v1.0官方文档:https://python.langchain.com/v0.1/docs/get_started/introduction/
最新文档:https://python.langchain.com/v0.2/docs/introduction/
LangChain是一个能够利用大语言模型(LLM,Large Language Model)能力进行快速应用开发的框架:
- 高度抽象的组件,可以像搭积木一样,使用LangChain的组件来实现我们的应用
- 集成外部数据到LLM中,比如API接口数据、文件、外部应用等;
- 提供了许多可自定义的LLM高级能力,比如Agent、RAG等等;
LangChain框架主要由以下六个部分组成:
- Model IO:格式化和管理LLM的输入和输出
- Retrieval:检索,与特定应用数据交互,比如RAG,与向量数据库密切相关,能够实现从向量数据库中搜索与问题相关的文档来作为增强LLM的上下文
- Agents:决定使用哪个工具(高层指令)的结构体,而tools则是允许LLM与外部系统交互的接口
- Chains:构建运行程序的block-style组合,即能将多个模块连接起来,实现复杂的功能应用
- Memory:在运行一个链路(chain)时能够存储程序状态的信息,比如存储历史对话记录,随时能够对这些历史对话记录重新加载,保证长对话的准确性
- Callbacks:回调机制,可以追踪任何链路的步骤,记录日志

可以到上一篇文章LangChain入门开发教程(一):Model I/O回顾了Model I/O涉及的Prompts、LLMs、Chat model、Output Parser等概念及其使用,这篇文章则继续介绍LangChain的第二个核心组件:Retrieval。
Retrieval
https://python.langchain.com/v0.1/docs/modules/data_connection/
- 许多LLM应用需要使用到用户特定的数据,比如某些私域/垂直领域的数据,但它并不包含在LLM的训练样本集合,因此LLM无法在这些领域很好地发挥它的能力
- 对于近期的资讯信息,由于训练样本的滞后性,无法实时更新最新资讯语料,因此LLM是无法获知临近的资料信息的,有时甚至会一本正经的胡说八道
而针对这种数据情况,目前最主要的解决方式则是RAG(Retrieval Augmented Generation,检索增强生成):在生成过程中,外部的数据会通过检索然后传递给LLM,让LLM能够利用这些新知识作为上下文。
LangChain提供了全部RAG应用的构建模板,覆盖了与检索流程相关的所有步骤,例如获取外部数据等。它主要包含以下几个核心模块:

- Document loaders:LangChain内置100多种document loaders,可以从许多不同的数据源加载数据,支持所有类型包括HTML、PDF和code等,也支持各种地址包括S3 buckets、公开的网站等等。
- Text Splitting:检索的一个关键部分就是只获取文档中相关的那一部分,这涉及到多个转换步骤来为检索准备文档。其中主要的一个步骤就是将一个大型文档拆分为更小的chunks(块)。
- Text Embedding Models:检索的另外一个关键部分就是为文档创建embeddings。embeddings可以捕获文本的语义信息,让你可以快速高效的寻找到相似的文本。
- Vector Stores:随着embeddings数量增加,便需要一个向量数据库来高效地存储和检索这些embeddings,像之前介绍过的支持本地内存: Annoy & Faiss、chroma,或者C/S架构:milvus、weaviate、qdrant等等
- Retrievers:一旦数据存入数据库,接下来要做的便是检索。LangChain提供了许多不同的检索算法,能够很轻松的实现语义相似检索。
- Indexing:LangChain提供了Indexing API来同步数据源到向量数据库。
文档加载器
示例代码:document_loaders.ipynb
文档加载器可以从任意源加载数据,以Document类的形式,Document包括一块文本(text)和相关的元数据(metadata)。LangChain提供了许多文档加载器,既可以加载简单的.txt文件,也有从任意网页加载文本内容的,甚至可以加载Youtube视频的文字内容。
文档加载器提供了load方法可以从指定源加载数据为文档,也实现lazy_load的懒加载方式,仅在需要访问的时候才加载到内存。
Text
TextLoader是最简单的一个加载器,它会读取一个文件作为text,然后将所有内容放置在一个document里。
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./examples/sql.md")
loader.load()
"""
[Document(page_content="## 创建表\n\n```sql\n# 分区表\ncreate table test_t2(words string,frequency string) partitioned by (partdate string) row format delimited fields terminated by ','.....", metadata={'source': './examples/sql.md'})]
"""
page_content存储文字内容,metadata存储了数据源信息。
CSV
CSV(Comma-separated values)是一种逗号分隔文本文件,每一行代表一条数据记录,一条数据记录会有一个或者多个fields,以逗号隔开。
比如下面的csv文件样例:

from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./examples/test.csv')
loader.load()
"""
[Document(page_content='id: 1\nname: 张三\ndegree: 本科', metadata={'source': './examples/test.csv', 'row': 0}),
Document(page_content='id: 2\nname: 李四\ndegree: 硕士', metadata={'source': './examples/test.csv', 'row': 1})]
"""
CSVLoader会把一行即一条数据记录作为一个Document,不同fields之间以换行符隔开,metadata则存储了对应的行号和数据源信息。
CSV是分隔符分隔文本文件中的一种,CSVLoader可以指定分隔符,通过参数 csv_args:
loader = CSVLoader(file_path='./examples/no_fields_name.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['id', 'name', 'degree']
},
source_column='id'
)
loader.load()
"""
[Document(page_content='id: 1\nname: 张三\ndegree: 本科', metadata={'source': '1', 'row': 0}),
Document(page_content='id: 2\nname: 李四\ndegree: 硕士', metadata={'source': '2', 'row': 1})]
"""
- delimiter:分隔符
- quotechar:csv这类文件是以换行符来分隔每一条数据记录的,如果某个field中的值存在换行符,则需要转义字符
quotechar - fieldnames:当csv文件没有列名时,可以指定列名
- source_column:选择一个fields name作为metadata中的source
下面我们再列举PDF文件的加载,以上述TextLoader中的sql.md导出pdf为例:
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("examples/sql.pdf")
pages = loader.load()
pages
"""
[Document(page_content="创建表 \n插⼊数据 # 分区表create table test_t2(words string,frequency string) partitioned by (partdate string) row format delimited fields terminated by ','......", metadata={'source': 'examples/sql.pdf', 'page': 0})]
"""
LangChain会把pdf文件的每一页内容存储到一个Document实例中。
其他加载器
File Directory、HTML、JSON、Markdown 等
自定义加载器
文档加载主要包括以下几个抽象组件:
| Component | Description |
|---|---|
| Document | Contains text and metadata |
| BaseLoader | Use to convert raw data into Documents(将原始数据转换为Documents) |
| Blob | A representation of binary data that’s located either in a file or in memory(表示一个文件或内存里的二进制数据) |
| BaseBlobParser | Logic to parse a Blob to yield Document objects(将 Blob解析为Document) |
自定义文档加载器.
一个文档加载器需要继承BaseLoader,并提供了以下几个需要实现的接口来加载文档:
| Method Name | Explanation |
|---|---|
| lazy_load | Used to load documents one by one lazily. Use for production code.(懒加载,使用一个文档加载一个,适合生产环境) |
| alazy_load | Async variant of lazy_load(异步实现) |
| load | Used to load all the documents into memory eagerly. Use for prototyping or interactive work.(饿汉式加载,一次性加载全部的文档到内存,可以不重写,默认调用list(self.lazy_load())) |
| aload | Used to load all the documents into memory eagerly. Use for prototyping or interactive work. (异步实现) |
下面实现了一个加载文本文件的例子,每一行加载为一个Document
from typing import AsyncIterator, Iterator
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
class CustomDocumentLoader(BaseLoader):
"""An example document loader that reads a file line by line."""
def __init__(self, file_path: str) -> None:
"""Initialize the loader with a file path.
Args:
file_path: The path to the file to load.
"""
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]: # <-- Does not take any arguments
"""A lazy loader that reads a file line by line.
When you're implementing lazy load methods, you should use a generator
to yield documents one by one.
"""
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
# alazy_load is OPTIONAL.
# If you leave out the implementation, a default implementation which delegates to lazy_load will be used!
async def alazy_load(
self,
) -> AsyncIterator[Document]: # <-- Does not take any arguments
"""An async lazy loader that reads a file line by line."""
# Requires aiofiles
# Install with `pip install aiofiles`
# https://github.com/Tinche/aiofiles
import aiofiles
async with aiofiles.open(self.file_path, encoding="utf-8") as f:
line_number = 0
async for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
仍然以上述的sql.md文件为例子进行加载:
loader = CustomDocumentLoader('./examples/sql.md')
for doc in loader.lazy_load():
print(doc)
"""
<class 'langchain_core.documents.base.Document'> | page_content='## 创建表\n' metadata={'line_number': 0, 'source': './examples/sql.md'}
<class 'langchain_core.documents.base.Document'> | page_content='```sql\n' metadata={'line_number': 1, 'source': './examples/sql.md'}
......
"""
async for doc in loader.alazy_load():
print()
print(type(doc))
print(doc)
"""
<class 'langchain_core.documents.base.Document'> | page_content='## 创建表\n' metadata={'line_number': 0, 'source': './examples/sql.md'}
<class 'langchain_core.documents.base.Document'> | page_content='```sql\n' metadata={'line_number': 1, 'source': './examples/sql.md'}
......
"""
文本分割器
示例代码:text_splitter.ipynb
在这里,要先理解一个概念,RAG中基于向量数据库的语义相似检索或者其他数据库的全文检索,其对象都是文档,在LangChain中则对应上述的Document。因此,传给LLM的检索文档:
- 不能过于冗长,一是会增加成本(包括tokens消耗和性能),二是依赖LLM的context length能力
- 尽量只包含与查询query语义相关的内容,不要有过多不相关的内容,这反而会影响LLM的推断
- 尽量保证文档的上下文完整性,而不是随意切分同个主题/段落中的句子
那么,此时就需要对原始文本进行切割,更好地将我们的文本数据转化为一个个Document,而不是像上述Text和PDF加载器例子那样,直接将整个文本直接加载为一个Document。
一般的处理思路如下:
- 将长文本切分为小的、有语义价值的块(chunks),通常是句子;
- 将这些小的块合并为稍微大一点的块,直到一定程度的大小(size),当然,最理想的情况是语义相关的句子能够合并在一起;
- 可以额外设置一个overlap,当超出指定size时,可以继续取内容,尽量每一个块是一个完整的句子。
分割级别
整个文本分割过程可以非常简单,也可以很复杂,复杂程度从低到高的处理方法如下:
- 字符分割:指定某个字符作为分隔符
- 递归字符分割:使用一组字符,递归地切分
- 文档格式分割:针对不同格式的文档使用不同的方法
- 语义分割:基于embeddings进行分隔
下面,我们会对每种级别的分割都列举一些LangChain内置的实现例子。
在开始实践之前,我们需要认识两个概念:
- Chunk Size:切割之后的一个块(也就是一个
Document)的大小 - Chunk Overlap:连续的块之间重复的字符数量,这是尽量避免将一个完整的上下文片段被切分了。这也将会连续的两个块存在一部分重复的字符,这部分重复的内容便是overlap。

字符分割
首先,我们可以直接按照上图[Chunk Overlap]的示例,仅指定chunk size和chunk overlap进行切割,仅以固定的大小去切分为每一个Document:
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="", # 默认为"\n\n",因此不使用分隔符的话,需要指定separator=""
chunk_size=35,
chunk_overlap=4,
)
text = "This is the text I would like to chunk up. It is the example text for this exercise"
text_splitter.create_documents([text])
"""
[Document(page_content='This is the text I would like to ch'),
Document(page_content='o chunk up. It is the example text'),
Document(page_content='ext for this exercise')]
"""
如果指定了使用分隔字符的话,那么会按照以下流程进行切分:
-
先以
separator作为分割符对长文本进行切分 -
然后对切分之后比较短的chunk进行合并,直到与下一个chunk合并会超过chunk_size
-
但是,存在单个chunk的文本超过chunk_size的情况
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=35,
chunk_overlap=4,
)
text = "This is\n the text I would\n like to chunk up.It is the example text for this exercise"
text_splitter.create_documents([text])
"""
[Document(page_content='This is\n the text I would'),
Document(page_content='like to chunk up.It is the example text for this exercise')]
"""
递归字符分割
有了前面的字符分割原理基础之后,那么递归字符分割就比较好理解了,它在字符切割的基础上,加入了一组分割字符列表和递归,并且这组分割字符等级应该逐渐降低,比如 ["\n\n", "\n", " ", ""] 是段落->句子->单词这样的逐级递减:
- 首先,逐级递减的顺序去找到长文本存在的最高等级的分隔字符,比如
\n\n; - 然后执行上面指定字符分割的步骤;
- 对当前分割字符切割之后,超过chunk_size的chunk,继续递归执行下一个等级的分割字符(比如
\n)的块; - 直到最后一个分隔字符即
"",跳出递归
首先,我们还是先上代码例子,依然以上述的英文句子为例,看看使用递归字符分割之后是什么结果:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""],
chunk_size=35,
chunk_overlap=4,
)
text = "This is\n\n the\n\n text\n I would like\n to chunk up. It is the example text\n for\n\n this exercise"
text_splitter.create_documents([text])
"""
[Document(page_content='This is\n\n the'),
Document(page_content='text\n I would like'),
Document(page_content='to chunk up. It is the example'),
Document(page_content='text'),
Document(page_content='for'),
Document(page_content='this exercise')]
"""
递归字符分割是实用性非常高的一种长文本切分方法,也是LangChain推荐使用的方法。
代码分割
这一类文本分割是针对代码文件,比如cpp、python等,但其依赖的仍然是上面的递归字符分割,比如下面的python代码,其实就是使用了一组特殊的分割字符列表而已:['\nclass ', '\ndef ', '\n\tdef ', '\n\n', '\n', ' ', ''],先根据类和函数去切分,再根据正常的行切分:
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
"""
[Document(page_content='def hello_world():\n print("Hello, World!")'),
Document(page_content='# Call the function\nhello_world()')]
"""
RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
"""
['\nclass ', '\ndef ', '\n\tdef ', '\n\n', '\n', ' ', '']
"""
但其实除了普通的代码,还支持markdown、html、latex等格式的文本文件的切分。
特定格式文档
如上所述,一直在强调每一个chunk应当保证文本的下上文,那么对于某些格式的文本文件,我们应该需要遵循它本身的结构去切分。比如markdown文本,它是以不同等级的headers来组织目录的,比如#表示一级目录,##表示二级目录,那么直观的想法便是按照headers来切分:
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = "# Intro \n\n ## History \n\n Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \n\n Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files. \n\n ## Rise and divergence \n\n As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \n\n additional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n\n #### Standardization \n\n From 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort. \n\n ## Implementations \n\n Implementations of Markdown are available for over a dozen programming languages."
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
"""
[Document(page_content='Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \nMarkdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files.', metadata={'Header 1': 'Intro', 'Header 2': 'History'}),
Document(page_content='As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \nadditional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n#### Standardization \nFrom 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort.', metadata={'Header 1': 'Intro', 'Header 2': 'Rise and divergence'}),
Document(page_content='Implementations of Markdown are available for over a dozen programming languages.', metadata={'Header 1': 'Intro', 'Header 2': 'Implementations'})]
"""
可以看到,结果已经按照headers分组切分,比如第一个Document则对应一级目录Intro和二级目录History,也即{'Header 1': 'Intro', 'Header 2': 'History'}。
虽然,这已经是按照原本的预期进行切分,但是切分后的每一个Document可能还是长文本。此时,便可以使用上述的递归字符分割,对每一段文本进一步切成较小的chunk。
# MD splits
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False
)
md_header_splits = markdown_splitter.split_text(markdown_document)
# Char-level splits
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# Split
splits = text_splitter.split_documents(md_header_splits)
splits
"""
[Document(page_content='# Intro \n## History \nMarkdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9]', metadata={'Header 1': 'Intro', 'Header 2': 'History'}),
Document(page_content='Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files.', metadata={'Header 1': 'Intro', 'Header 2': 'History'}),
Document(page_content='## Rise and divergence \nAs Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \nadditional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks.', metadata={'Header 1': 'Intro', 'Header 2': 'Rise and divergence'}),
Document(page_content='#### Standardization \nFrom 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort.', metadata={'Header 1': 'Intro', 'Header 2': 'Rise and divergence'}),
Document(page_content='## Implementations \nImplementations of Markdown are available for over a dozen programming languages.', metadata={'Header 1': 'Intro', 'Header 2': 'Implementations'})]
"""
- strip_headers=False表示保留headers原始文本
- 可以看到,从原本较长的3个Documents切分为5个较小的Documents
语义分割
LangChain接口文档:semantic-chunker,使用上非常简单:
# pip install --quiet langchain_experimental
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import OpenAIEmbeddings
# This is a long document we can split up.
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = SemanticChunker(OpenAIEmbeddings())
docs = text_splitter.create_documents([state_of_the_union])
但它背后的原理比较有意思,这里讲一下:(预备知识:句子的Embedding可以用来衡量两个句子之间的语义相关性)
- 选择一种合适的方法对整块长文本切分为句子
- 以三个句子组的窗口形式组合句子,对应下面代码的
buffer_size=1,即前面buffer_size个句子+当前句子+后面buffer_size个句子,并且对所有组合句子进行Embedding - 遍历所有句子,比较当前组合句子与下一个组合句子的语义相关性,即embeddings的距离
- 如果距离不超过
threshold,则合并当前句子和下一个句子到当前的chunk中 - 如果距离超过了
threshold,则当前chunk合并完成,下一个句子作为下一个chunk的开头
这里解释下这么做的有效性:
- 比较Embedding距离的是窗口形式的组合句子,因为单个句子比较存在较大的噪声
- 连续的两个组合句子Embedding距离超过阈值时,则前后句子语义相关性较低,可以认为开始了一个的语义部分
threshold有多种计算方法,其中一种是使用分位法,计算所有距离的95分位值作为阈值。
import re
with open('./examples/mit.txt') as file:
essay = file.read()
# Splitting the essay on '.', '?', and '!'
single_sentences_list = re.split(r'(?<=[.?!])\s+', essay)
print (f"{len(single_sentences_list)} senteneces were found")
sentences = [{'sentence': x, 'index' : i} for i, x in enumerate(single_sentences_list)]
sentences[:3]
"""
317 senteneces were found
[{'sentence': '\n\nWant to start a startup?', 'index': 0},
{'sentence': 'Get funded by\nY Combinator.', 'index': 1},
{'sentence': 'October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.',
'index': 2}]
"""
sentences = combine_sentences(sentences, buffer_size=1)
sentences[:3]
"""
[{'sentence': '\n\nWant to start a startup?',
'index': 0,
'combined_sentence': '\n\nWant to start a startup? Get funded by\nY Combinator.'},
{'sentence': 'Get funded by\nY Combinator.',
'index': 1,
'combined_sentence': '\n\nWant to start a startup? Get funded by\nY Combinator. October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.'},
{'sentence': 'October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.',
'index': 2,
'combined_sentence': 'Get funded by\nY Combinator. October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school. I think there will increasingly be a third option:\nto start your own startup.'}]
"""
Embedding
示例代码:embeddings.ipynb
开头已经提到embeddings是检索的关键部分,embeddings可以为一块文本创建一个向量表征,这能够用于实现文本相似检索,在同一个向量空间里,我们通过计算embeddings之间的距离来衡量两块文本的语义相关性。
许多主流的大模型供应商都会有其对应的Embedding模型。下面仍然以通义千问的免费tokens额度来作为演示案例,它支持最大2048的字符长度,生成的向量维度为1536。
不过LangChain没有内置通义千问的Embedding实现,因此需要自己实现,比较简单,可以参考内置的BaichuanTextEmbeddings实现:
- embed_documents:批量调用Embedding模型,生成一批文本的向量
- embed_query:生成单个文本的向量
from tongyi.embeddings import TongyiEmbeddings
embeddings_model = TongyiEmbeddings()
embeddings = embeddings_model.embed_documents(
[
"你好吗",
"你的名字是什么",
"我的肚子好痛啊",
"肠胃不舒服",
"我在吃东西"
]
)
len(embeddings), len(embeddings[0])
"""
(5, 1536)
"""
那么,我们来验证下embeddings是否能来衡量句子之间的语义相关性,下面以这个文本"肠胃不舒服"与上面的5个文本进行逐一比较:
import numpy as np
def normalize(x):
x = np.asarray(x)
norms = np.sum(np.multiply(x, x))
norms = np.sqrt(norms)
return x / norms
for i in range(5):
similarity = np.dot(normalize(embeddings[2]), normalize(embeddings[i]))
print(f'"{texts[2]}"与"{texts[i]}"的语义相似度为:{similarity}')
"""
"我的肚子好痛啊"与"你好吗"的语义相似度为:0.3540708666322656
"我的肚子好痛啊"与"你的名字是什么"的语义相似度为:0.3079039808785484
"我的肚子好痛啊"与"我的肚子好痛啊"的语义相似度为:1.0
"我的肚子好痛啊"与"肠胃不舒服"的语义相似度为:0.418081827009795
"我的肚子好痛啊"与"我在吃东西"的语义相似度为:0.3523671162523911
"""
可以看到,结果是合理的,肚子与肠胃、好痛与不舒服存在一定的相关性,因此"我的肚子好痛啊" 与"肠胃不舒服"的相似度最高。
缓存
这一章节讲一下embeddings的缓存,防止重复计算,以文本的hash值作为缓存的key,即需要完全相同的文本才能利用缓存快速二次访问。
其实现过程如下:
- 初始化一个
CacheBackedEmbeddings - 需要用到Embeddings生成模型,如上述的
TongyiEmbeddings - 还有一个存储对象,如
LocalFileStore,会在指定目录以文件的形式进行embeddings的存储
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
store = LocalFileStore("./cache/")
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
embeddings_model, store, namespace=embeddings_model.model_name
)
%%time
cached_embedder.embed_documents(texts)
"""
CPU times: user 75.1 ms, sys: 6.25 ms, total: 81.4 ms
Wall time: 357 ms
"""
%%time
cached_embedder.embed_documents(texts)
"""
CPU times: user 5.27 ms, sys: 2.35 ms, total: 7.62 ms
Wall time: 6.12 ms
"""
list(store.yield_keys())
"""
['text_embedding_v1f33a10ff-859a-5463-b3ff-f49f9fa5f6fa',
'text_embedding_v1046ba0f1-f46d-50cb-a4a2-d42b4b0a372b',
'text_embedding_v1fdcb1804-6409-5e76-89ff-9684747fff9d',
'text_embedding_v17cd8ea1f-6312-57bd-b0c4-46b1e007af6a',
'text_embedding_v1c8a6a73e-11f0-59e7-84f4-cb126b59694f']
"""
- 可以看到,因为有缓存,第二次生成向量的速度比第一次快出许多。
- namespace,支持多个命名空间,可以避免不同Embedding模型去生成相同文本时的key碰撞
- batch_size,可以设置CacheBackedEmbeddings批量写入换粗,而不是一次性全量写入
CacheBackedEmbeddings其实跟TongyiEmbeddings一样都是Embeddings的子类,因此也是调用相同的方法embed_documents来生成向量,它其实就是调用传入的真正的Embeddings来生成向量,并且缓存起来。
不过内置的CacheBackedEmbeddings的embed_query方法并没有实现缓存,这明明只是批量和单个文本的区别,LangChain内置却不实现,不懂。
内存存储、基于redis的缓存:
使用方式与上述的LocalFileStore一样
from langchain.storage import InMemoryByteStore
from langchain.storage import RedisStore
向量数据库
示例代码:vector_store.ipynb
上述介绍了几种向量缓存的方式,包括本地文件、内存、redis等,但其实这些都不是主流的向量存储方式,因为它们其实并不支持检索。
更普遍的方式是:
- 选择Embedding模型,对源数据进行批量文档生成的表征向量,存储到向量数据库
- 在查询的时候,对非结构化的查询文本使用同样的Embedding模型生成表征向量,然后去向量数据库召回与查询文本的表征向量相似的向量对应的文档。

下面我们以faiss作为向量数据库进行实例演示。(LangChain支持的向量数据库十分丰富,可以根据自己的需求进行选择)
加载源数据
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('./examples/rag.txt').load()
text_splitter = CharacterTextSplitter(separator='\n\n\n', chunk_size=50, chunk_overlap=4)
documents = text_splitter.split_documents(raw_documents)
documents[:2]
"""
[Document(page_content='2024年普通高等学校招生全国统一考试(简称:2024年全国高考),是中华人民共和国合格的高中毕业生或具有同等学力的考生参加的选拔性考试 [1-2]。2024年报名人数1342万人,比2023年增加51万人 [21]。', metadata={'source': './examples/rag.txt'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'})]
"""
向量存储
from langchain_community.vectorstores import FAISS
from tongyi.embeddings import TongyiEmbeddings
db = FAISS.from_documents(documents, TongyiEmbeddings())
这里的from_documents会进行以下步骤:
-
初始化faiss索引,这里LangChain的FAISS实现看起来并不完善,仅支持
IndexFlatIP和IndexFlatL2两种索引方式,并且默认是使用效率较低的精确检索IndexFlatL2,更多的索引方式可前往以前的文章 Faiss -
对documents里的所有文本块通过Embedding模型生成向量
-
向量写入faiss,并更新/构建索引(后续才能进行向量检索)
检索
query = "哪里可以了解高考成绩"
docs = db.similarity_search(query)
print(docs[0].page_content)
"""
一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?
各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。
考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。
"""
docs
"""
[Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等......', metadata={'source': './examples/rag.txt'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'}),
Document(page_content='三、高校招生章程有什么作用,如何查询?\n高校招生章程由学校依据相关法律规定和国家招生政策制定,是学校开展招生工作的依据。考生在填报志愿前,应仔细查阅拟报考高校的招生章程,全面了解高校招生办法和相关招生要求。\n主要查询途径有:中国高等教育学生信息网的“阳光高考”信息平台(https://gaokao.chsi.com.cn);各高校官方招生网站等。', metadata={'source': './examples/rag.txt'}),
Document(page_content='二、高考志愿填报咨询有哪些公共服务?\n教育部高度重视高考志愿填报咨询服务工作,指导各地建立了招生考试机构、高校、中学多方面志愿填报咨询公共服务体系......', metadata={'source': './examples/rag.txt'})]
"""
其中,有几个关键的参数:
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[Union[Callable, Dict[str, Any]]] = None,
fetch_k: int = 20,
**kwargs: Any,
)
- k:返回的检索数量
- filter:由于
Document有附带metadata的,因此可以使用filter函数,metadata作为入参,在检索之后能够进一步筛选 - score_threshold:相似度阈值,可以用来过滤相似度较低的文档
- fetch_k:向量数据库的召回数量,即在filter和相似度阈值过滤之前的文档数量
MMR
LangChain支持对检索结果进行基于maximum marginal relevance(MMR,最大边界相关法)的重新排序,MMR具体公式如下:
M M R = A r g m a x D i ∈ R \ S [ λ S i m ( D i , Q ) − ( 1 − λ ) m a x D j ∈ S S i m ( D i , D j ) ] MMR=Argmax_{D_i\in R \backslash S}[\lambda Sim(D_i,Q)-(1-\lambda)max_{D_j \in S}Sim(D_i,D_j)] MMR=ArgmaxDi∈R\S[λSim(Di,Q)−(1−λ)maxDj∈SSim(Di,Dj)]
- Q为查询文档,
- D为所有检索得到的相关文档
- S是已经被选择的文档
- R\S是未被选择的文档
- λ \lambda λ是一个0-1的权重
S初始化为与查询相似度最高的一个文档,然后一直循环MMR的计算,每一次S都会增加一个文档,直到所有文档都被选择到。
query = "哪里可以了解高考成绩"
docs = db.max_marginal_relevance_search(query)
docs
"""
[Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等......', metadata={'source': './examples/rag.txt'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'}),
Document(page_content='十、录取通知书何时能收到?\n高校一般会在录取结束后一周左右向录取新生寄发录取通知书。若考生在省级招生考试机构或高校官方网站上查询到了录取结果,一直没有收到录取通知书,可及时联系录取高校公布的招生咨询电话查询本人录取通知书邮寄情况。', metadata={'source': './examples/rag.txt'}),
Document(page_content='地区,报名时间\n北京,2023年10月25日9时至28日17时......', metadata={'source': './examples/rag.txt'})]
"""
可以看到,加了MMR重排序之后,top2与前面不加的是一样,不过MMR重排序之后,第3和第4个文档就改变了。
检索
示例代码:retrievers.ipynb
LCEL调用
在上一篇文章LangChain入门开发教程(一):Model I/O中,我们提到了LangChain的一种表达语言/协议:LCEL,基本上所有核心组件都是基于LCEL的方式去实现和调用,那么检索也可以通过LCEL来使用,这样对后面跟其他组件如LLM联动,提供很大的便捷性。
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": 2})
retriever.invoke("哪里可以了解高考成绩")
"""
[Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等......', metadata={'source': './examples/rag.txt'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'})]
"""
search_type:支持similarity、similarity_score_threshold、mmr
search_kwargs:检索参数,上述章节[向量数据库-检索]已经详细阐述过
多查询检索
以距离为度量的向量数据库检索,是通过将query进行embedding(表征)到高维的向量空间,然后基于距离检索相似文档(embedding到相同向量空间)。
- 但有时query中词语的轻微改变,或者embedding无法很好地捕获query的语义信息,那么将导致无法有效检索到相似文档。
而多query检索便是应对这个问题,会通过提示词工程,将query输入到LLM从不同角度生成多个类似的查询,再分别用多个query去进行检索,然后汇聚这些检索结果,并进行去重,这样能够获取更多潜在的相似文档。
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_community.chat_models import ChatTongyi
chat = ChatTongyi()
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=retriever, llm=chat, include_original=True
)
unique_docs = retriever_from_llm.invoke("哪里可以了解高考成绩")
unique_docs
"""
[Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等......', metadata={'source': './examples/rag.txt'}),
Document(page_content='三、高校招生章程有什么作用,如何查询?\n高校招生章程由学校依据相关法律规定和国家招生政策制定,是学校开展招生工作的依据。考生在填报志愿前,应仔细查阅拟报考高校的招生章程,全面了解高校招生办法和相关招生要求。\n主要查询途径有:中国高等教育学生信息网的“阳光高考”信息平台(https://gaokao.chsi.com.cn);各高校官方招生网站等。', metadata={'source': './examples/rag.txt'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'})]
"""
len(unique_docs)
"""3"""
生成多个查询的LLM提示词也可以从LangChain源码获取:
You are an AI language model assistant. Your task is
to generate 3 different versions of the given user
question to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question,
your goal is to help the user overcome some of the limitations
of distance-based similarity search. Provide these alternative
questions separated by newlines. Original question: {question}
上下文压缩
检索面临的一个挑战是在你构建文档知识库时,是无法提前预知query的内容,它可能是任何的内容,这意味着检索到的文档中与query最相关的信息可能会被湮没在许多不相关的文本中,这即会导致更加昂贵的LLM tokens调用费用,又会影响LLM的回复效果,因为引入了噪声。
针对这个问题,LangChain提供了一种思路方法:对检索文档,即上下文进行压缩。
1. LLMChainExtractor
LLMChainExtractor会引入额外的一个LLM来遍历原始的检索文档中提取与query相关的信息片段,而不是整一个文档,并且会过滤不存在与query相关的信息的文档。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"哪里可以了解高考成绩"
)
compressed_docs
"""
[Document(page_content='各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。', metadata={'source': './examples/rag.txt'})]
"""
我们仍然可以从LangChain源码中得到这个提取相关信息的LLM提示词:
Given the following question and context, extract any part of the context *AS IS* that is relevant to answer the question. If none of the context is relevant return {no_output_str}.
Remember, *DO NOT* edit the extracted parts of the context.
> Question: {{question}}
> Context:
>>>
{{context}}
>>>
Extracted relevant parts:
2. LLMChainFilter
LLMChainFilter则是更为简单但更鲁棒的实现,它仍然需要引入额外的LLM,让LLM来决定和筛选原始的检索文档中哪些文档是与query相关的需要返回的,也即过滤LLM认为与query不相关的文档,但不改写文档的内容
from langchain.retrievers.document_compressors import LLMChainFilter
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"哪里可以了解高考成绩"
)
compressed_docs
"""
[Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。\n考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。', metadata={'source': './examples/rag.txt'})]
"""
同样的,过滤不相关文档的LLM提示词:
Given the following question and context, return YES if the context is relevant to the question and NO if it isn't.
> Question: {question}
> Context:
>>>
{context}
>>>
> Relevant (YES / NO):
3. DocumentCompressorPipeline
DocumentCompressorPipeline可以实现多种上下文压缩器(compressors)和转换器(transformers)序列的链式调用。
下面代码样例中的compressors-EmbeddingsFilter和transformers-EmbeddingsRedundantFilter都是基于Embedding模型,这样可以不用引入额外的LLM,因为额外的LLM调用其实是昂贵且增加大量耗时的。
- 但是
EmbeddingsFilter貌似比较鸡肋,因为它是基于embeddings相似度阈值进行过滤,这其实向量数据库检索便支持阈值过滤了,这对后面会提及的全文检索才有着重要的作用。 EmbeddingsRedundantFilter则是通过过滤原始的检索文档中高度雷同(相似)的文档,从而实现上下文的压缩
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"哪里可以了解高考成绩"
)
集成检索
类似于机器学习中的集成学习,我们也可以在检索的时候,使用多个检索器,集成它们的结果。而一般是搭配spare retriever(即全文检索)和dense retriever(向量相似度检索),全文检索是基于关键词去搜索相关文档,而向量检索是基于语义相似度,可以互为补充。
下面,我们以BM25作为全文检索器,可以先了解下它的原理:

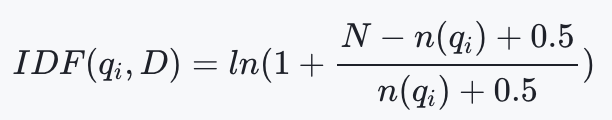
- q i q_i qi是query分词之后的第i个词(term)
- f ( q i , D ) f(q_i,D) f(qi,D)是 q i q_i qi在文档中的出现频率
- ∣ D ∣ |D| ∣D∣是文档的长度,avgdl则是所有文档的平均长度,这里的长度是基于分词之后的词的数量,即term的数量,而不是字符串长度
- I D F ( q i , D ) IDF(q_i,D) IDF(qi,D)是TF-IDF中的一项:逆文档频率,不过BM25的IDF稍有调整。N是文档的总数, n ( q i ) n(q_i) n(qi)是包含 q i q_i qi的文档数量
from langchain_community.retrievers import BM25Retriever
doc_list = [doc.page_content for doc in documents]
bm25_retriever = BM25Retriever.from_texts(
doc_list, metadatas=[{"source": f"BM25"}] * len(doc_list)
)
bm25_retriever.k = 2
from langchain.retrievers import EnsembleRetriever
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.invoke("哪里可以了解高考成绩")
docs
"""
[Document(page_content='十、录取通知书何时能收到?\n高校一般会在录取结束后一周左右向录取新生寄发录取通知书。若考生在省级招生考试机构或高校官方网站上查询到了录取结果,一直没有收到录取通知书,可及时联系录取高校公布的招生咨询电话查询本人录取通知书邮寄情况。', metadata={'source': 'BM25'}),
Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。\n考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。', metadata={'source': './examples/rag.txt'}),
Document(page_content='九、录取工作采用什么方式,一般什么时间开始?\n高校招生实行计算机远程网上录取,各省(区、市)录取工作一般于7月上旬开始,8月底之前结束。', metadata={'source': 'BM25'}),
Document(page_content='2024年高考是黑龙江、甘肃、吉林、安徽、江西、贵州、广西7个省份(中国第四批高考综合改革省份)的第一届落地实施的新高考。 [3]', metadata={'source': './examples/rag.txt'})]
"""
##多向量检索-分块
在检索之前,切分文档的过程中经常存在着这样冲突的需求:
- 希望文档是更短的文本,这样embedding可以更精准的映射它们的语义。过于长的文本,可能会导致embedding丢失重要的语义;
- 检索得到的文档又希望是更长的文本,这样能才能保持完整的上下文。
LangChain提供了这样的思路和实现:
- 将原始文档切分为更小的chunk然后进行embedding
- 记录原始文档与切分后的chunk的映射关系
- 通过向量数据库检索相似的chunk,然后映射回原始文档
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
import uuid
from langchain_text_splitters import RecursiveCharacterTextSplitter
doc_ids = [str(uuid.uuid4()) for _ in documents]
id_key = "doc_id"
# The splitter to use to create smaller chunks
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
sub_docs = []
for i, doc in enumerate(documents):
_id = doc_ids[i]
_sub_docs = child_text_splitter.split_documents([doc])
for _doc in _sub_docs:
_doc.metadata[id_key] = _id
sub_docs.extend(_sub_docs)
len(documents), len(sub_docs)
"""
(15, 70)
"""
vectorstore = FAISS.from_documents(sub_docs, TongyiEmbeddings())
# The storage layer for the parent documents
store = InMemoryByteStore()
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
retriever.docstore.mset(list(zip(doc_ids, documents)))
# Vectorstore alone retrieves the small chunks
retriever.vectorstore.similarity_search("哪里可以了解高考成绩")[0]
"""
Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?', metadata={'source': './examples/rag.txt', 'doc_id': 'd855063c-ad52-4a09-a304-aa9d2b2ebd17'})
"""
# Retriever returns larger chunks
retriever.invoke("哪里可以了解高考成绩")[0]
"""
Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。\n考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。', metadata={'source': './examples/rag.txt'})
"""
不过对于这个过程,LangChain也提供了封装实现:Parent Document Retriever,其实也就是将拆分子文档和建立映射关系封装起来,效果等同于上面的代码。
from langchain.retrievers import ParentDocumentRetriever
from langchain_chroma import Chroma
from langchain.storage import InMemoryStore
# This text splitter is used to create the child documents
child_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
# The vectorstore to use to index the child chunks (empty to start)
# FAISS not supports empty initialzation
vectorstore = Chroma(
collection_name="full_documents", embedding_function=TongyiEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(documents, ids=None)
sub_docs = vectorstore.similarity_search("哪里可以了解高考成绩")
retrieved_docs = retriever.invoke("哪里可以了解高考成绩")
多向量检索-总结
概括总结有时可以对文本块进行精准的压缩,因为剔除了无用信息噪声,这可以带来更好的检索效果。
那么,我们可以使用上一个小节的思路,使用总结的文本块进行embedding和检索,然后再映射还原到本来的文本块。
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatTongyi
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("概括以下内容:\n\n{doc}")
| ChatTongyi(max_retries=0)
| StrOutputParser()
)
summaries = chain.batch(documents, {"max_concurrency": 5})
summaries[:2]
"""
['2024年全国高考是中国的一项重要考试,用于选拔高中毕业生和具备同等学历的考生,2024年的报名人数达到了1342万人,相比上一年增长了51万人。',
'2024年,中国有7个省份(黑龙江、甘肃、吉林、安徽、江西、贵州和广西)将首次实施新的高考制度,作为第四批改革省份。']
"""
doc_ids = [str(uuid.uuid4()) for _ in documents]
id_key = "doc_id"
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
# The vectorstore to use to index the child chunks
vectorstore = FAISS.from_documents(summary_docs, TongyiEmbeddings())
# The storage layer for the parent documents
store = InMemoryByteStore()
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
retriever.docstore.mset(list(zip(doc_ids, documents)))
sub_docs = vectorstore.similarity_search("哪里可以了解高考成绩")
sub_docs[0]
"""
Document(page_content='高考相关信息可以在各省级教育行政部门或招生考试机构的官方网站、微信公众号等权威渠道获取,包括成绩公布时间、查询方式、志愿填报时间、高校招生计划和历年录取参考等。考生和家长需密切关注官方发布的信息。志愿填报至关重要,考生必须遵循省级招生考试机构的规定。教育部已与相关部门合作确保官方渠道的权威性,提醒大家在查询时要识别官方标识,避免相信非官方的不实信息。', metadata={'doc_id': 'd5f6fbc3-3425-4c3e-914a-f10669c9ae53'})
"""
retrieved_docs = retriever.invoke("哪里可以了解高考成绩")
retrieved_docs[0]
"""
Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。\n考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。', metadata={'source': './examples/rag.txt'})
"""
多向量检索-假设问题
有这么一种场景,例如QA系统,用户往往是输入一个问题形式的query,然后去检索相关的回答/答案形式的document。那么,使用常规的处理方法,会导致query和数据库中的documents形式差异较大,embedding可以无法捕获这种问题(query)和回答(document)的语义相关。
那么,既然使用问题形式的query进行检索,那么我们也可以为documents构造合适的假设性问题,为何叫假设性问题,因为这些问题是通过LLM生成的,而不是真实存在的。
from langchain_core.messages import AIMessage
from langchain_core.exceptions import OutputParserException
def custom_parse(ai_message: AIMessage) -> str:
"""Parse the AI message."""
if '\n\n' in ai_message.content:
return ai_message.content.split('\n\n')
elif '\n' in ai_message.content:
return ai_message.content.split('\n')
else:
raise OutputParserException("Badly formed question!")
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("为下面内容生成3个合适的提问问题:\n\n{doc}\n\n#限制\n生成的3个问题使用两个换行符,即```\n\n```符号进行隔开")
| ChatTongyi(max_retries=0)
| custom_parse
)
hypothetical_questions = chain.batch(documents, {"max_concurrency": 5})
hypothetical_questions[0]
"""
['1. 2024年全国高考的全称是什么?',
'2. 与2023年相比,2024年全国高考的报名人数有何变化?',
'3. 能否提供2023年全国高考的报名人数数据作为对比?']
"""
doc_ids = [str(uuid.uuid4()) for _ in documents]
id_key = "doc_id"
question_docs = []
for i, question_list in enumerate(hypothetical_questions):
question_docs.extend(
[Document(page_content=s, metadata={id_key: doc_ids[i]}) for s in question_list]
)
# The vectorstore to use to index the child chunks
vectorstore = FAISS.from_documents(question_docs, TongyiEmbeddings())
# The storage layer for the parent documents
store = InMemoryByteStore()
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
retriever.docstore.mset(list(zip(doc_ids, documents)))
sub_docs = vectorstore.similarity_search("哪里可以了解高考成绩")
sub_docs[0]
"""
Document(page_content='1. 从哪里可以获得高考成绩查询的具体时间和方式,以及志愿填报的详细指导?', metadata={'doc_id': '120780d1-f9f2-4ee4-ac03-d806343878b8'})
"""
retrieved_docs = retriever.invoke("哪里可以了解高考成绩")
retrieved_docs[0]
"""
Document(page_content='一、在哪里可以了解高考成绩、志愿填报时间和方式、各高校招生计划、往年录取参考等志愿填报权威信息?\n各省级教育行政部门或招生考试机构官方网站、微信公众号等权威渠道都会公布今年高考各阶段工作时间安排,包括高考成绩公布时间和查询方式、志愿填报时间,以及今年各高校招生计划、往年录取情况参考等权威信息。考生和家长要及时关注本地官方权威渠道发布的消息内容。\n考生高考志愿是高校录取的重要依据,请广大考生务必按照省级招生考试机构相关要求按时完成志愿填报。前期,教育部已会同有关部门协调互联网平台对省级招生考试机构和高校的官方网站、微信公众号等进行了权威标识,请广大考生在信息查询时认准官方权威渠道,切勿轻信网络不实信息。', metadata={'source': './examples/rag.txt'})
"""
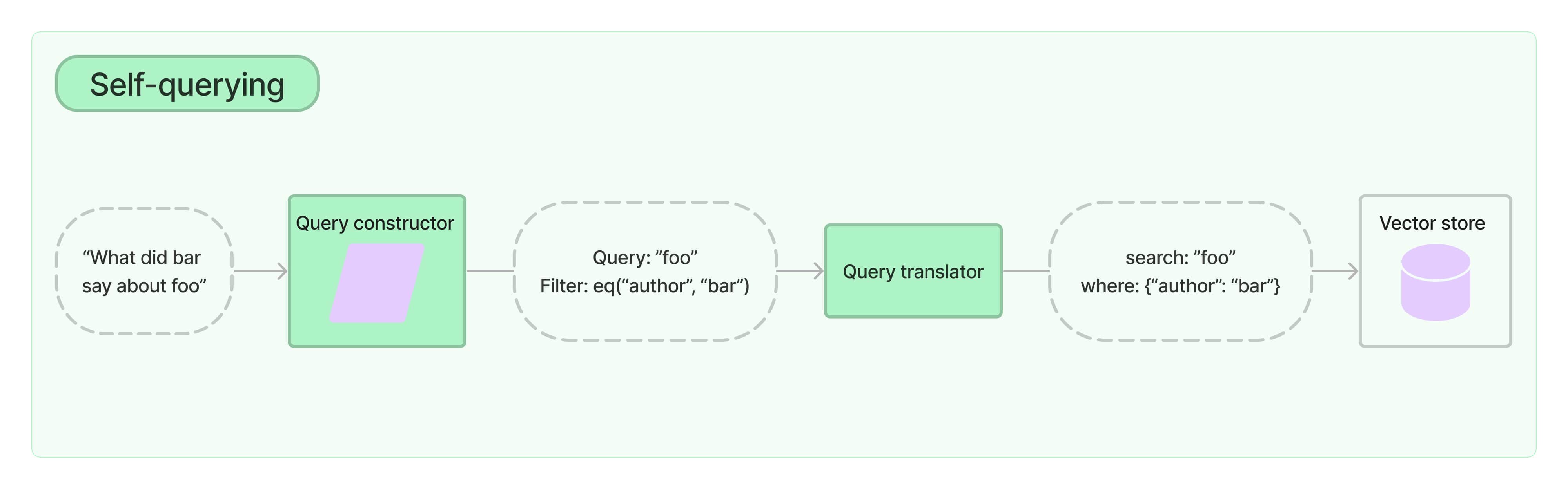
Self-querying检索
self-querying检索,正如它的名字,可以自我查询。具体来讲,给定任何自然语言的query,检索器使用一个查询构造的LLM来生成和解析成结构化的查询语法,然后应用到数据库。如下图所示:
- 这不仅能够让检索器使用用户输入的query与存储的文档进行语义相似比较,还能够从用户输入提取一个过滤器,来对文档的metadata进行筛选。
1. 构造电影类型的文档数据,包含上映年份(year)、评分(rating)、类型(genre)
from langchain_chroma import Chroma
from langchain_core.documents import Document
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,
"director": "Andrei Tarkovsky",
"genre": "thriller",
"rating": 9.9,
},
),
]
vectorstore = Chroma.from_documents(docs, TongyiEmbeddings())
2. 创建self-querying检索器,需要增加文档数据的描述document_content_description和每个metadata字段的描述metadata_field_info
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = ChatTongyi()
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
3. 检索测试
# This example only specifies a filter
retriever.invoke("I want to watch a movie rated higher than 8.5")
"""
[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),
Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})]
"""
4. 实现原理
下面,我们来揭开self-querying检索器的神秘面纱,简单的阐述下它的原理机制。
其中,最重要的是查询构造器query_constructor的LLM chain,即将自然语言的query转化为filter。下一步其实就是直接执行向量数据库检索,只是带上了filter。
from langchain.chains.query_constructor.base import (
StructuredQueryOutputParser,
get_query_constructor_prompt,
)
from langchain.retrievers.self_query.chroma import ChromaTranslator
from langchain_community.chat_models import ChatTongyi
llm = ChatTongyi()
prompt = get_query_constructor_prompt(
document_content_description,
metadata_field_info,
allowed_comparators=ChromaTranslator.allowed_comparators,
allowed_operators=ChromaTranslator.allowed_operators
)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
如上面代码,LLM Chain包含了一个提示词模板,一个llm和一个输出解析器。我们一个一个来。
prompt.format(query="dummy question")
"""
Your goal is to structure the user\'s query to match the request schema provided below.
<< Structured Request Schema >>
When responding use a markdown code snippet with a JSON object formatted in the following schema:
```json
{
"query": string \\ text string to compare to document contents
"filter": string \\ logical condition statement for filtering documents
}
```
The query string should contain only text that is expected to match the contents of documents. Any conditions in the filter should not be mentioned in the query as well.
A logical condition statement is composed of one or more comparison and logical operation statements.
A comparison statement takes the form: `comp(attr, val)`:
- `comp` (eq | ne | gt | gte | lt | lte): comparator
- `attr` (string): name of attribute to apply the comparison to
- `val` (string): is the comparison value
A logical operation statement takes the form `op(statement1, statement2, ...)`:
- `op` (and | or): logical operator
- `statement1`, `statement2`, ... (comparison statements or logical operation statements): one or more statements to apply the operation to
Make sure that you only use the comparators and logical operators listed above and no others.
Make sure that filters only refer to attributes that exist in the data source.
Make sure that filters only use the attributed names with its function names if there are functions applied on them.
Make sure that filters only use format `YYYY-MM-DD` when handling date data typed values.
Make sure that filters take into account the descriptions of attributes and only make comparisons that are feasible given the type of data being stored.
Make sure that filters are only used as needed. If there are no filters that should be applied return "NO_FILTER" for the filter value.
<< Example 1. >>
Data Source:
```json
{
"content": "Lyrics of a song",
"attributes": {
"artist": {
"type": "string",
"description": "Name of the song artist"
},
"length": {
"type": "integer",
"description": "Length of the song in seconds"
},
"genre": {
"type": "string",
"description": "The song genre, one of "pop", "rock" or "rap""
}
}
}
```
User Query:
What are songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre
Structured Request:
```json
{
"query": "teenager love",
"filter": "and(or(eq(\\"artist\\", \\"Taylor Swift\\"), eq(\\"artist\\", \\"Katy Perry\\")), lt(\\"length\\", 180), eq(\\"genre\\", \\"pop\\"))"
}
```
<< Example 2. >>
Data Source:
```json
{
"content": "Lyrics of a song",
"attributes": {
"artist": {
"type": "string",
"description": "Name of the song artist"
},
"length": {
"type": "integer",
"description": "Length of the song in seconds"
},
"genre": {
"type": "string",
"description": "The song genre, one of "pop", "rock" or "rap""
}
}
}
```
User Query:
What are songs that were not published on Spotify
Structured Request:
```json
{
"query": "",
"filter": "NO_FILTER"
}
```
<< Example 3. >>
Data Source:
```json
{
"content": "Brief summary of a movie",
"attributes": {
"genre": {
"description": "The genre of the movie. One of [\'science fiction\', \'comedy\', \'drama\', \'thriller\', \'romance\', \'action\', \'animated\']",
"type": "string"
},
"year": {
"description": "The year the movie was released",
"type": "integer"
},
"director": {
"description": "The name of the movie director",
"type": "string"
},
"rating": {
"description": "A 1-10 rating for the movie",
"type": "float"
}
}
}
```
User Query:
dummy question
Structured Request:
"""
ChromaTranslator.allowed_comparators
"""
[<Comparator.EQ: 'eq'>,
<Comparator.NE: 'ne'>,
<Comparator.GT: 'gt'>,
<Comparator.GTE: 'gte'>,
<Comparator.LT: 'lt'>,
<Comparator.LTE: 'lte'>]
"""
ChromaTranslator.allowed_operators
"""
[<Operator.AND: 'and'>, <Operator.OR: 'or'>]
"""
上述便是LangChain设计的查询构造器的提示词模板,其中我们需要输入对应向量数据库支持的比较操作和逻辑操作。
根据提示词中的examples可以看出,llm的输出应该是类似这样的形式:
and(or(eq("artist", "Taylor Swift"), eq("artist", "Katy Perry")), lt("length", 180), eq("genre", "pop"))
然后再通过输出解析器将它转化为结构化的过滤器:
query_constructor.invoke("I want to watch a movie about dinosaurs rated higher than 8.5")
"""
StructuredQuery(query='dinosaurs', filter=Comparison(comparator=<Comparator.GT: 'gt'>, attribute='rating', value=8.5), limit=None)
"""
应用
讲到这里,铺垫了这么久,最后来一个实际的应用案例。
大模型局限
首先,众所周知,许多大模型包括ChatGPT、文心一言、通义千问等等,由于其训练语料是存在滞后性的,因此,这些大模型对于最新的资讯是无法获知。我们就以最近的2024年高考,来对大模型进行询问:
from langchain_community.chat_models import ChatTongyi
chat = ChatTongyi()
chat.invoke('2024高考报名人数是多少')
"""
AIMessage(content='对不起,我无法提供具体的2024年高考报名人数信息,因为这些数据通常由各省份的教育考试机构或政府部门发布,而且会在高考报名开始前公布。对于这类实时数据,建议你关注当地教育部门或考试院的官方通知,或者在高考报名开始时查询相关公告。', response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'stop', 'request_id': '2cffd503-04a3-96e6-bed6-efd912311105', 'token_usage': {'input_tokens': 16, 'output_tokens': 67, 'total_tokens': 83}}, id='run-293addeb-4aa2-4ea9-b53a-861483c0114c-0')
"""
chat.invoke('2024高考,广东的报名时间是什么时候')
"""
AIMessage(content='高考报名时间每年可能会有所变动,具体以官方发布的通知为准。一般来说,广东省的高考报名时间通常在每年的11月份进行,持续一周左右。建议你关注广东省教育考试院或当地教育局的官方网站,他们会发布最准确的高考报名通知和时间安排。同时,也要注意报名截止日期,不要错过报名时间。', response_metadata={'model_name': 'qwen-turbo', 'finish_reason': 'stop', 'request_id': 'a2e34ac6-4188-9626-a93d-cfea2347401d', 'token_usage': {'input_tokens': 20, 'output_tokens': 74, 'total_tokens': 94}}, id='run-5a200266-3e07-4271-9f7e-a74f4b7156d9-0')
"""
可以看到,对于第一个问题,大模型根本无法问答,只能含糊其辞。第二个问题,也是无法直接回答,而是借鉴了2023年高考。
引入RAG
正如开头便提到的,RAG(Retrieval Augmented Generation,检索增强生成)是在生成过程中,外部的数据会通过检索然后传递给LLM,让LLM能够利用这些新知识作为上下文。
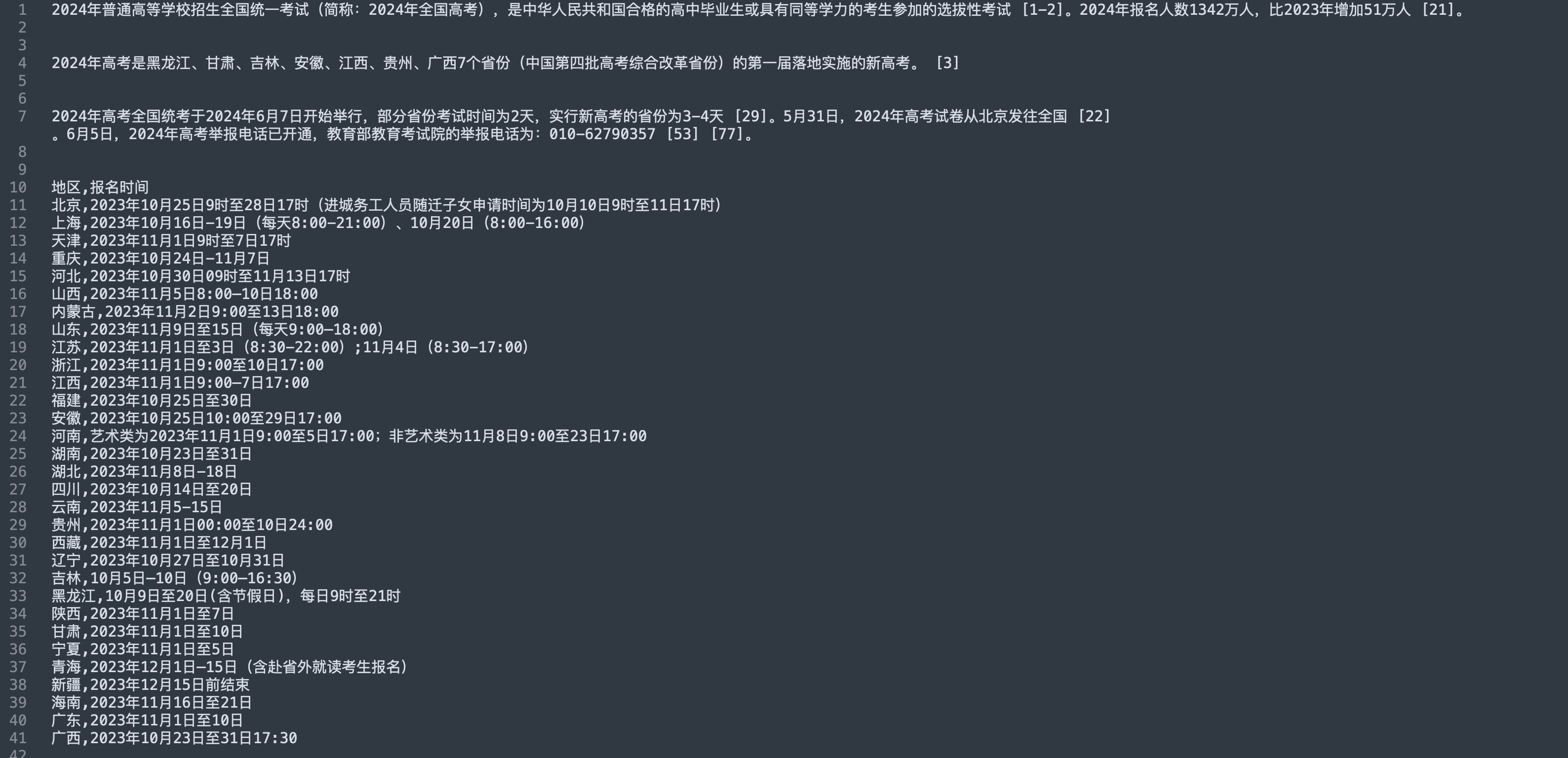
首先,来看看我们关于2024年高考的文档语料:
接着,我们以上述讲解的一个检索器:基于假设问题的多向量检索。对文档构造多个假设性提问,将query去检索相似的假设性提问,并关联到原始的文档,作为LLM提示词的上下文:
(retriever便完全对应上述章节中的多向量检索-假设问题)
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """回答用户的问题,下面的内容可以作为你的知识依据:
```
{context}
```
用户的问题:{query}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
rag_chain = (
{"context": retriever | format_docs, "query": RunnablePassthrough()}
| prompt
| chat
| StrOutputParser()
)
rag_chain.invoke("2024年高考报名人数是多少")
"""
'2024年全国高考的报名人数达到1342万人。'
"""
rag_chain.invoke("2024年高考,广东的报名时间是什么时候")
"""
'2024年广东的高考报名时间是2023年11月1日至10日。'
"""
总结
对于LangChain,我们在项目不一定非得使用,但学习LangChain,可以让我们学习到其中一些巧妙的大模型处理技巧:
- 比如如何解析各式各样的文件数据
- 如何更好得检索相关文档等等
完整代码
llms/langchain_tutorial








![[每周一更]-(第104期):Go中使用Makefile的经验](https://i-blog.csdnimg.cn/direct/d5f01334a4f94f9e840e6682d61c4dad.jpeg#pic_center)






