总结/朱季谦
某天同事突然问我,你知道Mybatis Plus的insert方法,插入数据后自增id是如何自增的吗?
我愣了一下,脑海里只想到,当在POJO类的id设置一个自增策略后,例如@TableId(value = "id",type = IdType.ID_WORKER)的注解策略时,就能实现在每次数据插入数据库时,实现id的自增,例如以下形式——
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(value = "用户对象")
@TableName("user_info")
public class UserInfo {
@ApiModelProperty(value = "用户ID", name = "id")
@TableId(value = "id",type = IdType.ID_WORKER)
private Integer id;
@ApiModelProperty(value = "用户姓名", name = "userName")
private String userName;
@ApiModelProperty(value = "用户年龄", name = "age")
private int age;
}
但是,说实话,我一直都没能理解,这个注解策略实现id自增的底层原理究竟是怎样的?
带着这样的疑惑,我开始研究了一番Mybatis Plus的insert自增id的策略源码,并将其写成了本文。
先来看一下Mybatis Plus生成id的自增策略,可以通过枚举IdType设置以下数种策略——
@Getter
public enum IdType {
/**
* 数据库ID自增
*/
AUTO(0),
/**
* 该类型为未设置主键类型
*/
NONE(1),
/**
* 用户输入ID
* 该类型可以通过自己注册自动填充插件进行填充
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 全局唯一ID (idWorker)
*/
ID_WORKER(3),
/**
* 全局唯一ID (UUID)
*/
UUID(4),
/**
* 字符串全局唯一ID (idWorker 的字符串表示)
*/
ID_WORKER_STR(5);
......
}
每个字段都有各自含义,说明如下:
AUTO(0): 用于数据库ID自增的策略,主要用于数据库表的主键,在插入数据时,数据库会自动为新插入的记录分配一个唯一递增ID。NONE(1): 表示未设置主键类型,存在某些情况下不需要主键,或者主键由其他方式生成。INPUT(2): 表示用户输入ID,允许用户自行指定ID值,例如前端传过来的对象id=1,就会根据该自行定义的id=1当作ID值;ID_WORKER(3): 表示全局唯一ID,使用的是idWorker算法生成的ID,这是一种雪花算法的改进。UUID(4): 表示全局唯一ID,使用的是UUID(Universally Unique Identifier)算法。ID_WORKER_STR(5): 表示字符串形式的全局唯一ID,这是idWorker生成的ID的字符串表示形式,便于在需要字符串ID的场景下使用。
接下来,让我们跟着源码看一下,究竟是如何基于这些ID策略做id自增的,本文主要以ID_WORKER(3)策略id来追踪。
先从插入insert方法开始。
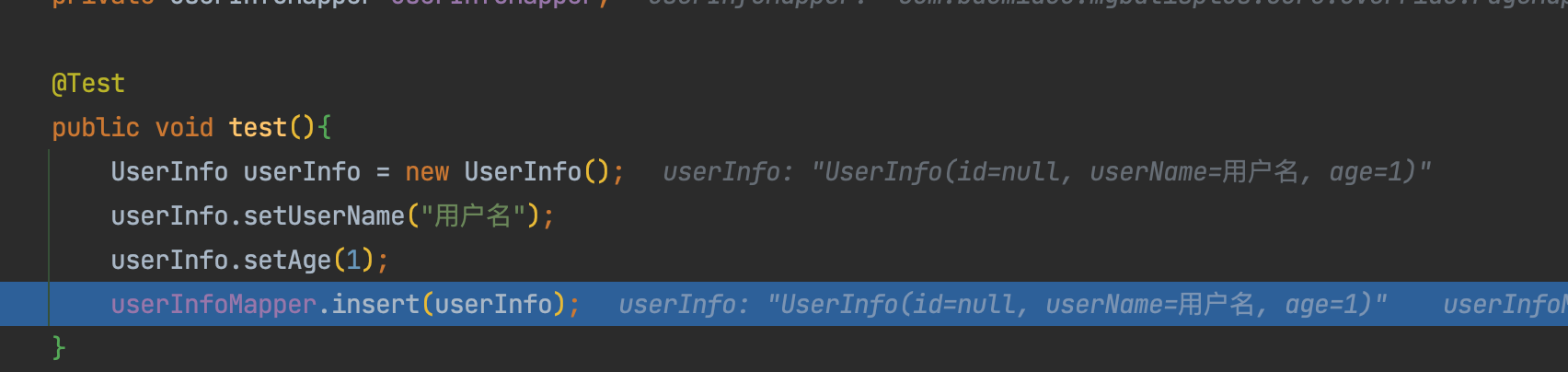
基于前文创建的UserInfo类,我们写一个test的方法,用于追踪insert方法——
@Test
public void test(){
UserInfo userInfo = new UserInfo();
userInfo.setUserName("用户名");
userInfo.setAge(1);
userInfoMapper.insert(userInfo);
}
可以看到,此时的id=0,还没有任何值——
执行到insert的时候,底层会执行一个动态代理,最终通过动态代理,执行DefaultSqlSession类的insert方法,可以看到,insert方法里,最终调用的是一个update方法。
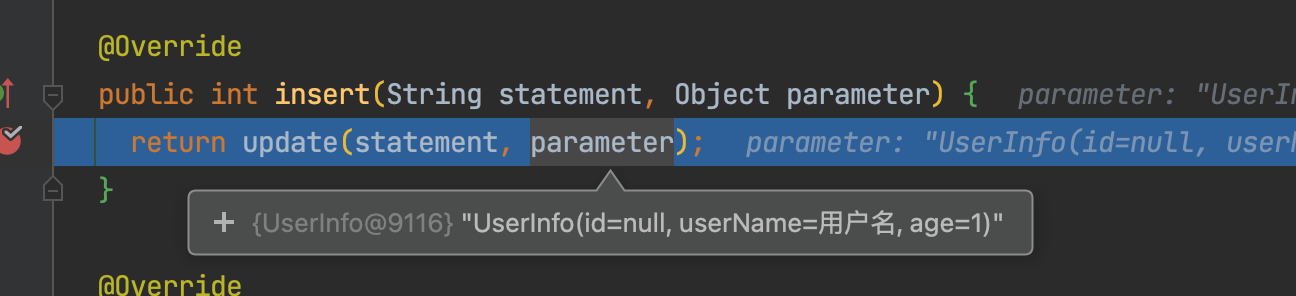
在mybatis中,无论是新增insert或者更新update,其底层都是统一调用DefaultSqlSession的update方法——
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
执行到executor.update(ms, wrapCollection(parameter))方法时,会跳转到BaseExecutor的update方法里——
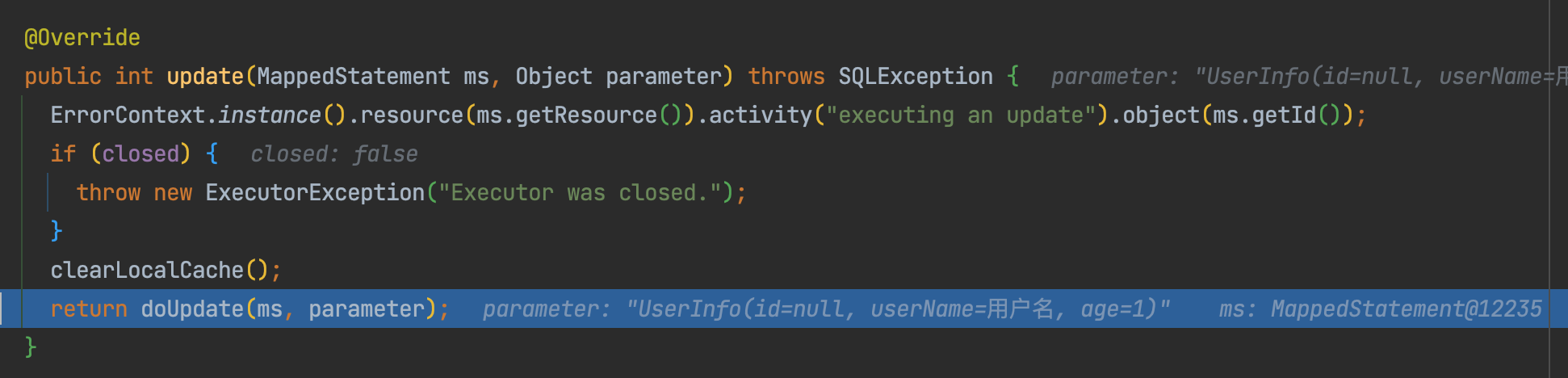
这里的BaseExecutor是mybatis的核心组件,它是Executor 接口的一个具体实现,提供了实际数据的增删改查操作功能。在 MyBatis 中,基于BaseExecutor扩展了以下三种基本执行器类:
- SimpleExecutor:这是最简单的执行器类型,它对每个数据库CURD操作都创建一个新的
Statement对象。如果应用程序执行大量的数据库操作,这种类型的执行器可能会产生大量的开销,因为它不支持Statement重用。 - ReuseExecutor:这种执行器类型会尝试重用
Statement对象。它在处理多个数据库操作时,会尝试使用相同的Statement对象,从而减少创建Statement对象的次数,提高性能。 - BatchExecutor:这种执行器类型用于批量操作,它会在内部缓存所有的更新操作,然后在适当的时候一次性执行它们,适合批量插入或更新操作的场景,可以显著提高性能。
除了这三种基本的执行器类型,MyBatis 还提供了其他一些执行器,这里暂时不展开讨论。
在本文中,执行到doUpdate(ms, parameter)时,会默认跳转到SimpleExecutor执行器的doUpdate方法里。注意我标注出来的这两行代码,自动填充插入ID策略的逻辑,就是在这两行代码当中——
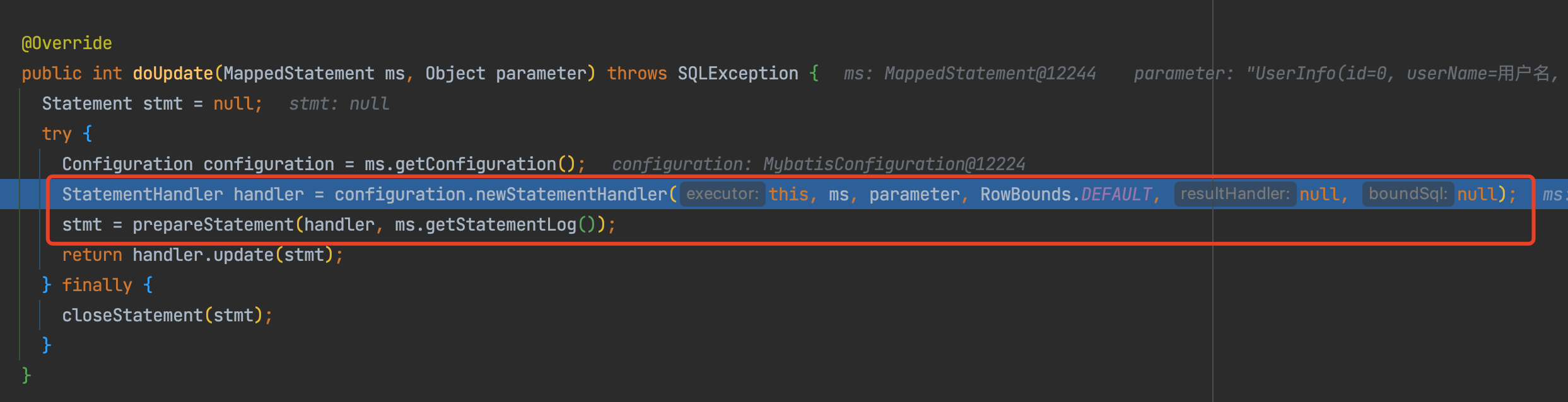
先来看第一行代码,从类名就可以看出,这里创建里一个实现StatementHandler接口的对象,这个StatementHandler接口专门用来处理SQL语句的接口。从这里就可以看出,通过创建这个对象,可以专门用来处理SQL相关语句操作,例如,对参数的设置,更具体一点,可以对参数id进行自定义设置等功能。
实现StatementHandler接口有很多类,那么,具体需要创建哪个对象呢?
跟着代码一定进入到RoutingStatementHandler类的RoutingStatementHandler方法当中,可以看到,这里有一个switch,debug到这一步,最终创建的是一个PreparedStatementHandler对象——
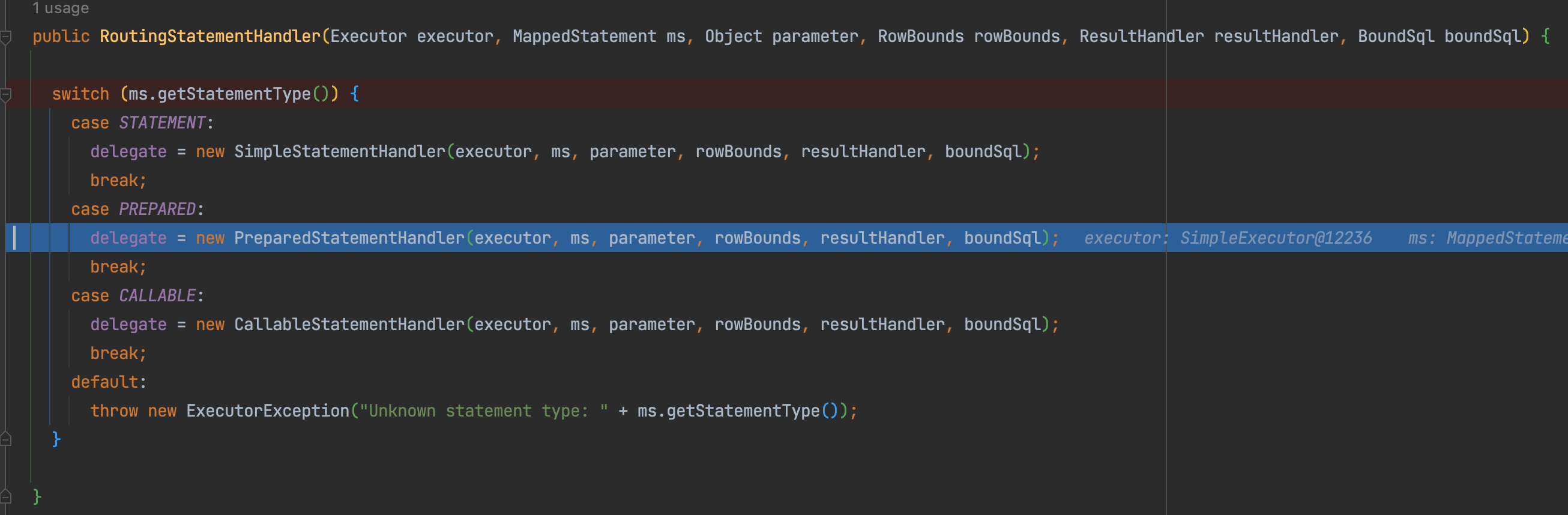
进入到PreparedStatementHandler方法当中,可以看到会通过super调用创建其父类的构造器方法——
public PreparedStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
super(executor, mappedStatement, parameter, rowBounds, resultHandler, boundSql);
}
从super(executor, mappedStatement, parameter, rowBounds, resultHandler, boundSql)方法进去,到父类的BaseStatementHandler里,这里面有一行很关键的代码 this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql),这是一个MyBatis内部的接口或实现类的实例,用于处理SQL的参数映射和传递。
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
this.configuration = mappedStatement.getConfiguration();
this.executor = executor;
this.mappedStatement = mappedStatement;
this.rowBounds = rowBounds;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.objectFactory = configuration.getObjectFactory();
if (boundSql == null) { // issue #435, get the key before calculating the statement
generateKeys(parameterObject);
boundSql = mappedStatement.getBoundSql(parameterObject);
}
this.boundSql = boundSql;
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}
进入到configuration.newParameterHandler(mappedStatement, parameterObject, boundSql)代码里,可以看到这里通过createParameterHandler方法创建一个实现ParameterHandler接口的对象,至于这个对象是什么,可以接着往下去。
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
最终来到MybatisXMLLanguageDriver类的createParameterHandler方法,可以看到,创建的这个实现ParameterHandler接口的对象,是这个MybatisDefaultParameterHandler。
public class MybatisXMLLanguageDriver extends XMLLanguageDriver {
@Override
public ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject,
BoundSql boundSql) {
/* 使用自定义 ParameterHandler */
return new MybatisDefaultParameterHandler(mappedStatement, parameterObject, boundSql);
}
}
继续跟进去,可以看到构造方法里,有一个processBatch(mappedStatement, parameterObject)方法,我们要找的填充自增id的IdType.ID_WORKER策略实现,其实就在这个processBatch方法里。
public MybatisDefaultParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
super(mappedStatement, processBatch(mappedStatement, parameterObject), boundSql);
this.mappedStatement = mappedStatement;
this.configuration = mappedStatement.getConfiguration();
this.typeHandlerRegistry = mappedStatement.getConfiguration().getTypeHandlerRegistry();
this.parameterObject = parameterObject;
this.boundSql = boundSql;
}
至于processBatch(mappedStatement, parameterObject)中的两个参数分别是什么,debug就知道了,mappedStatement是一个存储执行语句相关的Statement对象,而parameterObject则是需要插入数据库的对象数据,此时id仍然是默认0,相当还没有值。
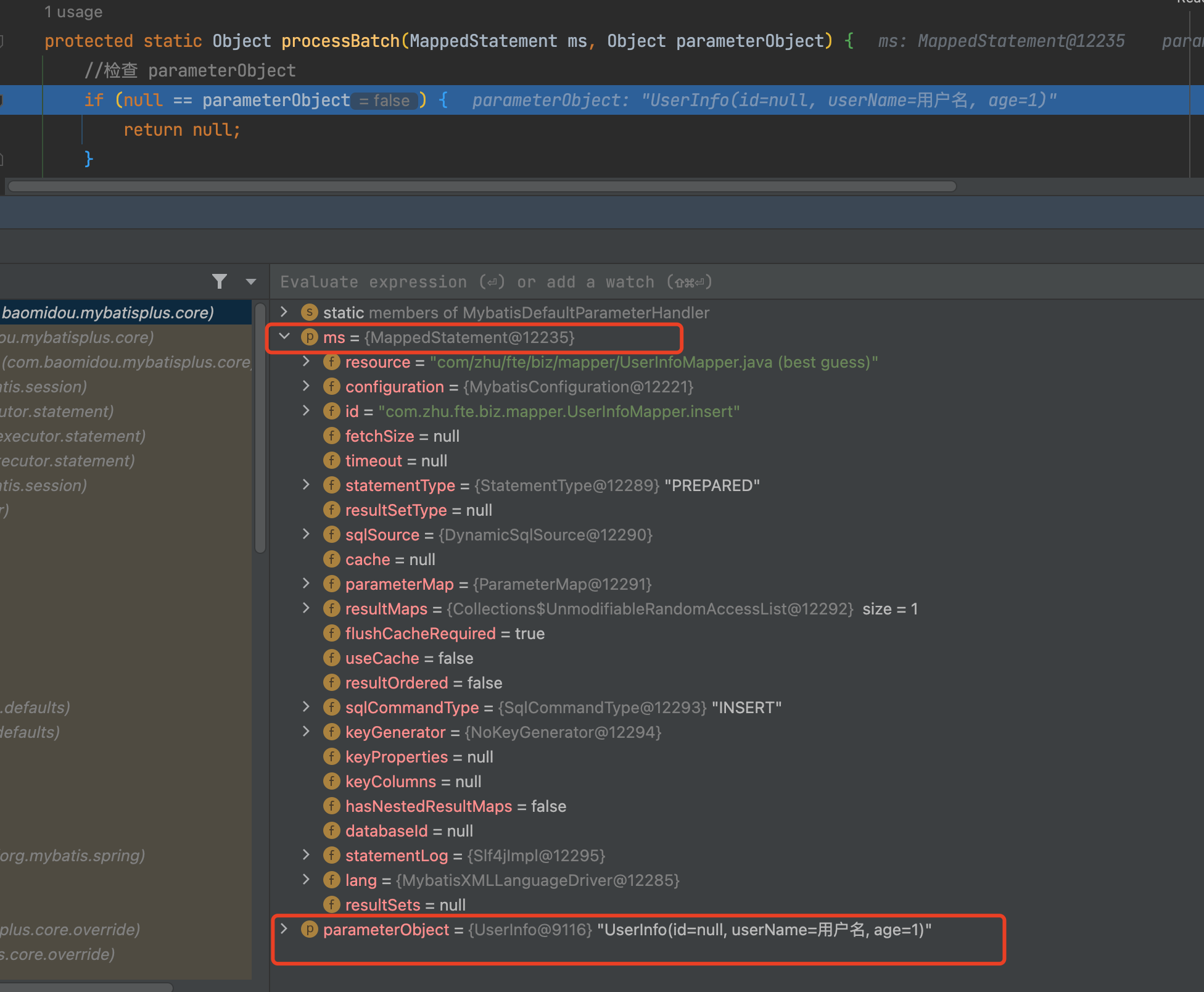
继续往下debug,因为是insert语句,故而会进入到ms.getSqlCommandType() == SqlCommandType.INSERT方法里,将isFill赋值true,isInsert赋值true,这两个分别表示是否需要填充以及是否插入。由此可见,它将会执行if (isFill) {}里的逻辑——
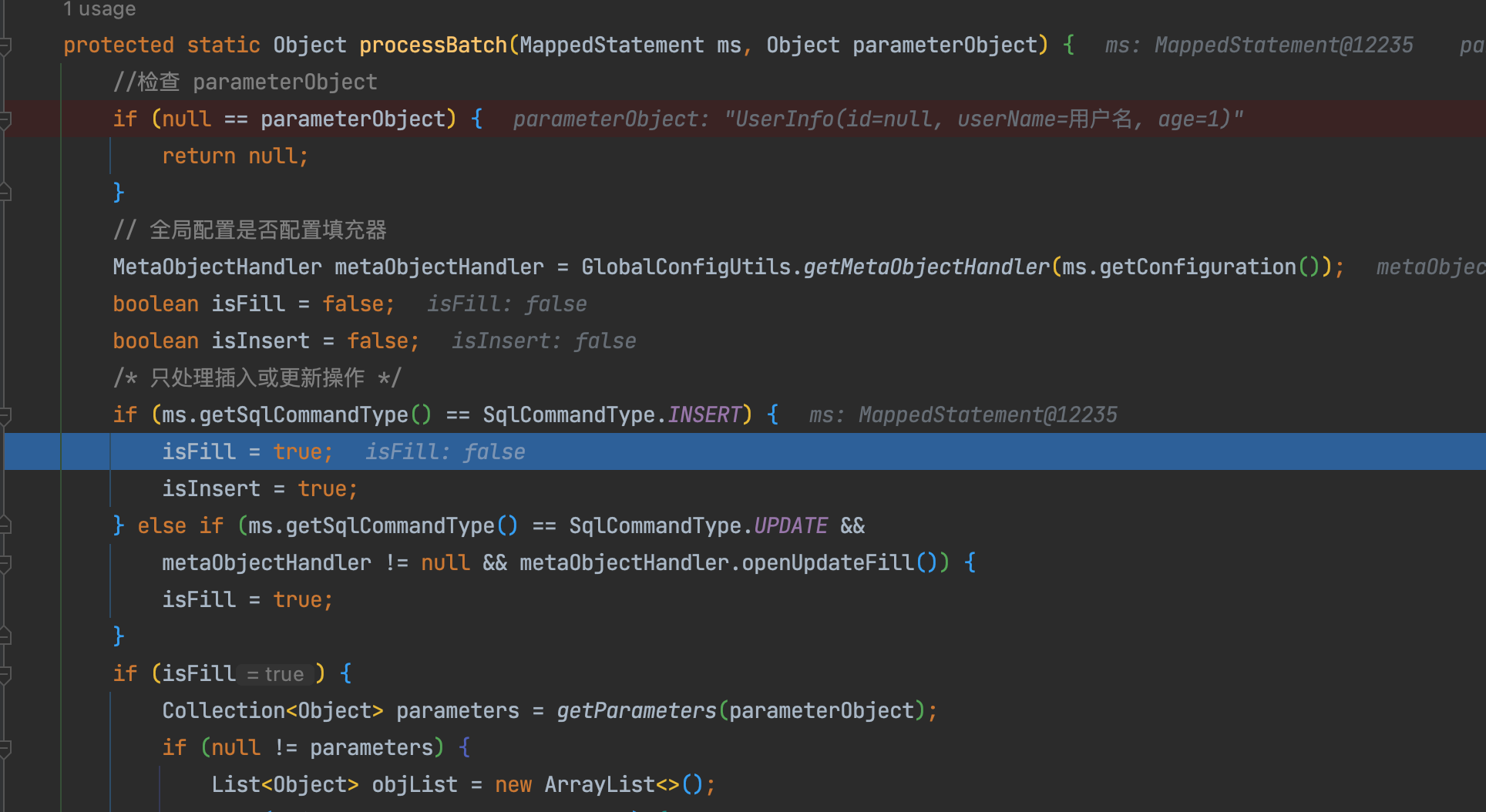
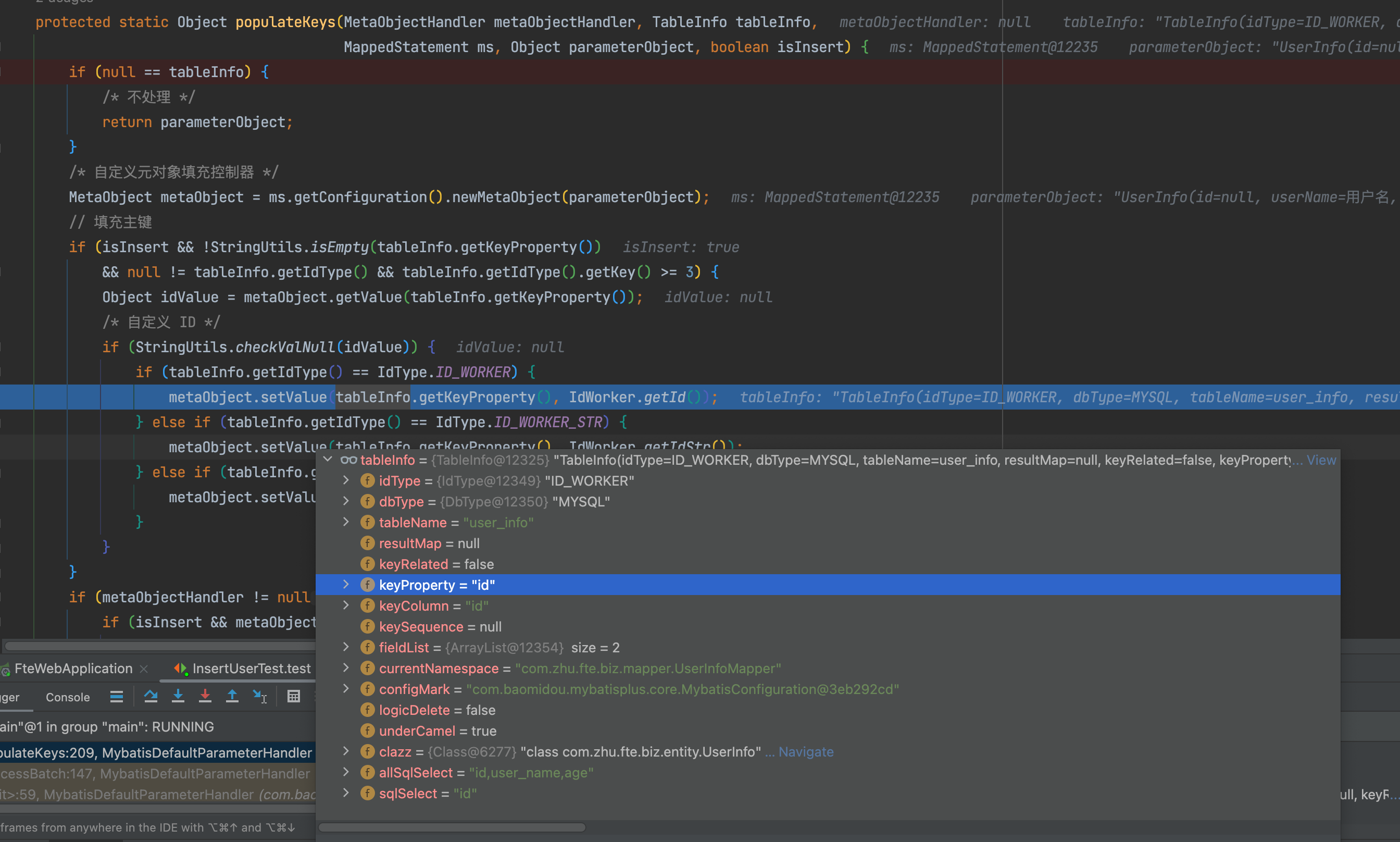
在if(isFill)方法当中,最重要的是populateKeys(metaObjectHandler, tableInfo, ms, parameterObject, isInsert);这个方法,这个方法就是根据不同的id策略,去生成不同的id值,然后填充到id字段里,最终插入到数据库当中。而我们要找的最终方法,正是在这里面——
protected static Object populateKeys(MetaObjectHandler metaObjectHandler, TableInfo tableInfo,
MappedStatement ms, Object parameterObject, boolean isInsert) {
if (null == tableInfo) {
/* 不处理 */
return parameterObject;
}
/* 自定义元对象填充控制器 */
MetaObject metaObject = ms.getConfiguration().newMetaObject(parameterObject);
// 填充主键
if (isInsert && !StringUtils.isEmpty(tableInfo.getKeyProperty())
&& null != tableInfo.getIdType() && tableInfo.getIdType().getKey() >= 3) {
Object idValue = metaObject.getValue(tableInfo.getKeyProperty());
/* 自定义 ID */
if (StringUtils.checkValNull(idValue)) {
if (tableInfo.getIdType() == IdType.ID_WORKER) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getId());
} else if (tableInfo.getIdType() == IdType.ID_WORKER_STR) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getIdStr());
} else if (tableInfo.getIdType() == IdType.UUID) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.get32UUID());
}
}
}
if (metaObjectHandler != null) {
if (isInsert && metaObjectHandler.openInsertFill()) {
// 插入填充
metaObjectHandler.insertFill(metaObject);
} else if (!isInsert) {
// 更新填充
metaObjectHandler.updateFill(metaObject);
}
}
return metaObject.getOriginalObject();
}
例如,我们设置的id策略是这个 @TableId(value = "id",type = IdType.ID_WORKER),当代码执行到populateKeys方法里时,就会判断是否为 IdType.ID_WORKER策略,如果是,就会执行对应的生存id的方法。这里的IdWorker.getId()就是获取一个唯一ID,然后赋值给tableInfo.getKeyProperty(),这个tableInfo.getKeyProperty()正是user_info的对象id。