式 runDriver() // 进程内部启动Driver } else { runExecutorLauncher() // Client模式 }- Cluster模式下,用户通过spark-submit提交应用,提交以后即离开,没有启动SparkContext,更没有启动ApplicationMaster。我们从
SparkContextSubmit.scala中可以看到,这时候提交应用,仅仅是通过YarnClusterApplication进行了相应Application的提交。 - Cluster模式下,用户业务代码的Main Class,以及Driver端代码,即Driver(SparkContext)的构造是在ApplicationMaster中启动的。这个启动是一个异步的过程,ApplicationMaster在构造自己的AMEndpoint前,一定会等待SparkContext构造完成,这是通过SparkContext构造完成以后通过sparkContextPromise通知ApplicationMaster来完成的:
private def runDriver(): Unit = { addAmIpFilter(None) userClassThread = startUserApplication()// 异步启动用户线程,构造SparkContext ...... val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME) - 等待SparkContext构造完成。SparkContext构造过程中,就会启动对应的TaskScheduler和SchedulerBackend,下文会详细讲到。
val sc = ThreadUtils.awaitResult(sparkContextPromise.future, Duration(totalWaitTime, TimeUnit.MILLISECONDS)) - 注册AMEndpoint。注册的过程是Client模式和Cluster模式通用的,其基本流程都是向Driver(Cluster模式下Driver在本地,Client模式下Driver在远程)发送RegisterClusterManager消息注册自己的Endpoint,然后,通过封装的Yarn的标准API,向Yarn注册这个ApplicationMaster的角色(这是Yarn的协议要求):
rpcEnv = sc.env.rpcEnv // Driver和ApplicationMaster运行在一起,因此是直接从SparkContext中获取对应的RpcEnv // 设置Driver的EndpoingRef val driverRef = createSchedulerRef( sc.getConf.get("spark.driver.host"), sc.getConf.get("spark.driver.port")) registerAM(sc.getConf, rpcEnv, driverRef, sc.ui.map(_.webUrl))registerAM()主要完成以下工作:-
向Yarn注册自己:
// 调用了 Yarn的标准API, 即接口register 方法来注册这个ApplicationMaster allocator = client.register(driverUrl, driverRef, // driver的 endpointRef ..... historyAddress, // History 地址,这个地址是Yarn上的Application详情页的地址 s) -
构造AMEndpoint:构造的时候就会向Driver的Endpoint发送RegisterClusterManager消息注册自己
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
-
- Cluster模式下,用户通过spark-submit提交应用,提交以后即离开,没有启动SparkContext,更没有启动ApplicationMaster。我们从
-
Client模式
与Cluster模式的巨大区别是,Client模式下,Driver(SparkContext)就在客户端构造,因此ApplicationMaster需要与远程的Driver通信以确认其构造完成以后再启动并向Driver注册自己AMEndpoint。但是对于registerAM()本身来讲,除了Driver的位置不同,其注册逻辑没有任何区别。
在spark-submit提交应用程序以后,Client模式下的ApplicationMaster是调用runExecutorLauncher()启动的:
private def runExecutorLauncher(): Unit = { .... // 创建ApplicationMaster的RPCEnv对象。在这里调用静态方法RpcEnv.create(),创建的RpcEnv实现是NettyRpcEnv对象 // 在Client模式下,Driver不在本地运行,因此这里localMode = true,以client模式运行,不启动service,因此端口号是-1 rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr, amCores, true) // 和Driver进行通信,直到和Driver建立socket连接以确定Driver启动成功,返回Driver的RpcEndpointRef, 设置Driver的EndpointRef val driverRef = waitForSparkDriver() registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress")) registered = true // In client mode the actor will stop the reporter thread. reporterThread.join() }其具体流程是:
- 创建ApplicationMaster的RpcEnv。在Cluster模式下,ApplicationMaster的RpcEnv直接使用的SparkContext的RpcEnv,因为在同一个进程。
rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr, amCores, true) - 等待SparkDriver的启动完成,这是在方法waitForSparkDriver()中完成的,这里其实是通过与SparkDriver进行Socket通信以确认其是否启动成功
private def waitForSparkDriver(): RpcEndpointRef = { ...... while (!driverUp && !finished && System.currentTimeMillis < deadline) { try { val socket = new Socket(driverHost, driverPort) socket.close() // socket建立成功,说明driver已经启动成功 driverUp = true - 如果Driver启动成功,则创建Driver的RpcEndpointRef:
createSchedulerRef(driverHost, driverPort.toString) - 构造AMEndpoint并向远程的Driver注册自己的AMEndpoint。这个过程与Cluster模式完全相同
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))
- 创建ApplicationMaster的RpcEnv。在Cluster模式下,ApplicationMaster的RpcEnv直接使用的SparkContext的RpcEnv,因为在同一个进程。
3.2 两种模式下的下层角色关系和启动以后的总体运行流程
下图显示了在Client模式下,在动态资源分配的场景下,Spark从客户端提交应用程序、资源分配、Task的启动等基本流程,用户代码、SparkContext(TaskScheduler, SchedulerBackend)都是在Yarn以外单独运行的:
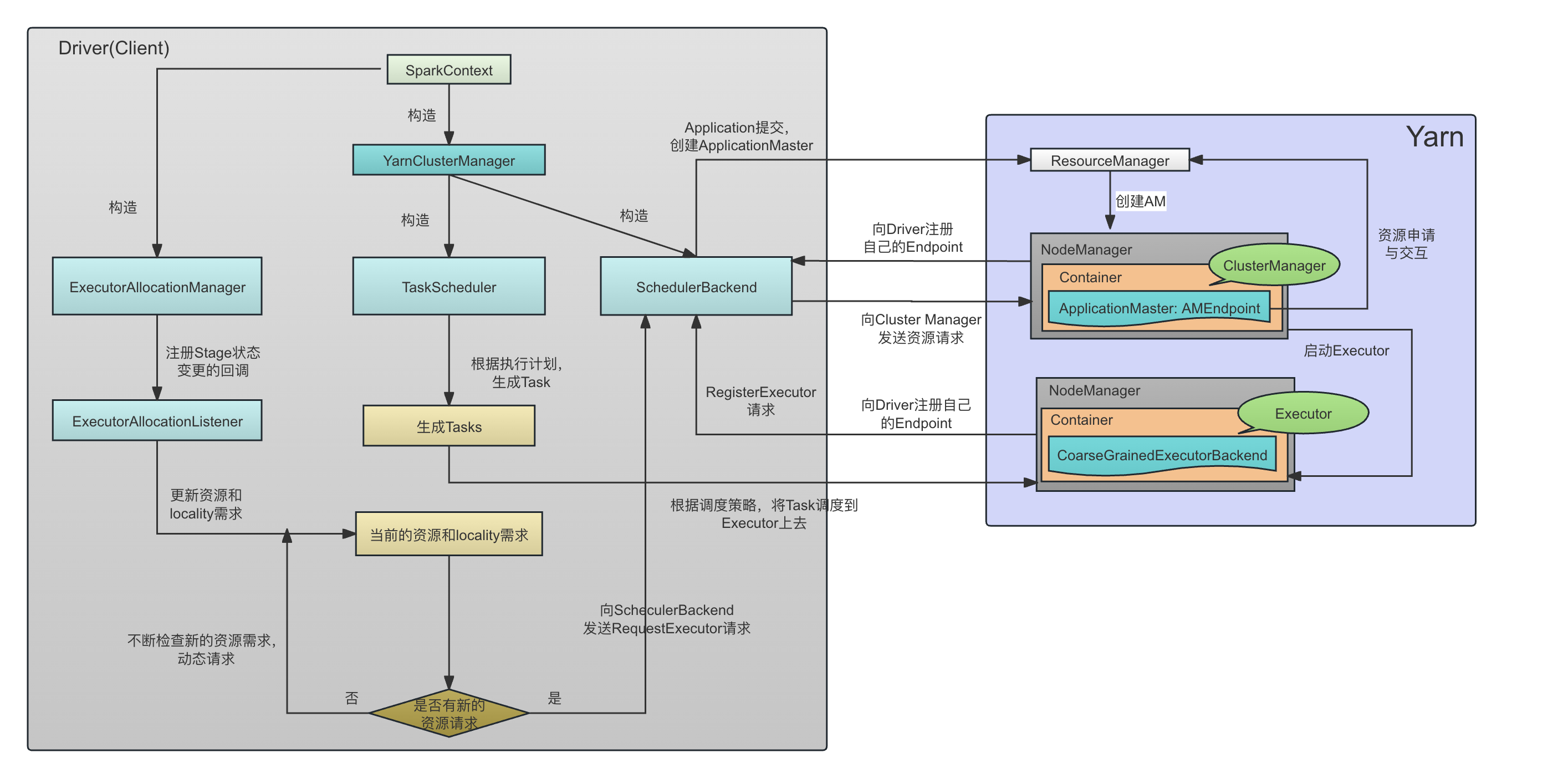
在Cluster模式下,用户代码、SparkContext(TaskScheduler, SchedulerBackend)以及AMEndpoint都是在ApplicationMaster中运行的:
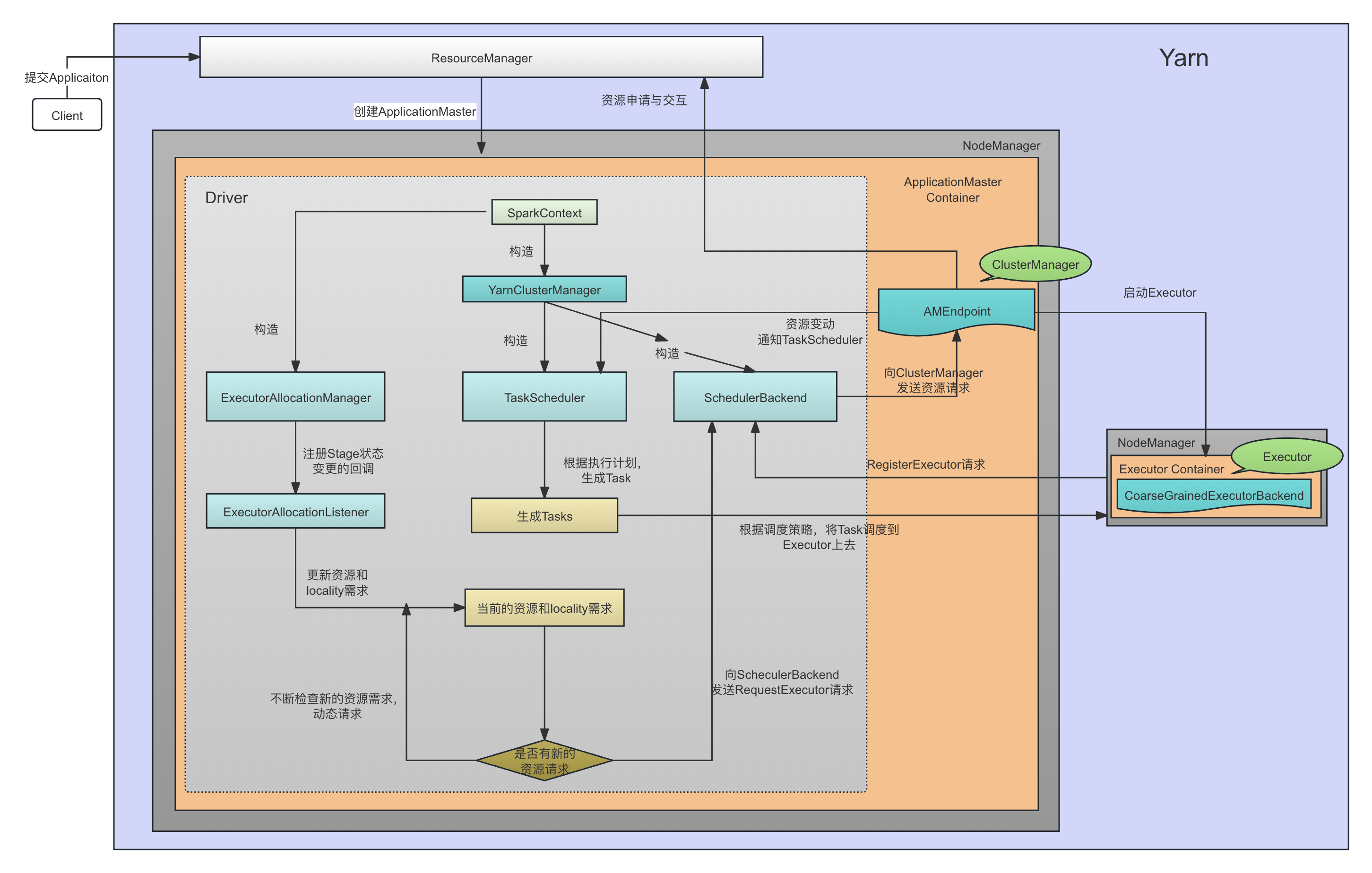
简单来讲,其基本流程和一些角色的作用如下:
- 在客户端,构造SparkContext。这是任何情况下我们提交一个Spark Application的第一步;
- 在SparkContext构造的时候,会构造对应的 ExternalClusterManager的具体实现类,用来管理整个Application。ExternalClusterManager是一个用来接入外部资源调度器的接口,比如,Spark可能运行在Standalone模式,Mesos上,Yarn上,K8S上,因此需要提供不同的ExternalClusterManager实现。在Spark on Yarn的场景下,ExternalClusterManager的实现类是YarnClusterManager;
- 基于ExternalClusterManager的实现,创建对应的 SchedulerBackend 实现,以及对应的TaskScheduler实现(TaskScheduler需要依赖SchedulerBackend进行Executor层面的控制,而SchedulerBackend在收到相关消息以后也会相应更新TaskScheduler中的元数据或者依赖TaskScheduler获取task的相关信息,因此它们相互依赖),其中:
- SchedulerBackend主要是接受TaskScheduler的委托,和对应的资源管理器(Yarn、Mesos、K8S)进行资源相关的操作,包括:
- 在任务调度层面,它会和自己管理的DriverEndpoint进行通信(Cluster模式下这个通信就是本地通信),来进行基本的Task的操作(但是操作的决策是来自上层的TaskScheduler)。比如CoarseGrainedSchedulerBackend代表的是一个基本的、粗粒度的调度逻辑,它维护了一个DriverEndpoint,后面会讲,这是粗粒度调度器下,资源本身的变化(Executor的新增、丢失等等资源事件)和TaskScheduler(TaskScheduler负责的是Task的管理逻辑,与资源管理无关)进行交互的一个中间层,从而要求DriverEndpoint根据集群的资源变化处理对应的Task调度。比如,当集群新增了Executor,那么CoarseGrainedSchedulerBackend就会通过DriverEndpoint作为一个中间层,通知到对应的TaskScheduler,TaskScheduler从而进行Task调度。
- 在Container的层面,与远程的ApplicationMaster进行通信,申请和释放资源则放在了子类YarnSchedulerBackend中的YarnSchedulerEndpoint中。Spark的Client模式和Cluster模式下的SchedulerBackend实现类分别为YarnClientSchedulerBackend和YarnClusterSchedulerBackend。Application(注意Application中的某一个Job)的提交是在这里进行的。
- TaskScheduler则基于Container(Executor)的当前状态,进行task的调度。后面会讲,Task的调度跟平台(Standalone, Spark on Yarn,Spark on Mesos, Spark on K8S等)无关,因此几乎所有的平台实现都使用了一个基本的TaskSchedulerImpl。
- SchedulerBackend主要是接受TaskScheduler的委托,和对应的资源管理器(Yarn、Mesos、K8S)进行资源相关的操作,包括:
- SparkContext中创建对应的ExecutorAllocationManager实现:
- ExecutorAllocationManager封装了Dynamic Allocation的基本逻辑,根据当前Task的状态(pending,running等等),对Executor的创建和释放进行动态的、不间断的处理。
- ExecutorAllocationManager管理了一个ExecutorAllocationListener,这个Listener在构造的时候注册给了Spark的ListenerBus,因此会收到自己关心的比如Stage提交、结束等等时间,并获取对应的task的需求。ExecutorAllocationManager就是根据这个不断变化的task的需求,来确定目标task的数量,进行对动态分配进行决策。因此,这个动态的分配过程是不断进行的。
- Client模式下,SchedulerBackend启动的时候会提交这个Application,Yarn会在远程启动对应的ApplicationManager,负责进行资源的分配
- ApplicationMaster在Spark中叫做Cluster Manager, 会接收来自Driver端SchedulerBackend的请求(其实只接受YarnSchedulerEndpoint而不是DriverEndpoint的请求,下面会解释),然后基于Yarn的AMRMClient API,向Yarn做资源申请和释放的相关交互;
- Executor 启动的时候,会向Driver注册自己的Endpoint,这时候就会在Driver和Executor之间存在一个长时间存在的长连接用来进行相互的通信。
- TaskScheduler基于当前的执行计划,以及Executor的分配状态,向Executor进行任务的调度。
TaskScheduler和SchedulerBackend的创建
在我们的客户端代码构造SparkContext的时候,会根据我们的启动参数来创建ExternalClusterManager的实现,进而根据ExternalClusterManager创建对应的SchedulerBackend以及对应的TaskScheduler。
SchedulerBackend和对应的TaskScheduler都运行在Driver这一端,其中SchedulerBackend负责和远程的ApplicationMaster通信进行资源调度信息的同步,而TaskScheduler则负责任务调度。显然 ,任务是被调度到Container的,因此任务调度需要依赖SchedulerBackend返回的结果。
在SparkContext启动的时候,会创建TaskScheduler,然后创建对应的DAGScheduler:
------------------------------------- SparkContext ----------------------------------------
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
DagScheduler根据Stage层面的状态变化和相关处理逻辑,调用对应的TaskScheduler层面的处理逻辑。比如:
- 在DAGScheduler提交一个Stage的时候,会通过调用TaskScheduler的submitTasks(taskSet: TaskSet)接口进行相关任务的提交
- 在DAGScheduler中的一个Job失败的时候,DAGScheduler会通过调用TaskScheduler的cancelTasks()接口来取消相关任务的运行
- 用户在Spark的运行页面Kill一个Task的时候,会通过SparkContext.killTaskAttempt() -> DAGScheduler.killTaskAttempt() -> TaskScheduler.killTaskAttempt()的调用逻辑,最终使用TaskScheduler来执行具体Task的相关操作。
TaskScheduler创建的时候,会首先创建对应的ExternalClusterManager的实现。当我们通过--master yarn参数提交基于Yarn的Spark job的时候,对应的ExternalClusterManager service的实现类是YarnClusterManager:
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" => // local 模式
.....
case LOCAL_N_REGEX(threads) => // local[N] 模式
.....
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) => // local[M,N]模式
.....
case SPARK_REGEX(sparkUrl) => // standlone 模式,url是spark://...
.....
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) => // local-cluster[N,C,M]模式
......
case masterUrl => // 其它情况,比如,--master yarn
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl) // Yarn Cluster模式下构建TaskScheduler
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
........
}
}
}
-
通过调用getClusterManager()来获取对应的 ExternalClusterManager 实现。从下面的代码可以看到,其实是调用ExternalClusterManager接口的canCreate()方法返回支持用户的–master参数值的ExternalClusterManager实现。如果是
--master yarn, 那么就是YarnClusterManager:private def getClusterManager(url: String): Option[ExternalClusterManager] = { val loader = Utils.getContextOrSparkClassLoader val serviceLoaders = ServiceLoader.load(classOf[ExternalClusterManager], loader).asScala.filter(_.canCreate(url)) ...... serviceLoaders.headOption } }YarnClusterManager的canCreate()方法实现:
private[spark] class YarnClusterManager extends ExternalClusterManager { override def canCreate(masterURL: String): Boolean = { masterURL == "yarn" } -
然后,基于创建好的ExternalClusterManager实现,调用对应的createTaskScheduler()方法和createSchedulerBackend()方法,获取对应的
TaskScheduler和SchedulerBackend,其中TaskScheduler主要是创建对应的Driver服务,用来接受Executor的注册,将Task调度到Executor上等等,而SchedulerBackend的实现主要是偏向于基于具体的资源管理器(Yarn, Standalone, Mesos, K8S)资源层面,即与ApplicationMaster进行通信,进行资源调度。显然,资源调度的操作依赖于任务调度的决策,因此SchedulerBackend很多的请求实际上是Driver端的TaskScheduler发起的。/** * Cluster Manager for creation of Yarn scheduler and backend */ private[spark] class YarnClusterManager extends ExternalClusterManager { .... override def createTaskScheduler(sc: SparkContext, masterURL: String): TaskScheduler = { sc.deployMode match { case "cluster" => new YarnClusterScheduler(sc) // Yarn Cluster模式 case "client" => new YarnScheduler(sc) // Yarn Client模式 } } override def createSchedulerBackend(sc: SparkContext, masterURL: String, scheduler: TaskScheduler): SchedulerBackend = { sc.deployMode match { case "cluster" => // Cluster 模式下的 SchedulerBackend实现 new YarnClusterSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc) case "client" => // Client 模式下的 SchedulerBackend实现 new YarnClientSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc) ... } }
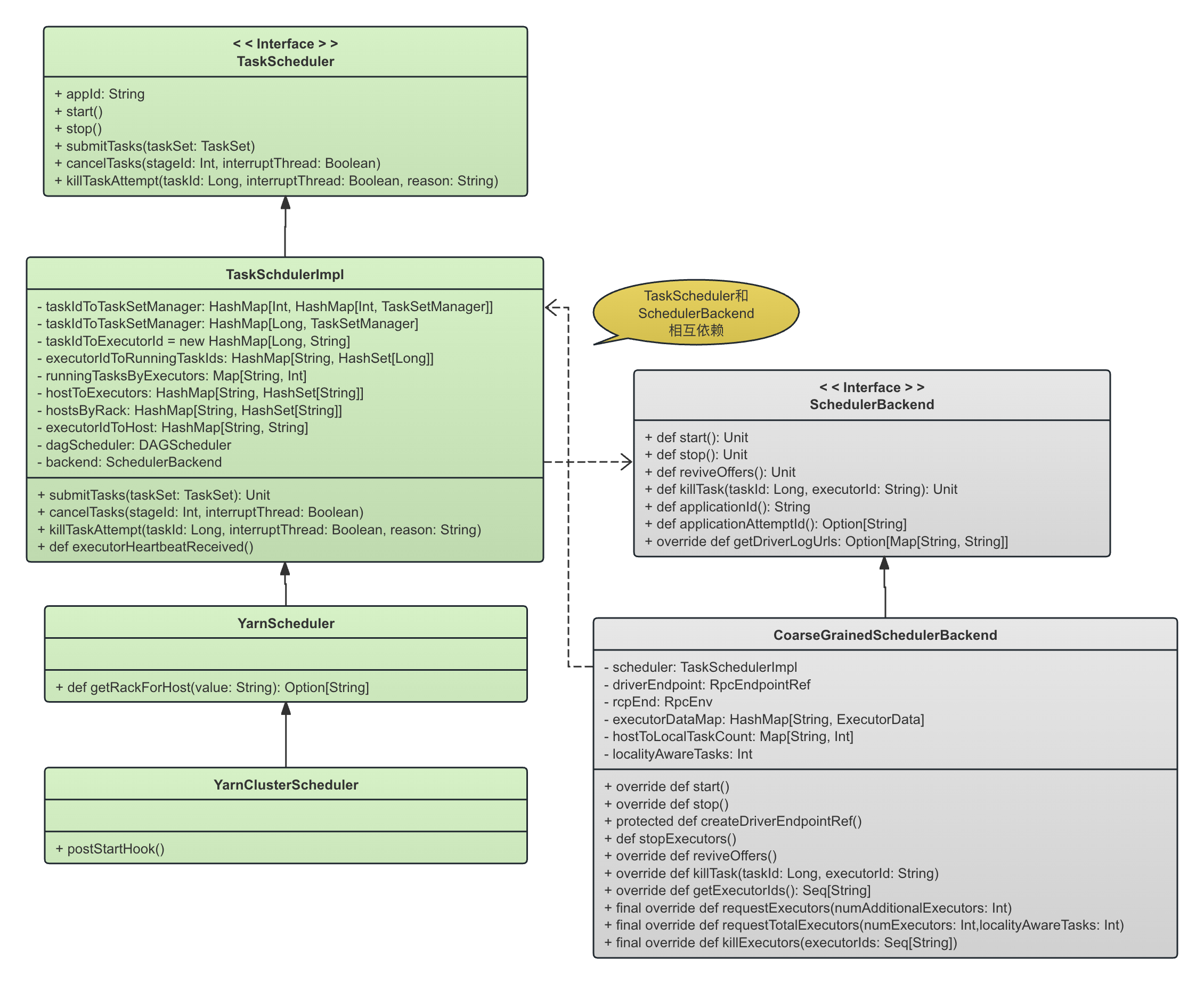
下图显示了TaskScheduler在Spark on Yarn中的实现类的类图,以及与SchedulerBackend的相应关系。
总之,我们可以看到:
- TaskScheduler接口的基本实现是TaskSchedulerImpl。Task层面本身的调度其实与Spark的运行方式(Standalone, Spark on Yarn,Spark on Mesos, Spark on K8S)没有关系,这种平台的差异只体现在TaskScheduler所依赖的SchedulerBackend上。因此,几乎所有的Spark运行方式都使用TaskSchedulerImpl作为任务调度器。
- 但是,在Yarn的模式下,无论Client模式或者Cluster模式,Spark还是对TaskSchedulerImpl的几个简单方法进行了微小的修正(方法的重写),因此使用YarnScheduler作为Client模式下的TaskScheduler实现,使用YarnClusterScheduler作为Cluster模式下的TaskScheduler实现。
下图显示了SchedulerBackend端的继承关系:
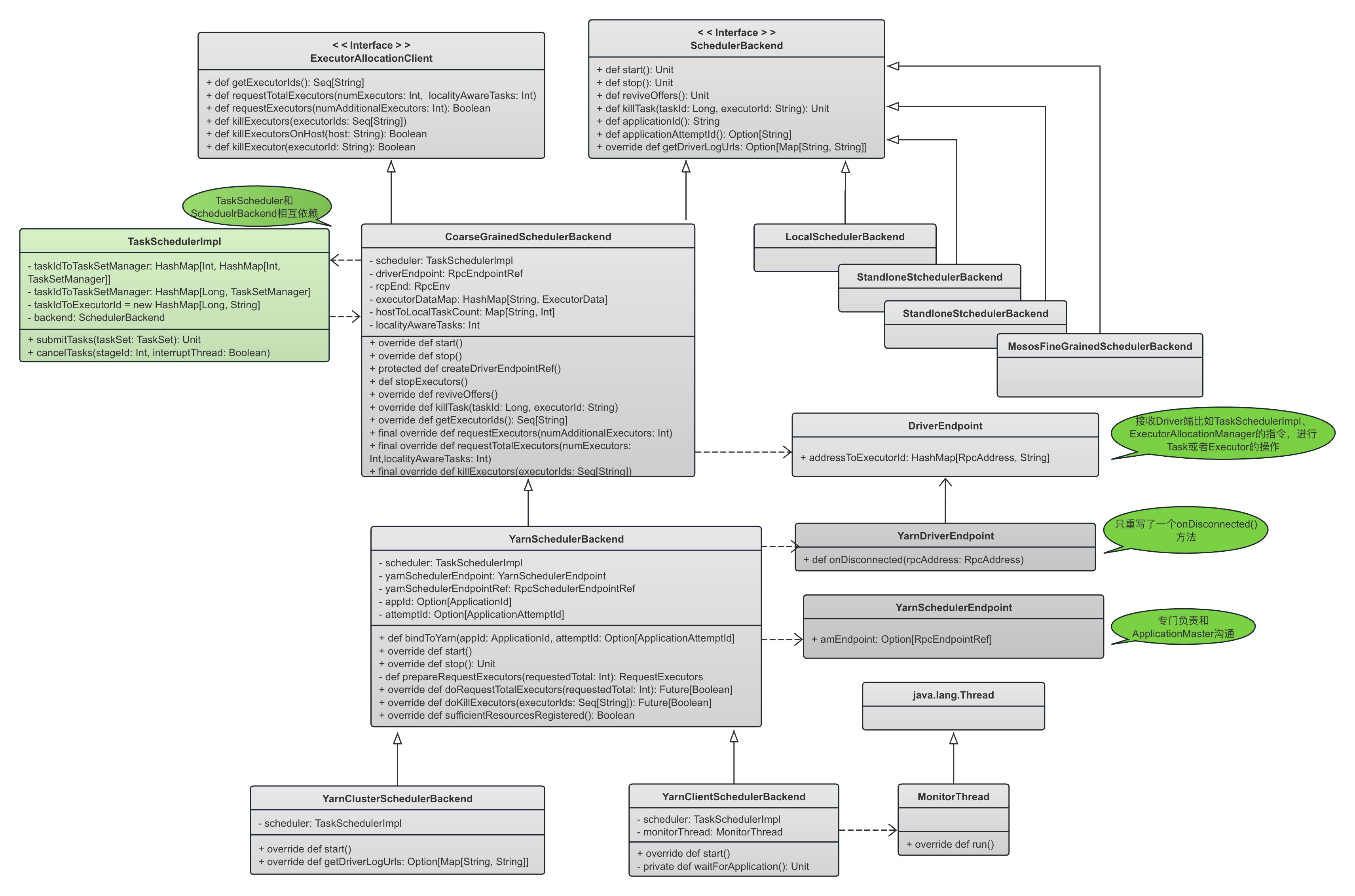
- 从继承关系也可以看到,CoarseGrainedSchedulerBackend在构造的时候就持有了TaskSchedulerImpl,这是为了在DriverEndpoint收到相关消息以后,可以通知TaskSchedulerImpl进行相关操作,或者依赖TaskScheduler进行相关操作。
- 我们可以看到,CoarseGrainedSchedulerBackend和TaskSchedulerImpl是相互依赖。在粗粒度的调度环境下,TaskScheduler依赖CoarseGrainedSchedulerBackend中的DriverEndpoint将任务调度映射到资源调度,而CoarseGrainedSchedulerBackend在收到相关信息更新以后也需要相应更新TaskScheduler中的任务信息,或者依赖TaskScheduler进行进一步操作。
- 同时,我们可以看到,在Driver端存在两个不同的Endpoint,CoarseGrainedSchedulerBackend中的DriverEndpoint,和它的子类YarnSchedulerBackend中的YarnSchedulerEndpoint。我们应该这样理解这两个Driver端的Endpoint的作用:
- YarnSchedulerEndpoint所在的YarnSchedulerBackend是DriverEndpoint所在的类CoarseGrainedSchedulerBackend的子类,因此,YarnSchedulerEndpoint是对DriverEndpoint的补充
- 首先,YarnSchedulerBackend是对粗粒度调度器CoarseGrainedSchedulerBackend基于Yarn的实现。在基本的粗粒度调度环境下,DriverEndpoint负责承担调度责任,包括粗粒度的Executor的调度(直接和Executor通信)和细粒度的Task调度
- 在粗粒度的调度环境下,Yarn这种资源调度器含有ApplicationMaster这种特殊角色。在Yarn中,资源的申请都必须和ApplicationMaster通信,而不是和Yarn直接通信,因此,粗粒度调度的基本逻辑无法满足Yarn这种特殊运行环境的需求。需要补充一个Endpoint专门负责和这个ApplicationMaster进行通信,这就是YarnSchedulerEndpoint出现的原因。我们看到YarnSchedulerEndpoint最重要的两个消息,KillExecutors和RequestExecutors,都需要ApplicationMaster通过AMRMClient来完成,因此,这两条命令都是发送给YarnSchedulerEndpoint,然后通过YarnSchedulerEndpoint交给ApplicationMaster;
- 由于YarnSchedulerEndpoint是和ApplicationMaster通信的,因此我们可以看到,ApplicationMaster启动以后的注册,RegisterClusterMaster是发送给YarnSchedulerEndpoint的,而不是发送给DriverEndpoint的
- ApplicationMaster在启动一个Allocated Container(Executor)的时候,发送给这个Executor的Driver的 URL是DriverEndpoint,而不是YarnSchedulerEndpoint,因此Executor启动以后是向DriverEndpoint注册,而不是向YarnSchedulerEndpoint注册(RegisterExecutor)。
从上面的继承关系可以看到:
- SchedulerBackend这一层与TaskScheduler这一层完全不同,其根本原因是SchedulerBackend这一层是跟平台(Standalone,Spark on Yarn, Spark on Mesos, Spark on K8S)强绑定的,因此不同的平台必须独立实现完全不同的SchedulerBackend,
- 在Spark on Yarn模式下,SchedulerBackend的直接实现类是CoarseGrainedSchedulerBackend。这里的CoarseGrained(粗粒度)的意思是,scheduler backend在Spark作业期间保留每个executor,而不是在任务完成时放弃executor并要求调度器为每个新的task启动新的executor。因此CoarseGrainedSchedulerBackend实现的是在CoarseGrained场景下的调度的基本路径,跟平台依然无关,只要平台支持这种CoarseGrained调度方式,那么只需要扩展一下 CoarseGrainedSchedulerBackend 以增加相应跟具体平台相关的东西就行了。
- Spark on Yarn的调度就是一种粗粒度的调度方式,因此,Yarn的调度实现YarnSchedulerBackend扩展了CoarseGrainedSchedulerBackend以支持Yarn。
- DriverEndpoint定义在了CoarseGrainedSchedulerBackend中,而不是定义在具体的YarnSchedulerBackend中,这说明DriverEndpoint中定义的消息、消息处理框架是基于CoarseGrain的基本处理逻辑,与下层平台是否是Yarn无关。但是某些具体的处理逻辑则还是依赖于平台,比如,在收到KillExecutorOnHost消息以后调用的doKillExecutor() 方法就显然依赖于具体的实现,这些实现与平台绑定,因此放在了其子类YarnSchedulerBackend中。
- 上文说过,SchedulerBackend的一个功能就是向Driver发送相关的Task指令,比如其接口reviveOffers()。CoarseGrainedSchedulerBackend持有一个DriverEndpointRef,以向Driver端发送对应的Task和Executor的相关请求。这些请求的决策来自TaskScheduler,发送给Driver以后,Driver可能和远程的Executor或者ApplicationMaster进行通信以执行相关操作。
override def start() { // CoarseGrainedSchedulerBackend 启动的时候,会构造DriverEndpoint的对应RpcEndpointRef // TODO (prashant) send conf instead of properties driverEndpoint = createDriverEndpointRef(properties) } - 基于Yarn的粗粒度调度的几乎全部公共逻辑都在YarnSchedulerBackend中实现,而子类YarnClusterSchedulerBackend和YarnClientSchedulerBackend重写了少量的接口。
- CoarseGrainedSchedulerBackend还继承了ExecutorAllocationClient,因此实现了跟Executor相关的基本操作,比如requestTotalExecutors(),requestExecutors(),killExecutors()和killExecutorsOnHost()方法。上面说过,CoarseGrainedSchedulerBackendy与具体平台没有关系,只是粗粒度的调度方式的基本实现框架,一旦需要跟下层平台交互,还是会交给具体的实现。比如,CoarseGrainedSchedulerBackend中requestTotalExecutors()是申请Exeuctor的基本流程,但是很显然,申请Executor还是要跟具体的运行平台交互,这一部分就交给其子类比如YarnSchedulerBackend去实现。
Client模式下,SchedulerBackend在构造的时候的重要职责,是提交Application到Yarn。Cluster模式下,客户端不会构造SparkContext和SchedulerBackend,提交应用的过程请参考TODO这篇文章。
DriverEndpoint的处理逻辑
在TODO中我们介绍了Spark RPC的基本架构。Driver端的RpcEndpoint实现是DriverEndpoint,定义在了CoarseGrainedSchedulerBackend中,这说明,DriverEndpoint的基本实现逻辑,是基于粗粒度调度方式的基本逻辑,跟这个粗粒度调度方式后面的资源管理器是Yarn或者其他并无关系。
Driver端的另外一个Endpoint, YarnSchedulerEndpoint是专门负责和Yarn调度器的一个特殊角色ApplicationMaster进行通信的,属于在Yarn场景下对DriverEndpoint的扩展。
参考TODO可以看到DriverEndpoint在整个SparkRPC框架中的继承关系。
我们看一下DriverEndpoint在整个RPC调用中的行为。
在TODO中介绍RpcEndpoint接口的时候我们讲到,RpcEndpoint接口通过receive()方法接收来自RpcEndpointRef.send() 和 RpcCallContext.reply()方法发送的消息,这里的消息不要求回复。通过receiveAndReply()方法接收来自RpcEndpointRef.ask()(当然包括了ask()和askAsync())方法发送的消息,ask()方法发送的消息要求接受者在receiveAndReply()方法中进行回复,消息的回复通过RpcCallContext进行回复。
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
......
case ReviveOffers =>
makeOffers() //
case KillTask(taskId, executorId, interruptThread, reason) =>
......
}
case KillExecutorsOnHost(host) =>
scheduler.getExecutorsAliveOnHost(host).foreach { exec =>
killExecutors(exec.toSeq, replace = true, force = true)
}
case UpdateDelegationTokens(newDelegationTokens) =>
executorDataMap.values.foreach { ed =>
ed.executorEndpoint.send(UpdateDelegationTokens(newDelegationTokens))
}
case RemoveExecutor(executorId, reason) =>
executorDataMap.get(executorId).foreach(_.executorEndpoint.send(StopExecutor))
removeExecutor(executorId, reason)
}
在receive()方法中,定义了集中典型的消息类型,分别接受来自Driver的相关操作指令,或者来自Executor的相关消息,包括:
-
StatusUpdate: 这个消息来自Executor的状态更新。这里处理的是Executor上一个Task的结束以后告知Driver的状态更新。
-
Driver会首先让TaskScheduler根据这个StatusUpdate消息更新它维护的相关元数据信息
case StatusUpdate(executorId, taskId, state, data) => scheduler.statusUpdate(taskId, state, data.value) -
然后更新自己维护的这个Executor的元数据信息,比如可用vcore资源
executorDataMap.get(executorId) match { case Some(executorInfo) => executorInfo.freeCores += scheduler.CPUS_PER_TASK // 更新可用资源元数据 -
同时,由于Task的结束导致可用资源的变化,因此通过makeOffers()方法尝试进行新的任务调度。
makeOffers(executorId) // 进行一次尝试调度- Spark中的offer是来自Executor的可用资源的Offer,一个WorkerOffer代表了一个Executor上的可用资源的描述信息。
- 待调度的任务的生成是TaskScheduler进行的,makeOffers(executorId)做的是根据当前生成的任务的需求(比如 locality需求等等)以及Offer信息,尝试将任务调度到对应的Executor上去。
private def makeOffers(executorId: String) { val taskDescs = CoarseGrainedSchedulerBackend.this.synchronized { // Filter out executors under killing if (executorIsAlive(executorId)) { // 如果是存活的Executor val executorData = executorDataMap(executorId) val workOffers = IndexedSeq( // 为这个Executor生成一个WorkerOffer,代表这个Executor当前的可用资源 new WorkerOffer(executorId, executorData.executorHost, executorData.freeCores)) scheduler.resourceOffers(workOffers) // 基于这个可用资源信息,进行Task的调度 } } launchTasks(taskDescs) // 将根据可用资源等调度规则生成的task启动起来 }
-
-
ReviveOffers: 这个消息来自Driver的请求,实际是来自TaskScheduler的调度决策生成的请求。比如,
TaskSchedulerimpl.submitTasks()的时候,就会调用这个方法,试图将Task在Executor上进行分配,即通过方法reviveOffers()进行Task的分配和启动(注意,是Task的启动,而不是资源的请求)。和上面讲StatusUpdate请求时候一样,这里也是调用makeOffers()方法来将已经由TaskScheduler生成的Task调度到具体的Executor上去的。
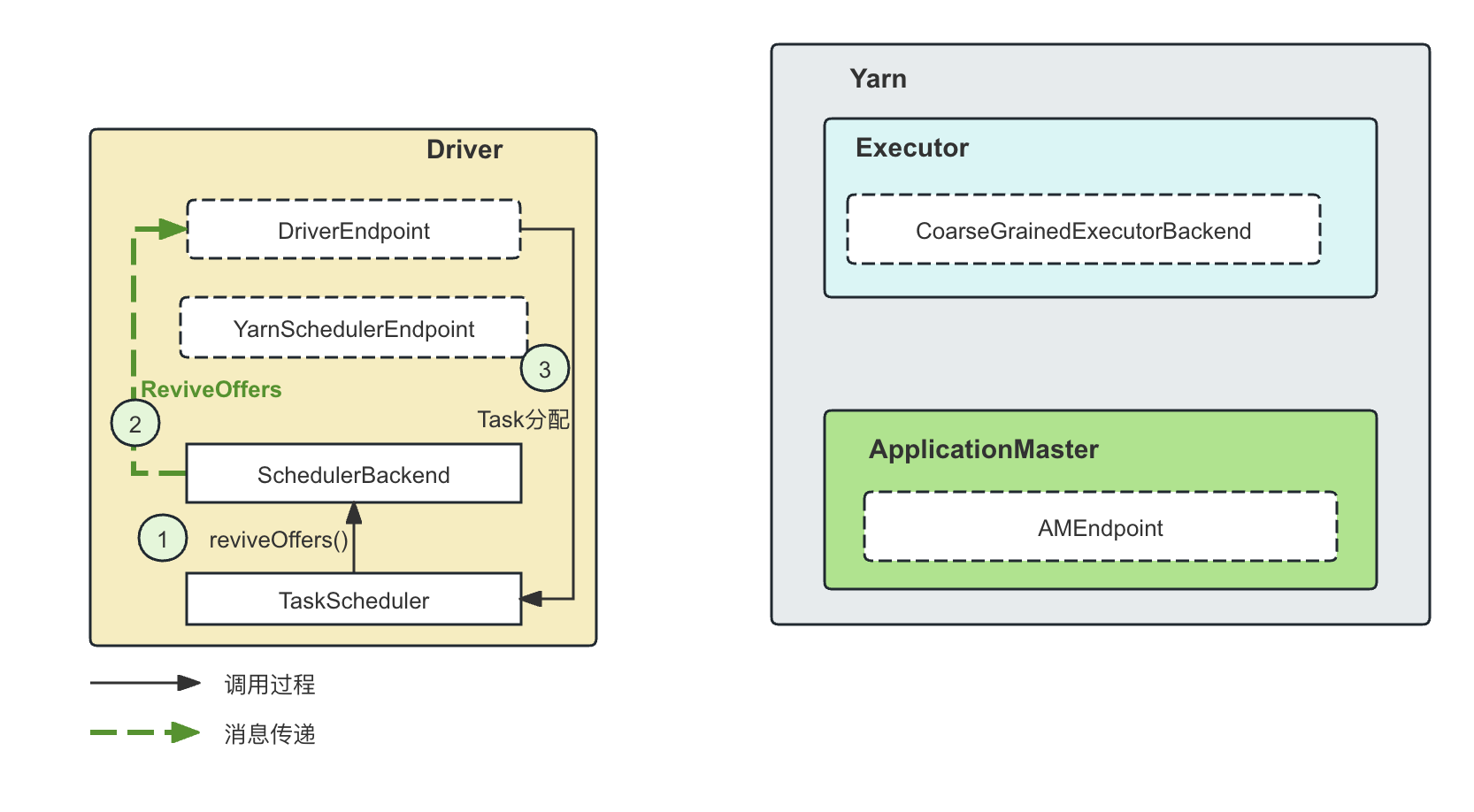
- 这里可以看到,ReviveOffers请求的发送者和接受者都是Driver,都在一个进程里面。因此,其实这种基于Actor的消息模型将网络部分全部交给了对应的RpcEnv去处理,只要正确构造了EndpointRef,就可以调用EndpointRef的对应发送消息的方法进行发送,接收者可能是本地的RpcEndpoint,可能是远程的RpcEndpoint。参考TODO中介绍Actor模型中在收到Local Message时的处理方式。
-
KillTask: 同样的,来自DAGScheduler的比如Job失败请求、用户在页面上手动kill一个任务、或者在推测执行的时候一个Task的另外一个attempt已经成功因此需要kill当前正在run的Task attempt,这时候都会由TaskSchedulerImpl调用到CoarseGrainedSchedulerBackend层,然后向DriverEndpoint 发送KillTask消息。
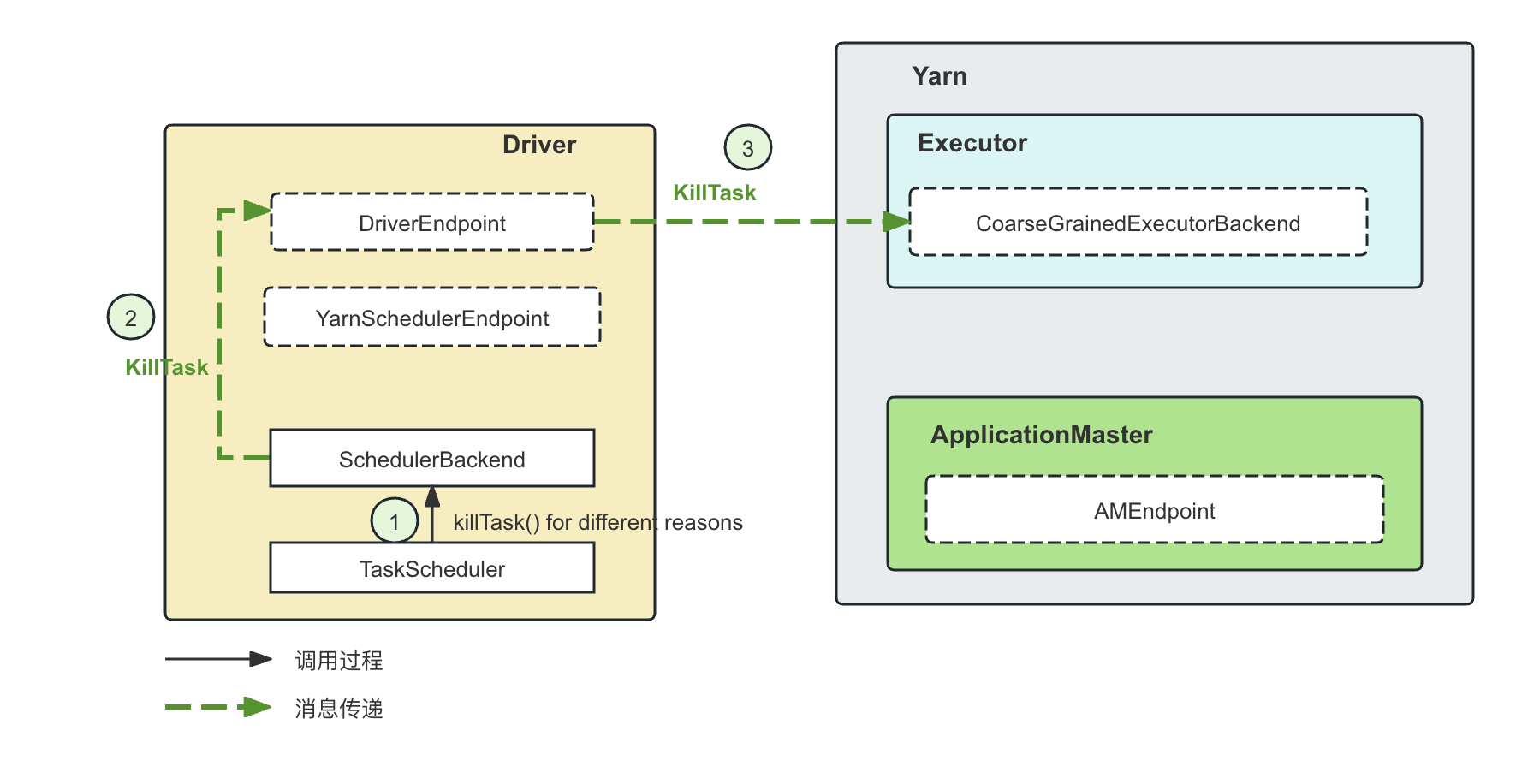
case ReviveOffers => makeOffers()- 对于KillTask消息,显然,Driver随后会向Executor发送KillTask的命令,这个消息的发送通过Driver端持有的Executor的RpcEndpointRef来进行的:
case KillTask(taskId, executorId, interruptThread, reason) => executorDataMap.get(executorId) match { case Some(executorInfo) => executorInfo.executorEndpoint.send( KillTask(taskId, executorId, interruptThread, reason)) } -
KillExecutorsOnHost: 这个消息的请求来自于TaskScheduler。这种情况主要发生在blacklist的处理上面。比如,基于失败以后的黑名单策略,TaskSetManager在处理一个失败的task的时候,假如根据策略需要将这个Task所在的节点(注意不是Task所在的Executor)加入到黑名单里面,那么就会向DriverEndpoint发送一个KillExecutorsOnHost消息,DriverEndpoint这时候就会通过TaskScheduler先获取这个host上的所有的Executor,然后通过killExecutor去杀死这个host上的所有的Executor。但是KillExecutor整个消息从被BlocklistTracker交付给DriverEndpoint,但是DriverEndpoint会委托YarnSchedulerEndpoint去做,因为YarnSchedulerEndpoint是来和ApplicationMaster通信的,而ApplicationMaster是负责进行Container的管理的:
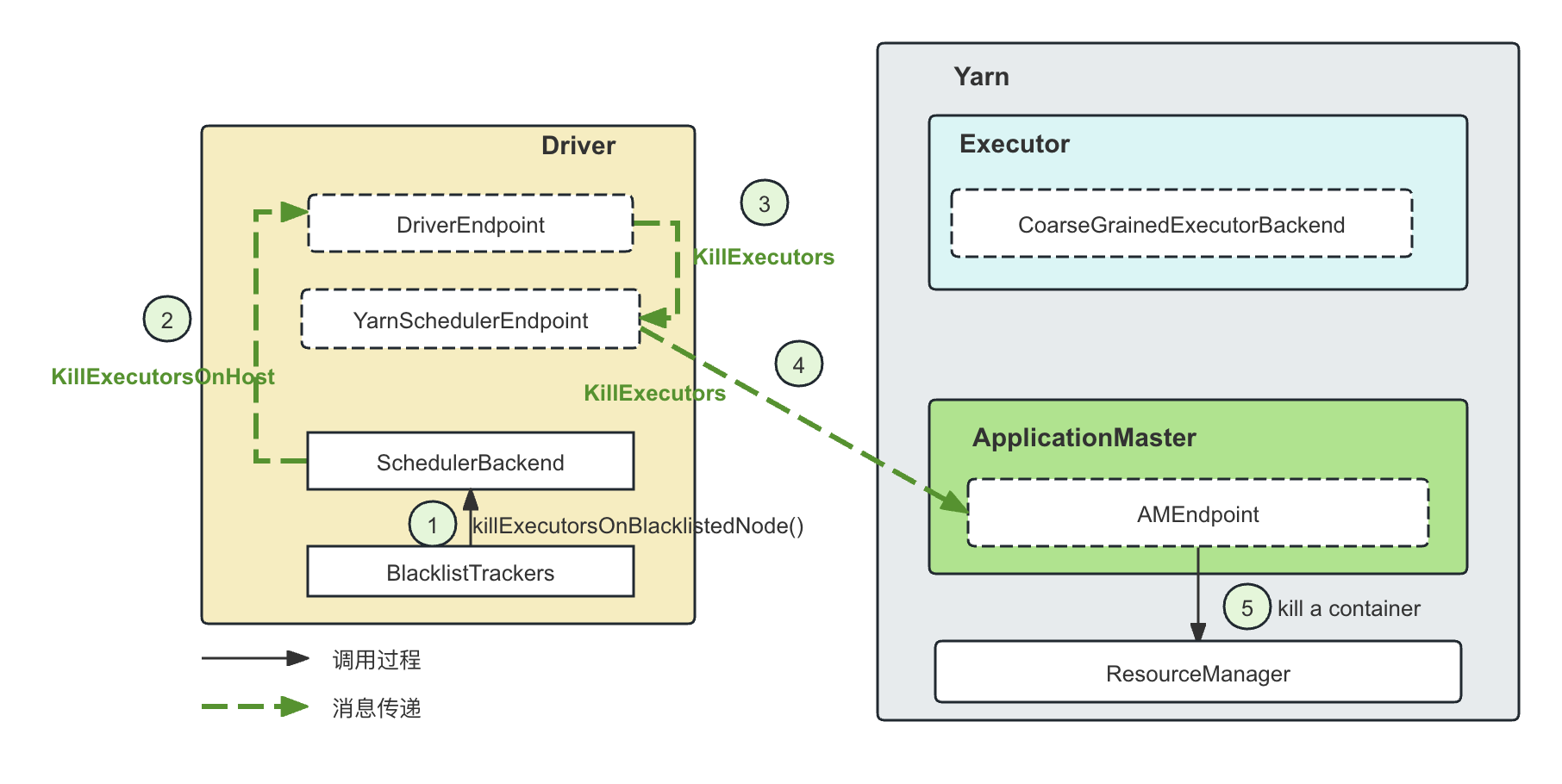
case KillExecutorsOnHost(host) => scheduler.getExecutorsAliveOnHost(host).foreach { exec => killExecutors(exec.toSeq, replace = true, force = true) } -
RemoveExecutor消息
DriverEndpoint收到了RemoveExecutor消息,会通过自己维护的executorDataMap向对应的ExecutorEndpoint发送StopExecutor消息,然后进行一些必要的清理工作
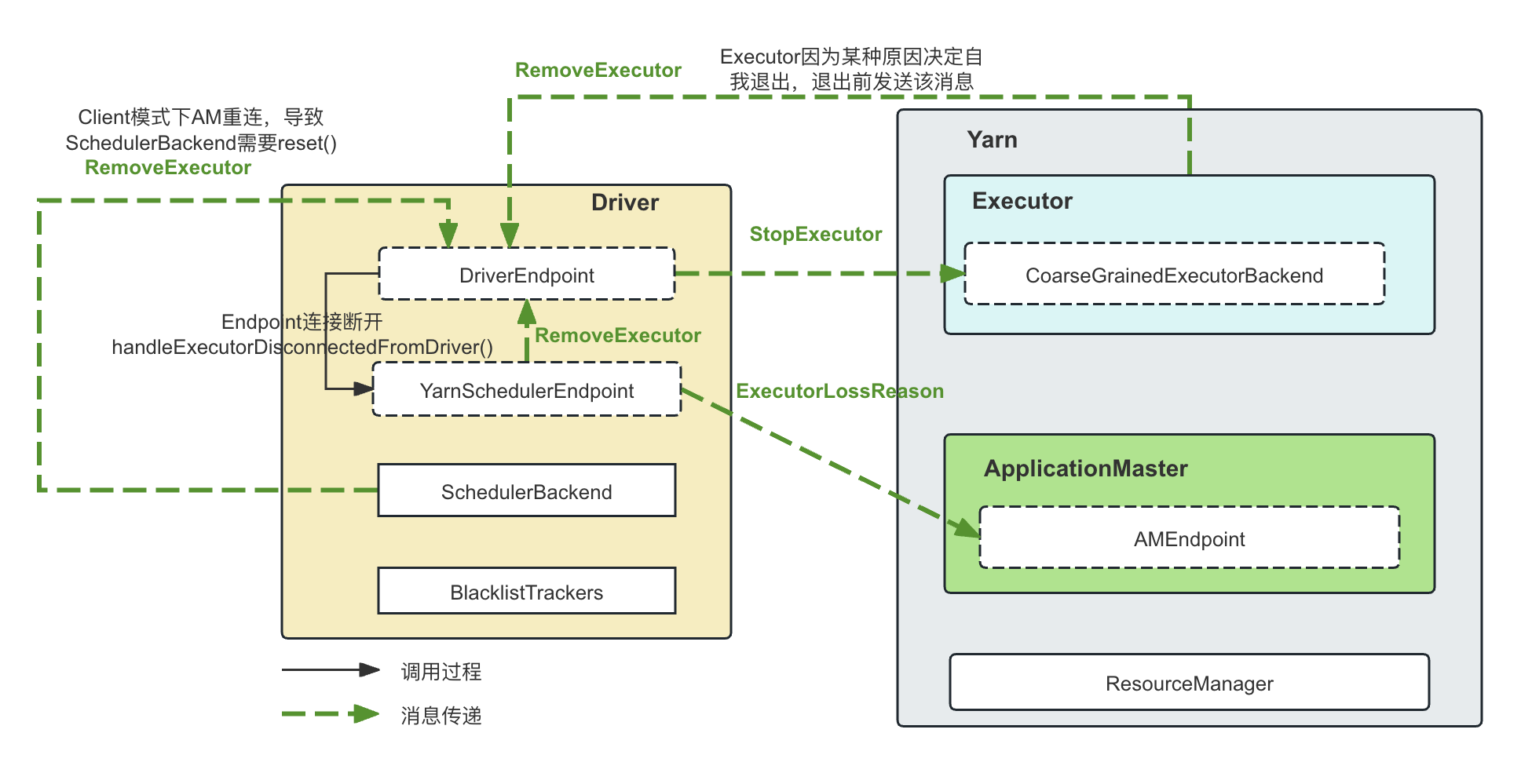
RemoveExecutor这个消息被触发发生的场景比较多,主要包括:
-
场景1: DriverEndpoint是和多个Executor建立连接的,一旦连接以外断开,RpcEndpoint的接口onDisconnected()会被回调以通知这个DriverEndpoint。在Yarn的场景下,DriverEndpoint的子类是YarnDriverEndpoint(注意不是YarnSchedulerEndpoint),YarnDriverEndpoint只重写了一个方法onDisconnected(),用来在收到connection断开的时候,调用YarnSchedulerEndpoint.handleExecutorDisconnectedFromDriver()来进行处理:
private[YarnSchedulerBackend] def handleExecutorDisconnectedFromDriver( executorId: String, executorRpcAddress: RpcAddress): Unit = { val removeExecutorMessage = amEndpoint match { case Some(am) =>a val lossReasonRequest = GetExecutorLossReason(executorId) am.ask[ExecutorLossReason](lossReasonRequest, askTimeout) .map { reason => RemoveExecutor(executorId, reason) }(ThreadUtils.sameThread) .recover { RemoveExecutor(executorId, SlaveLost()) }(ThreadUtils.sameThread) } removeExecutorMessage.foreach { message => driverEndpoint.send(message) } }具体步骤为:
-
向ApplicationMaster发送GetExecutorLossReason消息,企图获取对应的Executor断开连接的原因
am.ask[ExecutorLossReason](lossReasonRequest, askTimeout) -
组装对应的RemoveExecutor消息,发送给DriverEndpoint
removeExecutorMessage.foreach { message => driverEndpoint.send(message) }
-
-
场景2: 消息来自Executor,包括:
-
CoarseGrainedExecutorBackend在启动的时候会向DriverEndpoint注册自己,如果注册失败,会立刻向DriverEndpoint发送一个RemoveExecutor消息,然后退出自己的Executor进程
override def onStart() { ....... ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls)) }(ThreadUtils.sameThread).onComplete { ... case Failure(e) => exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false) }(ThreadUtils.sameThread) } -
CoarseGrainedExecutorBackend也是一个RpcEndpoint,同样也实现了RpcEndpoint.onDisconnected()方法。当连接中断,onDisconnected()方法被调用,也会向DriverEndpoint发送RemoveExecutor消息
override def onDisconnected(remoteAddress: RpcAddress): Unit = { exitExecutor(1, s"Driver $remoteAddress disassociated! Shutting down.", null, notifyDriver = false) } protected def exitExecutor(code: Int, notifyDriver: Boolean = true) = { ... driver.get.send(RemoveExecutor(executorId, new ExecutorLossReason(reason))) System.exit(code) } -
CoarseGrainedExecutorBackend在运行过程中发生任何情况失败导致Executor必须退出的时候,比如,收到DriverEndpoint的RegisteredExecutor时候构造Executor对象失败,启动task失败等等无可挽回的情况,会在进程退出前向DriverEndpoint发送RemoveExecutor消息以告知:
override def receive: PartialFunction[Any, Unit] = { case RegisteredExecutor => try { executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false) } catch { case NonFatal(e) => exitExecutor(1, "Unable to create executor due to " + e.getMessage, e) } case RegisterExecutorFailed(message) => exitExecutor(1, "Slave registration failed: " + message) case LaunchTask(data) => if (executor == null) { exitExecutor(1, "Received LaunchTask command but executor was null") } case KillTask(taskId, _, interruptThread, reason) => if (executor == null) { exitExecutor(1, "Received KillTask command but executor was null") } else { executor.killTask(taskId, interruptThread, reason) }
-
-
场景3:
在Client模式下,假如ApplicationMaster重新向客户端的Driver注册自己,那么CoarseGrainedSchedulerBackend会调用reset()进行充值,这时候会向DriverEndpoint(同一进程)发送RemoveExecutor消息。
我们再来看一下DriverEndpoint的另外一个方法receiveAndReply(),前面已经讲过,这个方法要求收到消息的RpcEndpoint通过传入的RpcCallContext句柄对消息进行回复:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { // 收到 RegisterExecutor 请求,这个请求发生在Executor启动以后,向Driver发送的信息 case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) => .... case StopDriver => context.reply(true) stop() case StopExecutors => .... for ((_, executorData) <- executorDataMap) { executorData.executorEndpoint.send(StopExecutor) } context.reply(true) case RemoveWorker(workerId, host, message) => removeWorker(workerId, host, message) context.reply(true) -
-
RegisterExecutor消息:
顾名思义,就是Executor的注册消息。当Executor启动的时候,Executor端的RpcEnv会以Client模式启动(参考TODO中讲述RpcEnv的Cluster和Client模式的区别),然后将自己注册到Driver: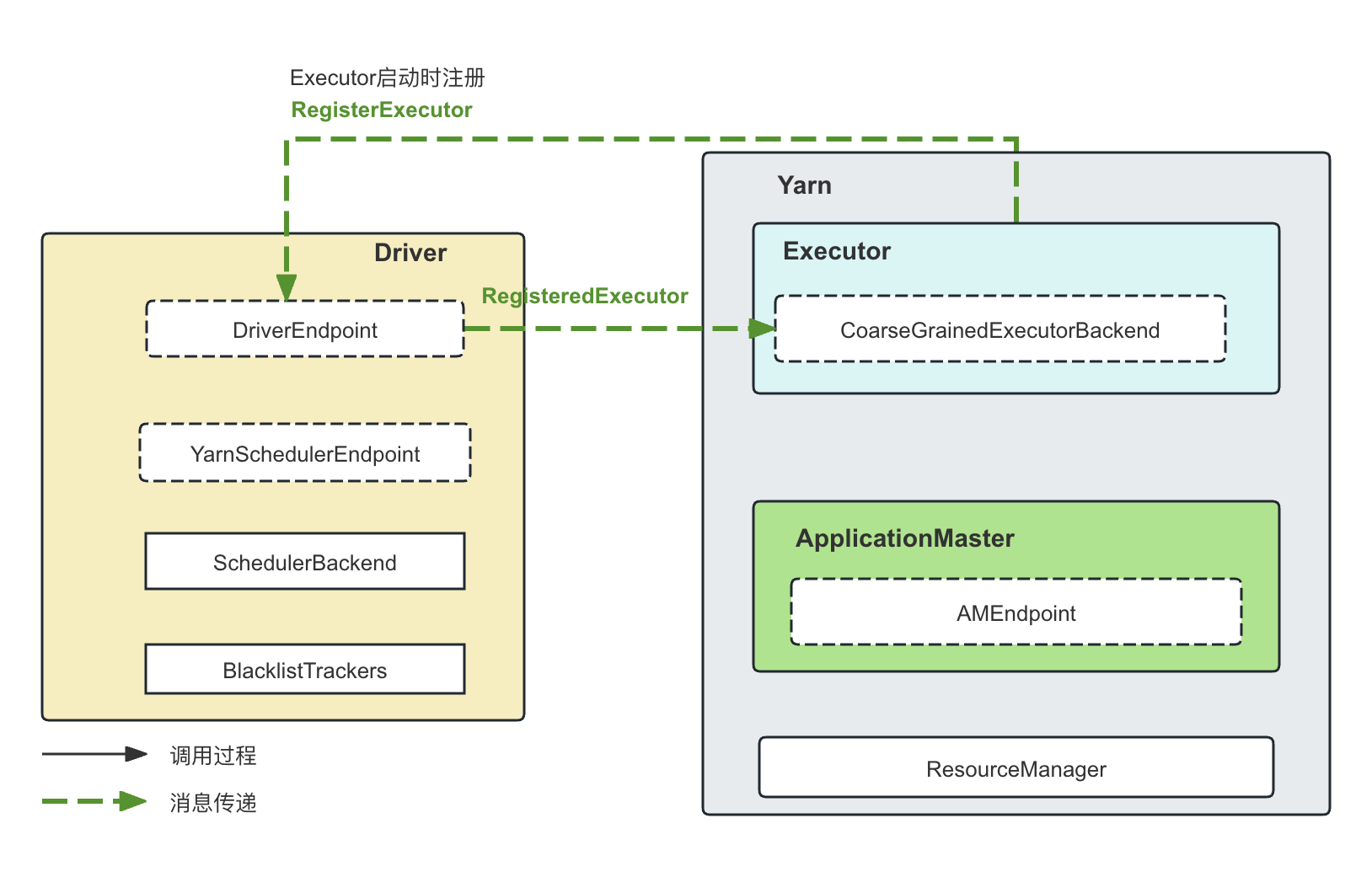
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) => ..... addressToExecutorId(executorAddress) = executorId // Executor ID .... val data = new ExecutorData(executorRef, executorAddress, hostname, cores, cores, logUrls) // This must be synchronized because variables mutated // in this block are read when requesting executors CoarseGrainedSchedulerBackend.this.synchronized { executorDataMap.put(executorId, data) ....... } executorRef.send(RegisteredExecutor) // 向Executor发送消息,注意,这里发送消息借用的是传过来的RpcEndpointRef context.reply(true) // 回复消息 listenerBus.post( SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data)) makeOffers() // 在这里进行task的重新调度和分配,因为毕竟有新的Executor假如进来,资源变多了,有必要看看是否有因为资源问题而pending的task }从上面的代码可以看到:
- 收到的RegisterExecutor消息包含了ExecutorID,这个Executor的RpcEndpoint所对应的RpcEndpointRef,以及这个Executor的其他信息比如hostname,cores,和logUrls
RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) - 将受到的消息组装成一个ExecutorData,存放到executorDataMap中
val data = new ExecutorData(executorRef, executorAddress, hostname, cores, cores, logUrls) CoarseGrainedSchedulerBackend.this.synchronized { executorDataMap.put(executorId, data) ....... } - 使用传过来的RpcEndpointRef,向Executor发送一个RegisteredExecutor消息。这仅仅是一条带有标记意味的、不带任何其他信息的消息。
关于这个RpcEndpointRef是怎么通过消息发送过来的,参考TODO文章。executorRef.send(RegisteredExecutor) // 向Executor发送消息,注意,这里发送消息借用的是传过来的RpcEndpointRef - 使用RpcCallContext句柄,回复一个true,代表消息已经收到。
为什么先向Executor发送一条消息,然后才回复true?我猜想是为了先向Executor发送一条探测消息,确认Executor刚刚发送过来的这个RpcEndpointRef是正常可用的,然后才给Executor回复,避免Executor发送过来的RpcEndpointRef无法正常使用,却还是通过RpcCallContext进行了回复。context.reply(true) // 回复消息 - 向ListenerBus中加入SparkListenerExecutorAdded事件,这样凡是在这个ListenerBus上订阅了这个事件的Listener都会收到消息并进行对应处理
listenerBus.post( SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data)) - 进行资源的重新调度。一个新的Executor注册过来,系统的可用资源变多,因此有必要进行资源的重新调度。再次强调,这里并不是生成新的Task,而是尝试检查Pending的Task然后尝试将Task调度出去。
makeOffers() // 在这里进行task的重新调度和分配,因为毕竟有新的Executor假如进来,资源变多了,有必要看看是否有因为资源问题而pending的task
- 收到的RegisterExecutor消息包含了ExecutorID,这个Executor的RpcEndpoint所对应的RpcEndpointRef,以及这个Executor的其他信息比如hostname,cores,和logUrls
-
StopDriver消息
顾名思义,就是停止Driver。通过调用堆栈,我们可以看到这来自SparkContext.stop()方法,这时候会通过DAGScheduler.stop() -> TaskScheduler.stop() -> CoarseGrainedSchedulerBackend.stop() 来让DriverEndpoint停止(RpcEndpoint的stop)
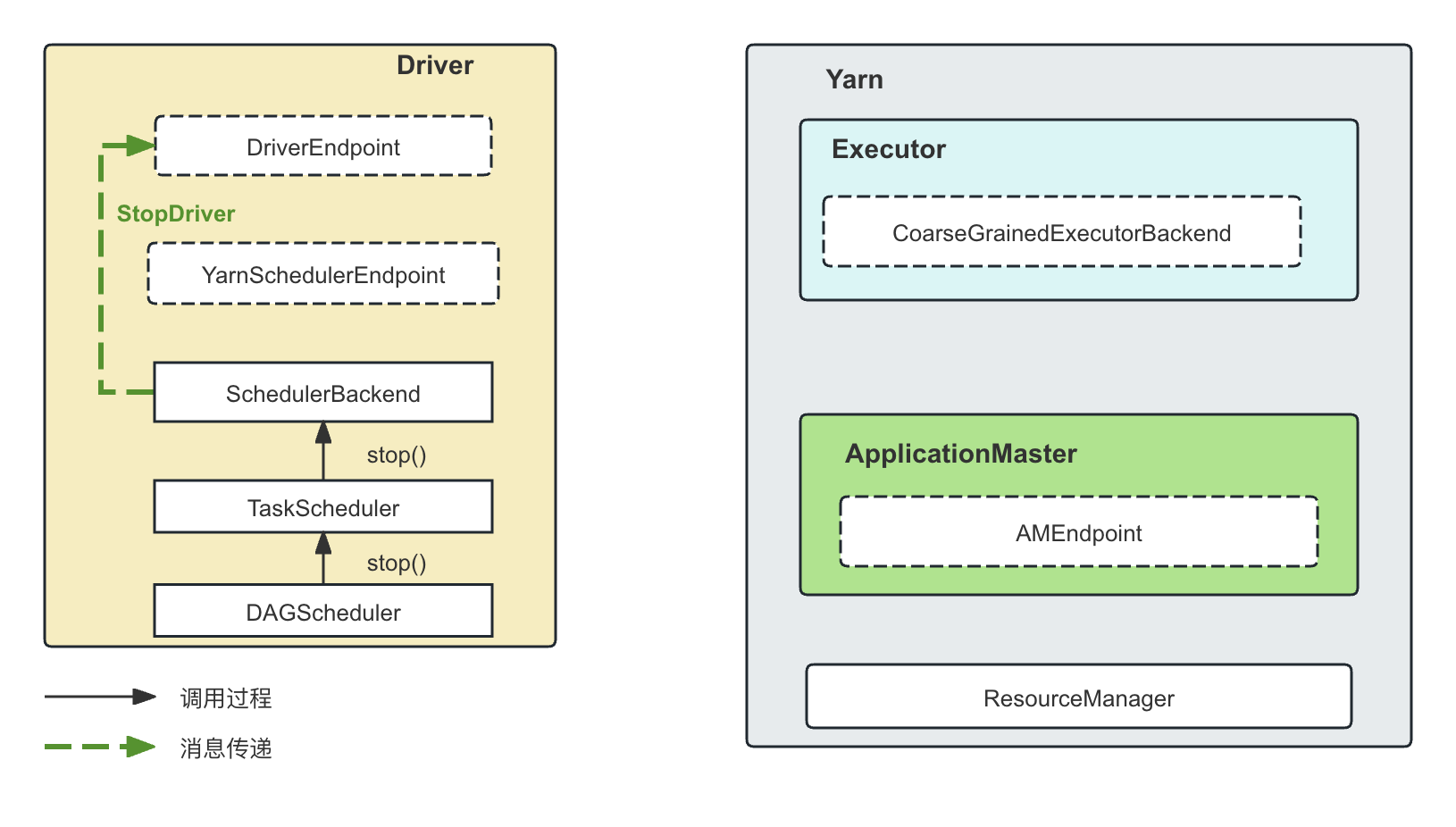
-
StopExecutors消息
和StopDriver的调用堆栈完全相同,当SparkContext.stop()方法调用的时候,既要求停掉Driver,也要求停掉Executor,这时候会给DriverEndpoint发送StopExecutors消息,DriverEndpoint然后给所有的Executor发送StopExecutor消息
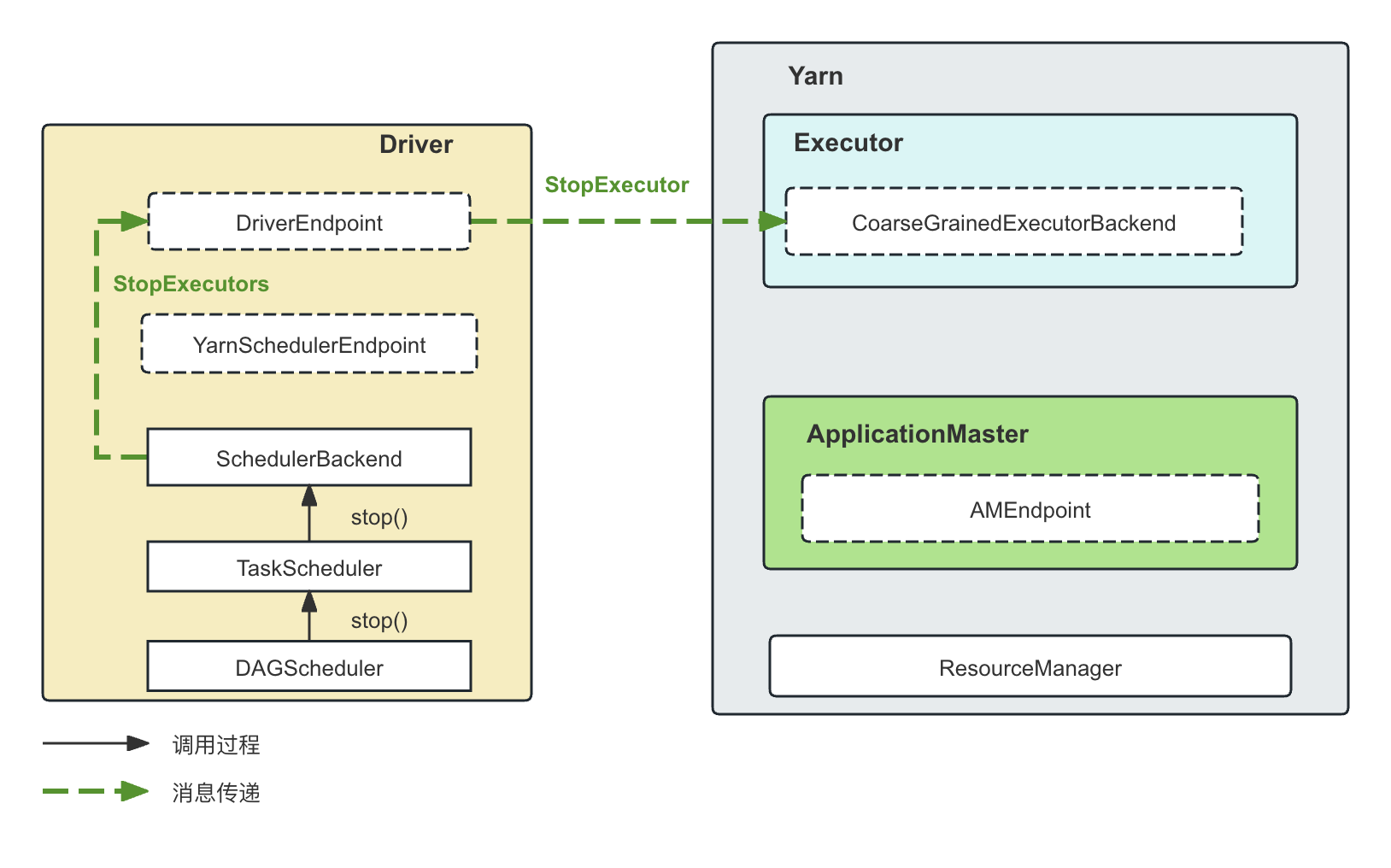
-
RemoveWorker消息
这个消息只在Standalone模式下发生,当一个Worker丢失的时候,会给DriverEndpoint发送RemoveWorker消息,具体细节这里不做赘述。
YarnSchedulerEndpoint的处理逻辑
前面说过,YarnSchedulerEndpoint所在的YarnSchedulerBackend类是DriverEndpoint所在的类CoarseGrainedSchedulerBackend的子类,因此,YarnSchedulerEndpoint是对DriverEndpoint的补充,主要负责和Yarn资源管理器的场景下和ApplicationMaster进行通信,其主要处理的消息有:
-
RegisterClusterManager消息
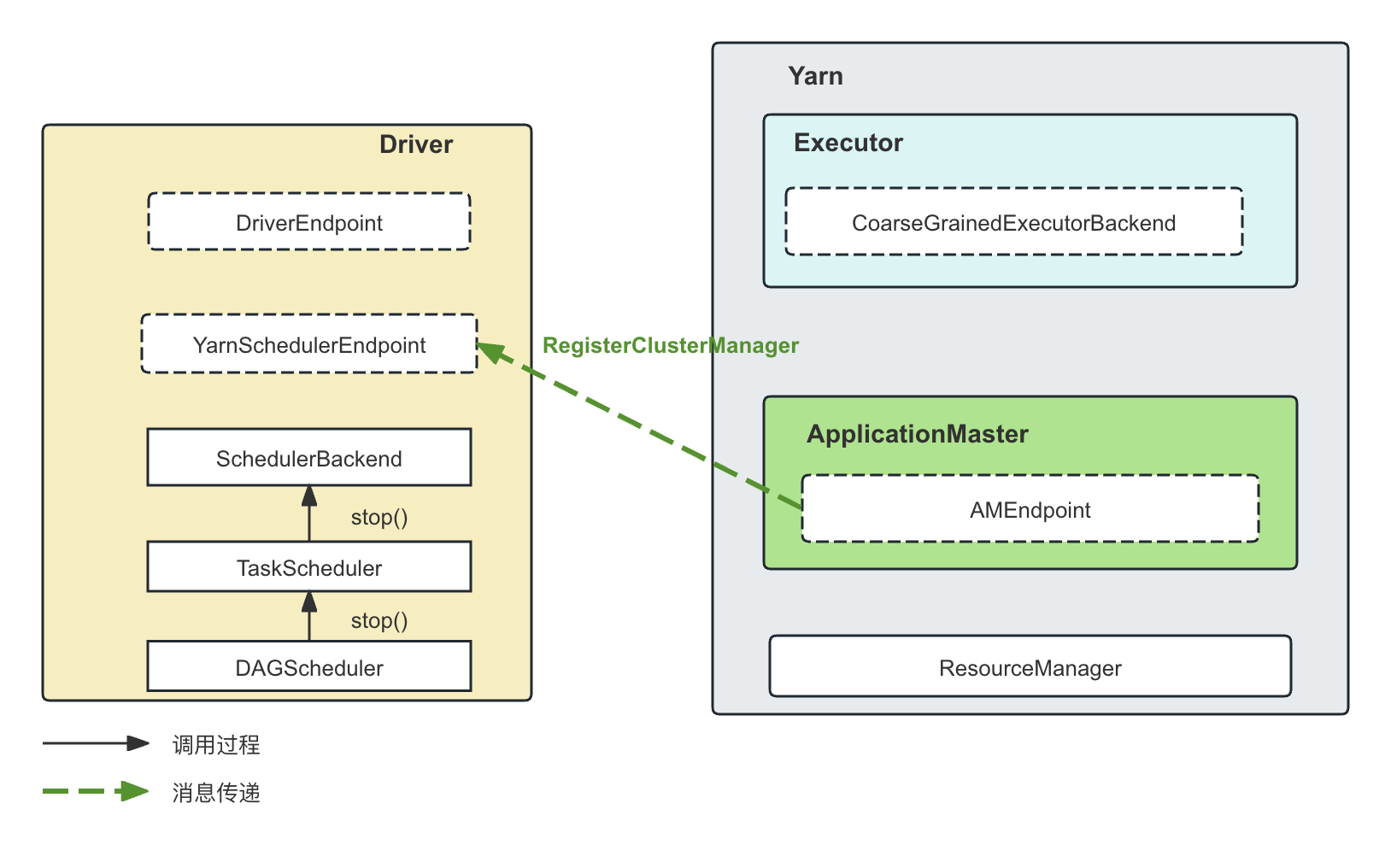
ApplicationMaster启动时的注册消息,收到消息以后,RegisterClusterManager将持有ApplicationMaster的RpcEndpointRef。从而可以向ApplicationMaster发送对应的资源请求消息。这里不再赘述。 -
RequestExecutors消息
这是进行资源申请(注意区分资源申请和资源申请以后的Task调度)的核心方法。这个消息的含义是Driver告知ApplicationMaster当前总的Executor的需求情况,而不是申请新的Executor。在TODO这篇文章中我们介绍到,ApplicationMaster会根据Request Executors消息中总的状态和当前Yarn上Executor运行的状态,决策出和Yarn进行交互的增量需求。
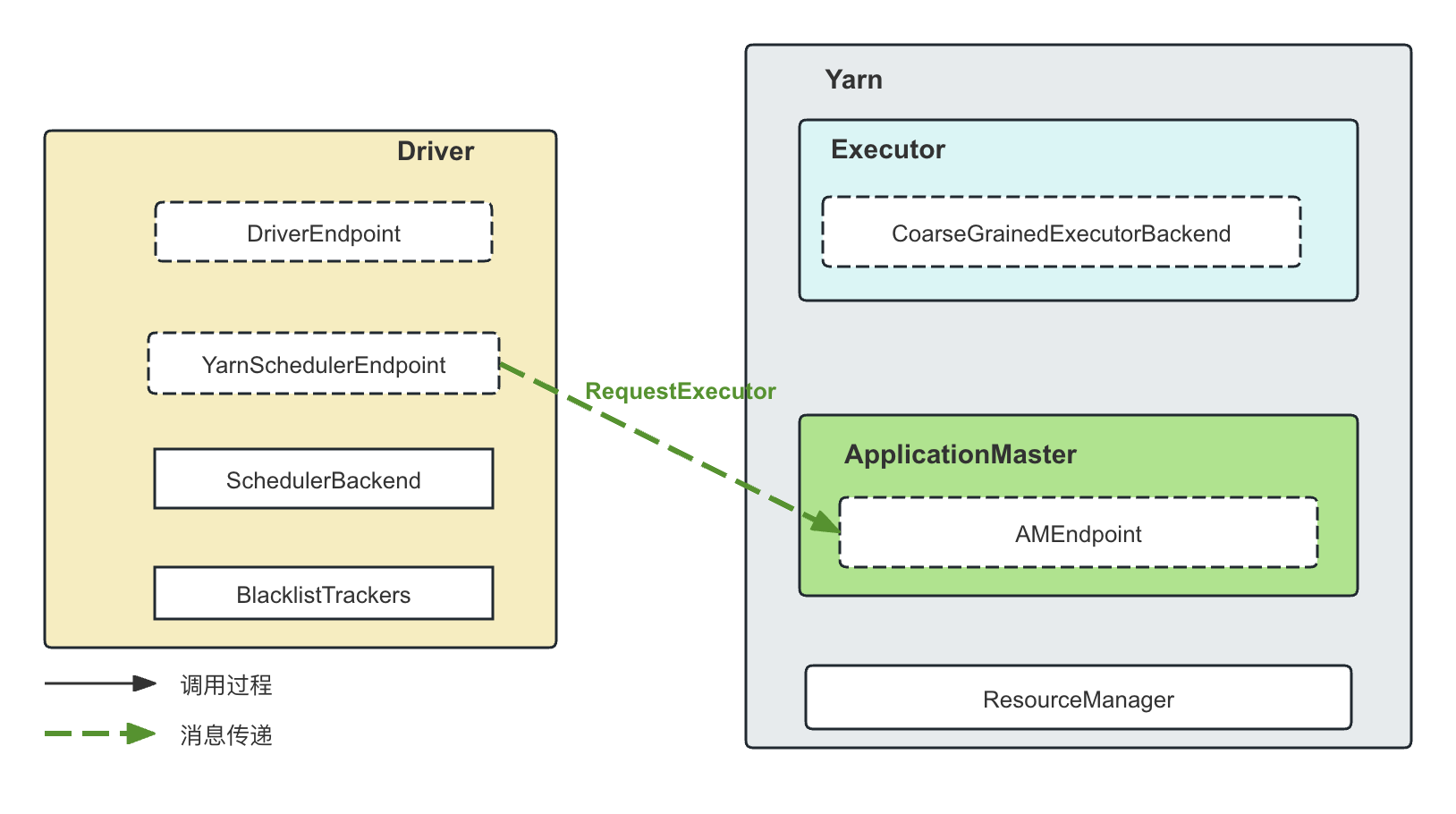
YarnSchedulerEndpoint其实是作为消息的转发者,在收到RequestExecutors请求以后会把消息转发给ApplicationMaster的AMEndpoint,AMEndpoint进而转换成Yarn可以理解的增量请求。那么,谁会给YarnSchedulerEndpoint发送RequestExecutors消息呢?是来自动态资源分配的类ExecutorAllocationManager。该类根据当前的需要申请Executor的时候,委托CoarseGrainedSchedulerBackend.requestTotalExecutors()方法进行申请,这个方法会向YarnSchedulerEndpoint(在本地)发送RequestExecutors消息,YarnSchedulerEndpoint随后将这个消息发送给远程的ApplicationMaster。RequestExecutors消息里面携带了请求的Executor收到总数量(注意是总数量,即状态量,而不是增量)、Task的数量以及Locality的相应信息:
case class RequestExecutors( requestedTotal: Int, // 请求的executor的总数量 localityAwareTasks: Int, // task的数量 hostToLocalTaskCount: Map[String, Int], // host以及希望分配到这个host的task的数量 nodeBlacklist: Set[String]) extends CoarseGrainedClusterMessage在TODO这篇文章中介绍过,ApplicationMaster收到消息以后,会根据locality等关键信息,和Yarn进行交互,申请Executor。
任何其他的集群总数量发生变化的情况,都会调用CoarseGrainedSchedulerBackend.doRequestTotalExecutors(),通过YarnSchedulerEndpoint告知远程的AM当前资源总需求的最新状态,AM从而和Yarn进行增量操作。我们从doRequestTotalExecutors()的调用堆栈可以看到,即使是KillExecutor,由于集群总的Executor的需求发生了变化,也可能需要通过doRequestTotalExecutors()方法来更新状态,所以doRequestTotalExecutors并不仅仅指的是申请资源,而是更新资源。 -
KillExecutors 消息
YarnSchedulerEndpoint在收到KillExecutors消息的时候是直接转发给ApplicationMaster的。
这个KillExecutor消息是通过CoarseGrainedSchedulerBackend.killExecutors()调用,将KillExecutors消息发送给YarnScheduerEndpoint,然后YarnScheduerEndpoint会将消息转发给AM。
CoarseGrainedSchedulerBackend.killExecutors()被调用的情况:- BlacklistTracker根据黑名单策略以后的决定,进而调用CoarseGrainedSchedulerBackend.killExecutors()。
- DriverEndpoint收到了KillExecutorsOnHost消息以后,进而调用CoarseGrainedSchedulerBackend.killExecutors()。
- 一个Executor节点长期没有心跳,HeartbeatReceiver会在expireDeadHosts()中通过killExecutorThread异步杀死Executor,进而调用CoarseGrainedSchedulerBackend.killExecutors()。
3.3 SparkDriver和ApplicationMaster的通信
ApplicationMaster的构建
ApplicationMaster就是Spark on Yarn的Main Class。因此其启动是从main方法开始的:
def main(args: Array[String]): Unit = {
val amArgs = new ApplicationMasterArguments(args)
master = new ApplicationMaster(amArgs)
System.exit(master.run())
}
在run()方法中,就是让ApplicationMaster在当前的ugi中运行runImpl()方法:
final def run(): Int = {
doAsUser {
runImpl()
}
exitCode
}
private def doAsUser[T](fn: => T): T = {
ugi.doAs(new PrivilegedExceptionAction[T]() {
override def run: T = fn
})
}
runImpl() 代码如下:
private def runImpl(): Unit = {
try {
......
// If the credentials file config is present, we must periodically renew tokens. So create
// a new AMDelegationTokenRenewer
if (sparkConf.contains(CREDENTIALS_FILE_PATH)) {
// Start a short-lived thread for AMCredentialRenewer, the only purpose is to set the
// classloader so that main jar and secondary jars could be used by AMCredentialRenewer.
val credentialRenewerThread = new Thread {
.....
}
}
credentialRenewerThread.start()
}
if (isClusterMode) {
runDriver() // 在Cluster模式下,driver和application master是运行在一起的
} else {
runExecutorLauncher() // 在Client模式下,driver运行在客户端,已经运行起来了
}
} catch {
.......
}
}
- 如果Enable了Security,那么会启动一个Credential Renew线程,对集群所有节点的Credential在过期前进行续约。这个跟认证相关,本文不做详细讲解:
..... credentialRenewerThread.start() - 上文讲过,根据当前是Cluster模式还是Client模式,走向不同的运行方式。如果是Cluster模式,那么调用runDriver(),因为Cluster模式下,Driver是运行在ApplicationMaster中。如果是Client模式,则调用runExecutorLauncher(),这里的ExeuctorLauncher就是负责资源管理的、单纯的ApplicationMaster角色,核心就是AMEndpoint。当然,runDriver()中也会启动一样的AMEndpoint,只不过由于此时Driver和AMEndpoint运行在一个进程中,因此他们之间的通信实际上不需要RPC,而是同一进程内部的方法调用,但也是走的Actor的基本调用流程。
if (isClusterMode) { runDriver() // 在Cluster模式下,driver和application master是运行在一起的 } else { runExecutorLauncher() // 在Client模式下,driver运行在客户端,已经运行起来了 }
本文主要以Client模式为例讲解,但是其实无论是Client还是Cluster模式,资源管理逻辑是完全一致的。
在runExecutorLauncher()中,创建了RpcEnv和AMEndpoint,并将AMEndpoint注册给ApplicationMaster的RpcEnv:
// 从参数可以看到,这里的RpcEnv是Client模式
rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr, amCores, true)
// 和Driver进行通信,直到和Driver建立socket连接以确定Driver启动成功,返回Driver的RpcEndpointRef, 设置Driver的EndpointRef
val driverRef = waitForSparkDriver() // 等待远程的Driver处于Reader的状态
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))
runExecutorLauncher()的基本过程为:
-
创建RpcEnv
在TODO中讲过,RpcEnv的启动模式分为Client和Cluster模式。这里RpcEnv的启动是Client模式启动的,这说明ApplicationMaster是不需要一个固定监听端口进行监听的,因为ApplicationMaster启动的时候会通过RegisterClusterManager的方式将自己的RpcEndpointRef发送给Driver端的YarnSchedulerEndpoint,基于TODO中讲过的RpcEndpointRef的序列化和反序列化,YarnSchedulerEndpoint对YarnSchedulerEndpoint进行反序列化以后会自动持有了这个RPC 长连接,从而可以随时用这个RpcEndpointRef对ApplicaitonMaster发送消息。rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr, amCores, true) -
等候Driver处于Ready的状态
在waitForSparkDriver()方法中,会与Driver建立Socket连接,并创建对应Driver的RpcEndpointRef来与Driver通信:
private def waitForSparkDriver(): RpcEndpointRef = { ...... while (!driverUp && !finished && System.currentTimeMillis < deadline) { val socket = new Socket(driverHost, driverPort) // socket建立成功,说明driver已经启动成功 driverUp = true } // 这里的scheduler指的是driver,设置Driver的EndpointRef,用来和Driver进行通信 createSchedulerRef(driverHost, driverPort.toString) } -
创建AMEndpoint并注册到RpcEnv
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))在这里,RegisterClusterManagerDriver消息中就封装了发送者(ApplicationMaster)的RpcEndpointRef,这个RpcEndpointRef在反序列化过程中已经将对应的通信信道设置在了其成员变量中,就好像整个通信信道都已经被成功地序列化和反序列化一样。在ApplicationMaster注册完成以后,Driver就可以根据需要跟Yarn上的ApplicationMaster通信。 参考TODO所讲解的RpcEndpointRef的序列化。
在ApplicationMaster的RpcEnv端处理AMEndpoint注册的时候,主要是创建了一个org.apache.spark.deploy.yarn.YarnRMClient对象,这个Spark端的对象YarnRMClient通过封装的Yarn的标准客户端AMRMClient来代理AM的注册、解除注册,以及创建一个Spark端的YarnAllocator对象,用来进行具体的Executor资源的请求。所以,Spark的两个对象YarnRMClient和YarnAllocator其实都借助于Yarn的标准客户端AMRMClient和Yarn交互,而YarnRMClien负责AM的注册、解除注册,而YarnAllocator负责具体的、复杂的动态资源管理。
-------------------------------------------- ApplicationMaster -----------------------------
private def registerAM(
_sparkConf: SparkConf,
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: Option[String]) = {
.....
// 通过Driver向Yarn提交应用的时候的配置项获取Driver的信息,构建Driver的Endpoint信息,
// ENDPOINT_NAME 是 CoarseGrainedScheduler
val driverUrl = RpcEndpointAddress( _sparkConf.get("spark.driver.host"), _sparkConf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
// 调用了 Yarn的标准API, 即接口register() 方法来注册这个ApplicationMaster,返回用来负责进行资源请求的YarnAllocator对象
allocator = client.register(driverUrl, driverRef, ..... localResources)
// 创建AMEndpoint并注册到RpcEnv
rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
// 开始进行资源的分配
allocator.allocateResources()
// 日志 “Started progress reporter thread with”打印了,说明launchReporterThread已经执行了
reporterThread = launchReporterThread() //这个方法是异步方法,在这个异步方法的线程中也会执行 allocateResources
}
-
构建用于资源分配的YarnAllocator对象。上面讲过,YarnAllocator是对Yarn的标准API AMRMClient的封装:
// 调用了 Yarn的标准API, 即接口register 方法来注册这个ApplicationMaster,返回用来负责进行资源请求的YarnAllocator对象 allocator = client.register(driverUrl, driverRef, ..... localResources)YarnRMClient.register()方法就是创建一个YarnAllocator对象:---------------------------------- YarnRMClient ---------------------------------------- def register( driverUrl: String, driverRef: RpcEndpointRef, ...... ): YarnAllocator = { // 创建AMRMClient对象,并进行初始化和启动 amClient = AMRMClient.createAMRMClient() amClient.start() logInfo("Registering the ApplicationMaster") synchronized { // 调用AMRMClient的registerApplicationMaster接口注册自己 amClient.registerApplicationMaster(Utils.localHostName(), 0, trackingUrl) registered = true } // 返回一个YarnAllocator对象,封装了AMRMClient对象,driver的地址信息,以及一个SparkRackResolver对象,用来解析网络拓扑 new YarnAllocator(driverUrl, driverRef, conf, sparkConf, amClient, getAttemptId(), securityMgr, localResources, new SparkRackResolver()) } -
创建AMEndpoint并注册到以Client模式运行的RpcEnv。
------------------------------------------ ApplicationMaster ----------------------------- val driverUrl = RpcEndpointAddress( _sparkConf.get("spark.driver.host"), _sparkConf.get("spark.driver.port").toInt, CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString // 调用了 Yarn的标准API, 即接口register 方法来注册这个ApplicationMaster,返回用来负责进行资源请求的YarnAllocator对象 allocator = client.register(driverUrl, driverRef, ..... localResources)实际上,在AMEndpoint这个RpcEndpoint启动(构造)的时候,就会向远程的Driver发送RegisterClusterManager消息注册自己(区别Executor启动的时候发送过来的RegisterExecutor, RegisterExecutor消息发送给Driver端的DriverEndpoint,而RegisterClusterManager是发送给专门和AM通信的Driver端的YarnSchedulerEndpoint):
------------------------------------- AMEndpoint ------------------------------------------ private class AMEndpoint(override val rpcEnv: RpcEnv, driver: RpcEndpointRef) extends RpcEndpoint with Logging { override def onStart(): Unit = { driver.send(RegisterClusterManager(self)) // ApplicationMaster启动的时候,向Driver发送RegisterClusterManager }DriverEndpoint收到了注册信息,会保存好ApplicationMaster的RpcEndpointRef:
---------------------------------- YarnSchedulerBackend -------------------------------- override def receive: PartialFunction[Any, Unit] = { case RegisterClusterManager(am) => // 收到ApplicationMaster启动的时候发过来的RegisterClusterManager请求 logInfo(s"ApplicationMaster registered as $am") amEndpoint = Option(am) // 收到了远程的AM的注册信息,设置这个am的RpcEndpointRef reset() -
启动资源分配。这里就是调用的是YarnAllocator.updateResource()方法,同时,也启动了一个后台线程,本质上,其做的事情也是不断调用YarnAllocator.updateResource()同Yarn交互进行Container的管理:
------------------------------------- ApplicationMaster -------------------------------- // 开始进行资源的分配 allocator.allocateResources() // 日志 “Started progress reporter thread with”打印了,说明launchReporterThread已经执行了 reporterThread = launchReporterThread() //这个方法是异步方法,在这个异步方法的线程中也会执行 allocateResources
3.4 ApplicationMaster和Yarn ResourceManager的通信
ApplicationMaster和Yarn ResourceManager的通信,在我的TODO中进行了详细的介绍。这里不再赘述。
3.5 Executor的启动以及与Driver通信的建立
我们看Executor的进程信息,可以看到Executor端的main class是CoarseGrainedExecutorBackend(区分Driver端的CoarseGrainedSchedulerBackend)。
必须了解,Executor的启动参数等信息,是ApplicationMaster组装并发送给Yarn的NodeManager并启动的,而不是客户端发送给NodeManager并启动的。
Executor的CoarseGrainedExecutorBackend.run()方法(注意不是Driver端的CoarseGrainedSchedulerBackend)会构建用来和Driver通信的Endpoint(这里Driver端的Endpoint是DriverEndpoint,而不是YarnSchedulerEndpoint,上面已经讲过二者区别):
----------------------------------------- SparkEnv -----------------------------------------
// 创建一个RpcEnv
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, cores, cfg.ioEncryptionKey, isLocal = false)
其实,SparkContext中构建Driver的Env和这里构建Executor的Env,都是调用的SparkEnv.create(),这里的Env包含的是Driver和Executor的整个运行环境和基本条件,RpcEnv只是整个需要构造的事务的一部分。方法SparkEnv.create()封装了Driver和Executor在构建起基本运行环境的共同过程包括了:
-
构建RpcEnv以进行RPC通信,其中Driver和Executor在这里出现巨大区别,后面会讲到
----------------------------------------- SparkEnv ----------------------------------------- val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf, securityManager, numUsableCores, !isDriver) -
初始化Serializer,Driver和Executor都需要进行数据的读写和序列化:
----------------------------------------- SparkEnv ----------------------------------------- val serializer = instantiateClassFromConf[Serializer]( "spark.serializer", "org.apache.spark.serializer.JavaSerializer") logDebug(s"Using serializer: ${serializer.getClass}") val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey) -
构建广播变量管理器BroadcastManager
val broadcastManager = new BroadcastManager(isDriver, conf, securityManager) -
构建对应的MapOutputTracker,在Driver和Executor,他们分别是MapOutputTrackerMaster和MapOutputTrackerExecutor,同时也将对应的Endpoint注册到这个RpcEnv:
val mapOutputTracker = if (isDriver) { new MapOutputTrackerMaster(conf, broadcastManager, isLocal) } else { new MapOutputTrackerWorker(conf) } -
初始化MemoryManager
// 将ExecutorEndpoint绑定到自己的RpcEnv env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend( env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env)) -
构建BlockManager
// NB: blockManager is not valid until initialize() is called later. val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster, serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager, blockTransferService, securityManager, numUsableCores)- 其他操作
我们这里重点关注的是与通信相关的的RpcEnv的构造过程。
-
在构建RpcEnv的时候,会根据当前是Driver还是Executor,决定是以Client模式还是Server模式启动RpcEnv(注意,这里的Client/Cluster模式不是Spark运行的Client和Cluster模式):
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf, securityManager, numUsableCores, !isDriver)- 如果是Driver进程,就以Cluster模式打开RpcEnv,因此会打开监听端口,
- 如果是Executor,就是以Client Mode启动RpcEnv,因此不会打开对应监听端口。
在我的另一篇文章TODO中,讲解了在Client模式下创建RpcEnv的通信特点,即,以Client模式打开的RpcEnv不会监听端口,而是将自己的EpvEndpointRef发送给对方(显然,对方必须是一个以Server模式启动的RpcEnv的RpcEndpoint),对方会通过当前建立的Socket连接跟客户端通信,这个通信链接是私有的,不会断开,但是同时也不可以被共享,即第三方的RpcEnv不可以通过Client模式打开的RpcEnv的端口与这个RpcEnv建立连接。
-
RpcEnv建立以后,就会将Executor端的RpcEndpoint绑定到这个RpcEnv,这个RpcEndpoint实现类是CoarseGrainedExecutorBackend(虽然没有以Endpoint作为类名结尾)
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend( env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))在我的TODO这篇文章中讲过,所有的RpcEndpoint都需要实现RpcEndpoint这个trait。启动时候的一些准备工作放在onStart()中。CoarseGrainedExecutorBackend这个RpcEndpoint在启动的时候只做了一件事,就是向Driver发送RegisterExecutor注册信息:
override def onStart() { rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref => // This is a very fast action so we can use "ThreadUtils.sameThread" driver = Some(ref) ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls)) } }可以看到,这个RegisterExecutor中就包含了self,即当前的RpcEndpointRef。在TODO这篇文章中我们会讲到,在Client模式下,这个RpcEndpointRef中的除了Socket部分无法被序列化外, 其它部分都被序列化并发送给对方,对方反序列话以后,会将当前的通信链接重新设置到RpcEndpointRef反序列化的连接变量中,看起来就好像socket连接也被序列化成功了一样。
3.6 Spark的操作与Yarn上的Container状态的对应关系
在本次事故中在ResourceManager端的代码我们可以看到,ResourceManager中Container的状态都进入了ACQURIED状态,但是无法进入Running状态。
这里看一下RUNNING状态以及前面的状态的基本含义,方便推测ApplicationMaster都Block在ACQURIED而无法进入RUNNING的可能原因。
关于Yarn中关于Container的状态机管理的基本原理, 可以参考这篇文章 《Yarn中的几种状态机》。
在ResourceManager这一层,一个Container对应了一个RMContainerImpl对象。
在RMContainerImpl类的静态代码快中,定义了ResourceManager端Container的生命周期管理的状态机:
-------------------------------------- RMContainerImpl ----------------------------------------
public class RMContainerImpl implements RMContainer, Comparable<RMContainer> {
....
private static final StateMachineFactory<RMContainerImpl, RMContainerState,
RMContainerEventType, RMContainerEvent>
stateMachineFactory = new StateMachineFactory<RMContainerImpl,
RMContainerState, RMContainerEventType, RMContainerEvent>(
RMContainerState.NEW)
// Transitions from NEW state
.addTransition(RMContainerState.NEW, RMContainerState.ALLOCATED,
RMContainerEventType.START, new ContainerStartedTransition())
// Transitions from ALLOCATED state
.addTransition(RMContainerState.ALLOCATED, RMContainerState.ACQUIRED,
RMContainerEventType.ACQUIRED, new AcquiredTransition())
.addTransition(RMContainerState.ACQUIRED, RMContainerState.RUNNING,
RMContainerEventType.LAUNCHED, new LaunchedTransition())
以下面的转换为例,我们来解释这个状态机的基本逻辑:
.addTransition(RMContainerState.ACQUIRED, RMContainerState.RUNNING,
RMContainerEventType.LAUNCHED, new LaunchedTransition())
这里的transition意味着,如果当前RMContainerState的状态是ACQUIRED,并且发生了事件,RMContainerEventType.LAUNCHED,那么,我们需要执行new LaunchedTransition(),并且把RMContainerState的状态更新为RUNNING。
在构造每一个RMContainerImpl的时候,都会为这个RMContainerImpl构建一个StateMachine对象,用来管理这个Container在ResourceManager端的状态演进:
public RMContainerImpl(Container container,
ApplicationAttemptId appAttemptId, NodeId nodeId,
String user, RMContext rmContext, long creationTime) {
this.stateMachine = stateMachineFactory.make(this);
this.containerId = container.getId();
本次事故发生的时候,所有Container的状态停留在ACQUIRED状态,但是无法进入正常的Running状态。
Container的所有状态定义在枚举类型RMContainerState中:
public enum RMContainerState {
NEW, // Container刚刚建立,还没有分配资源
RESERVED, // 为这个Container进行资源预留
ALLOCATED, // 已经为这个Container分配了节点
ACQUIRED, // ApplicationMaster已经获取了资源请求对应的分配节点的信息,剩下的就是ApplicationMaster拿着对应的NMToken通NodeManager进行通信从而启动container了
RUNNING, // 这个Container已经在对应的NodeManager上运行
COMPLETED, // 这个Conainer已经结束
EXPIRED, // 这个Container已经过期了
RELEASED, // 这个Container已经释放了
KILLED // 这个Container被杀死了
}
与我们的事故相关的状态,是ACQUIRED和RUNNING状态。整个状态转换如下图所示(如有侵权请联系我):
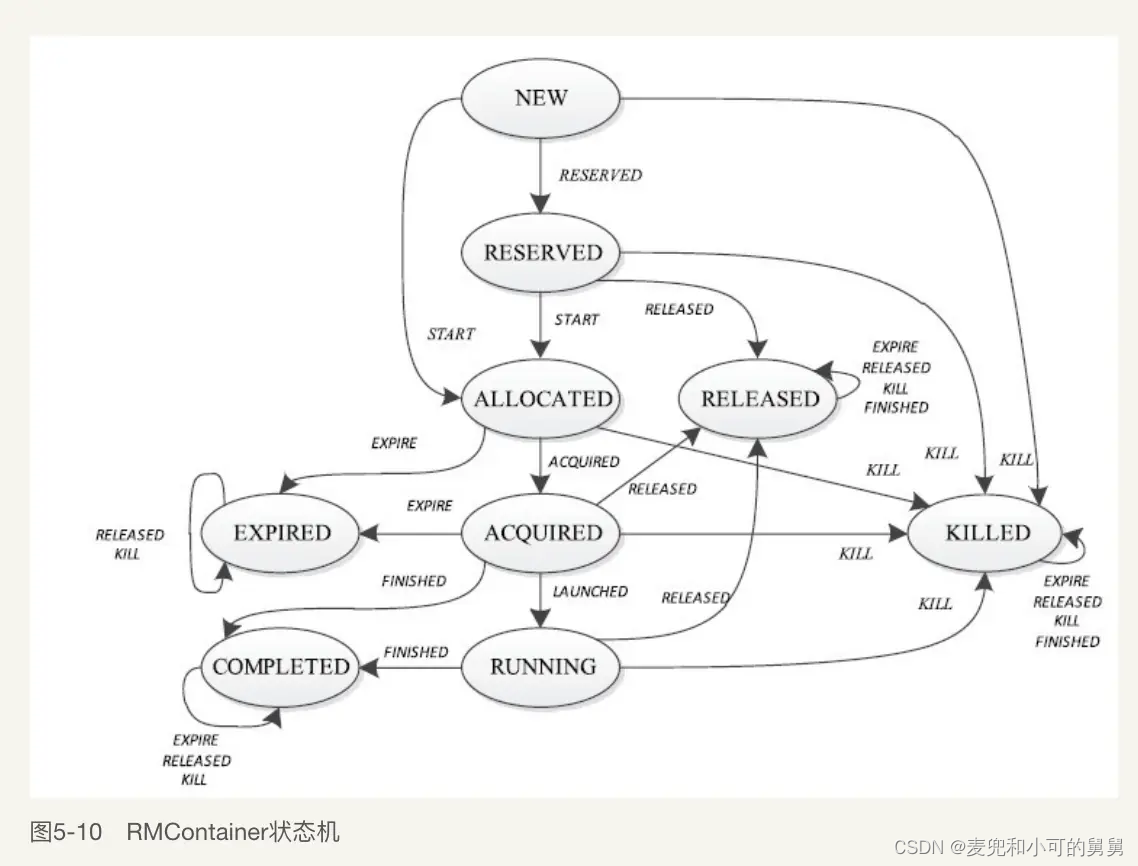
其中,和本次事故相关的状态包括:
- New状态:当一个RMContainerImpl刚构造但是还没有通过Scheduler分配资源的时候,处于New状态;
- Allocated状态:在ResourceManager这一端,Scheduler已经对这个Container分配了具体的资源(即这个Container在哪台机器上运行)。但是,这个分配结果还没有告知ApplicationMaster。关于Yarn的资源调度相关原理,请参考我的另外一篇文章:《Yarn资源调度请求和资源分配原理解析》
- Acquired状态:即资源分配的结果已经被ApplicationMaster获取到(acquired)。已经注册完成的ApplicationMaster通过AMRMClient的allocate()接口来向ResourceManager询问对应的Container的分配位置:
public abstract AllocateResponse allocate(float progressIndicator) throws YarnException, IOException; - Running状态:这个Container处于正在运行的状态。这个正在运行的状态是由NodeManager汇报上来的。launch一个container的基本过程是,ApplicationMaster通过allocate()接口获取了container分配的具体位置和对应的NodeManager的访问token,然后ApplicationMaster会携带着token,要求对应的NodeManager启动对应的Container。在Container启动以后,NodeManager会向ResourceManager汇报Container的Running状态。
状态转换的过程是:
-
从New到Allocated的状态转换、
我们看状态机的转换:// Transitions from NEW state .addTransition(RMContainerState.NEW, RMContainerState.ALLOCATED, RMContainerEventType.START, new ContainerStartedTransition())因此,RMContainerImpl处于NEW状态的时候,如果发生了RMContainerEventType.START事件,就会执行ContainerStartedTransition这个transition过程,同时状态转换为ALLOCATED。
什么时候会出现RMContainerEventType.START事件?
Yarn中是Scheduler的资源调度是根据当前队列的可用资源状态,从顶向下(从root queue一直遍历到leaf queue),然后对挂载在LeafQueue上的资源请求(ResourceRequest)进行资源分配。当对一个ResourceRequest进行了资源分配,就会为这个ResourceRequest创建一个Container,这个Container的初始状态是NEW,进行了资源的分配以后,会生成对应的RMContainerEventType.START,并进行状态转换:- 在Parent Queue层面进行分配:
------------------------------------------- FSParentQueue -------------------------------------------- public Resource assignContainer(FSSchedulerNode node) { ....... try { for (FSQueue child : childQueues) { // 遍历这个ParentQueue的所有LeafQueue进行资源分配 assigned = child.assignContainer(node); } return assigned; } - 在Leaf queue层面进行分配(由于可能存在多层,因此中间可能递归调用了多次FSParentQueue.assignContainer())
------------------------------------------- FSLeafQueue -------------------------------------------- public Resource assignContainer(FSSchedulerNode node) for (FSAppAttempt sched : fetchAppsWithDemand(true)) { // 遍历挂载在这个FSLeafQueue上的所有的FSAppAttempt,尝试进行资源分配 if (SchedulerAppUtils.isBlacklisted(sched, node, LOG)) { continue; } assigned = sched.assignContainer(node); - 在FSAppAttempt层面进行分配,即真正创建对应的Container:
调用堆栈如下图所示:-------------------------------------------- FSAppAttempt.java---------------------------------------- private Resource assignContainer( FSSchedulerNode node, ResourceRequest request, NodeType type, boolean reserved) { ....... // Create RMContainer RMContainer rmContainer = new RMContainerImpl(container, getApplicationAttemptId(), node.getNodeID(), appSchedulingInfo.getUser(), rmContext); ........ // // 在这里生成了START时间,CONTAINER的状态从初始化的NEW转换成ALLOCATED状态 rmContainer.handle( new RMContainerEvent(container.getId(), RMContainerEventType.START)); }
- 在Parent Queue层面进行分配:
-
从Allocated到Acquired的状态转换
我们看状态即的转换:// Transitions from ALLOCATED state .addTransition(RMContainerState.ALLOCATED, RMContainerState.ACQUIRED, RMContainerEventType.ACQUIRED, new AcquiredTransition())这说明,在ALLOCATED状态下的Container,当发生了RMContainerEventType.ACQUIRED事件,状态就会转换成ACQUIRED。
状态什么时候会发生ACQUIRED事件?
这是通过应用程序中的AMRMClient(一般是ApplicationMaster实现的)和Yarn这一端的ApplicationMasterServer通过allocate()接口来实现状态转换的。
在Yarn中,用户程序中的ApplicationMaster与Yarn进行资源相关的通信是基于ApplicationMasterProtocol(定义在ApplicationMasterprotocol.java中)接口进行的。其中最重要的接口就是allocate()。该接口有两个功能:- 资源分配请求:用户程序的ApplicationMaster使用这个接口提供一个资源请求(ResourceRequest)的list,或者将之前已经分配给这个Application但是这个Application由于没有使用而将对应的Container返还给Yarn。对于资源请求,Yarn收到请求以后并不会立刻阻塞式地进行资源分配,只是将对应资源请求记录下来(后面会异步分配)。
- 心跳:ApplicationMaster的心跳也是通过这个接口来进行的。可见,这个接口是需要在ApplicationMaster这一端不断进行调用的。
在收到allocate()请求以后,Yarn会返回给ApplicationMaster一系列已经分配(ALLOCATED)的Container。显然,基于异步的资源分配方式,这些已经分配的资源请求大概率应该不是本次调用allocate()方法的资源请求,而是前面某一次或者某几次调用allocate() 方法的资源请求。
在allocate()方法成功返回以后,Yarn认为这个异步分配的Container已经在ApplicationMaster端确认(Acquired),因此Container的状态会生成一个RMContainerEventType.ACQUIRED事件,Container的状态会从ALLOCATED变成ACQUIRED状态。具体代码如下:-
在某一个应用程序(Spark,MapReduce等)的ApplicationMaster端,调用allocate(),通过Yarn 资源请求的客户端AMRMClient向Yarn的ResourceManager发送本次新的资源请求(有可能没有新的资源请求,仅仅是心跳),以及需要返还给Yarn的多余的未使用的Container:
------------------------------------- AMRMClientImpl ------------------------------ @Override public AllocateResponse allocate(float progressIndicator) throws YarnException, IOException { ........ allocateRequest = AllocateRequest.newInstance(lastResponseId, progressIndicator, askList, releaseList, blacklistRequest); allocateResponse = rmClient.allocate(allocateRequest); -
Yarn端ApplicationMasterService收到请求以后,会将这次请求作为一个ApplicationMaster的心跳进行更新。然后,将这次请求更新到FSAppAttempt中等待异步调度,即调用对应的FairScheduler的allocate()方法:
@Override public AllocateResponse allocate(AllocateRequest request) throws YarnException, IOException { ..... this.amLivelinessMonitor.receivedPing(appAttemptId); ...... Allocation allocation = this.rScheduler.allocate(appAttemptId, ask, release, blacklistAdditions, blacklistRemovals); }需要区别FairScheduler的allocate()方法和上面讲到的导致Container从NEW到ALLOCATED状态的attemptScheduling()方法。allocate()方法是面向用户的ApplicationMaster的资源请求,将用户端请求挂载到对应的FSAppAttempt等待资源分配。而attemptScheduling()方法就是资源分配的实际过程,即根据ResourceRequest创建Container的过程,这个行为的触发来自于NodeManager的心跳或者来自于持续的调度。
-
在FairScheduler.allocate()方法中,在将用户的资源请求挂载到对应的FSAppAttempt以后,会尝试将资源请求的结果(即Container的分配结果)返回给用户。在这个过程中,生成了ACQUIRED事件:
@Override public Allocation allocate(ApplicationAttemptId appAttemptId, List<ResourceRequest> ask, List<ContainerId> release, List<String> blacklistAdditions, List<String> blacklistRemovals) { ...... ContainersAndNMTokensAllocation allocation = application.pullNewlyAllocatedContainersAndNMTokens(); // 获取当前的已经分配的相关结果public synchronized ContainersAndNMTokensAllocation pullNewlyAllocatedContainersAndNMTokens() { List<Container> returnContainerList = new ArrayList<Container>(newlyAllocatedContainers.size()); List<NMToken> nmTokens = new ArrayList<NMToken>(); for (Iterator<RMContainer> i = newlyAllocatedContainers.iterator(); i .hasNext();) { ...... returnContainerList.add(container); i.remove(); rmContainer.handle(new RMContainerEvent(rmContainer.getContainerId(), RMContainerEventType.ACQUIRED)); // 生成对应的ACQUIRED事件 } return new ContainersAndNMTokensAllocation(returnContainerList, nmTokens); }在RMContainerEventType.ACQUIRED事件生成以后,RMContainerImpl的状态就从ALLOCATED状态变成了ACQUIRED状态。
在ApplicationMaster通过allocate()方法获取了一些Container的分配状态以后,就会直接联系对应的NodeManager,试图要求在NodeManager上启动对应的Container。
-
从Acquired到Running的状态转换
// Transitions from ACQUIRED state .addTransition(RMContainerState.ACQUIRED, RMContainerState.RUNNING, RMContainerEventType.LAUNCHED, new LaunchedTransition())可以看到,当出于RMContainerState.ACQUIRED状态的Container,发生了RMContainerEventType.LAUNCHED事件,就会执行状态转换函数LaunchedTransition,然后将状态转换成RMContainerState.RUNNING。
那么,什么时候会发生RMContainerEventType.LAUNCHED事件呢?
这个事件发生在NodeManager的nodeUpdate()时。即,NodeManager会通过定期的心跳,向ResourceManager汇报自己的Container信息,包括了已经结束的Container以及刚刚Launch起来的Container。对于刚刚Launch起来的Container,Yarn就会将Container的状态更新为RUNNING:-
FairScheduler收到了NODE_UPDATE事件,调用对应的nodeUpdate()方法进行处理:
----------------------------------------- FairScheduler --------------------------- @Override public void handle(SchedulerEvent event) { switch (event.getType()) { case NODE_ADDED: .... break; case NODE_REMOVED: .... break; case NODE_UPDATE: NodeUpdateSchedulerEvent nodeUpdatedEvent = (NodeUpdateSchedulerEvent)event; nodeUpdate(nodeUpdatedEvent.getRMNode()); -
在nodeUpdate()方法中,对刚刚launch起来的Container进行处理:
-------------------------------- FairScheduler ----------------------------------- private synchronized void nodeUpdate(RMNode nm) { ....... // Processing the newly launched containers for (ContainerStatus launchedContainer : newlyLaunchedContainers) { containerLaunchedOnNode(launchedContainer.getContainerId(), node); } -
获取对应的Container的RMContainerImpl,并生成对应的LAUNCHED事件:
public synchronized void containerLaunchedOnNode(ContainerId containerId, NodeId nodeId) { RMContainer rmContainer = getRMContainer(containerId); ..... rmContainer.handle(new RMContainerEvent(containerId, RMContainerEventType.LAUNCHED)); }
-
-
RMContainerEventType.LAUNCHED时间的触发就会导致ResourceManager端Container的状态从RMContainerState.ACQUIRED转换到RMContainerState.RUNNING。由于全部Container全部卡在RMContainerState.ACQUIRED状态,那是不是因为NodeManager和ResourceManager之间通信出现异常呢?通过仔细研判,我们排除了这种可能,原因包括:
- 整个Yarn集群中的其他Application正常运行,
- 我们在NodeManager端没有搜索到关于这个Application的任何有用信息,因此似乎ApplicationMaster就是没有和NodeManager联系。
3.7 动态分配的整个通信过程
Driver根据物理执行计划生成Executor的放置的暗示信息
整个动态分配的决策流程来自于ExecutorAllocationManager。我们从客户端的超时错误堆栈也可以看到,发生了超时的request是ExecutorAllocationManager委托CoarseGrainedSchedulerBackend进行资源请求发生的超时。
这里的动态分配,指的是根据当前集群的Task的运行状态、Executor的运行状态(是否有Task在运行等等), 来决策是否还需要启动新的Executor、是否需要杀死当前空闲的Executor等等的动态调整过程。
那么, ExecutorAllocationManager是如何实时感知到整个Application的运行和调度状态的呢?是通过管理一个SparkListener的实现 ExecutorAllocationListener 来获取的。
在Spark中,所有需要获取Spark相关状态变化的类,都需要实现SparkListener接口,并将这个Listener实现注册给LiveListenerBus。既然是Bus(中文应该翻译成总线),LiveListenerBus所负责的就是对相关事件消息的分派和分发。就像Yarn中的事件调度器AsyncDispatcher一样。
我们看一下SparkListener这个抽象类的几个关键方法,可以看到,这些方法都是一些关键事件发生(一个新的Stage的提交、结束、一个新的Task的提交和结束等等)的回调。动态分配场景下,ExecutorAllocationManager必须捕获这些关键时间,以更新当前任务调度的基本状态,并动态进行下一步的任务调度。
abstract class SparkListener extends SparkListenerInterface {
override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = { }
override def onStageSubmitted(stageSubmitted: SparkListenerStageSubmitted): Unit = { }
override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = { }
override def onTaskEnd(taskEnd: SparkListenerTaskEnd): Unit = { }
在ExecutorAllocationManager中,其内部私有类ExecutorAllocationListener继承了SparkListener,并实现了onStageCompleted()、onStageSubmitted()、onTaskStart()等关键方法。其中,触发动态资源调度的时间主要来自于Stage 提交,因为一个Stage的提交,带来的是这个Stage的所有待分配的task,因此需要进行资源的分配。
在一个新的Stage提交了,ExecutorAllocationManager的ExecutorAllocationListener会收到这个Stage的StageInfo,一个StageInfo的构造方法如下所示:
class StageInfo(
val stageId: Int, // stage ID
@deprecated("Use attemptNumber instead", "2.3.0") val attemptId: Int,
val name: String, // stage的名字
val numTasks: Int, // task的数量
val rddInfos: Seq[RDDInfo],
val parentIds: Seq[Int], // parent stage id
// 每一个task的prefered location的list,一个task可能prefered location不止一个
private[spark] val taskLocalityPreferences: Seq[Seq[TaskLocation]] = Seq.empty) {
其中与调度相关的就是taskLocalityPreferences,代表每一个Task所倾向的被调度到的机器的集合。有一个Task所倾向于的机器可能不止一个,因此taskLocalityPreferences是一个双重数组。
ExecutorAllocationListener为了支持动态资源分配,onStageSubmitted()实现的最重要的功能,就是根据StageInfo,统计这个Stage上的任务信息,比如任务数量,每一个任务的locality信息,进行相应转化,方便后面按需进行资源请求。
override def onStageSubmitted(stageSubmitted: SparkListenerStageSubmitted): Unit = {
initializing = false
val stageId = stageSubmitted.stageInfo.stageId // 这个stage的id
val numTasks = stageSubmitted.stageInfo.numTasks // 这个stage上的task的数量
allocationManager.synchronized { // 基于 allocationManager对象锁的同步方法
stageIdToNumTasks(stageId) = numTasks
stageIdToNumRunningTask(stageId) = 0
...
// 计算这个stage在每一个host上的task数量
var numTasksPending = 0
val hostToLocalTaskCountPerStage = new mutable.HashMap[String, Int]()
// taskLocalityPreferences的类型是一个 Seq[Seq[TaskLocation]],
// 代表每一个task的prefered location的list,
// TaskLocation代表了一个task的其中一个location信息,
// 这个location信息可能是一个host,或者是一个executor
stageSubmitted.stageInfo.taskLocalityPreferences.foreach { locality =>
// 对于每一个task的prefered location的list
numTasksPending += 1
// 对于这个task的每一个 preferred location
locality.foreach { location => // 对于这个locality中的每一个location
// 这个host上的task的数量+1
val count = hostToLocalTaskCountPerStage.getOrElse(location.host, 0) + 1
hostToLocalTaskCountPerStage(location.host) = count //
}
}
// 这个map的key是stage id,value是一个元组,记录了这个stage的pending的task的数量,以及从host到task count的map信
stageIdToExecutorPlacementHints.put(stageId,
(numTasksPending, hostToLocalTaskCountPerStage.toMap))
// Update the executor placement hints
updateExecutorPlacementHints()
}
}
在这个方法中:
-
遍历这个StageInfo的taskLocalityPreferences,统计这个Stage的所有task的数量,这些task还没有调度出去,因此是pendingTasks,同时将每一个task的locality的信息(task -> hosts的映射关系)转换成每一个host上的task的数量信息(host -> task number),相当于做了一个映射关系的转置:
stageSubmitted.stageInfo.taskLocalityPreferences.foreach { locality => // 对于每一个task的prefered location的list numTasksPending += 1 // 对于这个task的每一个 preferred location locality.foreach { location => // 对于这个locality中的每一个location // 这个host上的task的数量+1 val count = hostToLocalTaskCountPerStage.getOrElse(location.host, 0) + 1 hostToLocalTaskCountPerStage(location.host) = count // } } -
将刚刚统计的这个Stage的信息存入到stageIdToExecutorPlacementHints中。顾名思义, stageIdToExecutorPlacementHints是当前所有还没有完成的Stage的资源请求的“暗示”信息,即Executor的放置暗示信息,后面的资源请求将尽量满足这个暗示信息:
stageIdToExecutorPlacementHints.put(stageId, (numTasksPending, hostToLocalTaskCountPerStage.toMap))我们可以看到,当前这个Stage的Executor放置的暗示信息由一个元组表达,元组中包含了这个Stage还没有分配出去的task的数量,以及这些task在每个机器上的分布数量。
比如:对于Stage 2,有两个Task,生成的物理执行计划包含了这两个Task的taskLocalityPreferences:
Task 0: [host0.prod.com, host1.prod.com, host2.prod.com]
Task 1: [host1.prod.com]
经过分析,我们生成了这个Stage的资源请求的暗示信息:
(2, (“host0.prod.com”:1, “host1.prod.com”:2, “host2.prod.com”: 1))
这个暗示信息表示当前这个Stage需要为2个pending task分配资源,同时,经过统计,在host0 ~ host 2 上可能分配的task的比例为1:2:1 -
通过调用updateExecutorPlacementHints()来对stageIdToExecutorPlacementHints中的所有Stage的信息进行统计,主要是统计全体的localityAwareTasks和hostToLocalTaskCount。这就是生成的全局的资源请求的“暗示”信息:
// 更新全局的executor的放置暗示信息 updateExecutorPlacementHints()updateExecutorPlacementHints()方法的具体实现如下,就是遍历stageIdToExecutorPlacementHints,获取一个全局的Executor的放置策略的暗示信息:def updateExecutorPlacementHints(): Unit = { var localityAwareTasks = 0 val localityToCount = new mutable.HashMap[String, Int]() stageIdToExecutorPlacementHints.values.foreach { case (numTasksPending, localities) => // 遍历所有stage的资源分配暗示信息,生成一个全局的统计信息 localityAwareTasks += numTasksPending localities.foreach { case (hostname, count) => val updatedCount = localityToCount.getOrElse(hostname, 0) + count localityToCount(hostname) = updatedCount } } // 总的task的数量 allocationManager.localityAwareTasks = localityAwareTasks // 每一个host和希望调度上去的task的数量 allocationManager.hostToLocalTaskCount = localityToCount.toMap } }
注意,在一个Stage运行完成的时候,相应Stage的暗示信息就不再需要,因此会进行删除,当然还会删除这个Stage中的其他信息:
override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = {
val stageId = stageCompleted.stageInfo.stageId
allocationManager.synchronized {
.......
stageIdToSpeculativeTaskIndices -= stageId
stageIdToExecutorPlacementHints -= stageId // 删除这个Stage的executor放置的暗示信息
// Update the executor placement hints
updateExecutorPlacementHints()
因此,stageIdToExecutorPlacementHints保存的是当前Active的Stage的调度“暗示”信息。
所以,可以看到,基于事件的触发方法,让ExecutorAllocationManager始终监听Stage提交等关键事件,并维护着当前集群的Executor的放置暗示信息,包括有locality需求的tasks的总数量,以及统计出的每一个hosts上需要调度的task的数量信息(其实只是一个比例,比如一个task所希望调度到的host有3个,这三个host将会被各计数一次),然后,基于一个持续的后台线程,不断进行资源请求:
-------------------------------------- ExecutorAllocationManager --------------------------------
def start(): Unit = {
/**
* 注册这个ExecutorAllocationListener, 负责executor的动态分配
* 当stage开始或者结束的时候,
* 更新对应的task和希望调度的机器的对应关系
*/
listenerBus.addToManagementQueue(listener)
val scheduleTask = new Runnable() {
override def run(): Unit = {
schedule() // 这里会根据需要更新numExecutorsTarget的数量,也会调用
}
}
executor.scheduleWithFixedDelay(scheduleTask, 0, intervalMillis, TimeUnit.MILLISECONDS)
// 异步线程运行起来可能需要等待一会儿,这里由于已经注册了Listener,因此可能已经有了回调带来的资源请求,所以先尝试进行一次调度
client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount)
}
上面的方法启动了一个定期执行的调度策略,不断调用schedule()方法进行资源请求,实际上是调用updateAndSyncNumExecutorsTarget()方法,进行资源请求:
---------------------------------- ExecutorAllocationManager --------------------------------
private def updateAndSyncNumExecutorsTarget(now: Long): Int = synchronized {
val maxNeeded = maxNumExecutorsNeeded // 在这里根据当前的task需求确定executor的数量
// 如果当前需要的Executor数量小于numExecutorsTarget,那么可能需要cancel一部分executor
if (maxNeeded < numExecutorsTarget) {
val oldNumExecutorsTarget = numExecutorsTarget
numExecutorsTarget = math.max(maxNeeded, minNumExecutors)
if (numExecutorsTarget < oldNumExecutorsTarget) {
// 依赖ExecutorAllocationClient向ClusterManager发送executor的请求
client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount)
}
numExecutorsTarget - oldNumExecutorsTarget
}else if (addTime != NOT_SET && now >= addTime) { /
val delta = addExecutors(maxNeeded)
.....
}
}
- 计算当前我们所需要的Executor的数量,这里所需要的executor的数量的含义是,当每一个executor能够运行的task数量是一定的,那么总共运行多少的executor才能服务当前pending的(还没有分配出去)和running的task?
private def maxNumExecutorsNeeded(): Int = { val numRunningOrPendingTasks = listener.totalPendingTasks + listener.totalRunningTasks (numRunningOrPendingTasks + tasksPerExecutor - 1) / tasksPerExecutor } - 如果当前需要的Executor的数量小于目标的executor的数量,那么需要减小Executor的数量,即cancel一部分executor。这里的目标executor的数量是上一轮调度的时候的executor的数量。
请注意,这里的client是ExecutorAllocationClient的实现类,调用的方法是requestTotalExecutors(),这个方法的参数是当前总共需要的executor的数量,而不是增量,因此假如参数中传入的executor的数量大于当前实际运行的executor的数量,可能反而会cancel掉一部分executor。与之对应的是ExecutorAllocationClient.requestExecutors()方法,其参数是需要额外申请的executor的数量,是一个增量。if (numExecutorsTarget < oldNumExecutorsTarget) { // 依赖ExecutorAllocationClient向ClusterManager发送executor的请求 client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount) } - 如果当前需要的Executor的数量大于目标的executor的数量,并且调度时机到达了(不能过于频繁的调度),那么会调用addExecutors方法,这个方法根据当前的情况确定目标的executor的数量,也是调用requestTotalExecutors()进行资源请求。
Driver向ApplicationMaster发送Task的相关信息
上面已经确定了所需要的Executor的总量,以及当前的Task的task locality特性,因此将调用ExecutorAllocationClient.requestTotalExecutors()进行Executor的请求(需要的大于目前已有的)或者Executor的取消(需要的小于目前已有的)。
上面说过,ExecutorAllocationClient是负责Executor管理的trait,其实现是CoarseGrainedSchedulerBackend。CoarseGrainedSchedulerBackend实现了requestTotalExecutors()、requestExecutors()、killExecutors()、killExecutorsOnHost()等方法。
上面讲过,CoarseGrainedSchedulerBackend实现的是在CoarseGrained场景下的基本流程和策略,跟平台依然无关。只要平台支持这种CoarseGrained调度方式,那么只需要扩展一下 CoarseGrainedSchedulerBackend 以增加相应跟具体平台相关的东西就行了。因此,具体申请Container等操作,是在YarnSchedulerBackend中实现的。下面我们看到,CoarseGrainedSchedulerBackend的requestTotalExecutors()只是定义了基本流程,真正跟Yarn交互申请Container,还是依赖具体的基于Yarn平台的实现类YarnSchedulerBackend:
----------------------------------- CoarseGrainedSchedulerBackend ---------------------------
final override def requestTotalExecutors(
numExecutors: Int, // 目标Executor的数量,这是一个总数量
localityAwareTasks: Int, // 有locality需求的task的数量
hostToLocalTaskCount: Map[String, Int] // 从host到这个希望调度到这个host上的task的数量的映射关系
): Boolean = {
val response = synchronized {
this.requestedTotalExecutors = numExecutors // 目标Executor的数量,这是一个总数量
this.localityAwareTasks = localityAwareTasks // 有locality需求的task的数量
this.hostToLocalTaskCount = hostToLocalTaskCount // 从host到这个希望调度到这个host上的task的数量的映射关系
// 更新pendingExecutor的数量,这里暂未使用该变量
numPendingExecutors =
math.max(numExecutors - numExistingExecutors + executorsPendingToRemove.size, 0)
doRequestTotalExecutors(numExecutors) // 使用YarnSchedulerBackend,向Yarn申请资源
}
defaultAskTimeout.awaitResult(response)
}
从上面的代码可以看到:
- 准备好在申请资源过程中需要用到的基本信息,即目标Executor数量,有locality需要的task的数量,以及每一个host上的对应task的数量
this.requestedTotalExecutors = numExecutors // 目标Executor的数量,这是一个总数量 this.localityAwareTasks = localityAwareTasks // 有locality需求的task的数量 this.hostToLocalTaskCount = hostToLocalTaskCount // 从host到这个希望调度到这个host上的task的数量的映射关系 - 申请资源。这里的申请与平台有关,因此依赖子类的实现YarnSchedulerBackend:
doRequestTotalExecutors(numExecutors) // 使用YarnSchedulerBackend,向Yarn申请资源
YarnSchedulerBackend会将当前申请资源所需要的上下文信息统一封装成RequestExecutors消息,然后交付给本地的YarnSchedulerEndpoint进行处理(Endpoint的调用不一定是远程的,只要持有了对应的EndpointRef,就不用在乎是本地还是远程。详细过程参考 TODO)。
需要区分CoarseGrainedSchedulerBackend中的DriverEndpoint和子类的YarnSchedulerBackend的YarnSchedulerEndpoint。前者主要负责与平台无关的调度逻辑,比如,来自Executor的关于Task的状态更新、Kill掉Task、Executor的注册等,而YarnSchedulerBackend则与yarn强绑定,在接受了ApplicationMaster的注册以后,只和ApplicationMaster进行通信,以进行Executor(container)层面的相关操作,比如RequestExecutors,KillExecutors,RemoveExecutor等等。
下面的代码是根据上下文信息,封装好RequestExecutors对象。对象中包含了申请Executor需要的信息,包括总的需要的Executor的数量,总的有Locality 需求的Task的数量,每个Hosts上的Tasks的数量,以及黑名单节点:
----------------------------------- YarnSchedulerBackend ------------------------------------
private[cluster] def prepareRequestExecutors(requestedTotal: Int): RequestExecutors = {
val nodeBlacklist: Set[String] = scheduler.nodeBlacklist()
// For locality preferences, ignore preferences for nodes that are blacklisted
val filteredHostToLocalTaskCount =
hostToLocalTaskCount.filter { case (k, v) => !nodeBlacklist.contains(k) }
RequestExecutors(requestedTotal, localityAwareTasks, filteredHostToLocalTaskCount,
nodeBlacklist)
}
注意: 我们仔细查看代码可以看到,这些统计数据都是目前的统计状态,而不是一个增量结果。因此这些数据都来自于stageIdToExecutorPlacementHints,而stageIdToExecutorPlacementHints只有在onStageCompleted的时候才会清除对应的Stage,因此,每次基于stageIdToExecutorPlacementHints生成的资源需求都是全量的资源需求状态,而不是一个增量需求。而Yarn需要的是资源增量,即,ApplicationMaster和Yarn交互的时候只需要告诉Yarn需要新增多少Container,取消多少Container。这个从全量到增量的过程是在ApplicationMaster端进行的。
然后,YarnSchedulerBackend向ApplicationMaster发送RequestExecutors以进行资源请求:
----------------------------------- YarnSchedulerBackend -------------------------------------
case r: RequestExecutors =>
amEndpoint match {
case Some(am) => // 已经收到了am的注册请求,向AM发送RequestExecutors请求
// 向这个am对应的endpoint发送r,返回一个future,等待对方回复
am.ask[Boolean](r).andThen { // 向远程的ApplicationMater发送消息,触发远程的ApplicationMaster的对应的RpcEndPoint的receiveAndReply
case Success(b) => context.reply(b) // 给发送者回复一个消息,如果发送者是一个RpcEndpoint,那么其receive()方法将会被调用
.......
这里就是调用了ApplicationMaster的RpcEndpointRef(ApplicationMaster的endpoint来自于ApplicationMaster通过RegisterClusterManager消息进行的注册。由此可见,在Spark视角下,ApplicationMaster就是负责进行资源管理的ClusterManager)。
ApplicationMaster接收Driver的Task资源请求信息
ApplicationMaster基于RequestExecutors的处理是本文中最繁琐和复杂的部分,原因在于,RequestExecutors携带了一些本地性的偏向,即有些Task希望尽可能运行在某些某些机器上,因此,ApplicationMaster需要解决的问题在于,如何向Yarn请求资源,然后尽可能满足这些Task的本地性要求?
在ApplicationMaster端的AMEndpoint收到资源请求RequestExecutors以后,会通过YarnAllocator来更新当前当前的资源需求状态,以便后面将这个状态转换成Yarn可以立即的资源请求。
---------------------------------- ApplicationMaster --------------------------------------
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case r: RequestExecutors => // 申请Executor的请求在这里接收
Option(allocator) match { // 如果已经构建了allocator
allocator.requestTotalExecutorsWithPreferredLocalities(r.requestedTotal,
r.localityAwareTasks, r.hostToLocalTaskCount, r.nodeBlacklist)
context.reply(true)// 直接给Driver一个bool值
.....
下面的代码就是方法requestTotalExecutorsWithPreferredLocalities()对RequestExecutors的直接处理:
def requestTotalExecutorsWithPreferredLocalities(
requestedTotal: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int],
nodeBlacklist: Set[String]): Boolean = synchronized {
this.numLocalityAwareTasks = localityAwareTasks // 在 ReporterThread -> allocateResources() -> updateResourceRequests() 中会使用这个变量,通过amClient发送出去
this.hostToLocalTaskCounts = hostToLocalTaskCount // 在 ReporterThread -> allocateResources() -> updateResourceRequests() 中会使用这个变量,通过amClient发送出去
this.targetNumExecutors = requestedTotal
// 更新(新增或者删除)blacklist节点信息
amClient.updateBlacklist(blacklistAdditions.toList.asJava, blacklistRemovals.toList.asJava)
currentNodeBlacklist = nodeBlacklist // 更新currentNodeBlacklist
true
}
可见,处理的方式很简单,就是对四个要素进行了更新:
- 对locality有需求的task的总的数量numLocalityAwareTasks
- 从host到task数量的映射关系hostToLocalTaskCounts,
- 目标的总的executor的数量targetNumExecutors,
- 黑名单节点currentNodeBlacklist
这些数据都是在Driver层根据任务的物理执行计划生成的调度需求。
上面说过,这些数量信息都是总的状态信息,而Yarn接收的新增Container、取消Container等等的增量信息,因此ApplicaitonMaster需要将这个全局的资源需求同已经发送给Yarn的资源需求进行对比以确定新增的资源需求,然后将这个增量需求发送出去。
当有了目前的资源的基本状态,下一步就是将这个基本状态通过updateResourceRequests()翻译成Yarn可以理解的资源请求,并将请求发送给Yarn。
ApplicationMaster根据Task的请求信息向Yarn请求资源
上线说过,资源请求是在方法YarnAllocator.allocateResources()中进行的:
def allocateResources(): Unit = synchronized {
updateResourceRequests() // 这个方法会打印日志 Submitted 112 unlocalized container requests,在出问题的机器上打印了
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
handleAllocatedContainers(allocatedContainers.asScala)
val completedContainers = allocateResponse.getCompletedContainersStatuses()
processCompletedContainers(completedContainers.asScala)
}
}
其基本过程是:
- 更新资源请求。这里的更新,指的是,经过当前已经发出去的资源请求和当前实际需要的资源请求,生成资源请求的决策(包括新增的请求、释放请求、修改请求、机器黑名单等),通过调用Yarn的标准api addContainerRequest()保存这个请求(这个API还不会把请求发送Yarn,只是保存在Yarn的中。发送是由allocate()接口负责)。
- 所以,本质上,这是一个状态的转换,根据当前需求的总体资源和已经申请(也许还没有分配)的资源的状态,计算出还需要申请的资源(需求 > 已申请),或者需要取消的资源(需求 < 已申请),然后向Yarn发出资源的增加需求,或者资源的取消需求。
updateResourceRequests()涉及到动态资源分配下的资源调度算法,在我的一篇独立文章TODO中,对这个算法进行了具体介绍。这里不再赘述。我们只需要知道,经过updateResourceRequests()方法,相应的资源调度请求ContainerRequest已经在updateResourceRequests()中通过Yarn的标准API addContainerRequest()全局添加进来,多余的Container(如果有)也在这个方法中通过Yarn的标准API removeContainerRequest()进行了取消。必须注意,addContainerRequest()和removeContainerRequest()都不会真正发送请求到Yarn,而只是将请求暂存在AMRMClient中。请求的发送是通过allocate()进行的。updateResourceRequests() // 这个方法会打印日志 Submitted 112 unlocalized container requests,在出问题的机器上打印了 - 发送资源请求并获取当前已经分配成功的资源。这是调用Yarn的标准API allocate(),来获取资源分配的最新状态,我在下文讲解Yarn中Container的状态转换会讲到,ApplicationMaster通过allocate()将资源请求发送(新的请求,需要取消的请求等等) 发送给Yarn,Yarn在收到allocate()请求以后,会返回给ApplicationMaster一系列已经分配(ALLOCATED)的Container,然后异步处理本次allocate()发送过来的资源请求,即,,基于异步的资源分配方式,这些已经分配的资源请求大概率应该不是本次调用allocate()方法的资源请求,而是前面某一次或者几次调用allocate() 方法的资源请求。
在allocate()方法成功返回以后,Yarn认为这个异步分配的Container已经在ApplicationMaster端确认(Acquired),因此Container的状态会生成一个RMContainerEventType.ACQUIRED事件,Container的状态会从ALLOCATED变成ACQUIRED状态。val allocateResponse = amClient.allocate(progressIndicator) - 对新分配的container和已经结束的container进行相应处理。这里主要是将资源请求和Yarn的资源分配的结果进行匹配,以确认请求和Container之间的对应关系。匹配成功的资源请求会从本地删除以避免重复申请,同时,ApplicationMaster会在对应的NodeManager上启动Container。
关于动态资源分配的具体细节,可以参考我的另一篇文章TODO。val allocatedContainers = allocateResponse.getAllocatedContainers() handleAllocatedContainers(allocatedContainers.asScala) val completedContainers = allocateResponse.getCompletedContainersStatuses() processCompletedContainers(completedContainers.asScala)
启动Executor并将Task调度上去
在TODO这篇文章中详细记载了,启动Container、将Task请求和Container进行最优匹配然后将Task调度到Container上运行的基本流程,这里不再重复讲解。
3.8 Application执行结束以后关闭Executor
从日志可以看到,当Application执行结束以后,Driver会遍历当前所有的executor,向对应的NodeManager发送shutdown的请求,以关闭Executor:
我们从一个成功的Job的Driver日志中可以看到对应的信息:
[2024-04-25 09:14:52,211] {ssh_operator.py:133} INFO - 24/04/25 09:14:52 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
[2024-04-25 09:14:52,211] {ssh_operator.py:133} INFO - 24/04/25 09:14:52 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
[2024-04-25 09:14:52,213] {ssh_operator.py:133} INFO - 24/04/25 09:14:52 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
这时候,在对应的NodeManager上,会收到来自Driver的kill container的相应请求:
2024-04-25 09:09:08,011 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl: Event EventType: KILL_CONTAINER sent to absent container container_1700028334993_233460_01_000002
2024-04-25 09:09:08,011 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl: Event EventType: KILL_CONTAINER sent to absent container container_1700028334993_233460_01_000003
4. 事故后续处理
整个事故的处理我们分为事故发生时刻的处理过程,以及事故发生以后我们基于源码分析和Retro的过程所进行的后续方案。
事故发生时刻的处理:
- 立刻将多次导致事故的故障机器从Yarn集群中下线,重新提交失败的任务。该机器移走以后的近一个月,事故都未再发生。
事故发生以后的Retro:
-
事故再次发生时的操作步骤梳理:在对于一个在某处hang住的进程,堆栈可以非常直观地展示hang住的位置。本次事故没有精确定位hang住的具体位置,只是定位到了某个方法,因此,ApplicationMaster hang住的时候打印堆栈,可以最直接告诉我们hang住的位置。在事故刚刚发生的时候,我们往往一头雾水,直观的异常往往给我们错误的判断,因此,事故第一次发生时现场不足导致无法定位根本原因非常正常。但是经过事后的调查、事故处理流程的梳理,我们完全可以在事故二次发生的时候捕捉现场,精确定位。
-
Yarn监控:通过对本次事故的分析,我们几乎完全排除了Yarn集群本身的健康问题。但是由于我们缺少对Yarn集群的完备的监控,排除它的嫌疑却花了很大的精力。因此,有必要构建Yarn的全面的监控系统,至少,在事故发生的时候,我们可以获取Yarn的基本状态,从而帮我们将注意力迅速转移到真正导致问题的组件或者服务上。
-
打开ApplicationMaster的Debug日志:在不影响生产环境运行的情况下,我们可以单独打开ApplicaitonMaster的debug日志,在事故发生的时候为我们提供更过信息。