CMU 15-213 CSAPP (Ch1~Ch3)
CMU 15-213 CSAPP (Ch5~Ch7)
CMU 15-213 CSAPP (Ch8)
CMU 15-213 CSAPP (Ch9)
CMU 15-213 CSAPP (Ch10)
视频链接
课件链接
课程补充
该课程使用 64位 编译器!
Ch9. Virtual Memory
9.1 Address spaces
将内存看成数组,物理地址 ( physical address ) 是相对某个存储单元的偏移量;
简单微控制器直接使用物理地址即可完成简单任务,但无法胜任手机、电脑、服务器上的复杂任务,必须将 主存 ( main memory ) “虚拟化” ( virtualization );
虚拟化 的概念在计算机领域中被广泛应用,通过 介入资源访问过程,将资源以不同的视角呈现给资源的使用方,例如:
- 调试 malloc 使用的 Ch7.2.4 库插桩技术;
- 硬盘控制器 将 柱面、磁轨、扇区 以 “serious logical blocks” 的形式呈现给 kernel Ch6.1;
- …
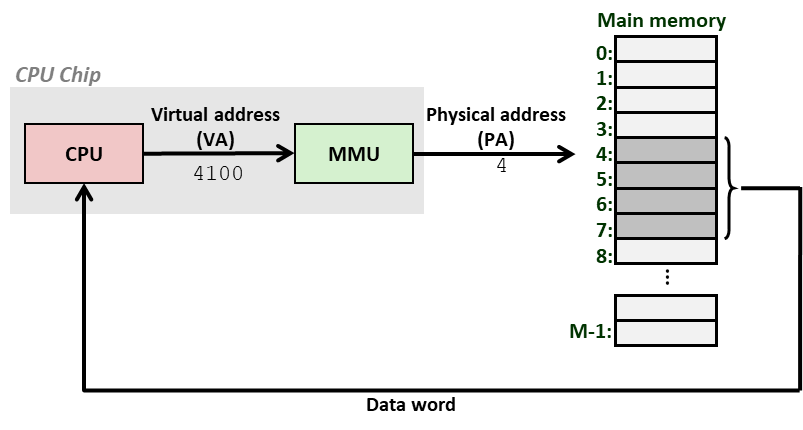
- CPU 向内存请求数据;
- MMU ( Memory Management Unit ) “拦截” ( intercept ) 请求,并将 虚拟地址 转换 ( Address Translation ) 为 物理地址 ( Physical Address );
- 内存收到请求后返回 物理地址对应单元内 的数据;
- CPU “幻觉” 自己可以访问所有的地址空间,独占了整个内存;
- 概念
- 【地址空间】地址的集合;
- 【线性地址空间】连续 非负数 的集合,eg { 0,1,2,3 … };
- 【虚拟地址空间】
N
=
2
n
N = 2^{n}
N=2n 个虚拟地址的集合,eg { 0,1,2,3 …
2
n
−
1
2^{n}-1
2n−1 };
进程内部地址,系统中所有进程相同; - 【物理地址空间】
M
=
2
m
M = 2^{m}
M=2m 个物理地址的集合,eg { 0,1,2,3 …
2
m
−
1
2^{m}-1
2m−1 };
DRAM 的物理容量; - 通常 虚拟地址空间 > 物理地址空间;
9.1.0 为什么需要 虚拟内存
- “虚拟内存” 技术的优点:
- 物理内存的使用效率更高,根据 局部性原理,一个进程只需要一小块 DRAM 来缓存硬盘上一小部分常用的数据或者指令;
- 降低内存管理的复杂程度,每个进程内存的 虚拟地址空间布局 相同,映射到后物理地址空间后,分散各处;
- 隔离、保护 私有地址空间,一个进程无法干涉、访问其他进程的地址空间,用户程序无法访问内核地址空间;
9.1.1 VM as a Tool for Caching
- Virtual Memory 可以抽象成 硬盘上 连续 字节组成的数组;
- 数组中的元素以 块为基本单位,缓存在 DRAM 中,被称为 VP ( virtual page );
- Page Size = 2 p 2^p 2p Bytes,Virtual Memory Size = 2 n 2^n 2n Bytes,Page Number = 2 n 2 p − 1 \frac{2^n}{2^p}-1 2p2n−1

- 通常,大部分虚拟页都 没有被分配 ( unallocated, 类似 VP 0 ),没有 存储在磁盘上;
DRAM 比 CPU 中的 SRAM 慢 10 倍,磁盘 比 DRAM 慢 10,000 倍;
-
磁盘 比 DRAM 慢太多,导致 未命中惩罚 ( miss penalty ) 巨大,设计整个 VM 系统的初衷,就是为了减轻 miss penalty;巨大的 miss penalty 导致 DRAM Cache 的结构(organization)与 Ch 6.Cache Memories 存在巨大差异:
- Page Size 通常 4KB,通过选项 ( x86 ) 可以扩大到 4MB,远大于 CPU Cache Blocks Size ( 64 Bytes ) ,单次未命中的惩罚不可调控,只能通过 更大的 Page ( or Block ) Size 换取 更高的命中率,均摊(amortize)未命中惩罚(时间);
- 直接映射缓存 拥有 较多的 set,但每个 set 只有一个 Line,发生 conflict miss 的概率相对较大,而 硬盘 与 DRAM 置换页面的代价巨大,因此直接映射缓存 并不适用于 DRAM Cache;
- 全相联 只有一个 Set,但 Line 越多 ( associativity 更大 ),conflict miss 的概率越小,更适合 DRAM 缓存( 经验结论:在多数情况下,一个 Line 就能满足进程所需的 Locality ):
- Cache Memory 由硬件对 set 中的 line 并行搜索(parallel search),由于硬件比较快且并行执行,时间能接受;
- 换页算法(replacement algrithms)高度复杂,由操作系统 软件 实现,以确保极高准确性 — 虽然计算需要花费一定的时间,但也远小于 miss 换页 带来的惩罚;
- 映射函数 需要能够 随机寻址 ( 记录所有 VA ⇒ PA 的映射关系 );
- 使用 写回 ( write-back ),尽量少写磁盘;
-
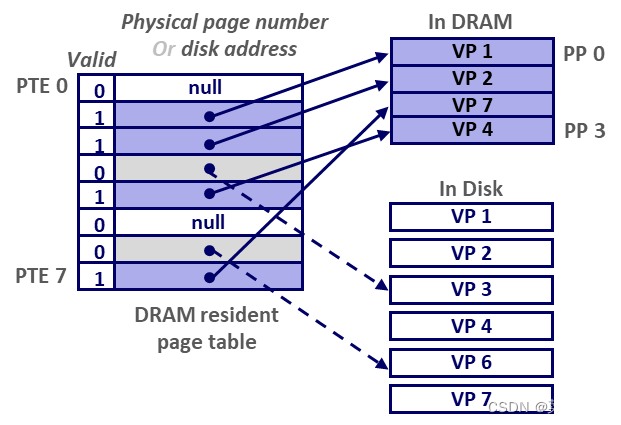
页表(Page Table)
- 是由页表项(Page Tables Entries)组成的数组,存放在内存中,由 kernel 维护,属于进程上下文的一部分( 每个进程都有自己的 Page Table );
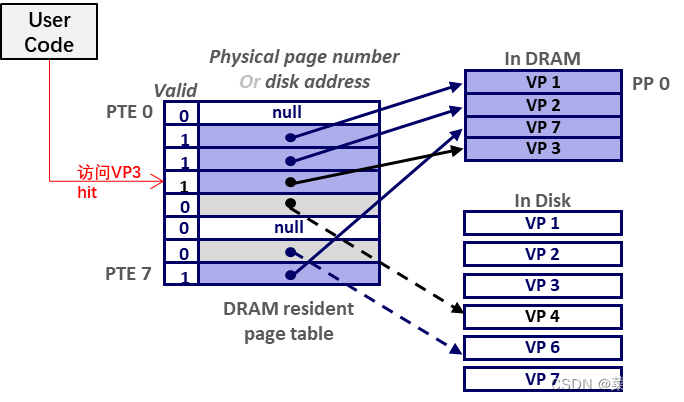
- 以下图为例:
- VP 0、5 为空,尚未分配物理空间,页表项 PTE 0 = null,PTE 6 = null,valid 置 0;
- VP 1、2、4、7 依次缓存到 PP 0、1、3、2 上,页表项 PTE [1] = & PP0、…、PTE [7] = & PP2,valid 置 1;
- VP 3、6 尚在硬盘中,页表项 PTE [3] = VP3’s 硬盘位置,PTE [6] = VP6’s 硬盘位置,且 valid 置 0;
-
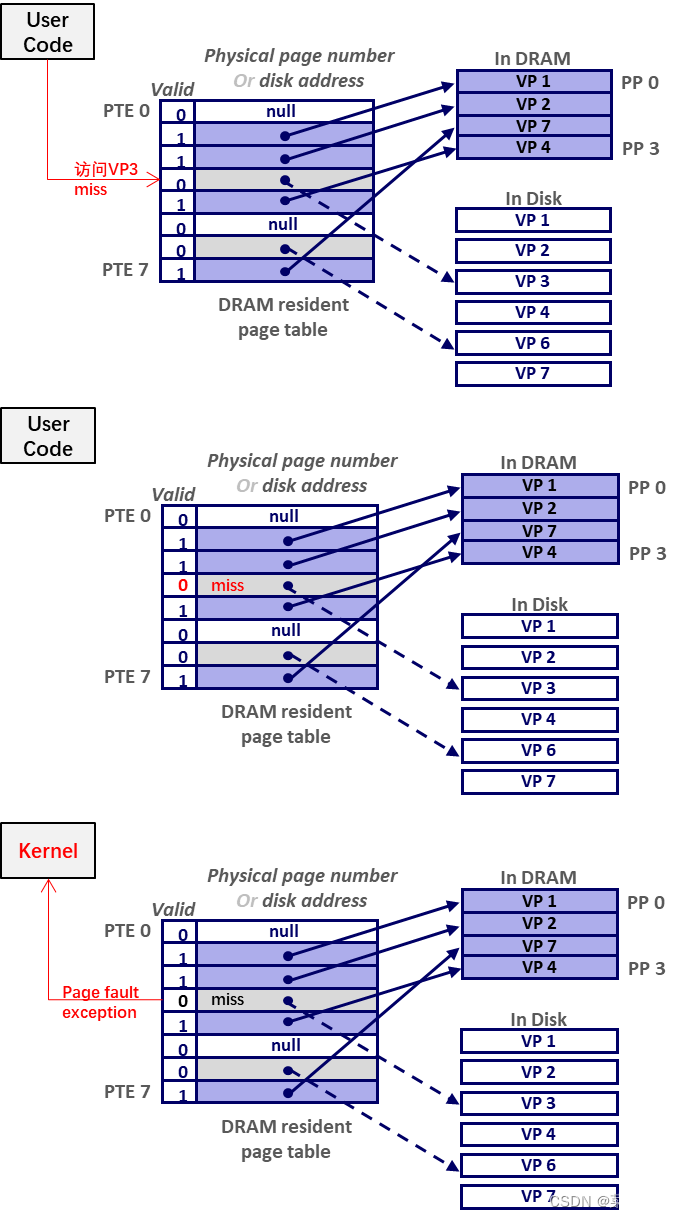
页命中 ( page hit )
- 访问 已经 被缓存在 DRAM 物理内存 中的页内数据;
-
页缺失 ( page fault )
- 访问 DRAM 当前没有 缓存的页内数据;
- 请求页缺失后,缺失页 被置换到 DRAM 中,采取这种缺页处理方式的 内存管理系统 称为 “请求分页系统” ( Demand paging );
-
举例
-
页创建(Page Allocate)
- malloc 请求分配一大块内存,这些内存原本只存在于 Virtual Address Space,(硬盘上)并没有物理实体,如上图 PTE0 = NULL;
- malloc () 调用 sbrk () 函数,向 Page Table 增添一条记录(如 PTE5 = VP5 in Swap,Swap 文件也是持久化在硬盘上的),此时 valid 还是置 0;
- 直到 进程 访问到 malloc 新增页面内的 Virtual Address,才触发 Page Fault,在 DRAM 中寻找合适的 PP 分配给 VP;
关于 sbrk 和 allocation 的关系,详见 Ch11.1.1.Dynamic Memory Allocation
- Locality works all the time !
- 直觉上,这种 VM 系统非常低效,需要频繁的在 硬盘 与 内存 间进行拷贝,每条指令的执行都需要经历至少一次 page mapping;
- 事实上,因为 locality,进程总时倾向于访问 同一部分活跃的 VP,这些 VP 组成的子集 被称为 working set;
- 如果 内存 能够存下 program 的 working set,program 的性能就会很好 ( 冷启动时除外 ) ;
- 但实际上,操作系统 通常是多任务的,如果 全部进程的 working set 之和 超过 内存大小,将导致 颠簸 ( thrashing each other ),连续不停的缺页换页,性能崩坏(meltdown);
9.1.2 VM as a Tool for Memory Management

- Kernel 为每个进程维护独立的 Page Table,使得每个进程都能拥有 独立的 虚拟地址空间;
- 进程的 VP 被 “七零八落” 的缓存映射到 DRAM 的 PP 上,但 效率很高;
- 历史上曾经 为每个进程 提供一小块 “自留地“(“a chunk of the physical address space”),进程只在自己的一小块物理内存中加载运行,但这会导致很多问题:
- 比如,新增进程就必需从其他进程那 ”抢走一小块“,或者由操作系统保留部分内存,创建新进程时再分割,空间利用率奇低,内存上全是空间碎片 ;
- 比如,A.bin 文件中的函数 Afunc () 引用了共享库 B.so 中的 Bfunc (),在没有 VM 条件下,Afunc () 并不知道 Bfunc () 的物理地址,就需要 重定位 所有的引用(references);这样,生成 excutable file 的过程,只有编译,没有链接( linking );
- …
- 虚拟地址 简化 了内存管理的复杂度,most flexible scheduling freedom:
- 任意 VP 可能被缓存在任意的 PP 上;
- 同一 VP 可能先后被缓存到不同的 PP上(被从 PP0 换出到硬盘上,又从硬盘被 换回到 PP1);
- 多个 VP ( 如 共享库文件 libc.so ) 可以被映射到同一个 PP 上;
- 虚拟地址 简化了 linking 和 loading
- 所有 program 的虚拟地址空间 布局 ( layout ) 都相同,Linker 以 .text segment 起始于 0x400000 为前提,在编译链接阶段,就能将 0x400000 作为统一的偏移基地址,relocate 多个 obj 文件中的 references(即链接过程),得到可执行文件 a.out;
- loading 过程,execve () 在 Page Table 中添加 .data section 和 .text sections 对应的 PTE,PTE 指向硬盘位置,置为 invalid,等待程序运行,触发 page fault,再将 PTE 对应的 VP 缓存到内存中;所以 loading 本质上是 demand paging ;
9.1.3 VM as a tool for memory protection
- x86-64 Intell 的 Virtual Address 仅 48 bit,剩余高位补0(用户空间)或 补1(内核空间);
- PTE 通过 权限位 控制 program 对页面的访问:
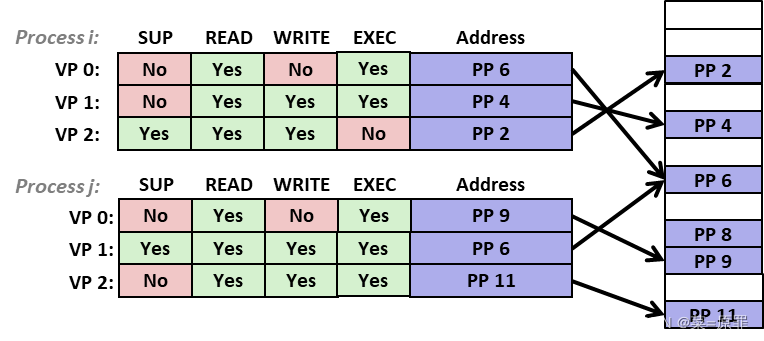
- 比如 高位全“1” 的 Proc i 的 VP2 和 Proc 的 j 的 VP1,只能在 supervisor mode 下访问;
- EXEC bit 仅在 x86-64 上实现,x86-32 不存在,能够防止 代码注入;正因如此,骇客们才放弃栈代码注入,转而使用 ROP 攻击,program 会 ret 到没有执行权限的页 发生 crash;
- 每个访问虚拟地址的请求,都会经过 MMU 的权限位校验;
9.1.4 VM Address Translation
-
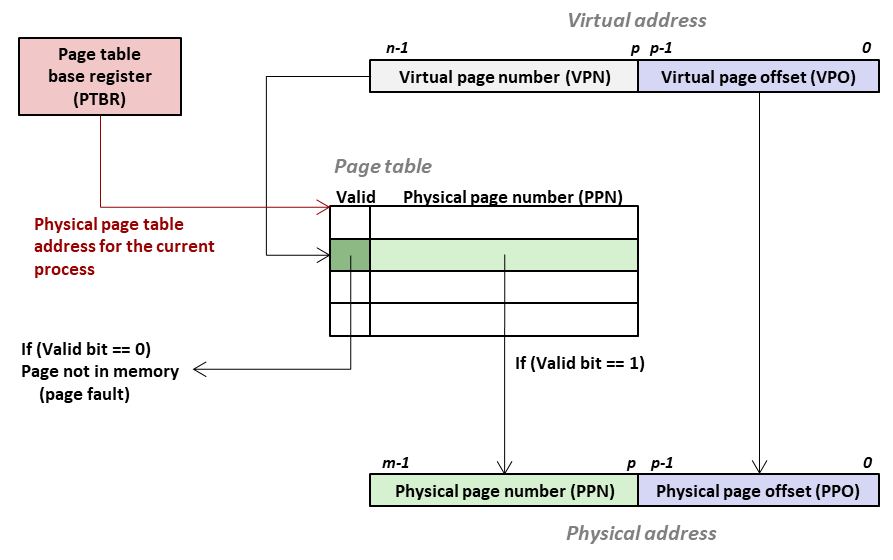
PTBR ( 在 x86 架构中对应 CR3, Controll Register 3 ) 指向 页表 的起始物理地址;
-
将 Virtual Address 拆成高低两部分:
- 高位部分定义为 VPN(Virtual Page Number),作为页表项 PTE 的索引,mapping 到 PPN(Physical Page Number);
- 低位部分定义为 VPO(Virtual Page Offset) ,VP 与 PP 的 Page Size 相同,VPO 直接用作 PPO(Physical Page Offset);
-
经过上述 translation,得到 PA(Physical Address)= PPN + PPO;
-
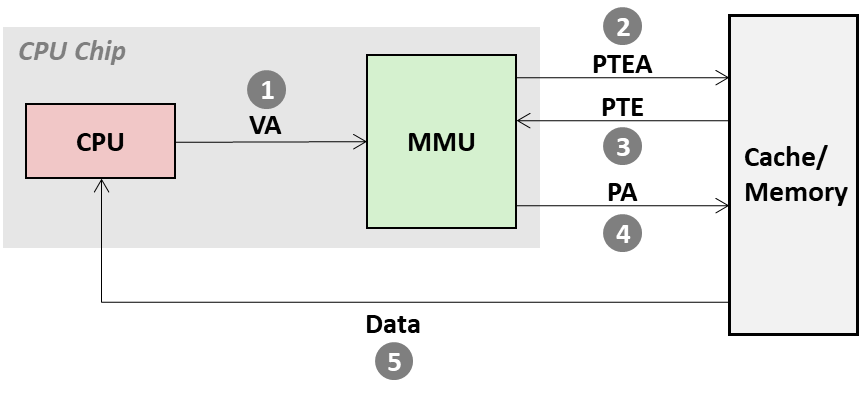
Page Hit
- 按照 step 1~5 的顺序完成 data fetching;
- 即便 VP 命中,也需要 step 2 获取 PTE,Step 4 根据 PA 获取数据 ,共计两次内存访问;
-
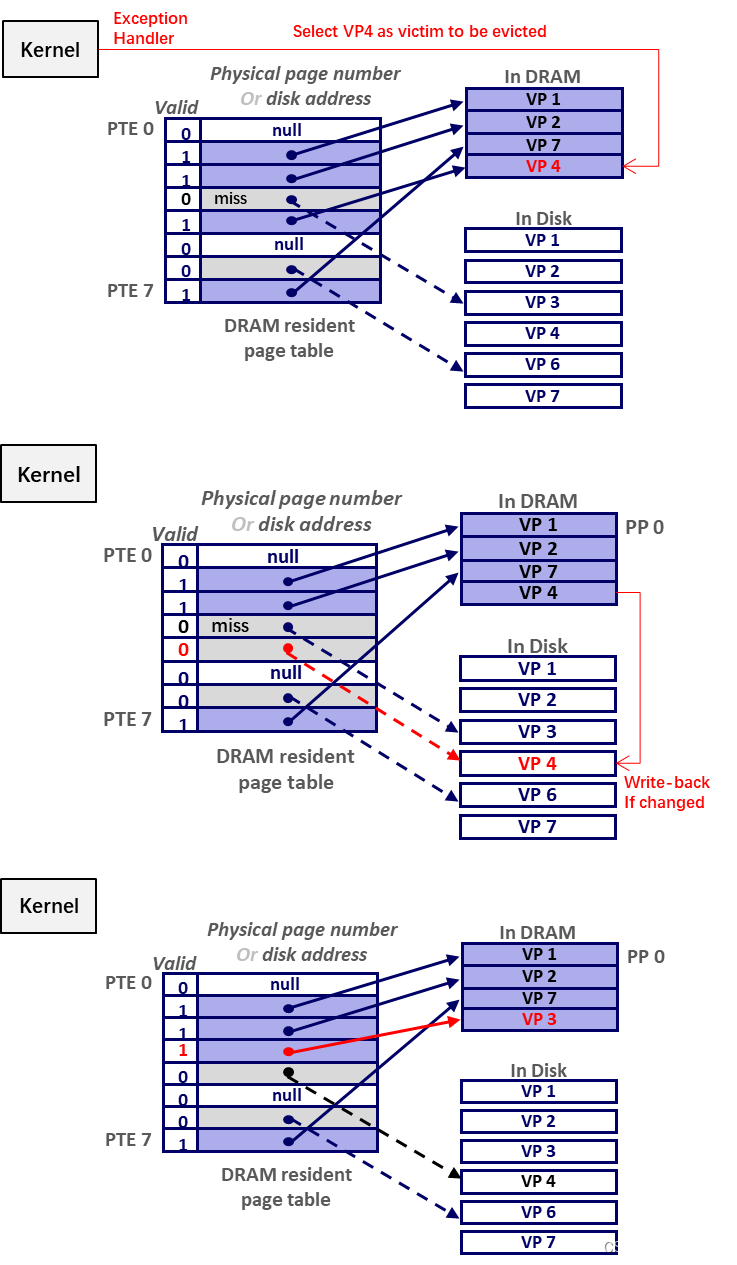
Page Fault
- step 2,valid = 0,MMU 触发 Page Fault Exception;
- step 5,handler 挑选 VP,如果在内存中被修改过(被标记为 dirty),则写回硬盘;反之(clean)则直接抛弃;
- step 6,handler 将缺失的页 缓存 到内存,再到 Cache,同时更新 PTE;
- step 7,handler 结束返回原进程,控制流 重新执行 Page Fault 的命令,这次 hit;
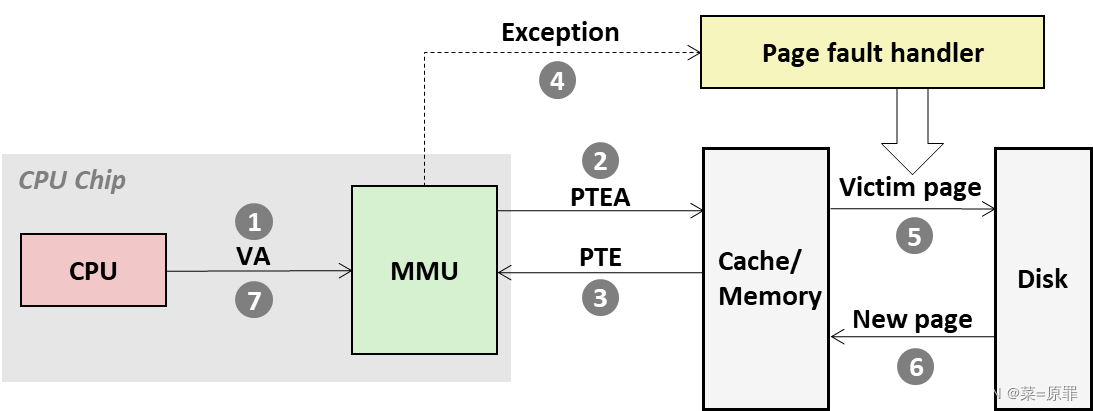
-
Cache 与 VM 的集成(第一次优化):
- MMU 向 L1 Cache 访问 PTE(应该是 PTBR + PPN 得到的 物理地址),如果 miss 则再由 L1 Cache 从 内存 读取存放有 PTE 的 block(Ch 6.4 Cache Memories);
- MMU 获得 PTE 中 VPN 对应的 PPN,拼接 PPO,得到 PA,再向 L1 Cache 请求 PA 单元内的数据;
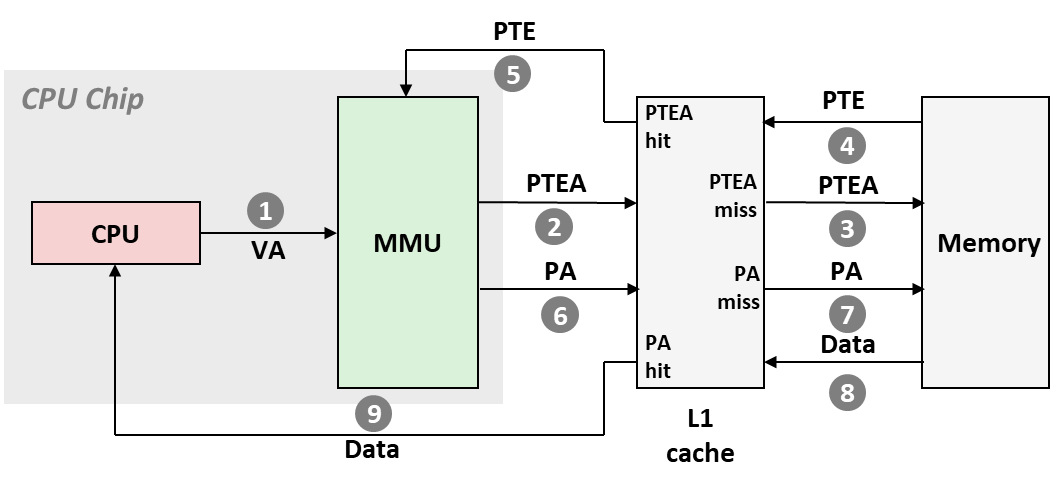
-
硬盘 与 VM 的三种交互
- .text 或 .data section 内的 Page 只读,不存在 dirty 回写硬盘的情况;
- C语言 open() 创建一个 user level 的文件,C 库 allocate 一段 虚拟地址 映射到这个文件,Virtual Memory System 分配对应的 PP 映射到 这段 虚拟地址,一旦文件被写入,PP 记为 dirty,带 文件被 close 或 文件映射的 PP 被 evict 时,PP 就被回写到硬盘上,user level 的文件得以保存;
- 如前所述,为节省 物理内存 资源,非活跃进程的部分 VP ( Virtual Page ) 被 evict 到硬盘上 交换分区(swap area 或 swap file)内;
-
Speed Up Translation with TLB
- 如果使用原有的 L1 Cache ⇒ L2 Cache ⇒ Memory 体系缓存页表,PTE 可能被 .data 或 .text section 挤到内存中,导致缓存 miss;即便 没有 miss,每次地址转换也会花费至少一个 L1 Cache 级别的延时;
- 地址转换的缓存 使用独立硬件(第二次优化),Translation Lookaside Buffer(TLB):
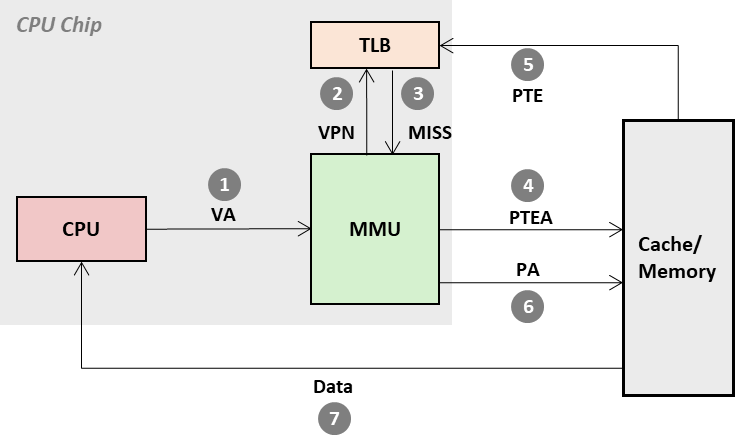
- TLB 属于 MMU,专用于缓存 PTE;
- 与 Ch 6.4 相同,将 VPN 分割为 索引 TLB set 的 index 域,和 索引 TLB line 的 tag 域;
- TLB 中 set 的数量决定了 index 域的位数,记为 TLBI;其余位作为 tag 域,记为 TLBT;
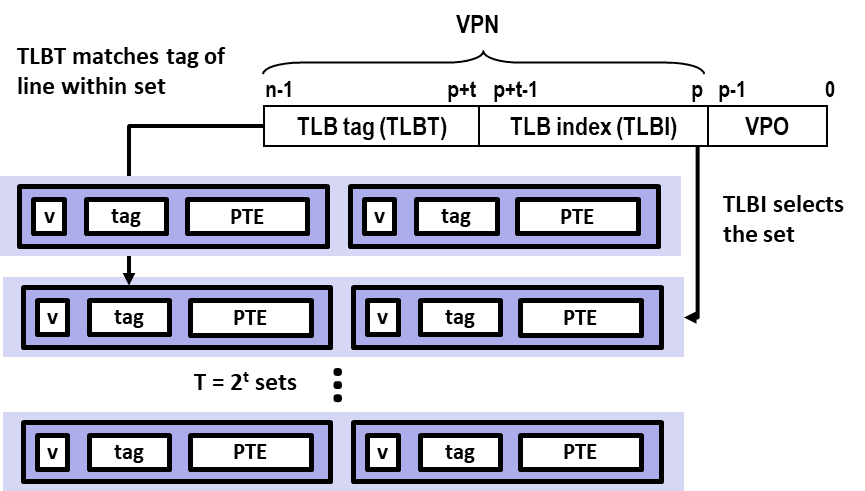
-
2-Level Page Tables
- 通常 x86-64 虚拟地址空间 48 bits,4 KB( 2 12 2^{12} 212 B)大小的页面,8 bytes 的 PTE,则页表总大小为: 2 48 2 12 ⋅ 8 = 2 39 b y t e s = 0.1 T B \frac{2^{48}}{2^{12}} \cdot 8 = 2^{39} bytes = 0.1 TB 212248⋅8=239bytes=0.1TB,显然,内存放不下,需要对页表 再次 “分级缓存”(第三次优化);
- 以 x86 为例,4-Byte PTE,4KB 页面 ,代码段 及 数据段 存储在 VP [0] ~ VP [2047] 中;其后 6 KB 未使用、未分配,用作 Gap;其后 1023 个未分配 VP;其后 VP [9215] 用作栈空间;
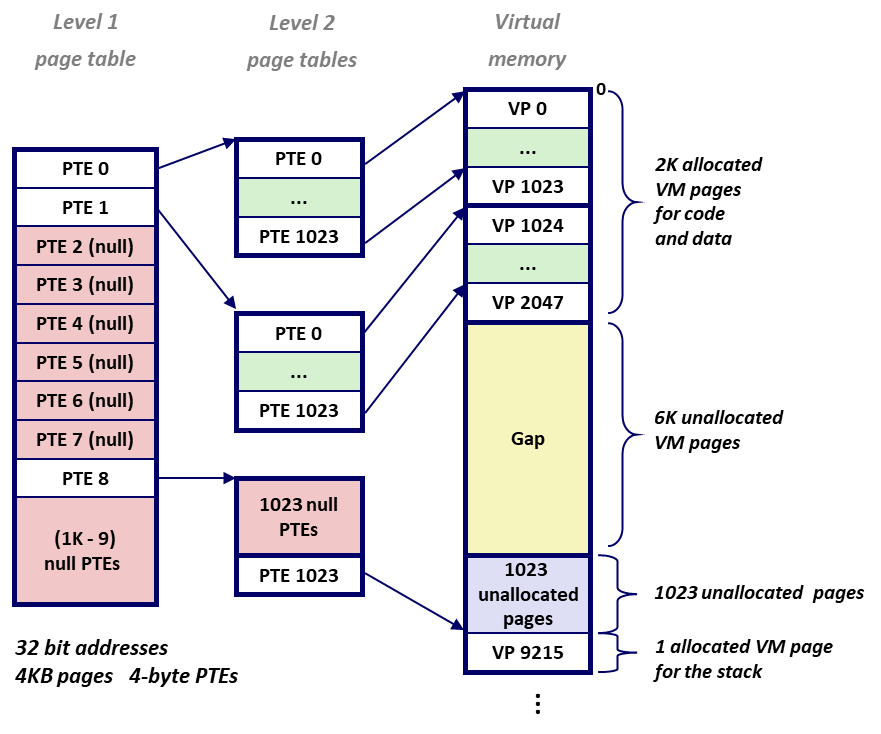
- 每个 Level 2 级页表均为 1024 × 4 B = 4 K B 1024 \times 4 B = 4 KB 1024×4B=4KB;program 共计 9216 个 VP,理论需要 9216 1024 = 9 \frac{9216}{1024} = 9 10249216=9 张 Level 2 级页表;而 9 张 Level 2 级页表的 物理 基地址,显然可以被一张 Level 1 级 页表 存下;
- 如果 program 所有 VP 均非空,Level 2 级 页表 将占用 9216 × 4 = 36 K B 9216 \times 4 = 36 KB 9216×4=36KB,此时 多级缓存 退化为 直接缓存(Level 1 级 页表 的存在多浪费了 9216 1024 × 4 B = 36 B \frac{9216}{1024}\times 4 B = 36 B 10249216×4B=36B 的空间);
- 如果 program 存在 6 K Gap + 1023 unallocated 的 Pages,实际只需要 3个 Level 2 级 页表,占用内存 1024 × 4 × 3 = 12 K B 1024 \times 4 \times 3 = 12 KB 1024×4×3=12KB,算上 Level 1 级 页表 1 K × 4 = 4 K B 1K \times 4 = 4 KB 1K×4=4KB,多级页表共占用 16 KB;
- 可见,多级页表 主要 利用了 数据稀疏性,Level 1 级 PTE = null,就可以省略大部分未被使用的 Virtual Page 对应的 Level 2 级 页表的空间;
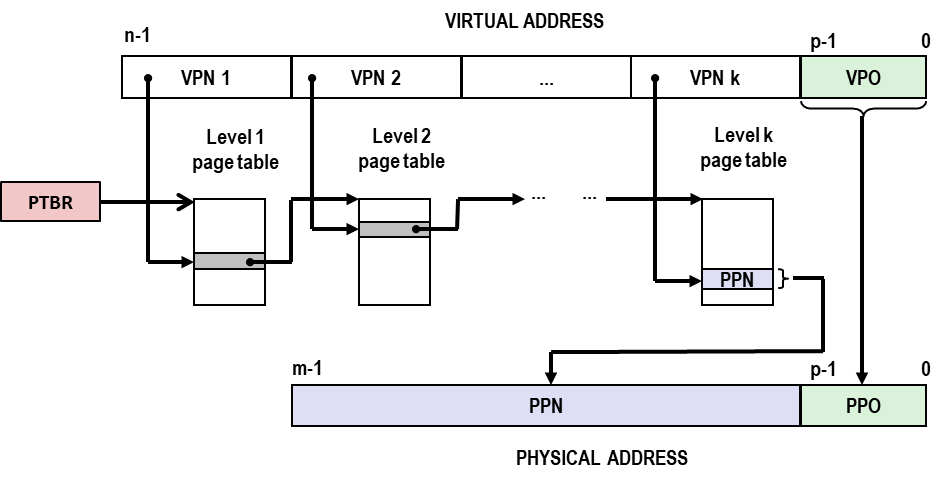
-
Multi-Level Page Tables
- VPN k 是第 k 级页表的 index,检索到的 PTE 指向第 k+1 级页表的物理地址;
- L1 级 页表 覆盖了全部地址空间,L2 则覆盖了当前 指令 前后的大部分地址空间(spacial locality),这些 上层页表 在 TLB 中常驻,保证了 MMU 地址转换 的高效;
早期,Intell 8086 只有 16 位地址总线,为了加大寻址空间,4 bit 的 Segment Register 诞生了(熟悉《微机原理》的朋友可能知道 Code Segment Register 和 Instruction Pointer Register 和 段间寻址 相关的内容),CS:IP 组合成 20 bit 的物理地址;这也许就是 VM 的原型;
9.2 Systems
9.2.1 Memory System Example
- 分析一个简单系统:
- Virtual Address 14 bit,Physical Address 12 bit,Page Size 64 B,TLB Page Table 容纳 16 个 PTE,4-way associative,则 16 / 4 = 4 个 set,TLBI 只需要 2 bit,其余 2 bit 作 TLBT;
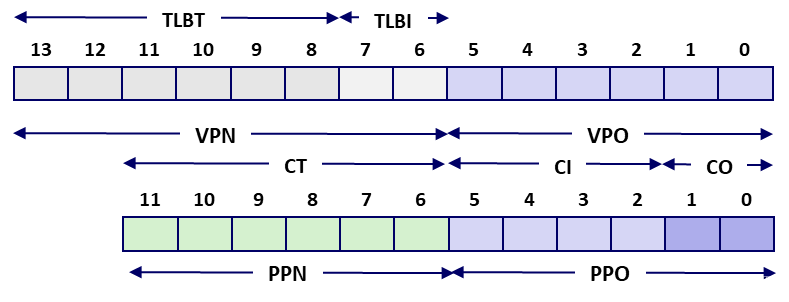
- TLB 中缓存的页表如下(这里为方便描述,展示了 Set 列,实际不存在);
 * 内存中缓存有 program 的全部页表(这里为方便描述,展示了 VPN 列,实际不存在);
* 内存中缓存有 program 的全部页表(这里为方便描述,展示了 VPN 列,实际不存在); 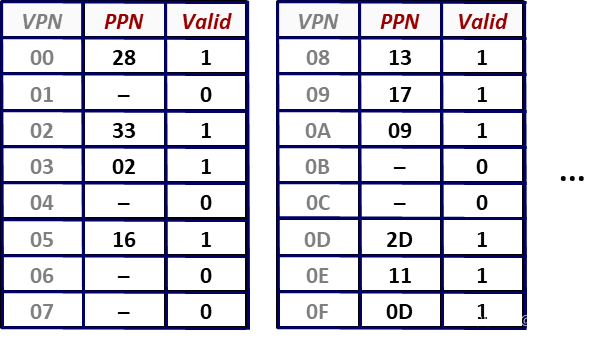
- L1 Cache,Fully Associative,1 set,16 lines,4-byte block(这里为方便描述,展示了 idx 列,实际不存在),Cache Offset 只需要 2 bit,Cache Index 这里取 4 bit,剩余 6 bit 给 Cache Tag;

- Virtual Address 14 bit,Physical Address 12 bit,Page Size 64 B,TLB Page Table 容纳 16 个 PTE,4-way associative,则 16 / 4 = 4 个 set,TLBI 只需要 2 bit,其余 2 bit 作 TLBT;
Cache Tag 并非必须等于 PPN,但 Intell 发现,相等 可以带来 “好处”;
-
场景一 TLB 与 L1 Cache 均 hit
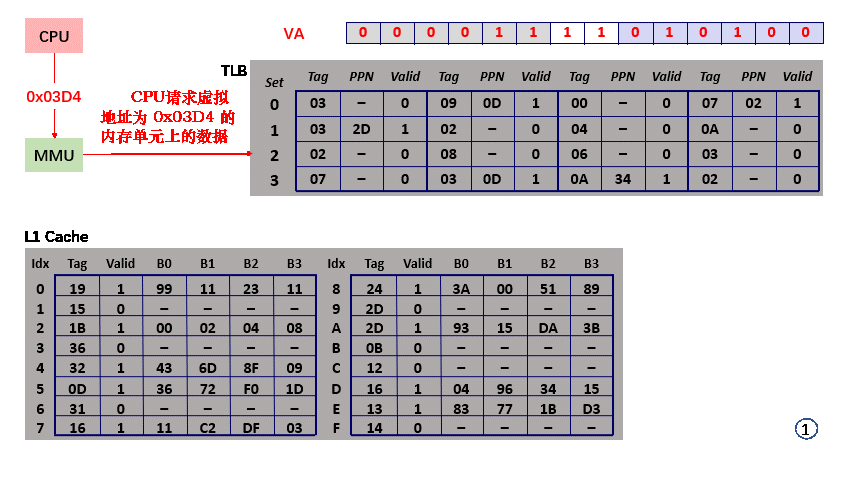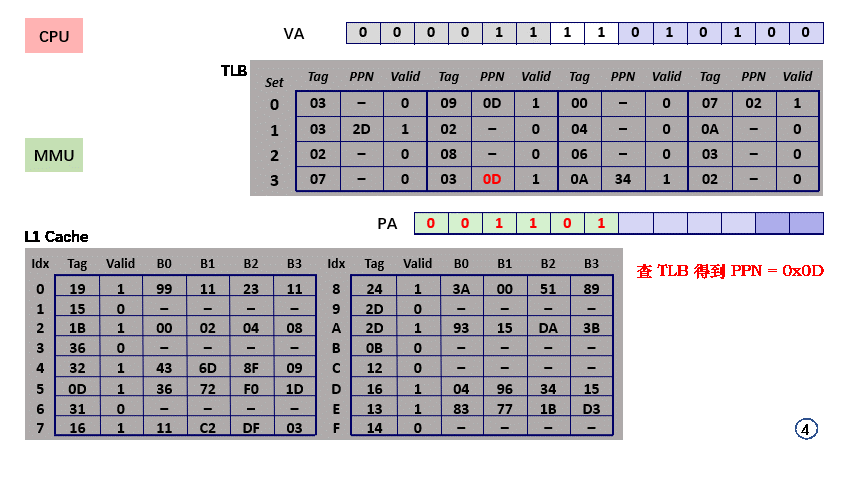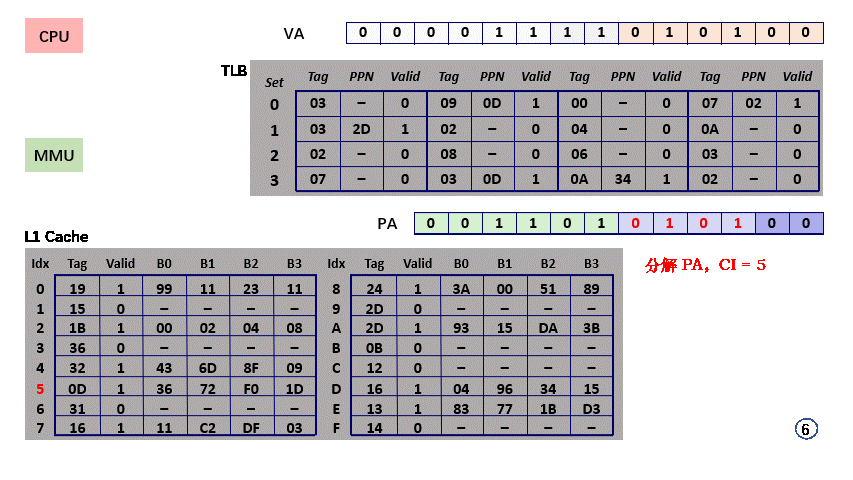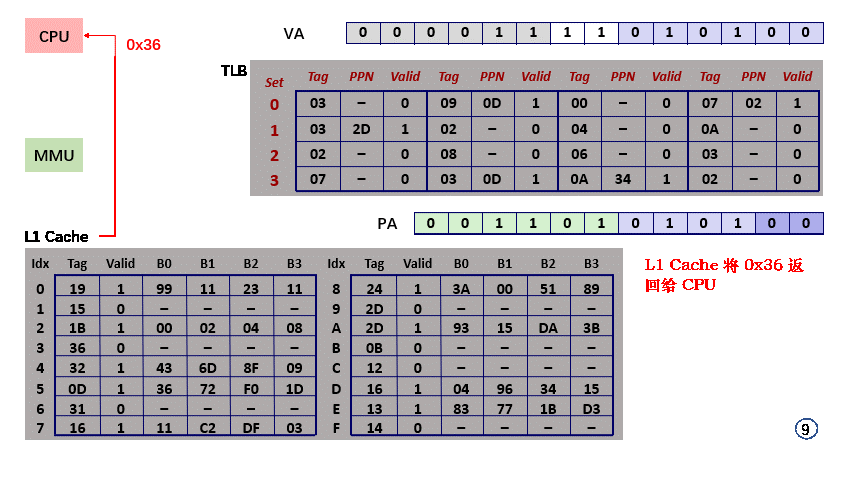
- step1,CPU 请求 虚拟地址 VA = 0x03D4 上的数据:
- step2,VA = 0x03D4,PPN = 0x0F,TLBI = set = 0x03;
- step3,TLBT = tag = 0x03,valid = 1,hit;
- step4,取得对应 PPN = 0x0D;
- step5,MMU 向 L1 Cache 请求 物理地址 PA = PPN + VPO = 0x0354 上的值;
- step6,PA 分解得 CI = set index = 5;
- step6,PA 分解得 CT = tag = 0x0D,valid = 1,hit,数据所在的 block 缓存在 L1 Cache 中;
- step7,PA 分解得 CO = 0x00,block 中检索 offset = 0 的内存单元,得到 0x36;
- step8,L1 Cache 直接将 物理地址 0x0354 上的值 0x36 返回给CPU;
- 整个过程没有访问内存,效率极高;
-
场景二 TLB 与 L1 Cache 均 miss
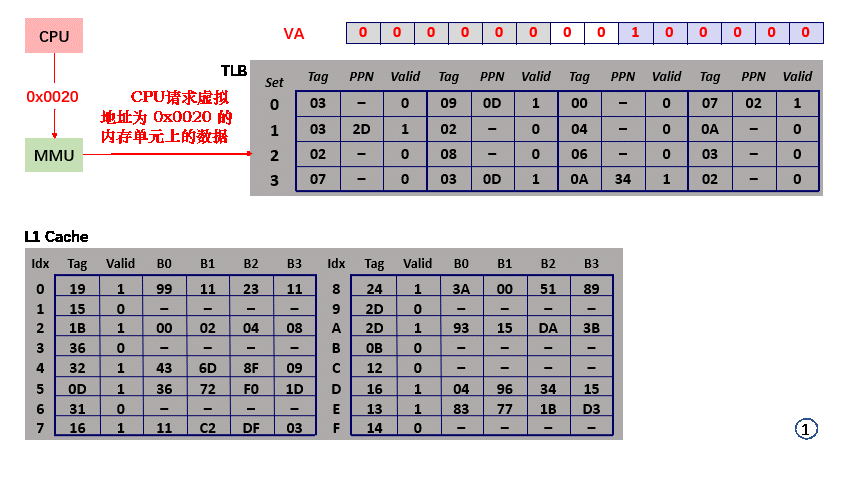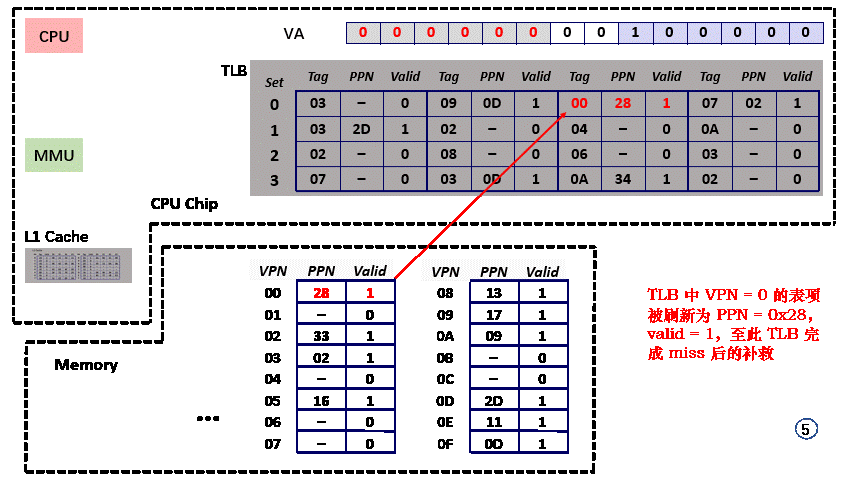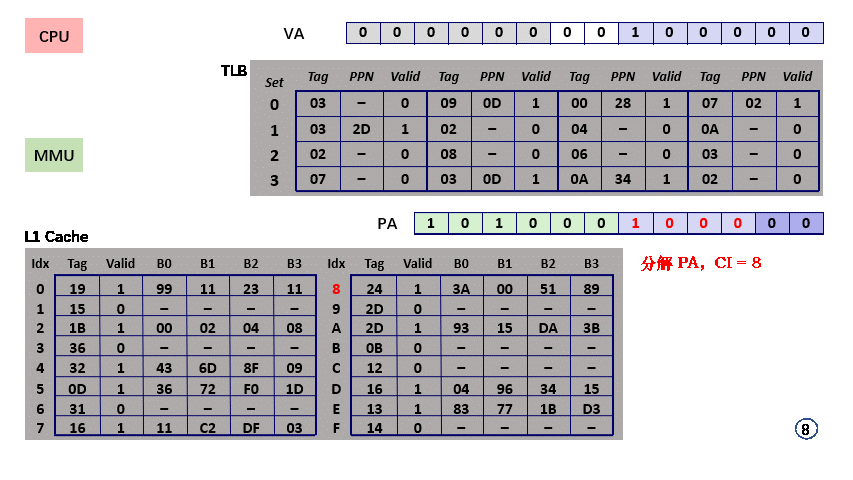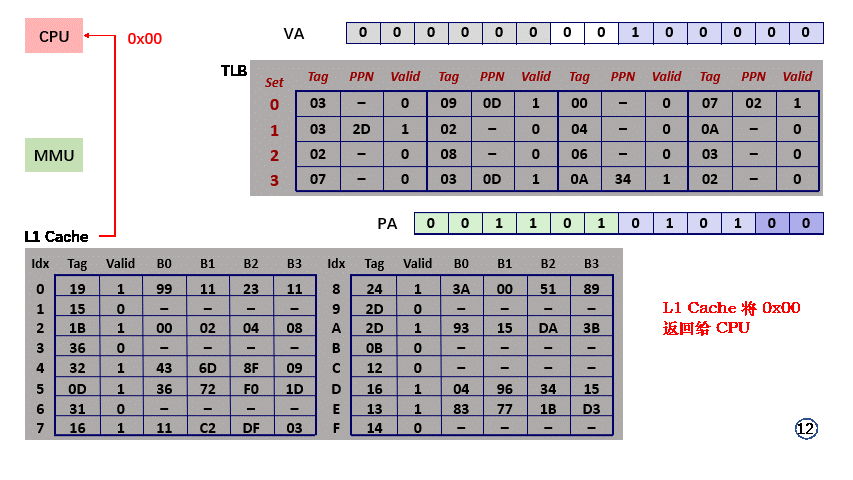
- step1,CPU 请求 虚拟地址 0x0020 上的数据;
- step2,VA = 0x0020,PPN = 0x00,TLBI = set = 0x00;
- step3,TLBT = tag = 0x00,但 valid = 0,页表项 miss;
- step4,根据 PTBR,MMU 向内存请求 物理地址 PA = PTBR + VPN 上的值,valid = 1,VPN 对应的页面无需 从硬盘取出 或 新建页面;得到 PTE = 0x28;
- step5,刷新 TLB 中 set = 0x00,tag = 0x00 对应的 PTE(0x28,valid=1),PPN = 0x28;
- step6,MMU 向 L1 Cache 请求 物理地址 PA = PPN + VPO = 0x0A20 上的值;
- step7,PA 分解得 CI = set index = 8;
- step8,PA 分解得 CT = tag = 0x28,L1 Cache 上 set = 0x08 但 tag = 0x28 不存在,miss,数据所在的 block 需要从内存中获取;
- step9,L1 Cache 从内存中取得对应 block,更新 set 内 tag = 0x28 的 block 单元;
- step9,PA 分解得 CO = 0x00,block 中检索 offset = 0 的内存单元,得到 0x00;
- step10,L1 Cache 直接将 物理地址 0x0A20 上的值 0x00 返回给CPU;
- 整个过程共访问 2次 内存;
9.2.2 A Real x86-64 Memory System
来看看真实的 Intell Core i7 VM 是如何实现的;
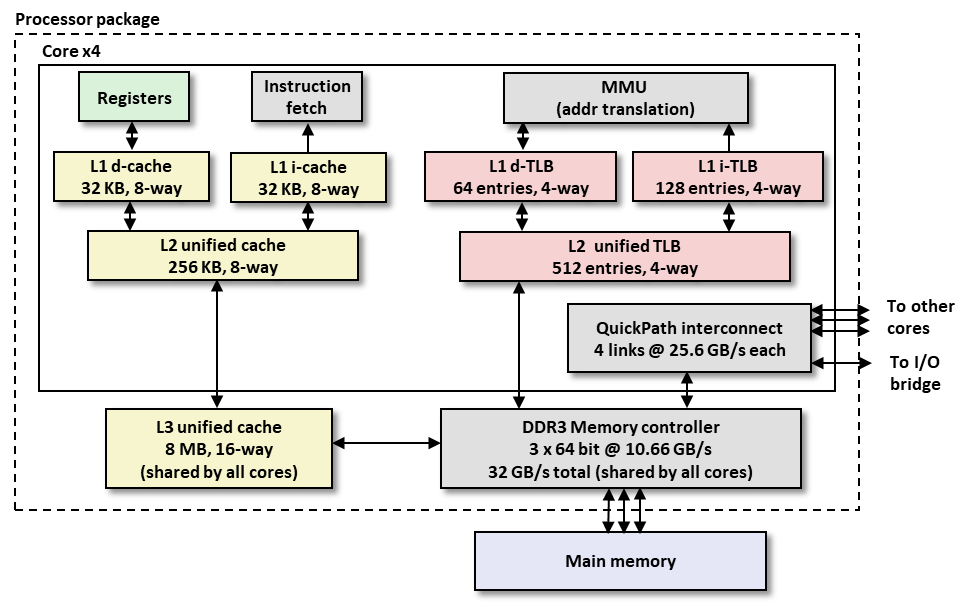
整个 Package 就是 一块 封装后的处理器芯片,芯片内封装有 4 个核 ( core ),每个核都有:
- Register
- 指令存取解码器
- L1 级数据缓存 ( L1 d-cache )、L1 级指令缓存 ( L1 i-cache )
- L2 级 ( 公用 ) 缓存
- MMU
- L1 级 TLB 数据缓存 ( L1 d-TLB )、L1 级 TLB 指令缓存 ( L1 i-TLB )
- L2 级 ( 公用 ) TLB 缓存
- QuickPath Interconnector
除 core 以外,芯片上还封装有:
- L3 级 ( 多核公用 ) 缓存
- DDR3 内存控制器
- 等…
访问 L1 级缓存 需要约 4个 时钟周期,访问 L2 级缓存 需要约 10个 时钟周期,访问 L3 缓存需要通过 核间 / 片外 ( off-chip ) 链接,因此耗费的时间增加到 30~50 个时钟周期;
把 L2 Cache 所需的晶体管,全堆到 L1 Cache 上,岂不是更好?
视频里,老师解释 “没有 L2 miss 的代价会很大”,我不是很认同,L1 + L2 的总大小没变 ( 事实上还变大了,L1 不再是 L2 某一块的 copy,L1 和 L2 可以全部用来缓存 L3 中的块,而不仅仅 L2 缓存 L3 中的块 ) miss 的概率没有发生变化,但 miss 的代价由 L2 降低到了 L1 的水平,所以理论上把 L2 用到的晶体管全部分配给 L1 会更快?不太确定 …
stackoverflow 查了一下,主流的说法还是 成本 和 工艺 问题,又 “大” 又能 “高速多路读写” 的 L1 不好造;
Intell 系统中,VA 长度 48 位,页面大小
4
K
B
=
2
2
×
2
10
=
2
12
4 KB = 2^{2} \times 2^{10} = 2^{12}
4KB=22×210=212,故 VPO 长 12 位,VPN 长
48
−
12
=
36
48-12=36
48−12=36 位;
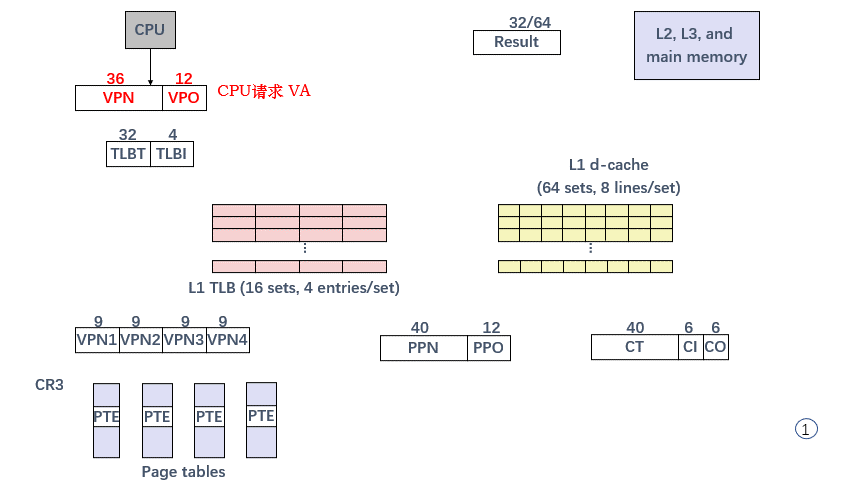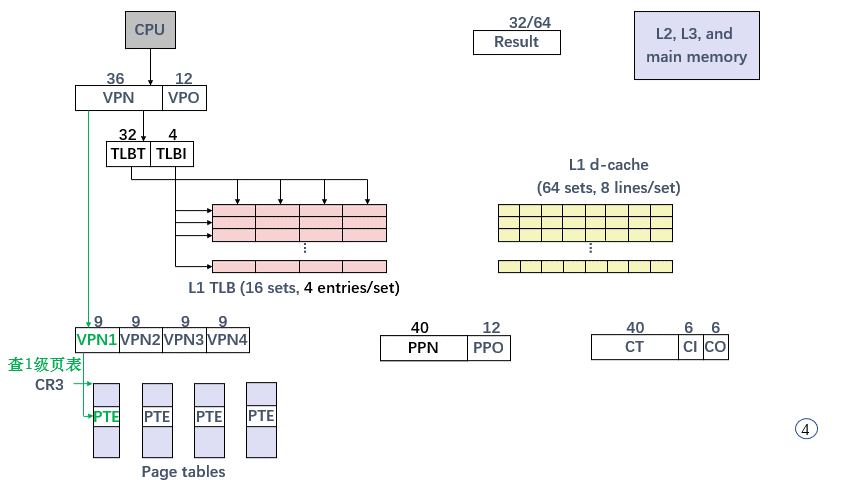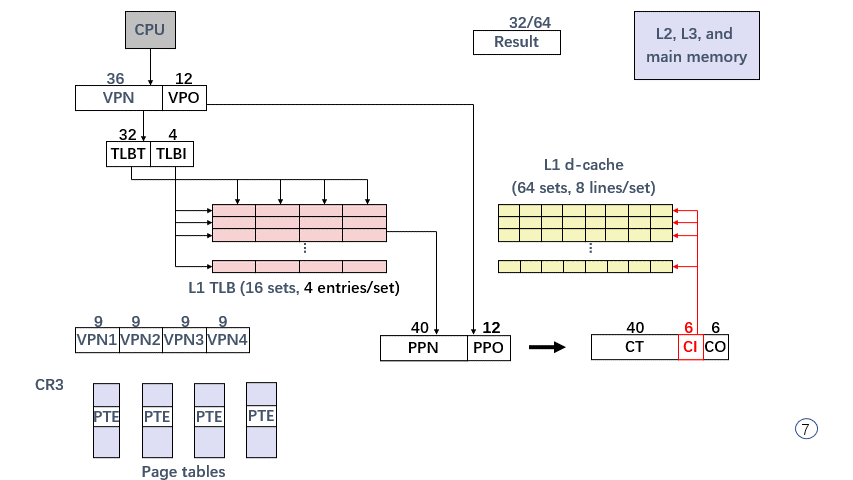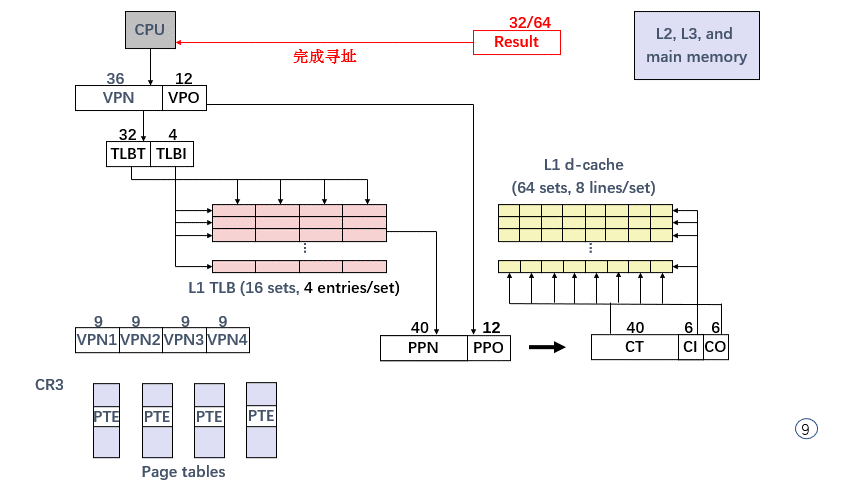
之前简单模型中 PPN = CT 只是巧合,但这里 不 是 巧 合 !
Intell 为了提升效率,将 VPO ( = PPO = CI + CO ) 直接给到 Cache 并立即查找 CI 对应 Set Index,CO 对应 Block Offset,等 CT 到达 Cache 后立刻就能确认 Line Tag,地址转换 与 Cache 缓存查找 能够并行了 !!
CI + CO 一共才 12 位,也因此导致 L1 Cache 比较小。。。
- Level 1~3 Page Table Entries

| bit | function |
|---|---|
| P | Present ? 页表 是 (1) / 否 (0) 存在于内存当中 如果不在,剩余的位 则表示 页表在磁盘中的位置 |
| R/W | 页表 ( 包括下级 ) 的访问权限是 只读 还是 读写 |
| U/S | User or Supervisor (kernel) mode 用户程序是否可访问 ( 即是不是内核页 ) 操作系统的 安全 不可侵犯 靠的就是这一位 |
| WT | 采用 “直写” 还是 “回写” 的缓存策略 ( 基本都是 “回写” ) |
| A | Reference bit MMU 读/写 时置位,软件复位 |
| PS | 页面大小 4 KB 还是 4 MB ( 仅1级页表有这一位 ). |
| PTPBA | 页表 物理 基地址 下级页表起始物理地址的最高 40 位 ( 页表大小 4KB,可以推算出 Core i7 支持的物理地址是 40 + 12 = 52 位 ) |
| XD | 页表内取出的指令是否可执行 还记得 “注入 攻击” 么? |
- Level 4 Page Table Entries

| bit | function |
|---|---|
| D | Dirty,MMU 写时置位,软件复位 |
| PPBA | 页表 物理 基地址,同前 40 bit |
每当进程切换,操作系统 便将 L1 页表的物理地址 写入 CR3 寄存器中,实现地址空间切换;
9.2.3 Virtual Address Space of a Linux Process
了解 Linux 如何实现虚拟内存 将帮助我们 彻底弄懂 execve 和 fork 的原理;
如 前文 Ch 7.2.4 所示
| Content | Address |
|---|---|
| Kernel ( different region ) 0xFFFF xxxx xxxx xxxxx | 进程 “上下文”,每个进程都不一样,存放如 ptables、task、mm struct 和 内核栈 等数据结构; |
| Kernel Physical Memory ( identical region ) 0xFFFF xxxx xxxx xxxxx | “都一样”区间,1:1 映射到 DRAM 物理内存 为内核提供了一种 便捷访问物理地址的方式 |
| Kernel Code and Data ( identical region ) 0xFFFF xxxx xxxx xxxxx | “都一样”区间,存放 内核 代码 及 数据 |
| Gap | 内核 与 用户空间 之间的 留白 |
| User stack (created at runtime) | 向下生长 |
| “大堆栈” ( for huge object ) | 在请求超大块空间时出现 推测 malloc 请求的大块 和 小块时 使用的分配策略 不同 |
| % rsp ⇒ | rsp 指向栈顶,入栈 即 rsp 值减小 |
| Memory-mapped region for shared libraries | 通过 内存映射 共用的 .so 库文件 |
| % brk ⇒ | 全局变量 brk 指向 堆顶 由内核维护,用于内核跟踪 堆顶 的位置 |
| Run-time heap (create by malloc) | 向上生长 |
| Read/write data segment .bss | 未初始化的变量 |
| Read/write data segment .data | 被 symtab 记录值 初始化 的变量 |
| Read-only code segment .init .text .rodata | 原封不动拷贝到内存 |
| Unused | 0x00~0x3FFFFF Linux 进程保留 4M 空间 |
Linux 的进程由 多个 Area 组成:
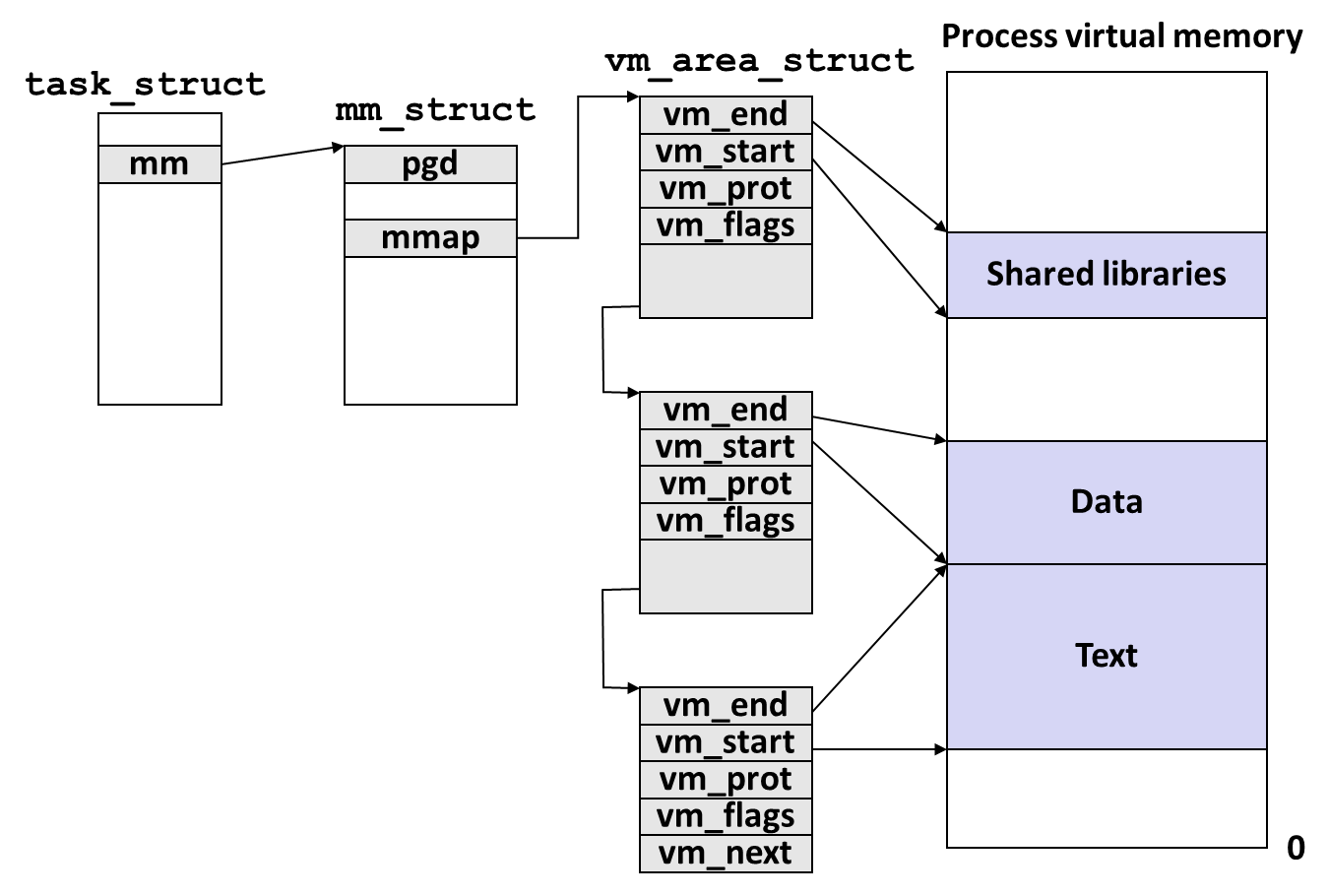
- 每个 Area 由对应的 vm_area_struct 管理;
- vm_prot 控制该 Area 的读/写 权限;
- vm_flags 控制页面 进程间共享 还是 私有,默认私有;
- 多个 vm_area_struct 节点组成链表;
- mm_struct 中的指针 mmap 指向 链表的表头;
- task_struct 中的指针 mm 指向 mm_struct;
-
mm_struct 中的指针 pgd ( Page Global Directory Address ) 指向一级页表, 进程被调度时 kernel 将 pgd 的值拷贝到 CR3 中实现不同进程虚拟地址空间的切换;
现实中, vm_area_struct 会组成 Red-Black tree,而非 List;
- Linux Page Fault Handling,三个 缺页中断 ( segment fault ) 的原因:
- 虚拟地址空间内,没有分配 或 创建过该页,kernel 遍历 vm_area_struct 链表后,发现没有对应节点;
- ( Linux ) kernel 检查 vm_area_struct 的 vm_flags 标志位,发现 指令 尝试向 只读Area ( 如 .text ) 执行写操作;
- 内存 没有缓存,需要 从磁盘换页;
9.2.4 Memory Mapping
- VM 的每个 Area 都拷贝 ( 初始化时只读 ) 自硬盘上的 Regular File 文件的 某一部分 ( 该过程即 内存映射 );
- 被写入的页面 ( dirtied ),发生换页时被保存到 磁盘上,swap file 中;
- 通过 Page Fault 申请分配一个 全 “0” 的物理页 ( demand-zero page ),但硬盘上没有其对应的实体文件,这种又被称作 匿名文件 ( Anonymous File ),但本质是一个 dirty 的页面;

以 Apache ( Nginx 类似同理 ) 为例,通常这类服务器进程为了提高并发性能,会 fork 出多个完全相同的 子进程 ( worker ) 同时处理外部请求,这些相同的子进程会用到相同的 库文件 ( libxx.so ),每个 库文件 被 load 到一块物理内存上 ( 只有一个物理实体 ),被映射到多个 子进程 的不同虚拟地址上
就需要开辟出一块 共享缓存 实现


















