目录
开始
为什么需要服务发现机制
File Service Discovery(file_sd)
基本概念
配置方式
使用案例
HTTP Service Discovery(http_sd)
基本概念
配置方式
使用案例
开始
为什么需要服务发现机制
我们知道在 Prometheus 配置文件中可以通过 static_configs 来配置静态地址来获取数据,但是在云环境下,特别是容器环境下,抓取的 地址 经常是变动的,也就是说,地址每次变动因此,我们不但需要去修改 prometheus.yml 文件,还需要重启 prometheus 来加载配置,十分麻烦.
因此,就引入了 file_sd 、http_sd 等 服务发现机制.
File Service Discovery(file_sd)
基本概念
file_sd 是基于文件的服务发现机制,来动态更新 prometheus 数据的.
我们只需要把之前在 prometheus.yml 中通过 static_config 配置的方式,都统一写到一个文件中(例如 mysql 集群所有实例写到一个文件,mongo 集群所有实例写道另一个文件...),文件的格式可以以 yml 或 json 格式提供(文件必须包含一个静态配置的列表).
一般更多的使用的是 json 格式,如下(这个文件就是一个大 json 数组,包含一个个目标对象):
[
{
"targets": ["10.0.1.1:9100"],
"labels": {
"env": "master",
"job": "mysql"
}
},
{
"targets": ["10.0.0.1:9100", "10.0.0.2:9100"],
"labels": {
"env": "slave",
"job": "mysql"
}
},
...
]
- targets:是一个数组,包含了需要监控的目标地址.
- labels:是一个 map,也就是一些键值对,这些键值我们是可以自定义的,但是我们也建议最好至少 有一个 job 标签 和 env 标签 来标识 名称 和 环境.
配置方式
prometheus.yml 配置如下:
scrape_configs:
- job_name: 'file_sd_example'
file_sd_configs:
- files:
- '/root/prometheus/targets/*.json'
refresh_interval: 10s
这个示例中,Prometheus 会每 10s 读取 '/root/prometheus/targets/' 目录下的所有以 .json 结尾的文件,获取最新的监控目标.
使用案例
a)prometheus.yml 配置文件如下:
scrape_configs:
- job_name: file_sd_expoter
file_sd_configs:
- files:
- '/sd/*.json'
refresh_interval: 5sPs:由于是在 docker 中部署的 prometheus,因此要注意 files 的目录也是容器内的目录!建议启动容器时,挂载好目录,以便操作.
b)目标 JSON 文件如下:
[
{
"targets": ["env-base:9100"],
"labels": {
"env": "prod",
"job": "node_exporter"
}
},
{
"targets": ["env-base:9104", "env-base:9121"],
"labels": {
"env": "prod",
"job": "mysql_and_redis_exporter"
}
}
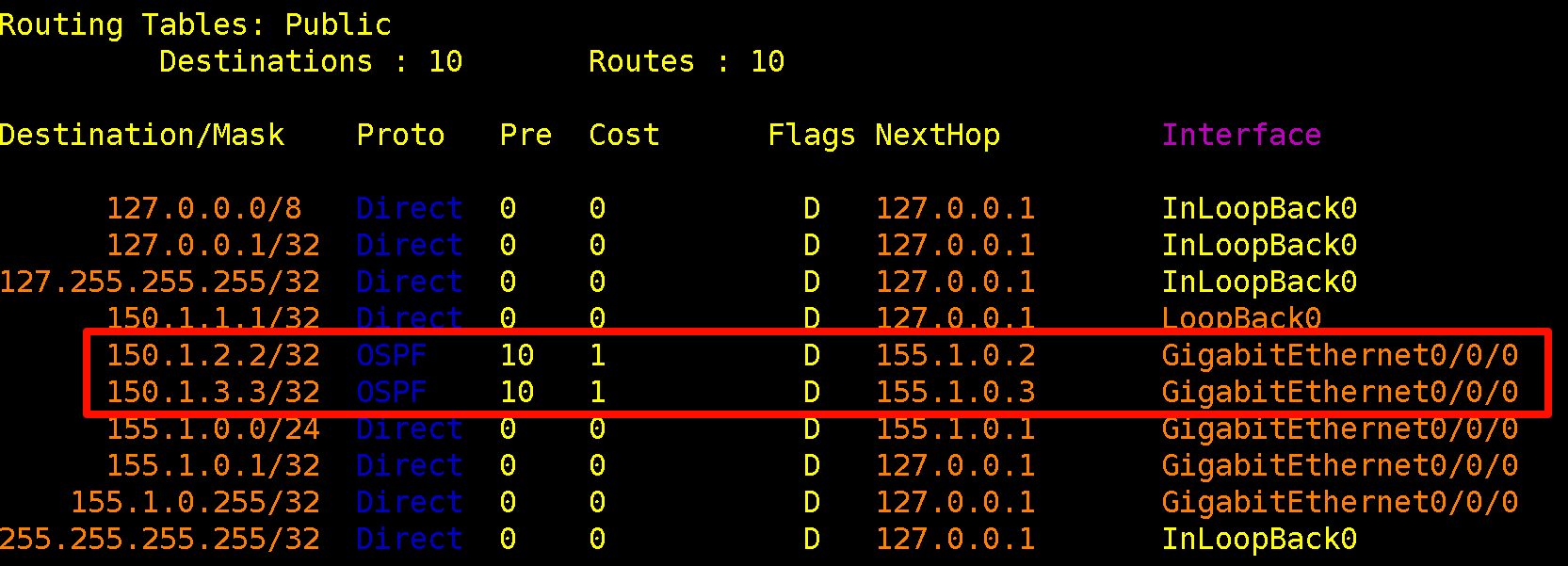
]c)启动 prometheus 容器之后,在浏览器中输入 env-base:9090 进入 prometheus 主页,在进入 Targets 目录,如下:

HTTP Service Discovery(http_sd)
基本概念
http_sd 方式允许 Prometheus 通过 HTTP 请求动态获取需要监控的目标列表.
a)工作原理:
- 首先需要配置 HTTP 端点,也就是在 prometheus.yml 文件中,只需要指定一个 HTTP 端点,这个端点一般是我们自己的写的 SpringMVC 程序中的一个 web 接口(GET 请求方式).
- Prometheus 就会定期向配置的 HTTP 端点发送 GET 请求,获取最新的数据列表.
- HTTP 端点返回的目标列表就是 JSON 格式的数据,里面是一个大 JSON 数组.
b)HTTP 端点返回的数据,例如如下:
[
{
"targets": ["10.0.0.1:9100", "10.0.0.2:9100"],
"labels": {
"env": "prod",
"job": "node_exporter"
}
},
{
"targets": ["10.0.1.1:9100"],
"labels": {
"env": "staging",
"job": "node_exporter"
}
}
]
- targets:是一个数组,包含了需要监控的目标地址.
- labels:是一个 map,也就是一些键值对,这些键值我们是可以自定义的,但是我们也建议最好至少 有一个 job 标签 和 env 标签 来标识 名称 和 环境.
Ps:labels 中的 key 和 value,第一个字符一定都不能是 数字!
配置方式
在 prometheus.yml 文件中配置 http_sd 示例如下:
scrape_configs:
- job_name: 'http_sd_example'
http_sd_configs:
- url: 'http://example.com/targets'
refresh_interval: 10s
这个示例中,Prometheus 会每 10s 向 http://example.com/targets 发送一次 GET 请求,来获取最新的目标列表.
Ps:
- 上述 url 的格式必须为 http://ip:port
- 这里不能加 cookie 或者 header,如果需要 token 来鉴权,建议直接 querystring 进行传参
使用案例
一般公司在做项目前,都会写一个发布系统,这个发布系统就用来复杂把我们写好的程序发布到 预发、生产 等环境. 那么在这个发布系统上,我们就可以给 Prometheus 提供 HTTP 接口,这个接口就可以从 发布系统 的数据库中拿到所有的 服务器示例套接字(ip:port),组装成 json 指定格式,最后返回.
Note:在公司,一般不会全部放到一个 HTTP 接口中,而是提供很多个 HTTP 接口,例如:
- MySQL 集群所有实例信息对应一个 HTTP 接口
- Kafak 集群所有实例信息对应一个 HTTP 接口.
- 所有跑在 jvm 上的程序(SpringBoot 程序)对应一个 HTTP 接口.
下面我来演示一个简单的例子:
a)SpringBoot 应用如下:
@RestController
class HttpApi {
// {
// "targets": ["env-base:9100"],
// "labels": {
// "env": "prod",
// "job": "node_exporter"
// }
// },
// {
// "targets": ["env-base:9104", "env-base:9121"],
// "labels": {
// "env": "prod",
// "job": "mysql_and_redis_exporter"
// }
@RequestMapping("/targets")
fun targets(): List<PrometheusVo> {
//1. 从数据库中获取对应的 套接字 信息,
//...
//2. 组装 json 数据
val v1 = PrometheusVo(
targets = listOf("env-base:9100"),
labels = Labels(
env = "prod",
job = "node_exporter"
)
)
val v2 = PrometheusVo(
targets = listOf("env-base:9104", "env-base:9121"),
labels = Labels(
env = "prod",
job = "mysql_and_redis_exporter"
)
)
return listOf(v1, v2)
}
}
data class PrometheusVo (
val targets: List<String>,
val labels: Labels
)
//注意,根据 prometheus 的要求,不允许值的第一个字符为数字!!
data class Labels (
val env: String,
val job: String
)
访问 100.94.135.96:9000/targets 如下:

b)配置文件如下:
scrape_configs:
- job_name: http_sd_expoter
http_sd_configs:
- url: 'http://100.94.135.96:9000/targets'
refresh_interval: 5s