目录
前言
环境准备
软件安装
数据准备
模型训练
模型名称修改
数据集修改
模型参数修改
数据读取编码修改
output_dir修改
模型调用
验证
小结
前言
人工智能大模型是一种能够利用大数据和神经网络来模拟人类思维和创造力的人工智能算法。它利用海量的数据和深度学习技术来理解、生成和预测新内容,通常情况下有数十亿乃至数百亿个参数,可以在不同的领域和任务中表现出智能拟人的效果。
现在大模型火的不行,项目中如果没有大模型好像都缺少点啥?没办法要跟着时代进步,最近研究了一下开源的通义千问大模型,翻阅了大量文档,记录一下使用心得。我使用的是通义千问Qwen-VL-Chat多模态模型。LLM模型可以通过Ollama下载官网最新推出的Qwen2模型,网上教程很多比较简单,但我们怎么可能仅仅只用聊天,必须得上多模态,Ollama的多模态模型很少,并且尝试过效果都不好,最后盯上modelScope上的Qwen-VL-Chat多模态,官网提供了modelScope和transformers两种途径获取模型,训练需要用到transformers,梯子已经架好。
环境准备
硬件: 本人使用的是window10系统,电脑为工作站内存,显存不需要考虑,正常情况下16G内存,6G显存能跑低7亿参数的模型。
软件: Anconda、Pytorch、Python、cuda(有GPU的考虑)主要用到这3个,其它包稍后说明。版本之间要按照官网上的说明来寻找适合的版本。我使用的版本如下:
Anconda:23.3.1;
Pytorch:2.0.1;
Python:3.10;
cuda:11.7;
软件安装
详细环境安装请看通义千问Qwen-VL-Chat大模型本地部署(一);
数据准备
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是Qwen-VL,一个支持视觉输入的大模型。"
}
]
},
{
"id": "identity_1",
"conversations": [
{
"from": "user",
"value": "Picture 1: <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>\n图中的狗是什么品种?"
},
{
"from": "assistant",
"value": "图中是一只拉布拉多犬。"
},
{
"from": "user",
"value": "框出图中的格子衬衫"
},
{
"from": "assistant",
"value": "<ref>格子衬衫</ref><box>(588,499),(725,789)</box>"
}
]
},
{
"id": "identity_2",
"conversations": [
{
"from": "user",
"value": "Picture 1: <img>assets/mm_tutorial/Chongqing.jpeg</img>\nPicture 2: <img>assets/mm_tutorial/Beijing.jpeg</img>\n图中都是哪"
},
{
"from": "assistant",
"value": "第一张图片是重庆的城市天际线,第二张图片是北京的天际线。"
}
]
}
]数据格式如上,文件喂.json格式。<img>标签为图片地址标签,<box>标签为左上角,右下角坐标,用于标出矩形框,<ref>引用文本标签。
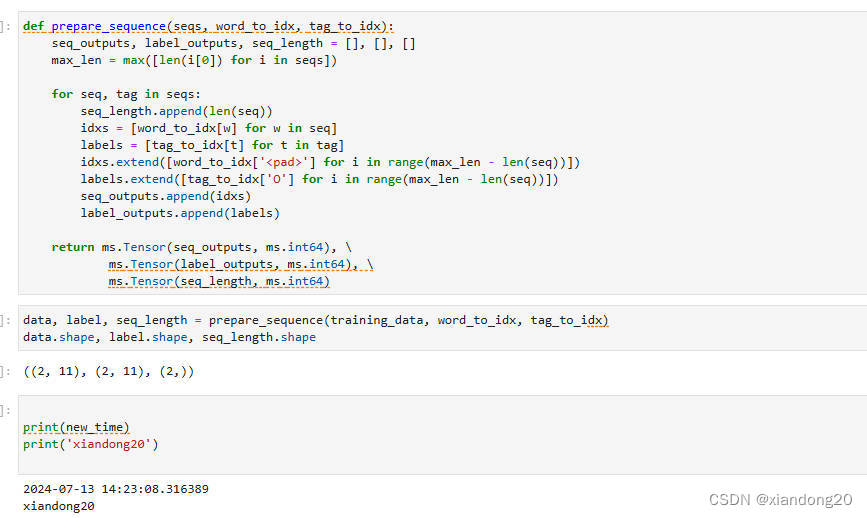
模型训练
这里面踩了不少坑,网上一大堆linux环境训练的教学,找个windows环境的训练找不到,身边也没有linux系统,头铁只能硬搞finetune.py脚本。finetune.py是windows系统执行训练的脚本,直接运行报错,问题不少下面列举我遇到的问题以及解决方式:
模型名称修改
将代码模型名称改成
class ModelArguments:
model_name_or_path: Optional[str] = field(default="QWen/QWen-VL-Chat")数据集修改
@dataclass
class DataArguments:
data_path: str = field(
default="自己的训练数据集位置", metadata={"help": "Path to the training data."}
)
eval_data_path: str = field(
default="自己的验证集位置", metadata={"help": "Path to the evaluation data."}
)
lazy_preprocess: bool = False模型参数修改
@dataclass
class TrainingArguments(transformers.TrainingArguments):
cache_dir: Optional[str] = field(default=None)
optim: str = field(default="adamw_torch")
model_max_length: int = field(
default=1024, # 这里根据自己硬件内存适当调整我的内存是150G 改成1024跑起来会占掉120G左右
metadata={
"help": "Maximum sequence length. Sequences will be right padded (and possibly truncated)."
},
)
use_lora: bool = True # 使用lora参数 将false 改成true
fix_vit: bool = Truemodel_max_length根据自己计算机内存适当调整,我们需要使用lora参数。
数据读取编码修改
def make_supervised_data_module(
tokenizer: transformers.PreTrainedTokenizer, data_args, max_len,
) -> Dict:
"""Make dataset and collator for supervised fine-tuning."""
dataset_cls = (
LazySupervisedDataset if data_args.lazy_preprocess else SupervisedDataset
)
rank0_print("Loading data...")
# 使用UTF-8加载
train_json = json.load(open(data_args.data_path, "r", encoding='utf-8'))
train_dataset = dataset_cls(train_json, tokenizer=tokenizer, max_len=max_len)
# 使用UTF-8加载
if data_args.eval_data_path:
eval_json = json.load(open(data_args.eval_data_path, "r", encoding='utf-8'))
eval_dataset = dataset_cls(eval_json, tokenizer=tokenizer, max_len=max_len)
else:
eval_dataset = None
return dict(train_dataset=train_dataset, eval_dataset=eval_dataset)这里要在open()中添加encoding='utf-8',不然文件读取会编码集错误。
output_dir修改
在运行finetune.py文件的时候会报output_dir找不到的错误,如果使用pycharm运行需要修改如下设置:

edit添加运行指令 --output_dir 模型输出路径,点OK;

命令行方式启动:
python finetune.py --output_dir 输出文件地址至此需要修改的内容都结束了,如果运行提示内存不足那么需要修改模型参数model_max_length到合适值。我使用的内存为150G,model_max_length=1024运行会占120G左右。这里用到transformers的版本是项目中自带版本不需要升级到最新版。上一篇中如果要使用transformers需要升级最新版。
模型调用
训练结束后会在设置的输出目录中看到保存的微调模型。接下来就是调用,我们还继续使用上一篇中的http_api.py调用。代码如下:
代码中添加了model_name_or_path = "H:/ali-qwen/Qwen-VL/output_dir"为上一步模型训练的输出地址,通过peft的PeftModel在模型加载的时候使用如下方式将我们自己训练的模型参数添加到预训练模型中。并且将modelscope相关加载方式换成了transformers的。
model = PeftModel.from_pretrained(model, model_id=model_name_or_path)
from argparse import ArgumentParser
from contextlib import asynccontextmanager
import torch
import uvicorn
from fastapi import FastAPI, Response
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
# from modelscope import (
# AutoModelForCausalLM, AutoTokenizer, GenerationConfig
# )
from sse_starlette.sse import EventSourceResponse
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
from peft import PeftModel
DEFAULT_CKPT_PATH = 'QWen/QWen-VL-Chat'
model_name_or_path = "H:/ali-qwen/Qwen-VL/output_dir"
@asynccontextmanager
async def lifespan(app: FastAPI): # collects GPU memory
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class RequestParams(BaseModel):
image: str
text: str
@app.post("/v1/chat/demo")
async def _launch_demo(params: RequestParams, resp: Response):
# 设置响应头部信息
resp.headers["Content-Type"] = "text/event-stream"
resp.headers["Cache-Control"] = "no-cache"
global model, tokenizer
message = params.text
query = tokenizer.from_list_format([
{'image': 'C:/Users/LENOVO/Desktop/f0d17c6f301f675ac8cbe600da4a8e1.png'},
{'text': '这是什么'},
])
return EventSourceResponse(stream_generate_text(query))
async def stream_generate_text(message):
for response in model.chat_stream(tokenizer, message, history=[]):
yield _parse_text(response)
# 设置模型参数
def _get_args():
parser = ArgumentParser()
parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH,
help="Checkpoint name or path, default to %(default)r")
parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only")
parser.add_argument("--share", action="store_true", default=False,
help="Create a publicly shareable link for the interface.")
parser.add_argument("--inbrowser", action="store_true", default=False,
help="Automatically launch the interface in a new tab on the default browser.")
parser.add_argument("--server-port", type=int, default=8000,
help="Demo server port.")
parser.add_argument("--server-name", type=str, default="0.0.0.0",
help="Demo server name.")
args = parser.parse_args()
return args
def _parse_text(text):
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split("`")
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f"<br></code></pre>"
else:
if i > 0:
if count % 2 == 1:
line = line.replace("`", r"\`")
line = line.replace("<", "<")
line = line.replace(">", ">")
line = line.replace(" ", " ")
line = line.replace("*", "*")
line = line.replace("_", "_")
line = line.replace("-", "-")
line = line.replace(".", ".")
line = line.replace("!", "!")
line = line.replace("(", "(")
line = line.replace(")", ")")
line = line.replace("$", "$")
lines[i] = "<br>" + line
text = "".join(lines)
return text
# 加载模型
def _load_model_tokenizer(args):
#, revision='master',
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "cuda"
# revision='master',
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
).eval()
# , revision='master',
model.generation_config = GenerationConfig.from_pretrained(
args.checkpoint_path, trust_remote_code=True, resume_download=True
)
# 添加自定义训练模型节点
model = PeftModel.from_pretrained(model, model_id=model_name_or_path)
return model, tokenizer
if __name__ == "__main__":
args = _get_args()
# 加载qwen-vl-chat合并后的新模型
model, tokenizer = _load_model_tokenizer(args)
uvicorn.run(app, host=args.server_name, port=args.server_port, workers=1)
验证
我将自定义的图片添加到数据集中;
验证图片如下:

在没有训练情况下模型回答如下:

经过训练后情况如下:

从结果来看只是去掉了关于键盘的描述部分,多次询问结果都一样,官网解释为当模型不清楚问题具体想要时会以介绍图片的形式回答问题,我们只是侧重于这张图片的关于烟的描述,训练后模型不再介绍关于这张图片其它之外的内容。说明对于这张图片以及我们喂给模型的数据它已经学习过了。
小结
本文介绍了开源Qwen-VL-Chat多模态本地训练功能,供小白参考,欢迎大佬指点问题。


![MySql性能调优04-[MySql事务与锁机制原理]](https://i-blog.csdnimg.cn/direct/ee3a2a3ecadc4e5eb330007d4184ee84.png)