文献阅读-Deep multi-view learning methods: A review
- Abstract
- 1-Introduction
- 1.1 Comparison with Previous Reviews
- 2 Multi-view Learning Methods in The Deep Learning Scope
- 2.1 Multi-view convolutional neural network
- 2.2. Multi-view auto-encoder
- 2.3. Multi-view generative adversarial networks
- 2.4. Multi-view graph neural networks
- 2.5. Multi-view deep belief net
- 2.6. Multi-view recurrent neural network
本文主要解释 -深度学习范围内的MVL-方法,并讨论 多视图与多模态 之间的关系。
Abstract
多视图学习 (MVL) 吸引了越来越多的关注,并通过利用多种特征或模态的互补信息取得了巨大的实际成功。最近,由于深度模型的卓越性能,深度 MVL 已在机器学习、人工智能和计算机视觉等许多领域得到采用。本文从以下两个角度全面回顾了深度 MVL:深度学习范围内的 MVL 方法和传统方法的深度 MVL 扩展。具体来说,我们首先回顾了深度学习范围内具有代表性的 MVL 方法,例如多视图自动编码器、传统神经网络和深度简短网络。
然后,我们研究了当传统学习方法遇到深度学习模型时 MVL 机制的进步,例如深度多视图典型相关分析、矩阵分解和信息瓶颈。此外,我们还总结了深度 MVL 领域的主要应用、广泛使用的数据集和性能比较。最后,我们试图确定一些开放的挑战,为未来的研究方向提供信息
1-Introduction
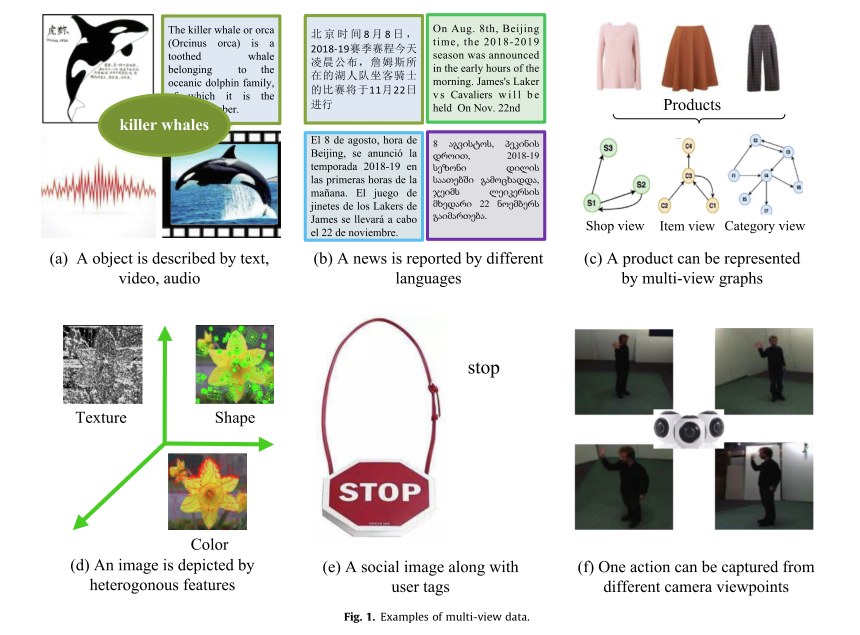
近几十年来,多视图数据已成为互联网上的主要数据类型之一,其数量在视频监控[1-3]、娱乐媒体[4-6]、社交网络[7]和医学检测[8,9]等。基本上,多视图数据是指从不同模态、来源、空间和其他形式捕获的数据,但具有相似的高级语义。如图1所示,一个对象可以用文本、视频、音频的形式来描述;通常用不同的语言报告一个事件;一个产品可以用多个图表示;一个逼真的图像可以用不同的视觉特征来描述;社交图像包含视觉信息和用户标签;不同的相机可以从不同的角度捕捉特定的人类动作。尽管这些视图通常代表同一数据的不同且互补的信息,但由于多个视图之间的偏差,将它们直接集成在一起并不能获得始终如一的令人满意的性能。因此,如何正确整合多个视图是一个中心问题,这也是多视图学习的目标。
多视图学习 (MVL) 旨在通过组合多个不同的特征或数据源来学习共同的特征空间或共享模式 [10]。在过去的几十年中,MVL 在机器学习和计算机视觉社区 [11-15] 中获得了巨大的发展势头,并启发了许多有前途的算法,例如协同训练机制 [16]、子空间学习方法 [17] 和多核学习(MKL)[ 18]。最流行的 MVL 方法之一是将多视图数据映射到一个公共特征空间,最大限度地提高多个视图的相互一致性 [19-22,7]。在这个研究方向中,较早且具有代表性的是典型相关分析(CCA)[11],它是一种搜索两个特征向量的线性映射的统计方法。之后,CCA 的各种扩展一直致力于学习多模态或视图的共享低维特征空间,例如内核 CCA [23,24]、共享内核信息嵌入 [18,25]。除了CCA,MVL的思想已经渗透到多种学习方法中[10,26-28],例如降维[13]、聚类分析[29]和集成学习[30]。尽管上述这些方法取得了可喜的结果,但它们使用手工制作的特征和线性嵌入函数,无法捕捉复杂多视图数据的非线性特性。
非线性是一个数学术语,描述了自变量和因变量之间不存在直线或直接关系的情况。在非线性关系中,输出的变化不与任何变化成正比输入的。在检查学习模型的输入和输出之间的关系时,非线性是一个常见问题。在机器学习和计算机视觉领域,存在各种类型的非线性数据,例如文本、图像、视频和音频。随着信息技术的快速发展,现实世界的应用中每天都会产生大量具有非线性特性的多视图数据,如图 1 所示。多视图数据的这种线性特性使得多视图上的学习任务成为可能。数据仍然具有挑战性.
近年来,由于强大的特征抽象能力,深度学习方法[31]以优异的性能广泛应用于计算机视觉[20,32-34]和人工智能[19,35,36,22]等许多应用领域。深度学习方法可以通过允许多个分层来有效地学习目标数据的复杂、微妙、非线性和抽象表示。随着深度学习在许多应用领域的成功,深度 MVL 方法也被越来越多地利用并取得了可喜的成果 [35,19,32,36,33,34,20,22]。
鉴于近年来提出的大量基于深度学习的 MVL 方法,我们试图对这些工作进行全面回顾并提出我们的分析。如图 2 所示,我们首先回顾了本文深度学习范围内的代表性 MVL 方法,例如多视图自动编码器 (AE)、传统神经网络 (CNN) 和深度简短网络 (DBN)。然后,我们研究了当传统学习方法遇到深度学习模型时 MVL 机制的进步,例如深度多视图典型相关分析 (CCA)、矩阵分解 (MF) 和信息瓶颈 (IB).最后,我们回顾了深度 MVL 方法的几个重要应用、广泛使用的数据集和未解决的问题,以进行进一步的研究和探索。
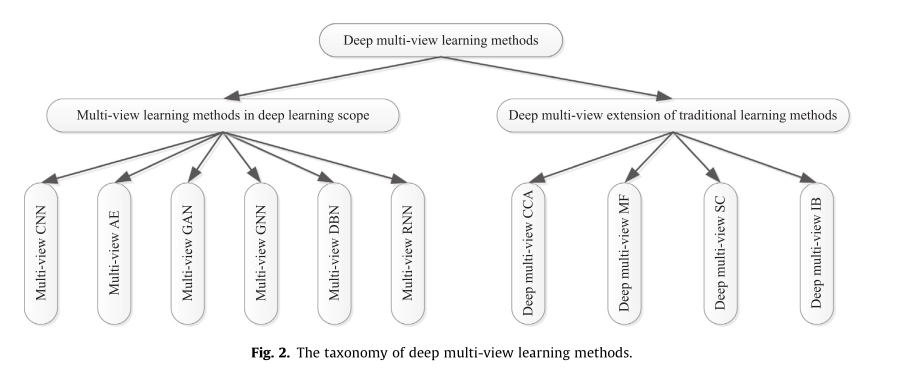
作者将多视图深度学习分为CNN,AE,GAN,GNN,DBN,RNN
1.1 Comparison with Previous Reviews
最近,一些关于 MVL 的重要相关调查已经发表,总结了现有 MVL 方法的理论、方法、分类和应用 [10,26–28,37–40]。这些调查侧重于特定 MVL 方法的问题,例如多视图融合 [10,27,28]、多模态学习 [37,38]、多视图聚类 [26] 和多视图表示学习 [39] ,40]。
与以往的调查相比,本文侧重于从深度学习和 MVL 的交叉角度回顾文献,因为很少有调查直接总结深度 MVL 方法。特别是,[10,26–28] 中的调查侧重于传统学习方法领域中的 MVL 方法。
例如,Baltrusaitis 等人 [38] 和 Li 等人 [39] 总结了具有代表性的多视图特征学习方法的浅层学习模型,其中基于深度学习的 MVL 方法在他们的研究中被忽略或仅总结了一小部分。相比之下,我们强调了近年来受到更多关注的深度 MVL 方法。从深度模型的角度来看,与本文最相关的工作是 [37,40]。然而,他们都专注于多模态表示融合的模型和应用。我们的审查与上述两个审查之间的主要区别总结为以下两个方面。首先,这篇评论涉及 MVL 的更多方面,而其他两个评论则侧重于多视图特征学习。其次,我们还回顾了传统方法的深度多视图扩展,如深度多视图 MF、深度多视图光谱学习和深度多视图 IB,这些方法从未被调查过。
本文组织如下。在第 2 节中,介绍了深度学习范围内的 MVL 方法,例如多视图自动编码器、自动编码器和传统神经网络。在第 3 节中,介绍了当传统学习方法遇到深度学习模型时 MVL 机制的进步,例如深度多视图矩阵分解和深度多视图信息瓶颈。在第 4 节中,我们介绍了 MVL 在不同领域中的几个有趣应用。在第 5 节中,总结了 MVL 领域中几个广泛使用的数据集。在第 6 节中,比较了具有代表性的深度 MVL 方法的性能。最后,第 6 节提供了深度 MVL 研究中的几个开放问题,我们旨在帮助推进深度 MVL 的发展。
2 Multi-view Learning Methods in The Deep Learning Scope
2.1 Multi-view convolutional neural network
作为一种典型的深度学习算法,卷积神经网络 (CNN) [31] 旨在学习具有各种参数优化的高级特征表示 [41-43],并在各个领域展示了卓越的性能 [44,45]。与单视图 CNN 架构相比,多视图 CNN 被定义为从多个特征集建模,可以访问目标数据的多视图信息,例如 3D 形状识别 [46]、多元脑电图 (EEG) [47] ,多特征聚合[48]。多视图 CNN 架构旨在整合来自不同视图的多视图信息,以获得更具辨别力的通用表示。现有的多视图 CNN 架构通常分为以下两种类型:单视图一网络机制和多视图一网络机制,如图 3 所示。
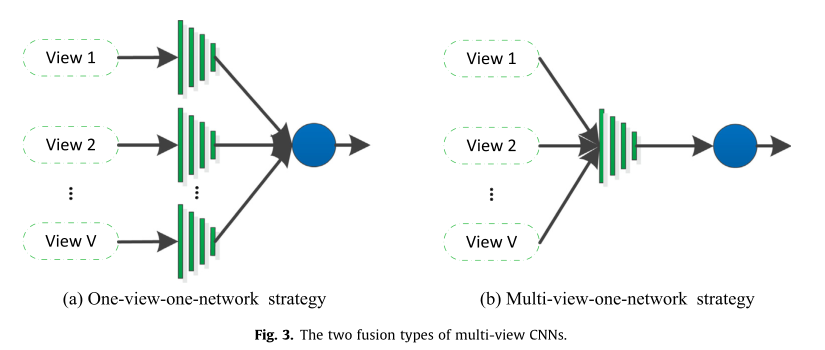
基于单视图一网络机制的多视图 CNN 对每个视图采用一个卷积神经网络,并分别提取每个视图的特征表示,然后通过网络的后续部分融合多个表示 [49–52,2, 53,46–48]。以 3D 形状识别为例,Yang 等人 [46] 提出了一种多视图 CNN 方法,用于 3Dimensional (3D) 模型的综合特征提取和聚合。正如我们从图 4 中看到的,给定一个 3D 模型,它首先被转换为生成 N 个图像的 N 个视图。然后,将这些图像放入 N 个 CNN 架构中,以获得每个视图的特征表示。这些特定于视图的特征被集成并传递到以下特征聚合模型中,以获得紧凑的、有判别力的形状特征。对于one-view-one-network策略,还有许多其他的努力来设计多视图CNN架构并探索它们的应用。例如,Feichtenhofer 等人 [2] 探索了几种结合 CNN 特征以全面提取人类活动时空特征的机制。
Multi-view-one-net 机制将多视图数据馈送到同一网络以获得最终表示。例如,Dou 等人 [54] 提出了一种通过结合多层次信息进行肺结节检测的上下文 3D CNN。该网络包括 3D 卷积层、3D 最大池化层和全连接层,用于分层提取最终特征表示。
本质上,one-view-one-net机制和multi-view-one-net机制的区别在于不同视图的融合方式。同样以3D形状识别为例,设
x
t
a
∈
R
H
∗
W
∗
D
x^a_t \in R^{H*W*D}
xta∈RH∗W∗D和
x
t
b
∈
R
H
∗
W
∗
D
x^b_t \in R^{H*W*D}
xtb∈RH∗W∗D表示融合层的两个输入数据,y表示融合层的输出结果,其中H;W;D 是当前层的维度。表 1 总结了两种不同的融合类型。

2.2. Multi-view auto-encoder
自动编码器 (AE) 是神经网络的一种变体,在数据检索 [35]、人体姿势恢复 [55] 和疾病分析 [56] 等病毒应用中取得了可喜的成果。 AEs是深度学习文献中的无监督特征学习方法,由两个目标函数组成:编码函数f()和解码函数g()。具体来说,编码函数旨在将输入数据
X
∈
R
D
1
X \in R^{D_1}
X∈RD1 映射到压缩隐藏表示
V
∈
R
D
2
V \in R^{D_2}
V∈RD2;
V
≈
f
(
X
)
V \approx f(X)
V≈f(X) ,其中 D1 和 D2 是原始数据及其压缩表示的维度。解码函数 g(x) 旨在从其压缩的隐藏表示中重建数据 X,使得
g
(
V
)
≈
X
g(V) \approx X
g(V)≈X. AE架构的超参数是通过重建的最小化误差
L
(
X
,
g
(
V
)
)
L(X,g(V))
L(X,g(V))得到的;可以通过一些损失来衡量,比如平方损失。例如AE的cost function用square loss作为reconstruction error制定如下:
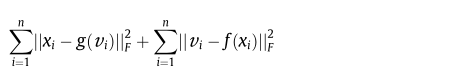
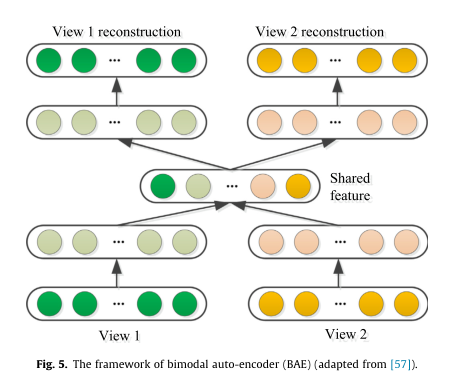
最近提出了一些工作来通过使用 AE 来学习多视图数据的通用表示。例如,Ngiam 等人 [57] 设计了一种新颖的双峰自动编码器(BAE),如图 5 所示。BAE 旨在找到音频和视频,通过最小化两个输入视图和重建表示的重建误差。
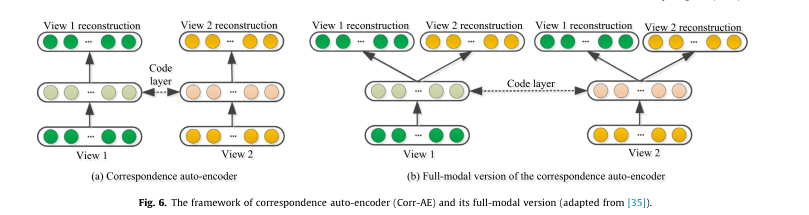
受 BAE 的启发,Feng 等人 [35] 提出了一种对应自动编码器(Corr-AE)来进行跨模态检索,它同时学习多种模态的共享信息和每个模态中的特定信息。 Corr-AE 的主要思想是最小化多个模态之间的相关学习误差和每个模态的特征学习误差。如图 6 所示,所提出的 Corr-AE 模型由以下两个子网络组成,每个子网络都是一个基本的自动编码器。这两个子网络通过设计一个具有预定义相似性度量的代码层来组合。 Feng 等人 [35] 还提出了 Corr-AE 的全模态版本,它可以看作是标准自动编码器和 Corr-AE 的集成,如图 6 所示。(b)
因此,Zhang 等人 [59] 在自动编码器网络 (AE2-Nets) 中提出了一种自动编码器,它专注于无监督表示学习的任务。 AE2-Nets 旨在自动将异构视图映射到通用表示,同时自适应地平衡多个视图之间的一致性和互补性。 AE2-Nets采用内部自动编码器网络从每个单视图中提取信息,并采用外部自动编码器网络对多视图信息进行编码。
最近,针对各种任务提出了 AE 架构的多视图扩展,例如 3D 重建 [60,19]、异常检测 [3,61]、医学数据分析 [56,32]、注释 [62,63] 和人体姿势恢复[55]。 Yang 等人 [60] 提出了一种具有注意力聚合模型的多视图 3D 重建方法,该方法融合了从不同视点记录的图像集合中编码的多个深度特征。巴特等人[19] 提出了一种基于集合的深度跨模态自动编码器(CMAE),它在获得另一个视图的情况下重建数据的一个视图,而每个中间步骤或每个隐藏层的表示之间的交互是增加。 Deepak 等人 [3] 提出通过时空自动编码器学习用于多视图视频异常检测的深度特征,它将手工制作的特征和来自时空自动编码器的深度特征与原始输入视频相结合。 Zhang 等人 [56] 提出了一种边缘敏感自动编码器 (MSAE) 方法来识别蛋白质折叠和阿尔茨海默病。在 MASE 中,编码器用于将多视图生理信号映射到公共共享子空间,而解码器架构用作重建的限制。此外,MASE 使用自调整方案来自适应地加权不同视图的重要性。 Wei 等人 [32] 提出了一种用于磁共振 (MR) 图像分割的多视图深度神经网络 (DNN),它使用卷积自动编码器来恢复 MR 切片。Hong 等人 [55] 提出了一种用于多模态人体姿势恢复的深度自动编码器架构,其中包括 2D 和 3D 特征学习部分。
2.3. Multi-view generative adversarial networks
作为一种无监督的深度学习模型,==生成对抗网络 (GAN) [64] ==已成功应用于许多领域并取得了可喜的成果,例如图像到图像的转换 [65] 和图像修复 [66]。通常,基本的 GAN 包括一个生成模型 G 和一个判别模型 D,因此,它具有最突出的对抗训练特征。生成模型 G 表征源数据的分布,而判别模型 D 旨在从训练数据中估计概率分布。
在本节中,我们使用变量 x 表示训练图像,并使用变量 z 表示先验噪声。在 GAN 的设置中,我们将先验噪声 z 作为 G 的输入,而将假图像 G(z) 作为 G 的输出。生成器的过程可以表述为一个函数 G(z;hg); 其中hg为G的参数。同理,D的输入输出为x和单标量D(x;hd);分别为其中的Dðx; hdÞ 是 x 属于训练数据的概率。 GAN的最终目标是得到如下参数:

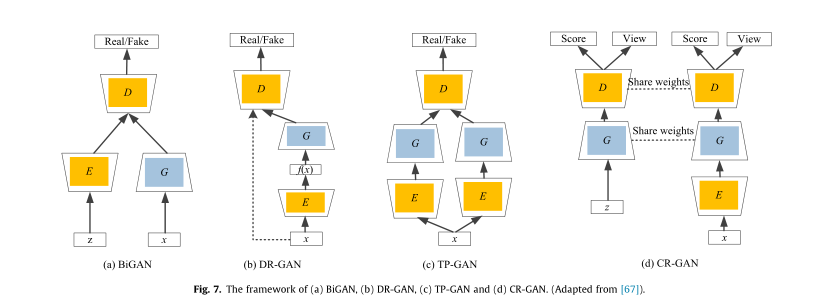
从单一视图输入生成具有多个视图的图像是计算机视觉、机器人和图形学广泛应用的基础研究课题。而广泛使用的 GAN 由于其对抗训练的特点,已经显示出令人印象深刻的结果 [36,33,68,67]。基于 GAN 的多视图生成方法首先使用编码器 E 将输入图像映射到潜在空间 Z,然后采用解码器 G 生成新视图。然而,单路径 GAN 可能学习到不完整的表示。为了为多视图生成生成完整的表示,已经付出了巨大的努力。多纳休等
[36] 提出双向 GAN(BiGAN)来联合学习推理网络 E 和生成器 G。换句话说,BiGAN 提供了一种学习将数据投影回潜在空间的逆映射的方法。 Tran 等人 [33] 提出了一种 DR-GAN 方法,该方法也旨在通过学习身份保留表示来合成多视图图像。在 DR-GAN 中,其编码器的输出同时充当解码器的输入,因此无法处理新数据。之后,Huang et al [68] 提出使用双通路 GAN 进行前视图合成,其中这两个通路采用两个不同的编码器解码器网络,这两个通路捕获全局特征和局部细节。 Tian 等人 [67] 提出了一种双路径 GAN 来保持学习嵌入空间的完整性。这两种学习途径以参数共享的方式协作和竞争,显着提高了对未见数据集的泛化能力。这些基于 GAN 的多视图生成之间的差异如图 7 所示。
除了多视图生成,GAN 还被应用于许多其他多视图应用程序。例如,Wang 等人 [69] 提出了一种对抗性相关自动编码器(ACAE)来获得多视图数据的共享特征空间,应用于跨视图检索和分类。 Xuan 等人 [70] 专注于多视图珍珠分类,因此提出了一种多视图 GAN 来扩展标记的珍珠图像,用于训练多流 CNN。
Sun 等人 [71] 提出了一种基于 GAN 的多视图嵌入网络,它同时保留来自单个网络视图的信息并考虑不同视图之间的连接性。 Chen 等人 [72] 提出了 BiGAN 的多视图扩展来进行多视图源数据的密度估计。
2.4. Multi-view graph neural networks
2.5. Multi-view deep belief net
2.6. Multi-view recurrent neural network
后面三种待完结!
有兴趣的可以直接看原论文!