1 体验1:Hive使用起来和Mysql差不多吗?
1.1 背景
对于初次接触Apache Hive的人来说,最大的疑惑就是:Hive从数据模型看起来和关系型数据库mysql等好像。包括Hive SQL也是一种类SQL语言。那么实际使用起来如何?
1.2 过程
体验步骤:按照mysql的思维,在hive中创建、切换数据库,创建表并执行插入数据操作,最后查询是否插入成功。
create database handsome;--创建数据库
show databases;--列出所有数据库
use handsome;--切换数据库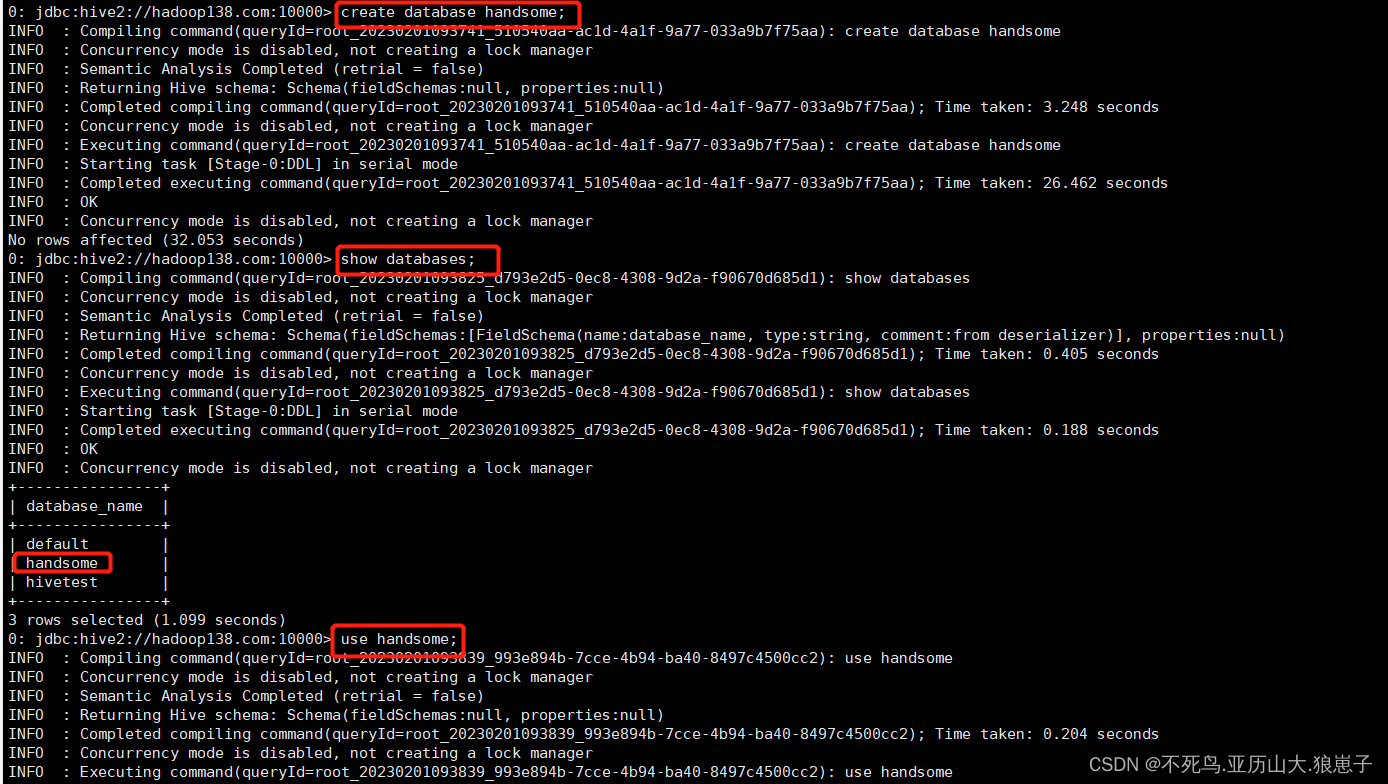
--建表
create table t_student(id int,name varchar(255));
--插入一条数据
insert into table t_student values(1,"allen");
--查询表数据
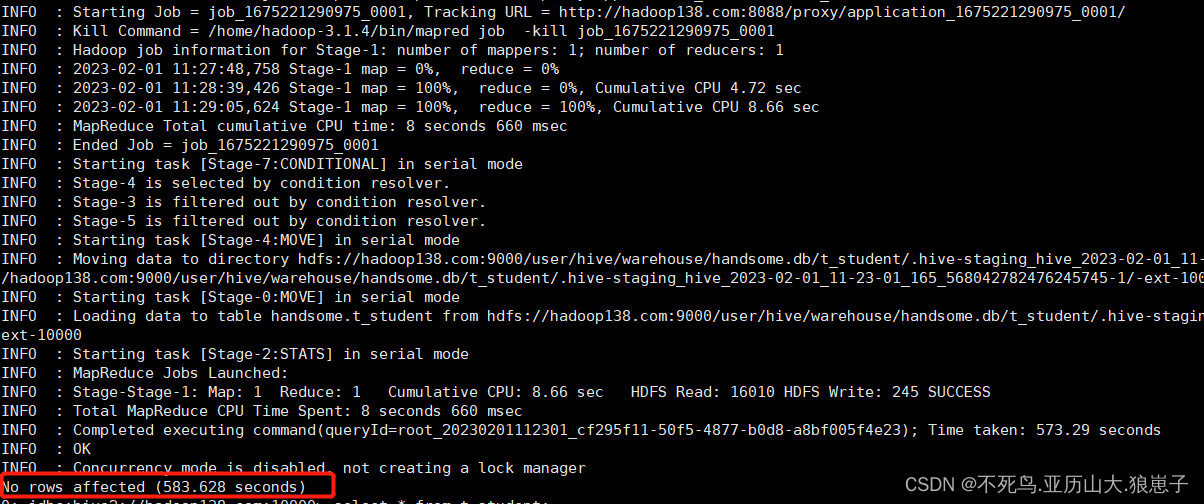
select * from t_student;执行完insert会发现执行时间很长,效率很低。
1.3 验证
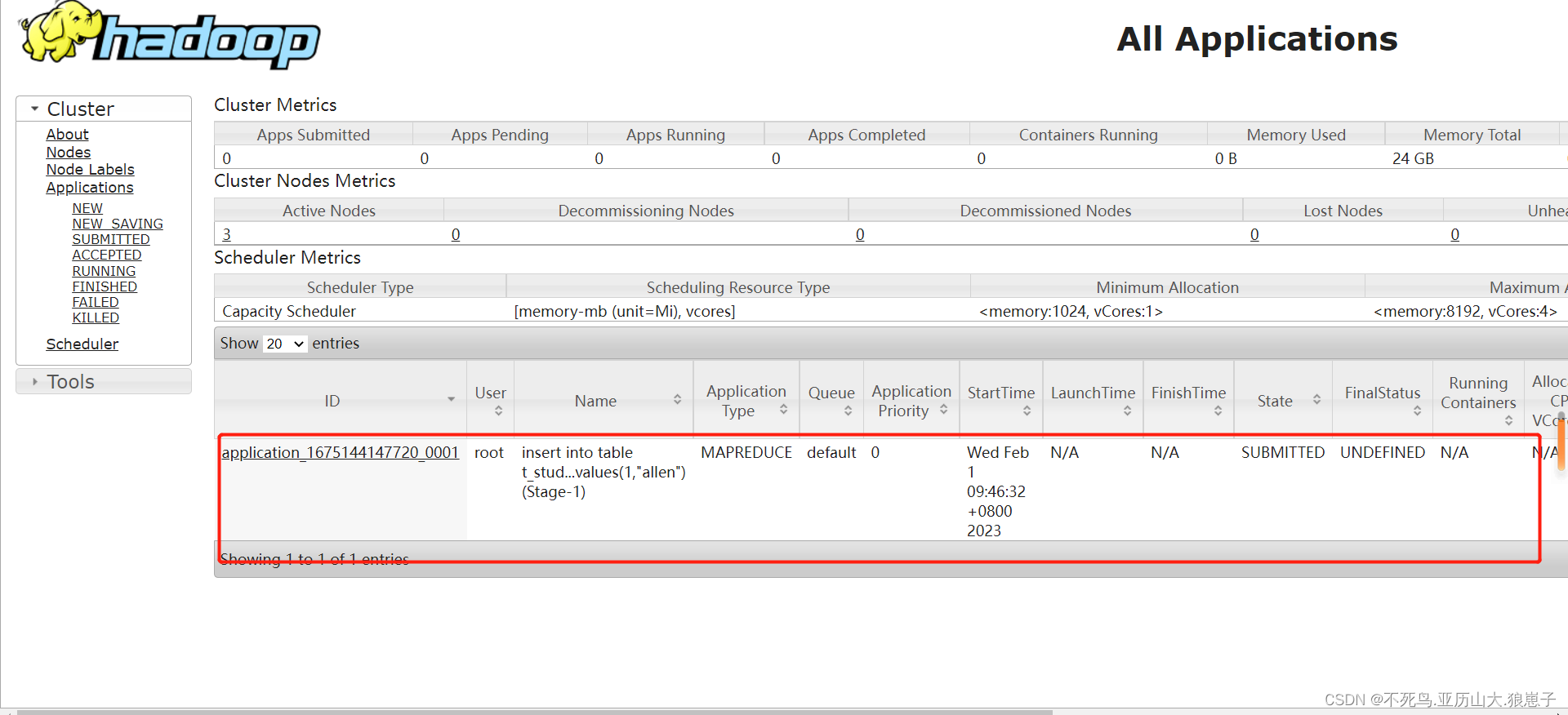
首先登陆Hadoop YARN上观察是否有MapReduce任务执行痕迹。
YARN Web UI: http://resourcemanager_host:8088/
然后登陆Hadoop HDFS浏览文件系统,根据Hive的数据模型,表的数据最终是存储在HDFS和表对应的文件夹下的。
HDFS Web UI: http://namenode_host:9870/

1.4 结论
- Hive SQL语法和标准SQL很类似,使得学习成本降低不少。
- Hive底层是通过MapReduce执行的数据插入动作,所以速度慢。
- 如果大数据集这么一条一条插入的话是非常不现实的,成本极高。
- Hive应该具有自己特有的数据插入表方式,结构化文件映射成为表。
2 体验2:如何才能将结构化数据映射成为表?
2.1 背景
在Hive中,使用insert+values语句插入数据,底层是通过MapReduce执行的,效率十分低下。此时回到Hive的本质上:可以将结构化的数据文件映射成为一张表,并提供基于表的SQL查询分析。
假如,现在有一份结构化的数据文件,如何才能映射成功呢?在映射成功的过程中需要注意哪些问题?不妨猜想文件的存储路径?字段类型?字段顺序?字段之间的分隔符问题?
2.2 过程
在HDFS根目录下创建一个结构化数据文件user.txt,里面内容如下
vim user.txt1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijinghadoop fs -put user.txt /在hive中创建一张表t_user。注意:字段的类型顺序要和文件中字段保持一致。
create table t_user(id int,name varchar(255),age int,city varchar(255));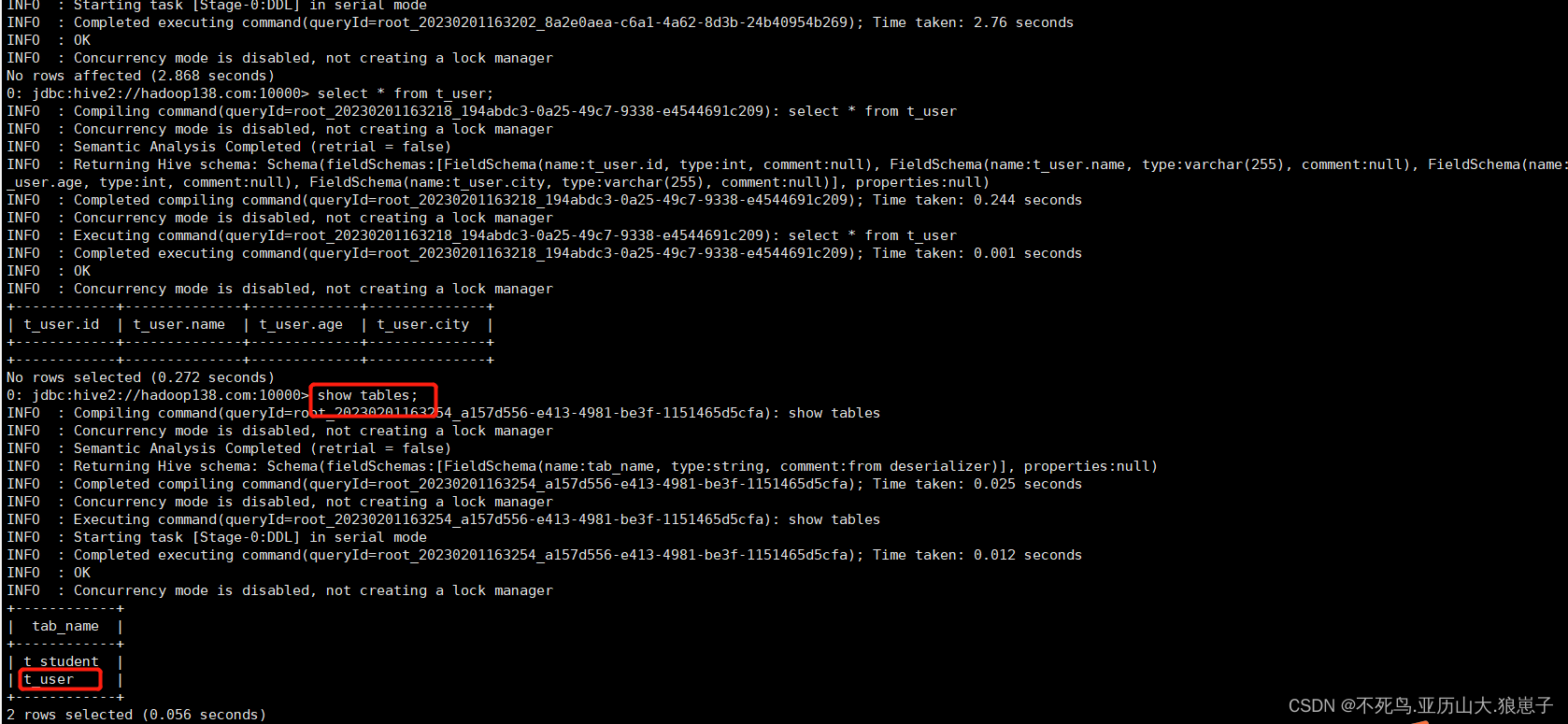
2.3 验证
执行数据查询操作,发现表中并没有数据。
猜想:难道数据文件要放置在表对应的HDFS路径下才可以成功?

hadoop fs -mv /user.txt /user/hive/warehouse/handsome.db/t_user

再次执行查询操作,显示如下,都是null:
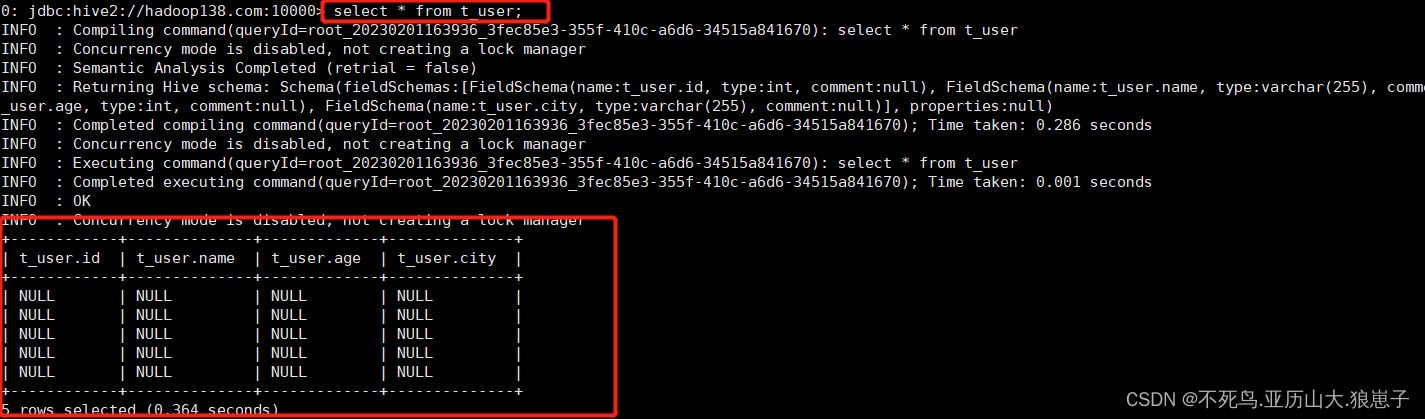
表感知到结构化文件的存在,但是并没有正确识别文件中的数据。猜想:还需要指定文件中字段之间的分隔符?重建张新表,指定分隔符。
建表语句 增加分隔符指定语句
--建表语句 增加分隔符指定语句
create table t_user_1(id int,name varchar(255),age int,city varchar(255))
row format delimited fields terminated by ',';把user.txt文件从本地文件系统上传到hdfs
hadoop fs -put user.txt /user/hive/warehouse/handsome.db/t_user_1执行查询操作
select * from t_user_1;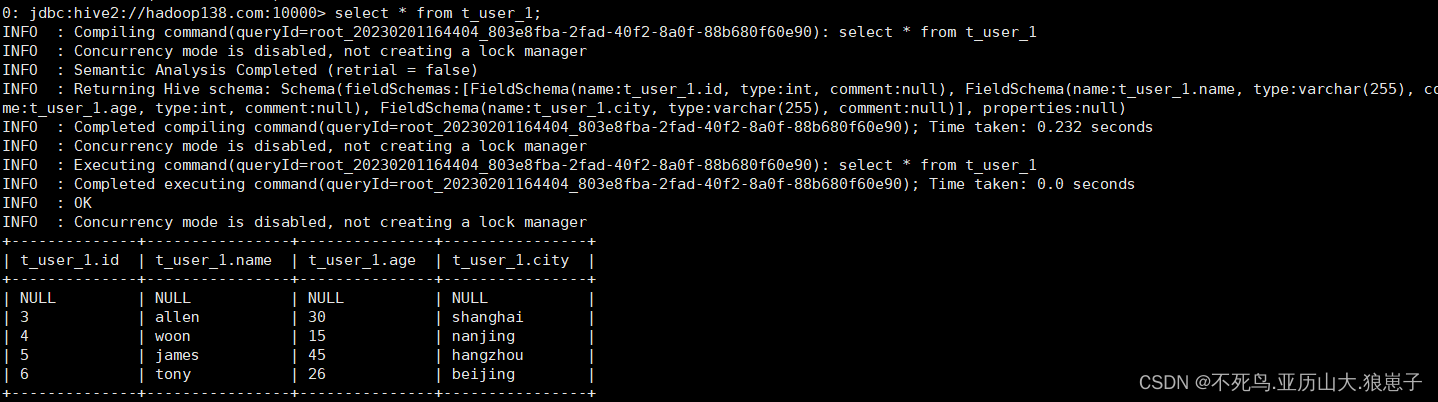
此时再创建一张表,保存分隔符语法,但是故意使得字段类型和文件中不一致。
--建表语句 增加分隔符指定语句
create table t_user_2(id int,name int,age varchar(255),city varchar(255))
row format delimited fields terminated by ',';
#把user.txt文件从本地文件系统上传到hdfs
hadoop fs -put user.txt /user/hive/warehouse/itcast.db/t_user_2/
--执行查询操作
select * from t_user_2;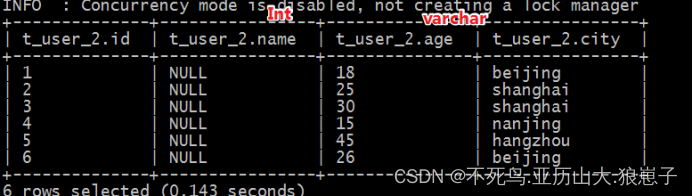
此时发现,有的列显示null,有的列显示正常。
name字段本身是字符串,但是建表的时候指定int,类型转换不成功;age是数值类型,建表指定字符串类型,可以转换成功。说明hive中具有自带的类型转换功能,但是不一定保证转换成功。
2.4 结论
要想在hive中创建表跟结构化文件映射成功,需要注意以下几个方面问题:
- 创建表时,字段顺序、字段类型要和文件中保持一致。
- 如果类型不一致,hive会尝试转换,但是不保证转换成功。不成功显示null。
- 文件好像要放置在Hive表对应的HDFS目录下,其他路径可以吗?
- 建表的时候好像要根据文件内容指定分隔符,不指定可以吗?
3 体验3:使用hive进行小数据分析如何?
3.1 背景
因为Hive是基于HDFS进行文件的存储,所以理论上能够支持的数据存储规模很大,天生适合大数据分析。假如Hive中的数据是小数据,再使用Hive开展分析效率如何呢?
3.2 过程
之前我们创建好了一张表t_user_1,现在通过Hive SQL找出当中年龄大于20岁的有几个。

3.3 验证
select count(*) from t_user_1 where age > 20;发现又是通过MapReduce程序执行的数据查询功能。
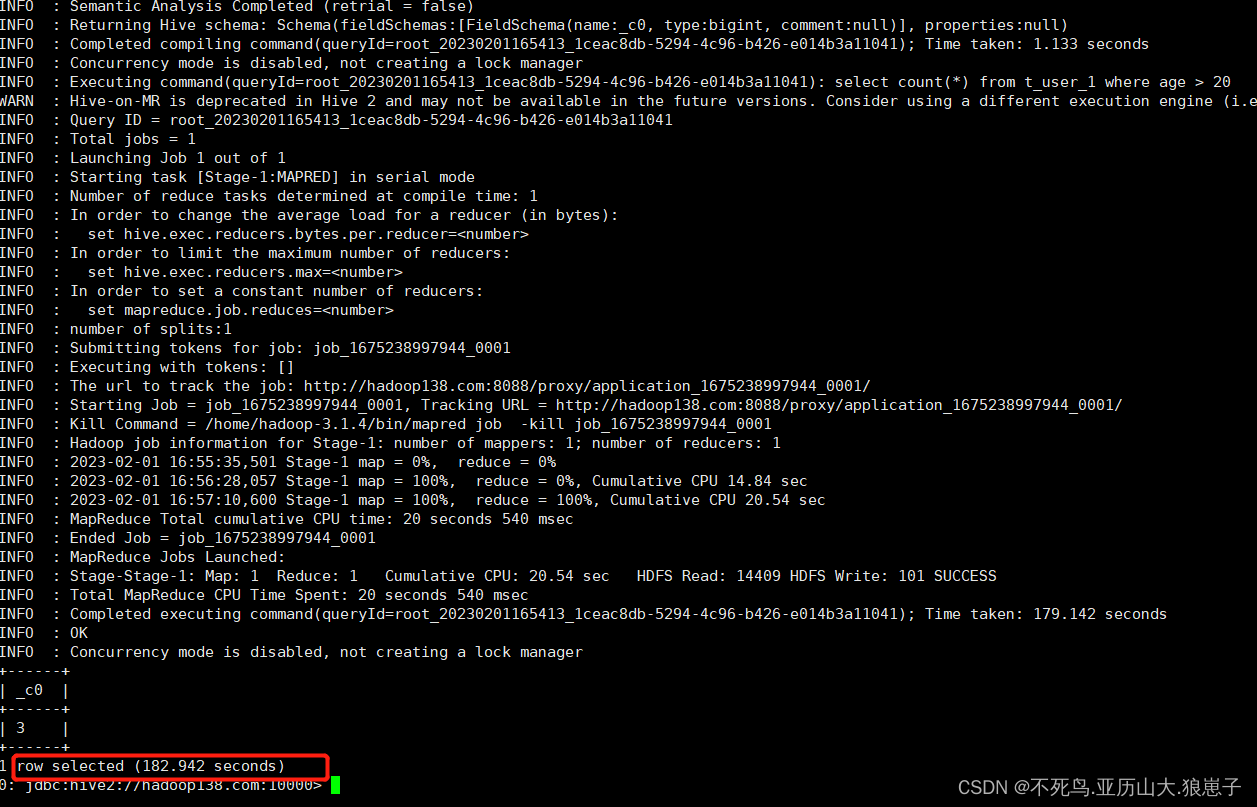
执行时间很长。
3.4 结论
- Hive底层的确是通过MapReduce执行引擎来处理数据的
- 执行完一个MapReduce程序需要的时间不短
- 如果是小数据集,使用hive进行分析将得不偿失,延迟很高
- 如果是大数据集,使用hive进行分析,底层MapReduce分布式计算,很爽