目录
前言
目的
思路
代码实现
1. 先将下载单个视频的功能封装成函数
2. 获取下载列表
3. 创建线程池调用下载函数
完整源码
运行效果
总结
前言
上一节我们实现了某短视频平台的去水印下载功能,本节我们实现批量抓取:给定某一个用户主页,抓取他的全部视频。
目的
基于多线程实现高效批量抓取任意主页的全部视频
思路
1. 我们实际上已经实现了单个视频的无水印下载,那么我们只需要从主页获得大量的视频链接即可
2. 访问用户主页,审查元素,找到视频列表,获取大量链接
3. 创建线程池,将视频链接放入单个视频下载的函数批量执行
代码实现
1. 先将下载单个视频的功能封装成函数
def grab_single_video(link):
url = f'{link}'
headers = {
'cookie': 'douyin.com; __ac_nonce=063d749310021f8bd394b; __ac_signature=_02B4Z6wo00f01R8urHgAAIDBnyxWOmwmfMUfDqjAACQfd6; ttwid=1%7CtRZY98IpvYfhjM-VRDQHgX3mgPcfWwWxylxnwwC7fFk%7C0%7C9af2c384c7d2b4e10ec0497fce797af996c72dd3868ec040595de36132c01ad0; home_can_add_dy_2_desktop=%220%22; passport_csrf_token=ee0cbadbf97ac430daac207c46997ca1; passport_csrf_token_default=ee0cbadbf97ac430daac207c46997ca1; strategyABtestKey=%221675053365.079%22; s_v_web_id=verify_ldibiwgl_ycqaypzT_aJxd_4ZEW_9iGD_XkAPFGlhzwd3; AB_LOGIN_GUIDE_TIMESTAMP=%221675053363589%22; msToken=L3xfxnCP4kW9_qabjW3S1cud_5DmI99tIEOw1_lJDMgdp1GJ9KQd6HWXKepYY-7iLlj4SR_V02zL3lYO6FVnXoPPVNneC5bD9cEnYN4nNpXzaNmvq7oA; ttcid=a598309ef5f3442b95f1d979574083f925; tt_scid=Px0Q21O38QIdeziR7nBXUqfZYJaS4qKakt5Zkfio72r9U4XaJdOYTb37LsjIrRLQca96; msToken=xibNm7RgEpzX8c6UaAgkzAOHMr5TcWNmNbfFR1vD-3uNUhtRXEqVQrmPIV6iDsnsA3WhMCTIOGDtST_F9GEyq8In6Dj7ug-RXsQ6dWDIjzE3OXKr5dlj',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
# resp = urllib.parse.unquote(resp.text)
# print(resp.text)
# 正则抓标题
obj = re.compile(r"<span><span><span><span>(?P<title>.*?)</span></span></span></span>", re.S)
title = obj.search(resp.text).group("title")
# print(title)
# 正则抓视频信息
info = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', resp.text)[0]
# print(info)
# url解码
html_data = urllib.parse.unquote(info)
html_data = json.loads(html_data)
# pprint(html_data) # 让字典更加美观
# 字典取值,拿视频播放链接
video_url = 'https:' + html_data['41']['aweme']['detail']['video']['bitRateList'][0]['playAddr'][0]['src']
# print(video_url)
# 获取视频二进制数据
video_content = resp = requests.get(url=video_url, headers=headers).content
# 保存视频
if not os.path.exists('./4_video_batch'):
os.mkdir('./4_video_batch')
with open('./4_video_batch/' + title + '.mp4', mode='wb') as f:
f.write(video_content)详细讲解见上一节:35. 实战:Python实现视频去水印(文末源码)
2. 获取下载列表
这里用了selenium的循环滚动功能,一直拉到主页最下面才停止,而判断它停止的方法就是滚动条上下的距离相等,还是比较巧妙的。
然后审查元素发现视频列表放在CSS选择器里面,并且都在一个class里,那么就用我们刚学过的知识,用CSS选择器筛选出这个class的所有列表项。
创建一个空列表,遍历所有的列表项,将其中的href写入列表即可,最后返回列表。
def grab_video_list():
# 准备好参数配置
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
driver = Chrome(options=opt) # 把参数配置设置到浏览器中
driver.get('见评论区')
# 向下滚动至元素可见(翻完这人的主页)
# 定义一个初始值
temp_height = 0
while True:
# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")
# sleep一下让滚动条反应一下
time.sleep(1)
# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script(
"return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
# 如果两者相等说明到底了
if check_height == temp_height:
break
temp_height = check_height
print(check_height)
lis = driver.find_elements(By.CSS_SELECTOR, '.Eie04v01')
url_list = []
for li in lis:
url = li.find_element(By.CSS_SELECTOR, 'a').get_attribute('href')
# print(url)
url_list.append(url)
return url_list3. 创建线程池调用下载函数
其实就是主函数的逻辑
def main():
video_list = grab_video_list()
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in video_list:
t.submit(grab_single_video, link=i)
# 等待线程池中的任务全部执行完毕
print("Clear!!!")先用获取下载列表函数拿到主页所有链接,然后创建线程池,将所有链接扔进下载函数。
(其实这里可以改进,用异步的方法把链接全部输入进去)
完整源码
import requests
import re
import json
import urllib
from urllib import parse
import os
from pprint import pprint
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
from concurrent.futures import ThreadPoolExecutor
"""
常规找视频资源:到Network --> Media里面抓包,就能得到地址
然后在Media里面拿到地址,去全局搜索URL来源
"""
def grab_video_list():
# 准备好参数配置
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
driver = Chrome(options=opt) # 把参数配置设置到浏览器中
driver.get('见评论区')
# 向下滚动至元素可见(翻完这人的主页)
# 定义一个初始值
temp_height = 0
while True:
# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")
# sleep一下让滚动条反应一下
time.sleep(1)
# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script(
"return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
# 如果两者相等说明到底了
if check_height == temp_height:
break
temp_height = check_height
print(check_height)
lis = driver.find_elements(By.CSS_SELECTOR, '.Eie04v01')
url_list = []
for li in lis:
url = li.find_element(By.CSS_SELECTOR, 'a').get_attribute('href')
# print(url)
url_list.append(url)
return url_list
def grab_single_video(link):
url = f'{link}'
headers = {
'cookie': 'douyin.com; __ac_nonce=063d749310021f8bd394b; __ac_signature=_02B4Z6wo00f01R8urHgAAIDBnyxWOmwmfMUfDqjAACQfd6; ttwid=1%7CtRZY98IpvYfhjM-VRDQHgX3mgPcfWwWxylxnwwC7fFk%7C0%7C9af2c384c7d2b4e10ec0497fce797af996c72dd3868ec040595de36132c01ad0; home_can_add_dy_2_desktop=%220%22; passport_csrf_token=ee0cbadbf97ac430daac207c46997ca1; passport_csrf_token_default=ee0cbadbf97ac430daac207c46997ca1; strategyABtestKey=%221675053365.079%22; s_v_web_id=verify_ldibiwgl_ycqaypzT_aJxd_4ZEW_9iGD_XkAPFGlhzwd3; AB_LOGIN_GUIDE_TIMESTAMP=%221675053363589%22; msToken=L3xfxnCP4kW9_qabjW3S1cud_5DmI99tIEOw1_lJDMgdp1GJ9KQd6HWXKepYY-7iLlj4SR_V02zL3lYO6FVnXoPPVNneC5bD9cEnYN4nNpXzaNmvq7oA; ttcid=a598309ef5f3442b95f1d979574083f925; tt_scid=Px0Q21O38QIdeziR7nBXUqfZYJaS4qKakt5Zkfio72r9U4XaJdOYTb37LsjIrRLQca96; msToken=xibNm7RgEpzX8c6UaAgkzAOHMr5TcWNmNbfFR1vD-3uNUhtRXEqVQrmPIV6iDsnsA3WhMCTIOGDtST_F9GEyq8In6Dj7ug-RXsQ6dWDIjzE3OXKr5dlj',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
# resp = urllib.parse.unquote(resp.text)
# print(resp.text)
# 正则抓标题
obj = re.compile(r"<span><span><span><span>(?P<title>.*?)</span></span></span></span>", re.S)
title = obj.search(resp.text).group("title")
# print(title)
# 正则抓视频信息
info = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', resp.text)[0]
# print(info)
# url解码
html_data = urllib.parse.unquote(info)
html_data = json.loads(html_data)
# pprint(html_data) # 让字典更加美观
# 字典取值,拿视频播放链接
video_url = 'https:' + html_data['41']['aweme']['detail']['video']['bitRateList'][0]['playAddr'][0]['src']
# print(video_url)
# 获取视频二进制数据
video_content = resp = requests.get(url=video_url, headers=headers).content
# 保存视频
if not os.path.exists('./4_video_batch'):
os.mkdir('./4_video_batch')
with open('./4_video_batch/' + title + '.mp4', mode='wb') as f:
f.write(video_content)
def main():
video_list = grab_video_list()
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in video_list:
t.submit(grab_single_video, link=i)
# 等待线程池中的任务全部执行完毕
print("Clear!!!")
if __name__ == '__main__':
main()
运行效果
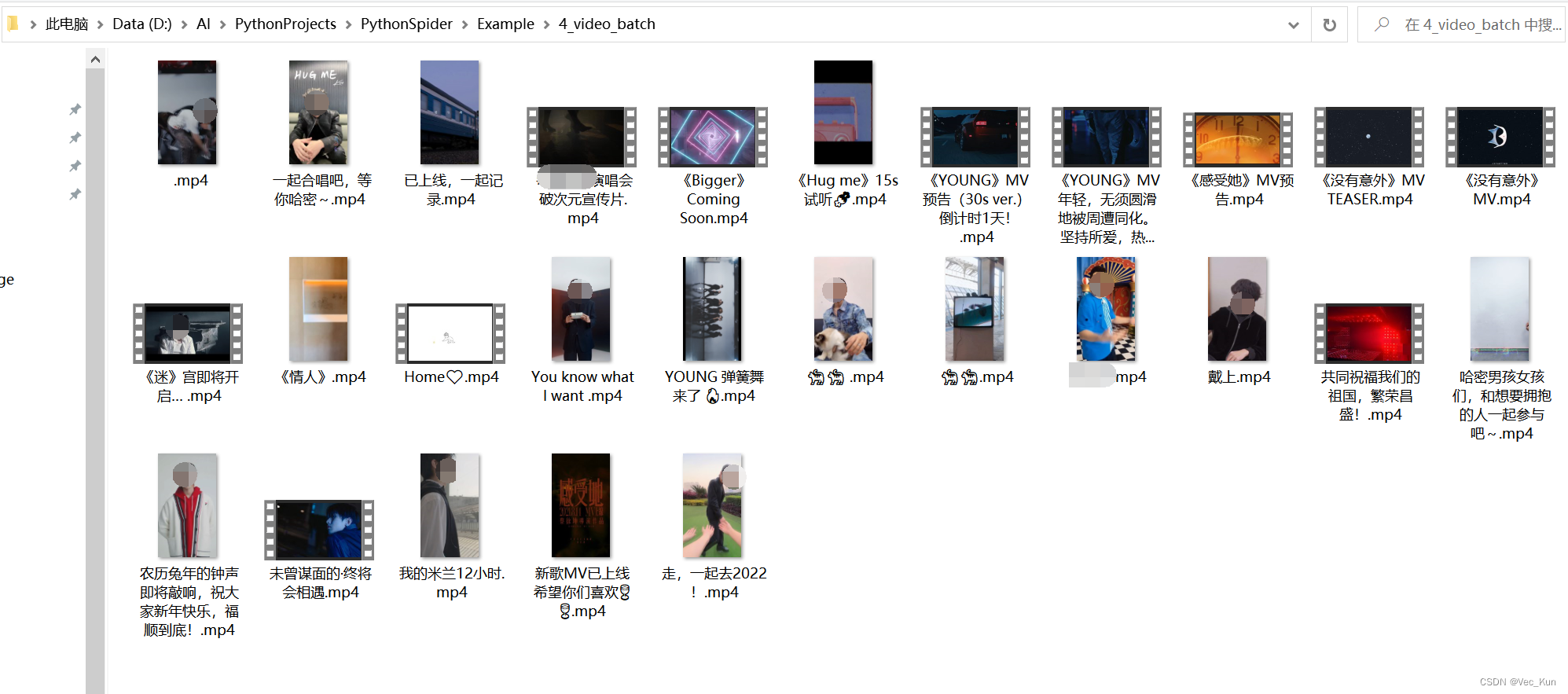
这里用我家咯咯的主页为例演示一下(纯路人):

把主页链接复制进URL,运行:
(输出的数字是滚动条高度,下载过程因网速而异,只要不报错就在下载。)
(如果想看得清楚可以在下载单个视频的函数那里自己加一个print输出,我就不加了)

总结
本节基于多线程实现了高效批量抓取任意主页的全部视频,只需要替换主页URL即可。示例URL我放在评论区了,有需要的自取即可!也可以选自己喜欢的博主测试一下。