目录
- 一、头文件
- **1、mex.h**
- **2、matrix.h**
- **3、string**
- **4、iostream**
- **5、omp.h**
- 6、cuda_runtime.h
- 7、stdlib.h
- 8、sys/time.h
- 9、stdio.h
- 10、string.h
- 11、time.h
- 12、math.h
- 13、device_launch_parameters.h
- 二、一些声明语句
- 1、using namespace std
- **2、typedef unsigned char byte**
- **3、enum**
- **4、template**
- **5、CUDA程序中函数的前缀**
- **6、threadIdx、blockIdx、blockDim和gridDim**
- **7、make_int2**
- **8、__double2loint、__double2hiint**
- **9、thrust::device_vector**
- **10、const int**
- **11、resize**
- **12、dim3**
- **13、.clear()**
- **14、isNormalized**
- **15、cudaCreateChannelDesc**
- **16、cudaMalloc3DArray**
- **17、cudaMemcpy3DParms**
- **18、cudaMalloc**
- **19、cudaMemcpy**
- 20、bool success = true
- 21、size_t类型
- 22、uchar4类型
- 23、计时方式 CLOCKS_PER_SEC
- 三、一些二常用语句
- 1、__syncthreads()
- 2、srand((unsigned)time(NULL))
- 3、cudaThreadSynchronize();
- 4、system("pause");
- 5、主函数int main(int argc, char** argv)
一、头文件
1、mex.h
#include "mex.h"
如果想在Matlab中,以Matlab函数的方式调用C程序,那就要用到MEX文件
2、matrix.h
#include "matrix.h"
这个类数据类型是double,包含了常用的矩阵计算
3、string
里面是一些字符串处理函数,注意这个string与string.h完全是两个文件,之间没有关联,这样定义是因为C中已有一个string.h的库文件,而C++是需要兼容C中的库,所以用另外一种特殊方式导入这个文件:
#include <string>
4、iostream
#include <iostream>
iostream 的意思是输入输出流。#include是标准的C++头文件,任何符合标准的C++开发环境都有这个头文件。
同时,还有一个iostream.h文件,它是input output stream的简写,意思为标准的输入输出流头文件。它包含:
(1)cin>>“要输入的内容”
(2)cout<<“要输出的内容”
这两个输入输出的方法需要#include<iostream.h>来声明头文件。
iostream.h与iostream是不同的。#include<iostream.h>是在旧的标准C++中使用。在新标准中,用#include。
5、omp.h
#include "omp.h"
OpenMP编译必须包含头文件<omp.h>.
OpenMP是用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive) 。
6、cuda_runtime.h
CUDA 目前有两种不同的 API:Runtime API 和 Driver API,两种 API 各有其适用的范围。由于 runtime API 较容易使用,一开始我们会以 runetime API 为主。
cuda_runtime.h头文件一般就是Runtime API中,运行时的API和其参数的定义。(如果使用Driver API,驱动API则头文件使用cuda.h)。
7、stdlib.h
stdlib.h头文件即standard library标准库头文件。里面定义了五种类型、一些宏和通用工具函数。
类型例如:size_t、wchar_t、div_t、ldiv_t和lldiv_t;
宏例如:EXIT_FAILURE、EXIT_SUCCESS、RAND_MAX和MB_CUR_MAX等等;
常用函数如:malloc()、calloc()、realloc()、free()、system()、atoi()、atol()、rand()、srand()、exit()等等。
8、sys/time.h
sys/time.h 是Linux系统的日期头文件。 但sys/time.h 通常会包含include “time.h”。
9、stdio.h
stdio 就是指 “standard input & output"(标准输入输出),所以,源代码中如用到标准输入输出函数时,就要包含这个头文件!例如c语言中的 printf(“%d”,i); scanf(“%d”,&i);等函数。
10、string.h
在使用到字符数组时需要使用。string .h 头文件定义了一个变量类型、一个宏和各种操作字符数组的函数。
11、time.h
事件相关的头文件
12、math.h
数学计算相关函数的头文件,例如:绝对值、取整和取余、三角函数、反三角函数、双曲三角函数、指数和对数、标准化浮点数、多项式、数学错误计算处理等等。
13、device_launch_parameters.h
要使用threadIdx、blockIdx、blockDim等内置变量时要在头文件里导入device_launch_parameters.h
14、
二、一些声明语句
1、using namespace std
namespace:是指标识符的各种可见范围。是C++语言特别重要的特性,当使用第三方供应商提供的库时,为了避免与其他供应商或者用户定义的名字相冲突(命名空间污染),常常将库的内容放置在自己独立的命名空间中。
std:就是C++标准程序库中定义所有标识符的namespace。
详细解释 参考文章
2、typedef unsigned char byte
typedef unsigned char byte;
在这个说明以后就可以在程序中用BYTE 代替unsigned char了,只是为了编写代码方便而已!因为typedef是变量类型定义命令,这句话的意思就是将unsigned char类型重新定义为byte,相当于为了简便重新给变量的这种类型命名。
在C/C++中char 表示一个字符变量,占8位,但是可以解释为int型的整数。unsigned char表示 0~255 的整数或者对应的字符。
3、enum
enum是计算机编程语言中的一种数据类型----枚举类型。在实际编程中,有些数据的取值往往是有限的,比如一个星期内只有七天,一年只有十二个月,一个班每周有六门课程等等;并为每个值取一个名字,方便在以后的代码中使用,具体语句格式为:
enum typeName{ valueName1, valueName2, valueName3, ...... };
enum是一个新的关键字,专门用来定义枚举类型,这也是它在C语言中的唯一用途;typeName是枚举类型的名字;valueName1, valueName2, valueName3, …是每个值对应的名字的列表。注意最后的分号;不能少。
应用示例代码:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}
具体用法传送门
4、template
定义函数模板或者类模板。假如我们需要写一个简单的交换函数,但对于C++来说,只能做同数据类型的转换,这时我们就需要针对不同类型之间的交换分别写一个函数,十分麻烦。template就是解决这个问题的,他会告诉系统a是Int型,而b也是int型的。下面是定义方式和调用方式,这种调用swap的方式就是隐式调用方式,可以看到不同类型的值可以统一用这一个函数了,不用单独定义不同类型时的函数。
//声明时这样
template<typename T>
void Swap(T *a, T *b)
{
T temp = *a;
*a = *b;
*b = temp;
}
//调用时这样
int a=10,b=20;
float c=30,d=40;
swap(&a,&b);
swap(&c,&d);
具体用法传送门
5、CUDA程序中函数的前缀
这些函数前缀在官方的文档里被称为函数执行环境标识符Function execution space specifiers,也就是他指明了这段函数是在哪里被调用的。
__global__
这个前缀修饰的函数是核函数,这些函数 在GPU上执行 ,但是需要 在CPU端调用。
注意:
(1)修饰的函数必须采用void返回值,并且需要在调用时制定运行的参数 (也就是<<<>>>里的block数和线程数);
(2)任何对__global__函数的调用都必须指定该调用的执行配置。执行配置定义将用于在该设备上执行函数的网格和块的维度,以及相关的流。
(3)函数是异步的,这也代表着函数没被执行完就返回了控制权,所以测量核函数的时间需要同步操作才能获得准确的结果。
代码示例:
naive_copyToTwoVolumes << <gid, blk >> >(函数的输入参数)
其中,尖括号作用为线程配置,gid类型若为dim3,指定网格的维度和大小,gid.x * gid.y * gid.z 等于所启动的块数量;blk的类型若为 dim3,指定各块的维度和大小,Db.x * Db.y * Db.z 等于各块的线程数量;这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码。传递给设备代码本身的参数是放在圆括号中传递的。
6、threadIdx、blockIdx、blockDim和gridDim
threadIdx //uint3类型,表示一个线程的索引。
blockIdx //uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim //dim3类型,表示线程块的大小。
gridDim //dim3类型,表示网格的大小,一个网格中通常有多个线程块。
以上涉及到线程、线程块、线程格的知识,下面是它们之间关系的示意图。grid表示线程格,一个线程格内包含许多block线程块,而一个线程块内又包含许多线程thread,其中线程块和线程都可以是一维、二维或三维的。
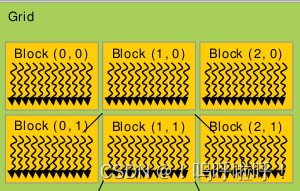
若线程格和线程块都是三维矩阵。这里假设线程格是一个3×4×5的三维矩阵, 线程块是一个4×5×6的三维矩阵,则有:
(1)gridDim
gridDim.x、gridDim.y、gridDim.z分别表示线程格各个维度的大小:
gridDim.x=3
gridDim.y=4
gridDim.z=5
(2)blockDim
blockDim.x、blockDim.y、blockDim.z分别表示线程块中各个维度的大小:
blockDim.x=4
blockDim.y=5
blockDim.z=6
(3)blockIdx
blockIdx.x、blockIdx.y、blockIdx.z分别表示当前线程块所处的线程格的坐标位置
(4)threadIdx
threadIdx.x、threadIdx.y、threadIdx.z分别表示当前线程所处的线程块的坐标位置
通过 blockIdx.x、blockIdx.y、blockIdx.z、threadIdx.x、threadIdx.y、threadIdx.z就可以完全定位一个线程的坐标位置了。
一般的线程索引方式:
int idz = threadIdx.x + blockIdx.x * blockDim.x;
假如现在我们想得到第6个block中第五个线程,则根据定义式有idz=5+6*8,threadIdx.x线程id为5(0开始),blockIdx.x块id为6,blockDim.x表示块的维度,即一共有8个线程块。
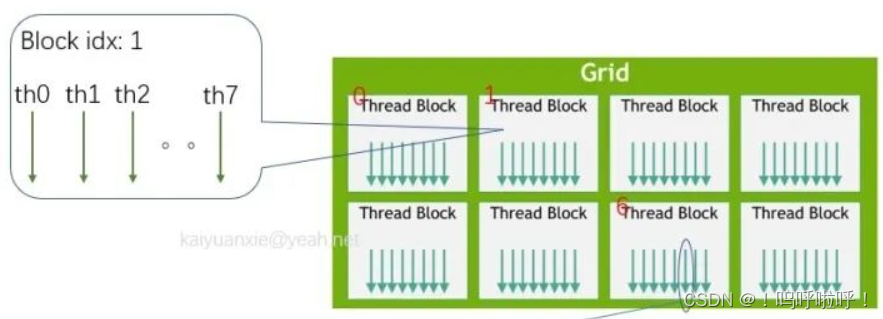
若定义的线程是三维的,则继续定义其他方向有:
int idx = threadIdx.y + blockIdx.y * blockDim.y;
int idy = threadIdx.z + blockIdx.z * blockDim.z;
如果不好理解可以看下图三维grig、block的示意图

三维grig、block的示意图
7、make_int2
内置的矢量类型:
char, short, int, long, longlong, float, double:
这些是从基本整数和浮点类型派生的矢量类型。 它们是结构,第一,第二,第三和第四个组件分别可以通过字段x,y,z和w访问。 它们都带有一个构造函数,形式为make_ 。
例如:
int2 make int2(int x, int y);
这条语句将创建一个类型为int2 的向量,值为(x, y).
8、__double2loint、__double2hiint
__double2loint()返回一个double的低32位
__double2hiint()返回一个double的高32位
9、thrust::device_vector
Trust 提供了两个vector容器:host_vector 与 device_vector。按照命名规则,host_vector位于主机端,device_vector位于GPU设备端。Trust的vector容器与STL中的容器类似,是通用的容器,可以存储任何数据类型,可以动态调整大小。
代码示例:
thrust::device_vector<float>& ZXY
其中,thrust::告诉编译器在thrust命名空间中查找函数与类;device_vector表示使用的容器位于GPU设备端;定义的容器类型是float;容器中存放的是ZXY的地址。
10、const int
const int表示定义一个常量,const int与int不同的点有:
(1)const int类型一旦定义以后就不能修改,int类型是随时可以修改的。
(2)const int 定义的常量不能在其他地方被重新赋值了
例如:const int Max=100; Max++会产生错误;
(3)const int & 是返回这个数值的一个常量的引用,而int 是返回这个数值的一个拷贝。
另外const和int先后顺序可换,即const int=int const。
更多知识点传送门
11、resize
resize(),设置大小(size);
例子:
const int nsiz_ZXY = (ZN + 1) * (XN + 1) * YN;
ZXY.resize(nsiz_ZXY);
该段代码先定义了常量整数nsiz_ZXY,取nsiz_ZXY的大小对容器ZXY的大小进行设置。
扩展传送门
12、dim3
封装三维数组,例如下面代码行:
dim3 blk(64, 16, 1);
定义了一个名为blk的数组,数组大小为64×16×1。
13、.clear()
代码示例:
thrust::device_vector<float> vol(hvol, hvol + siz);
vol.clear();
其中vol为一个容器,第二行代码clear()表示清楚其中数据,但容器整体结构并未改变。
14、isNormalized
判断是否符合特定的 Unicode 范式。
示例表示判断bool是否符合特定的 Unicode 范式
bool isNormalized
15、cudaCreateChannelDesc
作用是在设备内存中分配CUDA数组。该函数有一个独立的C和c++ API (c++ API被重载)。
官方使用格式:
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
尖括号内为数组数据类型,小括号内为分配数组是所需要的参数,channelDesc为分配的数组名称;
cudaCreateChannelDesc函数的内部结构:
struct cudaChannelFormatDesc {
int x, y, z, w;
enum cudaChannelFormatKind f;
};
__host__cudaChannelFormatDesc cudaCreateChannelDesc ( int x, int y, int z, int w, cudaChannelFormatKind f )
cudaChannelFormatDesc应该是CUDA频道格式设置的意思,cudaCreateChannelDesc是具体格式设置函数,cudaChannelFormatKind f为设置的数组类型,类型有以下几种:
cudaChannelFormatKindSigned = 0
Signed channel format (有符号型)
cudaChannelFormatKindUnsigned = 1
Unsigned channel format (无符号型)
cudaChannelFormatKindFloat = 2
Float channel format (浮点型)
cudaChannelFormatKindNone = 3
No channel format (无格式)
其他的四个参数x,y,z,w,对于C API函数,这些是每个通道的比特数。这些可以是颜色通道、空间维度或者任何你想用的东西。从cuda文档中,“返回格式为f的通道描述符,以及每个组件x、y、z和w的比特数。”
示例代码:
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<T>();
表示在CUDA内存中分配数组T
16、cudaMalloc3DArray
cudaMalloc3DArray //CUDA数组的分配。
(
struct cudaArray ** array,
const struct cudaChannelFormatDesc * desc,
struct cudaExtent extent,
unsigned int flags = 0
)
参数:
array - 指向设备内存中已分配数组的指针
desc - 请求通道格式
extent - 请求的分配大小(元素中的宽度字段)
flags - 扩展的标志(目前必须为0)
CUDA数组是使用cudaMallocArray()、cudaMalloc3DArray()分配的,使用cudaFreeArray()释放。
cudaMalloc3DArray(宽度,高度,深度) 能够分配1D、2D或3D数组,例如:
如果高度和深度范围都为零,则分配一个1D数组。对于1D数组,有效的范围是{(1,8192),0,0}。同理若
如果只有深度范围为零,则分配2D数组。对于2D数组,有效的范围是{(1,65536),(1,32768),0}。
3D为:{(1, 2048), (1, 2048), (1, 2048)}。
17、cudaMemcpy3DParms
CUDA 3D内存拷贝参数
18、cudaMalloc
在GPU内分配内存,这个函数与CPU中的malloc相似,可以先理解malloc的作用,malloc用法为:
int *a = (int )malloc(nsizeof(int)),返回的是一个int型指针,指向大小为n个int型数据的连续内存地址的首地址,可以理解为a是这个数组的首地址。
cudaMalloc也是十分相似的作用,例如cudaMalloc(float(**)&addr,n*sizeof(float)),意思是在GPU内申明一段n个大小的float型数组,addr这个变量中存的就是用户在GPU中声明的float型数组的首地址。
19、cudaMemcpy
用于在主机(Host)和设备(Device)之间往返的传递数据,使用方式:
主机到设备:cudaMemcpy(d_A,h_A,nBytes,cudaMemcpyHostToDevice)
设备到主机:cudaMemcpy(h_A,d_A,nBytes,cudaMemcpyDeviceToHost)
改行代码表示从h_A存储区中复制nBytes个字节到d_A中。
可以根据最后一个参数看出,源指针和目标指针分别是设备指针-主机指针、主机指针-设备指针。
注意:该函数是同步执行函数,在未完成数据的转移操作之前会锁死并一直占有CPU进程的控制权
20、bool success = true
定义一个布尔型变量flag并初始化为真(true)。
代码示例:
bool success = true;
if (succes) printf("balabala");
21、size_t类型
size_t是标准C库中定义的,它是一个基本的与机器相关的无符号整数的C/C + +类型, 它是sizeof操作符返回的结果类型,该类型的大小可选择。
22、uchar4类型
uchar4是在图形交互时使用的一种数据类型
23、计时方式 CLOCKS_PER_SEC
程序示例:
t1 = clock();
t2 = clock();
time = (double)(t2 - t1) / CLOCKS_PER_SEC;
为什么要用时间差除以CLOCKS_PER_SEC呢?
这个CLOCKS_PER_SEC是VC++6.0中time.h下宏定义的常量。其值为1000。它用来表示一秒钟会有多少个时钟计时单元。也就是说clock()将返回时钟周期,CLOCKS_PER_SEC表示一秒钟有多少个时钟周期,两者相除就得到这段时钟周期经历了多少秒钟。
三、一些二常用语句
1、__syncthreads()
__syncthreads()是cuda的内建函数,用于块内线程通信。
参考:https://blog.csdn.net/jyl1999xxxx/article/details/68950846
2、srand((unsigned)time(NULL))
如果想在一个程序中生成随机数序列,需要至多在生成随机数之前设置一次随机种子。 即:只需在主程序开始处调用srand((unsigned)time(NULL)); 后面直接用rand就可以了。不要在for等循环放置srand((unsigned)time(NULL));
参考文章
3、cudaThreadSynchronize();
块内通信:通过共享内存进行通信,块内每个线程都能访问共享存储器,不同块的线程不能通信。
__syncthreads(); 当某个线程执行到该函数时,进入等待状态,直到同一线程块(Block)中所有线程都执行到这个函数为止,即一个__syncthreads()相当于一个线程同步点,确保一个Block中所有线程都达到同步,然后线程进入运行状态。
调用 cudaThreadSynchronize()函数,会使cpu处于等待状态,等待所有的线程都执行完毕.但是,cudaThreadSynchronize()函数并不能在kernel中使用。因为CUDA API和host代码是异步的,cudaDeviceSynchronize可以用来停住CPU并等待CUDA中的操作完成。
也就是说cudaThreadSynchronize()是用来同步线程的,而cudaDeviceSynchronize是用来同步整个设备代码的。
参考网页
4、system(“pause”);
在编写的c++程序中,如果是窗口,有时会一闪就消失了,如果不想让其消失,在程序中添加:
system(“pause”);
注意:不要再return 的语句之后加,那样就执行不到了。
5、主函数int main(int argc, char** argv)
基本是固定写法,下面是具体含义,了解即可。
int argc
这个参数用来表示你在命令行下输入命令的时候,一共有多少个参数。比方说你的程序编译后,可执行文件是test.exe,若执行命令D:\tc2>test
这个时候,argc的值是1;
但是,若执行的命令是D:\tc2>test.exe myarg1 myarg2
argc的值是3。也就是一个命令名再加上两个参数,一共三个参数。
char argv[]
这个参数用来取得你所输入的参数
D:\tc2>test,这个时候,argc的值是1,argv[0]的值是 “test”
D:\tc2>test myarg1 myarg2,这个时候,argc的值是3,argc[0]的值是”test”,argc[1]的值是”myarg1”,argc[2]的值是”myarg2”。
6、