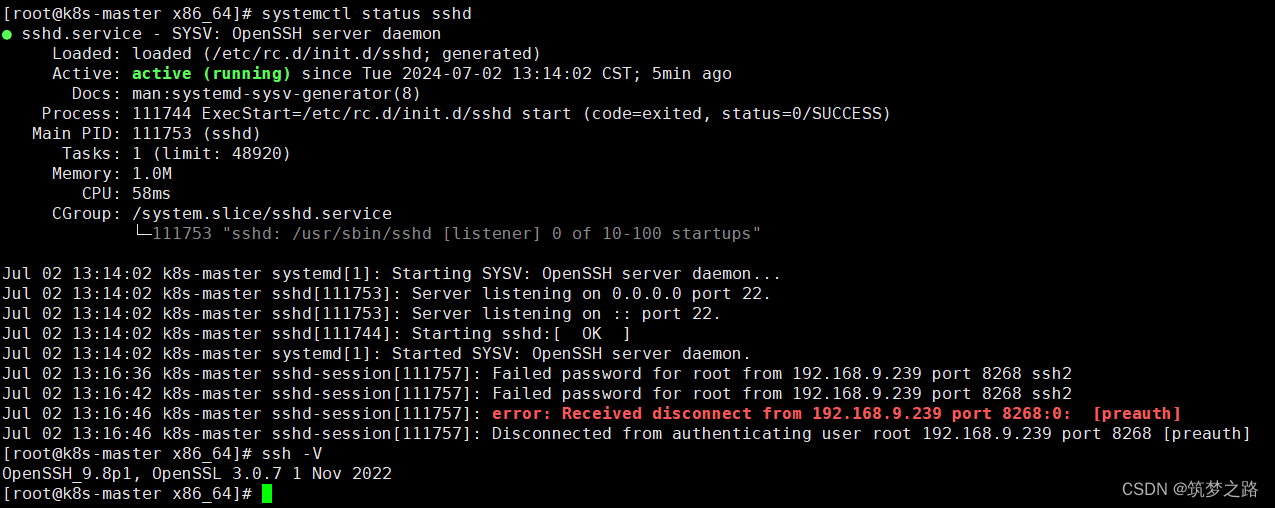
整体框架。不直接生成视频帧,而是在潜在空间中生成整体面部动态和头部运动,条件是音频和其他信号。给定这些运动潜在编码,通过面部解码器生成视频帧,还接受从输入图像中提取的外观和身份特征作为输入。
构建了一个面部潜在空间并训练面部编码器和解码器。
我们设计并训练了一个具有表现力和可分离特征的面部潜在学习框架,该框架基于真实面部视频。然后,训练一个扩散变换器,用于建模运动分布,并在测试时根据音频和其他条件生成运动潜在编码。
整体框架。不直接生成视频帧,而是在潜在空间中生成整体面部动态和头部运动,条件是音频和其他信号。给定这些运动潜在编码,通过面部解码器生成视频帧,还接受从输入图像中提取的外观和身份特征作为输入。
构建了一个面部潜在空间并训练面部编码器和解码器。
我们设计并训练了一个具有表现力和可分离特征的面部潜在学习框架,该框架基于真实面部视频。然后,训练一个扩散变换器,用于建模运动分布,并在测试时根据音频和其他条件生成运动潜在编码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1898337.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!