前言
当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴。
本文主要讨论的是以公司名称或地址为主的字符串的模糊匹配。
使用编辑距离算法进行模糊匹配
进行模糊匹配的基本思路就是,计算每个字符串与目标字符串的相似度,取相似度最高的字符串作为与目标字符串的模糊匹配结果。
对于计算字符串之间的相似度,最常见的思路便是使用编辑距离算法。
下面我们有28条名称需要从数据库(390条数据)中找出最相似的名称:
| 1 2 3 4 5 6 7 8 9 | import pandas as pd
excel = pd.ExcelFile("所有客户.xlsx")
data = excel.parse(0)
find = excel.parse(1)
display(data.head())
print(data.shape)
display(find.head())
print(find.shape)
|

编辑距离算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
一般来说,编辑距离越小,表示操作次数越少,两个字符串的相似度越大。
创建计算编辑距离的函数:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def minDistance(word1: str, word2: str):
'编辑距离的计算函数'
n = len(word1)
m = len(word2)
# 有一个字符串为空串
if n * m == 0:
return n + m
# DP 数组
D = [[0] * (m + 1) for _ in range(n + 1)]
# 边界状态初始化
for i in range(n + 1):
D[i][0] = i
for j in range(m + 1):
D[0][j] = j
# 计算所有 DP 值
for i in range(1, n + 1):
for j in range(1, m + 1):
left = D[i - 1][j] + 1
down = D[i][j - 1] + 1
left_down = D[i - 1][j - 1]
if word1[i - 1] != word2[j - 1]:
left_down += 1
D[i][j] = min(left, down, left_down)
return D[n][m]
|
关于上述代码的解析可参考力扣题解:https://leetcode-cn.com/problems/edit-distance/solution/bian-ji-ju-chi-by-leetcode-solution/
遍历每个被查找的名称,计算它与数据库所有客户名称的编辑距离,并取编辑距离最小的客户名称:
| 1 2 3 4 5 6 7 | result = []
for name in find.name.values:
a = data.user.apply(lambda user: minDistance(user, name))
user = data.user[a.argmin()]
result.append(user)
find["result"] = result
find
|
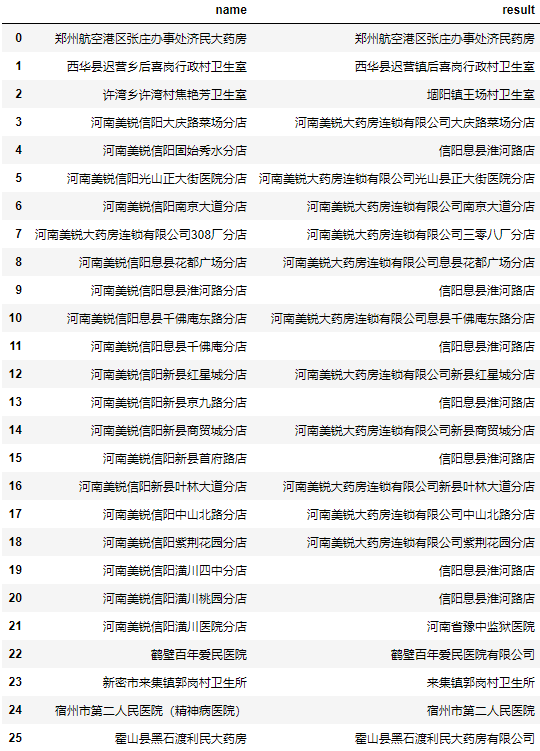
测试后发现部分地址的效果不佳。
我们任取2个结果为信阳息县淮河路店地址看看编辑距离最小的前10个地址和编辑距离:
| 1 2 3 4 5 | a = data.user.apply(lambda user: minDistance(user, '河南美锐信阳息县淮河路分店'))
a = a.nsmallest(10).reset_index()
a.columns = ["名称", "编辑距离"]
a.名称 = data.user[a.名称].values
a
|
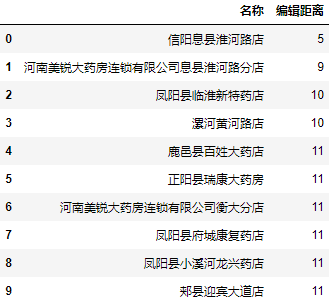
| 1 2 3 4 5 | a = data.user.apply(lambda user: minDistance(user, '河南美锐信阳潢川四中分店'))
a = a.nsmallest(10).reset_index()
a.columns = ["名称", "编辑距离"]
a.名称 = data.user[a.名称].values
a
|

可以看到,在前十个编辑距离最小的名称中还是存在我们想要的结果。
使用fuzzywuzzy进行批量模糊匹配
通过上面的代码,我们已经基本了解了通过编辑距离算法进行批量模糊匹配的基本原理。不过自己编写编辑距离算法的代码较为复杂,转换为相似度进行分析也比较麻烦,如果已经有现成的轮子就不用自己写了。
而fuzzywuzzy库就是基于编辑距离算法开发的库,而且将数值量化为相似度评分,会比我们写的没有针对性优化的算法效果要好很多,可以通过pip install FuzzyWuzzy来安装。
对于fuzzywuzzy库,主要包含fuzz模块和process模块,fuzz模块用于计算两个字符串之间的相似度,相当于对上面的代码的封装和优化。而process模块则可以直接提取需要的结果。
fuzz模块
| 1 | from fuzzywuzzy import fuzz
|
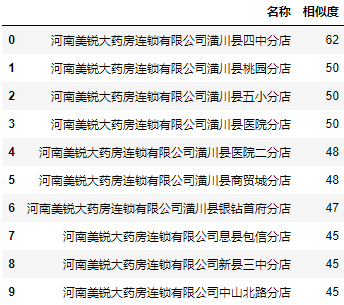
简单匹配(Ratio):
| 1 2 3 4 5 | a = data.user.apply(lambda user: fuzz.ratio(user, '河南美锐信阳潢川四中分店'))
a = a.nlargest(10).reset_index()
a.columns = ["名称", "相似度"]
a.名称 = data.user[a.名称].values
a
|
非完全匹配(Partial Ratio):
| 1 2 3 4 5 | a = data.user.apply(lambda user: fuzz.partial_ratio(user, '河南美锐信阳潢川四中分店'))
a = a.nlargest(10).reset_index()
a.columns = ["名称", "相似度"]
a.名称 = data.user[a.名称].values
a
|

显然fuzzywuzzy库的 ratio()函数比前面自己写的编辑距离算法,准确度高了很多。
process模块
process模块则是进一步的封装,可以直接获取相似度最高的值和相似度:
| 1 | from fuzzywuzzy import process
|
extract提取多条数据:
| 1 2 3 4 | users = data.user.to_list()
a = process.extract('河南美锐信阳潢川四中分店', users, limit=10)
a = pd.DataFrame(a, columns=["名称", "相似度"])
a
|

从结果看,process模块似乎同时综合了fuzz模块简单匹配(Ratio)和非完全匹配(Partial Ratio)的结果。
当我们只需要返回一条数据时,使用extractOne会更加方便:
| 1 2 3 | users = data.user.to_list()
find["result"] = find.name.apply(lambda x: process.extractOne(x, users)[0])
find
|
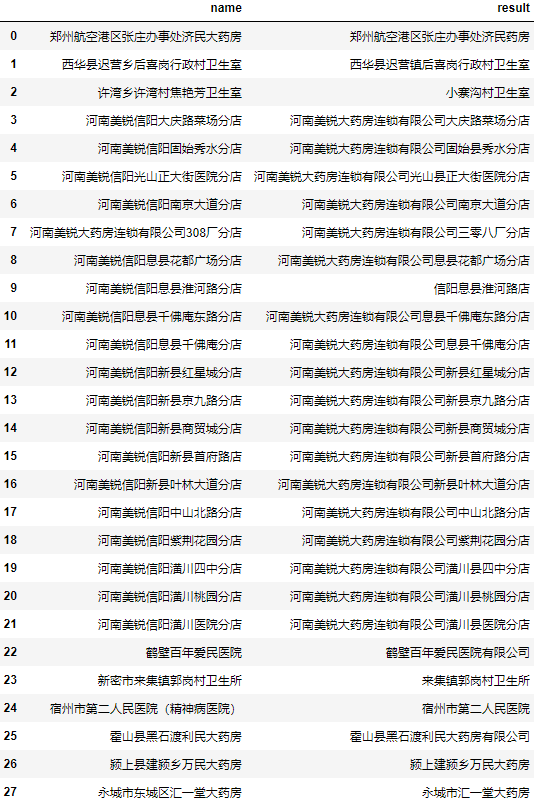
可以看到准确率相对前面自写的编辑距离算法有了大幅度提升,但个别名称匹配结果依然不佳。
查看这两个匹配不准确的地址:
| 1 | process.extract('许湾乡许湾村焦艳芳卫生室', users)
|
[('小寨沟村卫生室', 51),
('周口城乡一体化焦艳芳一体化卫生室', 50),
('西华县皮营乡楼陈村卫生室', 42),
('叶县邓李乡杜杨村第二卫生室', 40),
('汤阴县瓦岗乡龙虎村东卫生室', 40)]
| 1 | process.extract('河南美锐信阳息县淮河路分店', users)
|
[('信阳息县淮河路店', 79),
('河南美锐大药房连锁有限公司息县淮河路分店', 67),
('河南美锐大药房连锁有限公司息县大河文锦分店', 53),
('河南美锐大药房连锁有限公司息县千佛庵东路分店', 51),
('河南美锐大药房连锁有限公司息县包信分店', 50)]
对于这样的问题,个人并没有一个很完美的解决方案,个人建议是将相似度最高的n个名称都加入结果列表中,后期再人工筛选:
| 1 2 3 4 | result = find.name.apply(lambda x: next(zip(*process.extract(x, users, limit=3)))).apply(pd.Series)
result.rename(columns=lambda i: f"匹配{i+1}", inplace=True)
result = pd.concat([find.drop(columns="result"), result], axis=1)
result
|
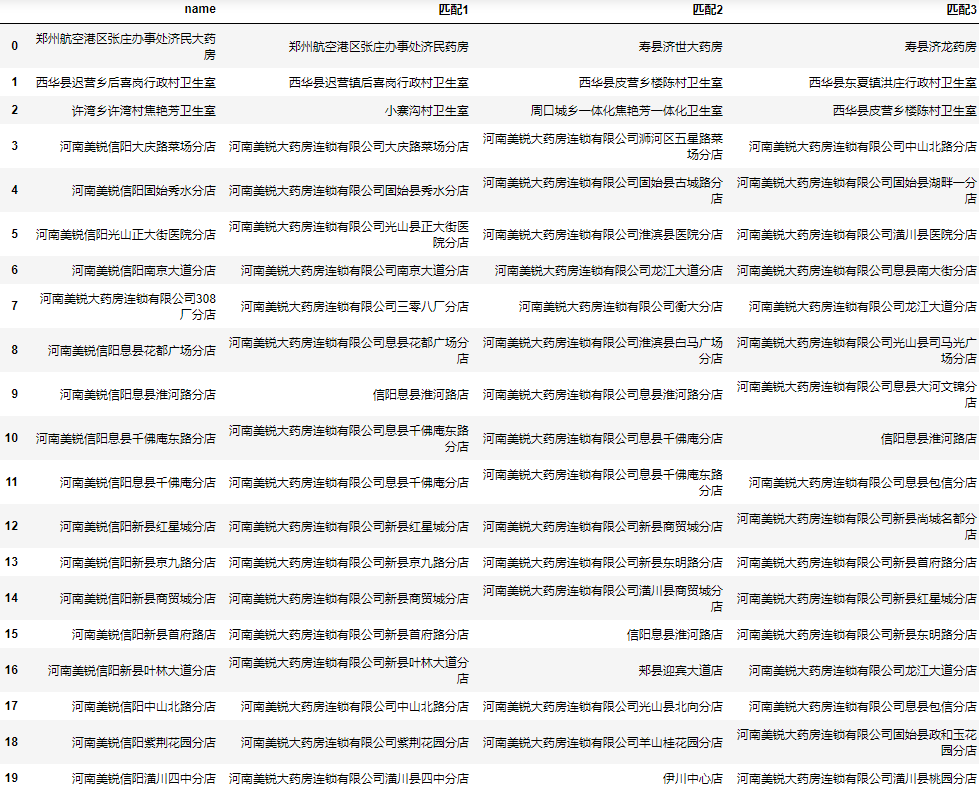
虽然可能有个别正确结果这5个都不是,但整体来说为人工筛查节省了大量时间。

整体代码
| 1 2 3 4 5 6 7 8 9 10 11 12 | from fuzzywuzzy import process
import pandas as pd
excel = pd.ExcelFile("所有客户.xlsx")
data = excel.parse(0)
find = excel.parse(1)
users = data.user.to_list()
result = find.name.apply(lambda x: next(
zip(*process.extract(x, users, limit=3)))).apply(pd.Series)
result.rename(columns=lambda i: f"匹配{i+1}", inplace=True)
result = pd.concat([find, result], axis=1)
result
|
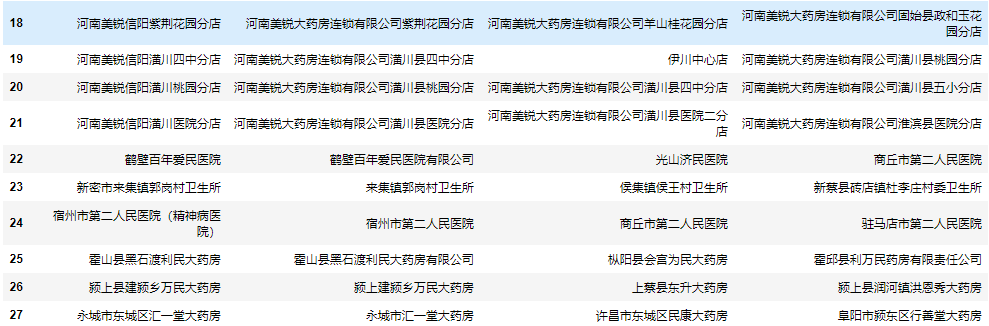
使用Gensim进行批量模糊匹配
Gensim简介
Gensim支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。
基本概念:
- 语料(Corpus):一组原始文本的集合,用于无监督地训练文本主题的隐层结构。语料中不需要人工标注的附加信息。在Gensim中,Corpus通常是一个可迭代的对象(比如列表)。每一次迭代返回一个可用于表达文本对象的稀疏向量。
- 向量(Vector):由一组文本特征构成的列表。是一段文本在Gensim中的内部表达。
- 稀疏向量(SparseVector):可以略去向量中多余的0元素。此时,向量中的每一个元素是一个(key, value)的元组
- 模型(Model):是一个抽象的术语。定义了两个向量空间的变换(即从文本的一种向量表达变换为另一种向量表达)。
安装:pip install gensim
官网:https://radimrehurek.com/gensim/
什么情况下需要使用NLP来进行批量模糊匹配呢?那就是数据库数据过于庞大时,例如达到几万级别:
| 1 2 3 4 5 6 7 8 | import pandas as pd
data = pd.read_csv("所有客户.csv", encoding="gbk")
find = pd.read_csv("被查找的客户.csv", encoding="gbk")
display(data.head())
print(data.shape)
display(find.head())
print(find.shape)
|

此时如果依然用编辑距离或fuzzywuzzy暴力遍历计算,预计1小时也无法计算出结果,但使用NLP神器Gensim仅需几秒钟,即可计算出结果。
使用词袋模型直接进行批量相似度匹配
首先,我们需要先对原始的文本进行分词,得到每一篇名称的特征列表:
| 1 2 3 4 | import jieba
data_split_word = data.user.apply(jieba.lcut)
data_split_word.head(10)
|
0 [珠海, 广药, 康鸣, 医药, 有限公司]
1 [深圳市, 宝安区, 中心医院]
2 [中山, 火炬, 开发区, 伴康, 药店]
3 [中山市, 同方, 医药, 有限公司]
4 [广州市, 天河区, 元岗金, 健民, 医药, 店]
5 [广州市, 天河区, 元岗居, 健堂, 药房]
6 [广州市, 天河区, 元岗润佰, 药店]
7 [广州市, 天河区, 元岗, 协心, 药房]
8 [广州市, 天河区, 元岗, 心怡, 药店]
9 [广州市, 天河区, 元岗永亨堂, 药店]
Name: user, dtype: object
接下来,建立语料特征的索引字典,并将文本特征的原始表达转化成词袋模型对应的稀疏向量的表达:
| 1 2 3 4 5 | from gensim import corpora
dictionary = corpora.Dictionary(data_split_word.values)
data_corpus = data_split_word.apply(dictionary.doc2bow)
data_corpus.head()
|
0 [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1)]
1 [(5, 1), (6, 1), (7, 1)]
2 [(8, 1), (9, 1), (10, 1), (11, 1), (12, 1)]
3 [(0, 1), (3, 1), (13, 1), (14, 1)]
4 [(0, 1), (15, 1), (16, 1), (17, 1), (18, 1), (...
Name: user, dtype: object
这样得到了每一个名称对应的稀疏向量(这里是bow向量),向量的每一个元素代表了一个词在这个名称中出现的次数。
至此我们就可以构建相似度矩阵:
| 1 2 3 | from gensim import similarities
index = similarities.SparseMatrixSimilarity(data_corpus.values, num_features=len(dictionary))
|
再对被查找的名称作相同的处理,即可进行相似度批量匹配:
| 1 2 3 4 | find_corpus = find.name.apply(jieba.lcut).apply(dictionary.doc2bow)
sim = index[find_corpus]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)
|
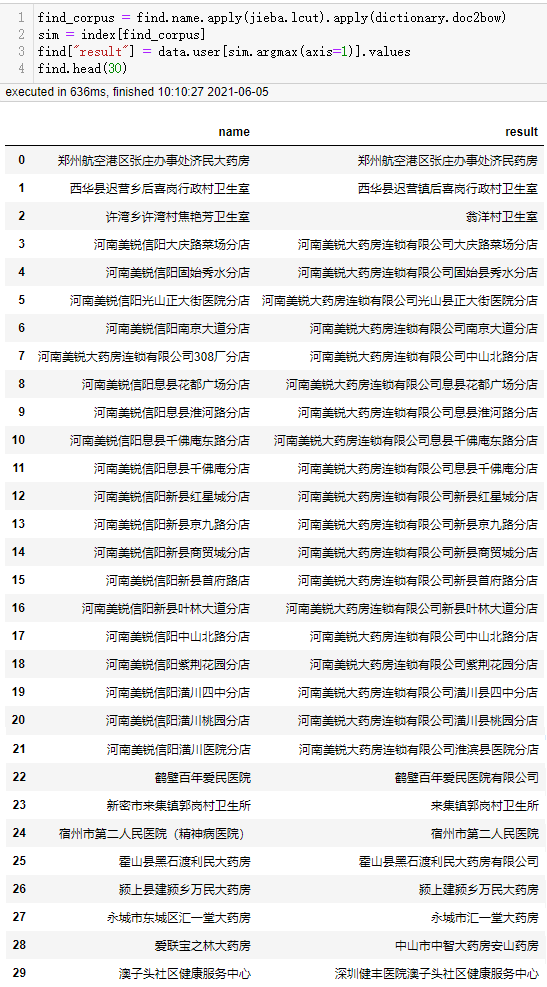
可以看到该模型计算速度非常快,准确率似乎整体上比fuzzywuzzy更高,但fuzzywuzzy对河南美锐大药房连锁有限公司308厂分店的匹配结果是正确的。
使用TF-IDF主题向量变换后进行批量相似度匹配
之前我们使用的Corpus都是词频向量的稀疏矩阵,现在将其转换为TF-IDF模型后再构建相似度矩阵:
| 1 2 3 4 5 | from gensim import models
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
|
被查找的名称也作相同的处理:
| 1 2 3 | sim = index[tfidf[find_corpus]]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)
|

可以看到许湾乡许湾村焦艳芳卫生室匹配正确了,但河南美锐信阳息县淮河路分店又匹配错误了,这是因为在TF-IDF模型中,由于美锐在很多条数据中都出现被降权。
假如只对数据库做TF-IDF转换,被查找的名称只使用词频向量,匹配效果又如何呢?
| 1 2 3 4 5 6 7 8 | from gensim import models
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
sim = index[find_corpus]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)
|

可以看到除了数据库本来不包含正确名称的爱联宝之林大药房外还剩下河南美锐大药房连锁有限公司308厂分店匹配不正确。这是因为不能识别出308的语义等于三零八。如果这类数据较多,我们可以先将被查找的数据统一由小写数字转换为大写数字(保持与数据库一致)后,再分词处理:
| 1 2 3 4 5 6 | trantab = str.maketrans("0123456789", "零一二三四五六七八九")
find_corpus = find.name.apply(lambda x: dictionary.doc2bow(jieba.lcut(x.translate(trantab))))
sim = index[find_corpus]
find["result"] = data.user[sim.argmax(axis=1)].values
find.head(30)
|
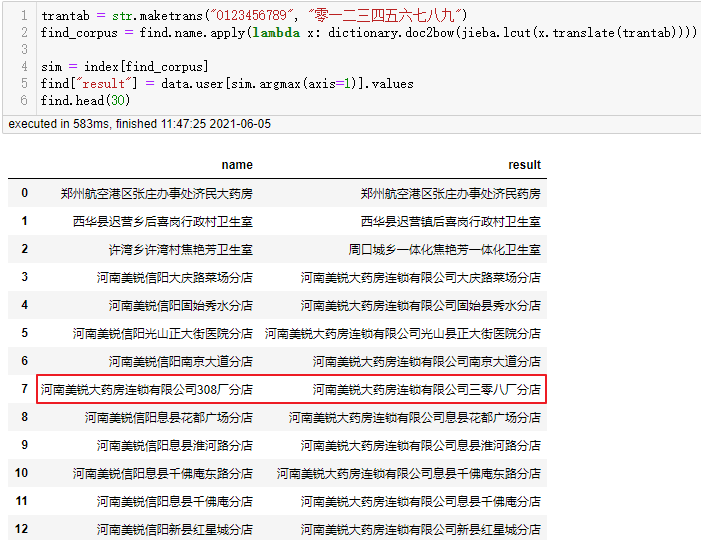
经过这样处理后,308厂分店也被正确匹配上了,其他类似的问题都可以使用该思路进行转换。
虽然经过上面的处理,匹配准确率几乎达到100%,但不代表其他类型的数据也会有如此高的准确率,还需根据数据的情况具体去分析转换。并没有一个很完美的批量模糊匹配的处理办法,对于这类问题,我们不能完全信任程序匹配的结果,都需要人工的二次检查,除非能够接受一定的错误率。
为了我们人工筛选的方便,我们可以将前N个相似度最高的数据都保存到结果中,这里我们以三个为例:
同时获取最大的3个结果
下面我们将相似度最高的3个值都添加到结果中:
| 1 2 3 4 5 6 7 8 | result = []
for corpus in find_corpus.values:
sim = pd.Series(index[corpus])
result.append(data.user[sim.nlargest(3).index].values)
result = pd.DataFrame(result)
result.rename(columns=lambda i: f"匹配{i+1}", inplace=True)
result = pd.concat([find.drop(columns="result"), result], axis=1)
result.head(30)
|
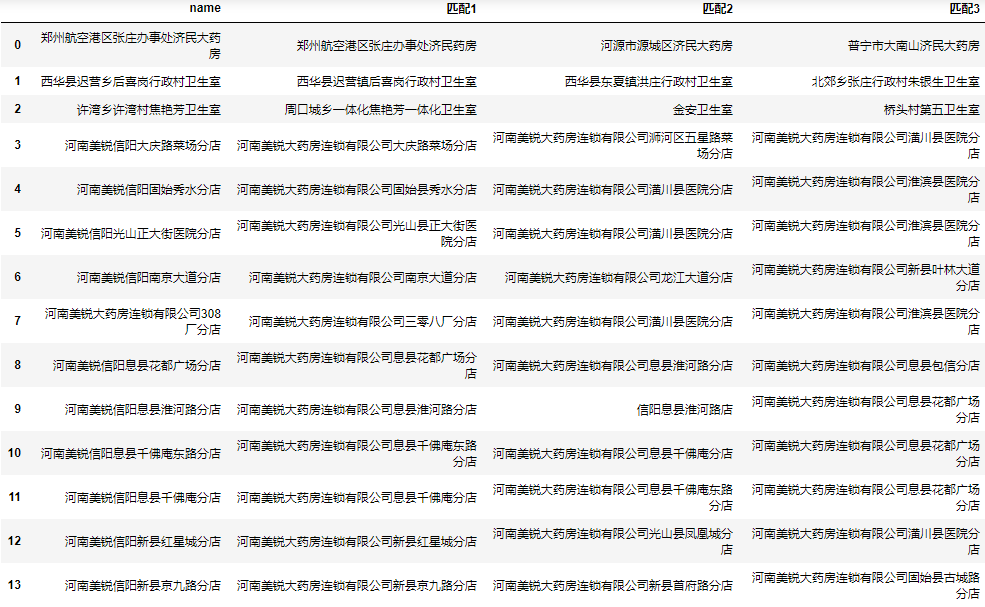
完整代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | from gensim import corpora, similarities, models
import jieba
import pandas as pd
data = pd.read_csv("所有客户.csv", encoding="gbk")
find = pd.read_csv("被查找的客户.csv", encoding="gbk")
data_split_word = data.user.apply(jieba.lcut)
dictionary = corpora.Dictionary(data_split_word.values)
data_corpus = data_split_word.apply(dictionary.doc2bow)
trantab = str.maketrans("0123456789", "零一二三四五六七八九")
find_corpus = find.name.apply(
lambda x: dictionary.doc2bow(jieba.lcut(x.translate(trantab))))
tfidf = models.TfidfModel(data_corpus.to_list())
index = similarities.SparseMatrixSimilarity(
tfidf[data_corpus], num_features=len(dictionary))
result = []
for corpus in find_corpus.values:
sim = pd.Series(index[corpus])
result.append(data.user[sim.nlargest(3).index].values)
result = pd.DataFrame(result)
result.rename(columns=lambda i: f"匹配{i+1}", inplace=True)
result = pd.concat([find, result], axis=1)
result.head(30)
|
总结
本文首先分享了编辑距离的概念,以及如何使用编辑距离进行相似度模糊匹配。然后介绍了基于该算法的轮子fuzzwuzzy,封装的较好,使用起来也很方便,但是当数据库量级达到万条以上时,效率极度下降,特别是数据量达到10万级别以上时,跑一整天也出不了结果。于是通过Gensim计算分词后对应的tf-idf向量来计算相似度,计算时间由几小时降低到几秒,而且准确率也有了较大提升,能应对大部分批量相似度模糊匹配问题。
到此这篇关于Python批量模糊匹配的3种方法的文章就介绍到这了,更多相关Python批量模糊匹配内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!