结构体入门
编写程序,用struct分别表示平面上的点和平面上的矩形。
#include <stdio.h>
int main() {
struct point {int x; int y;};
struct point p1 = {1, 2};
printf(“(%d, %d)\n”, p1.x, p1.y);
struct rectangle {
struct point p1;
struct point p2;
};
struct rectangle square = {{1, 2}, {3, 4}};
printf("p1 = (%d, %d), p2 = (%d, %d)\n", square.p1.x, square.p1.y, square.p2.x, square.p2.y);
}
结构体和函数
在C语言中,结构体和函数可以结合使用,以便更好地组织和管理数据和操作。
结构体与函数的结合使用
传递结构体给函数
你可以将结构体作为参数传递给函数,有两种方式:传值和传引用(通过指针)。
传值
#include <stdio.h>
struct Point {
int x;
int y;
};
void printPoint(struct Point p) {
printf("Point: (%d, %d)\n", p.x, p.y);
}
int main() {
struct Point p1 = {10, 20};
printPoint(p1);
return 0;
}
在这种方式中,结构体的值被复制到函数参数中,函数内的修改不会影响原始结构体。
传引用(指针)
#include <stdio.h>
struct Point {
int x;
int y;
};
void movePoint(struct Point *p, int dx, int dy) {
p->x += dx;
p->y += dy;
}
int main() {
struct Point p1 = {10, 20};
movePoint(&p1, 5, -5);
printf("Moved Point: (%d, %d)\n", p1.x, p1.y);
return 0;
}
在这种方式中,传递的是结构体的指针,函数内的修改会影响原始结构体。
使用结构体和函数的完整示例
#include <stdio.h>
// 定义结构体
struct Rectangle {
int width;
int height;
};
// 计算面积的函数
int area(struct Rectangle r) {
return r.width * r.height;
}
// 计算周长的函数
int perimeter(struct Rectangle *r) {
return 2 * (r->width + r->height);
}
int main() {
struct Rectangle rect = {10, 20};
printf("Area: %d\n", area(rect));
printf("Perimeter: %d\n", perimeter(&rect));
return 0;
}
结构体数组
考虑编写一个程序来统计每个 C 关键字的出现次数。我们需要一个字符字符串数组来存储关键字的名称,并且需要一个整数数组来存储计数。一个可能的方案是使用两个并行数组,keyword 和 keycount,如下所示:
char *keyword[NKEYS];
int keycount[NKEYS];
但是,数组是并行的这一事实暗示了一种不同的组织方式,即结构体数组。每个关键字是一对:
char *word;
int count;
并且这是一个包含若干对的数组。结构体声明如下:
struct key {
char *word;
int count;
} keytab[NKEYS];
这段代码声明了一个结构体类型 key,定义了一个 keytab 结构体数组,并为这些结构体分配了存储空间。数组的每个元素都是一个结构体。这也可以写成:
struct key {
char *word;
int count;
};
struct key keytab[NKEYS];
由于结构体 keytab 包含了一组固定的名称,所以将其设为外部变量并在定义时初始化一次是最简单的做法。结构体的初始化类似于之前的初始化 - 定义之后紧跟着用大括号括起来的初始化列表:
struct key {
char *word;
int count;
} keytab[] = {
"auto", 0,
"break", 0,
"case", 0,
"char", 0,
"const", 0,
"continue", 0,
"default", 0,
/* ... */
"unsigned", 0,
"void", 0,
"volatile", 0,
"while", 0
};
实现
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#define MAXWORD 100
#define NKEYS (sizeof(keytab) / sizeof(keytab[0])) // Calculate the number of keywords
struct key {
char *word;
int count;
} keytab[] = {
{"auto", 0}, {"break", 0}, {"case", 0}, {"char", 0}, {"const", 0},
{"continue", 0}, {"default", 0}, {"unsigned", 0}, {"void", 0},
{"volatile", 0}, {"while", 0}
};
int getword(char *, int);
int binsearch(char *, struct key *, int);
/* count C keywords */
int main() {
int n;
char word[MAXWORD];
// Read words until end of file
while (getword(word, MAXWORD) > 0) {
if (isalpha(word[0])) {
// If the word is a keyword, increment its count
if ((n = binsearch(word, keytab, NKEYS)) >= 0) {
keytab[n].count++;
}
}
}
// Print all keywords that were found
for (n = 0; n < NKEYS; n++) {
if (keytab[n].count > 0) {
printf("%4d %s\n", keytab[n].count, keytab[n].word);
}
}
return 0;
}
/* binsearch: find word in tab[0]...tab[n-1] */
int binsearch(char *word, struct key tab[], int n) {
int cond;
int low, high, mid;
low = 0;
high = n - 1;
// Perform binary search
while (low <= high) {
mid = (low + high) / 2;
if ((cond = strcmp(word, tab[mid].word)) < 0) {
high = mid - 1;
} else if (cond > 0) {
low = mid + 1;
} else {
return mid;
}
}
return -1;
}
int getword(char *s, int lim) {
int i;
for (i = 0; i < lim && (*s = getchar()) != EOF && !isblank(*s); s++, i++)
;
*s = '\0';
return i;
}
结构体指针
用指针的方式重写上面的程序。
#include <stdio.h> // 标准输入输出头文件
#include <ctype.h> // 字符处理函数头文件
#include <string.h> // 字符串处理函数头文件
#define MAXWORD 100 // 定义最大单词长度为100
// 函数声明
int getword(char *, int);
struct key *binsearch(char *, struct key *, int);
// 主函数,统计C语言关键字,指针版本
int main() {
char word[MAXWORD]; // 用于存储单词的字符数组
struct key *p; // 指向关键字表的指针
// 获取单词并检查是否为字母开头
while (getword(word, MAXWORD) != EOF) {
if (isalpha(word[0])) {
// 在关键字表中查找单词
if ((p = binsearch(word, keytab, NKEYS)) != NULL) {
p->count++; // 如果找到则计数加1
}
}
}
// 输出关键字出现的次数
for (p = keytab; p < keytab + NKEYS; p++) {
if (p->count > 0) {
printf("%4d %s\n", p->count, p->word);
}
}
return 0; // 返回0表示程序正常结束
}
/*
* binsearch: 在tab[0]...tab[n-1]中查找单词
*/
struct key *binsearch(char *word, struct key *tab, int n) {
int cond; // 比较结果
struct key *low = &tab[0]; // 指向表首的指针
struct key *high = &tab[n]; // 指向表尾后一个元素的指针
struct key *mid; // 中间元素的指针
// 二分查找算法
while (low < high) {
mid = low + (high - low) / 2; // 计算中间位置
if ((cond = strcmp(word, mid->word)) < 0) {
high = mid; // 在低半区查找
} else if (cond > 0) {
low = mid + 1; // 在高半区查找
} else {
return mid; // 找到单词,返回指针
}
}
return NULL; // 未找到单词,返回NULL
}
自引用结构体
假设我们想处理一个更一般的问题,即统计某些输入中所有单词的出现次数。由于单词列表事先未知,我们不能方便地对其进行排序并使用二分查找。然而,我们也不能对每个到来的单词进行线性搜索,以查看它是否已经出现过;这样程序的运行时间会太长。(更准确地说,其运行时间可能会随着输入单词数量的增加而成二次方增长。)我们如何组织数据以有效地处理任意单词列表呢?
一种解决方案是始终保持已见单词的集合按顺序排列,将每个单词按其到达的顺序放入其适当位置。但这不应通过在线性数组中移动单词来完成,这同样会耗费太多时间。相反,我们将使用一种称为二叉树的数据结构。树包含每个不同单词的一个“节点”;每个节点包含:
- 指向单词文本的指针,
- 出现次数的计数,
- 指向左子节点的指针,
- 指向右子节点的指针。
任何节点都不能有超过两个子节点;它可能只有零个或一个子节点。节点的维护方式是,使得在任何节点处,左子树仅包含按字典顺序小于该节点单词的单词,而右子树仅包含按字典顺序大于该节点单词的单词。以下是通过逐个插入遇到的单词构建的句子“now is the time for all good men to come to the aid of their party”的树结构。
具体解释
在这个例子中,二叉树的数据结构被用来保持单词的顺序并高效地统计它们的出现次数。以下是一些关键点:
-
插入操作:
- 每次插入一个新单词时,比较新单词与当前节点的单词。
- 如果新单词小于当前节点的单词,则移至左子树继续比较。
- 如果新单词大于当前节点的单词,则移至右子树继续比较。
- 如果新单词等于当前节点的单词,则增加该节点的计数。
-
二叉树的优势:
- 保持动态排序:新单词可以快速插入到适当位置,而不需要移动其他元素。
- 查找效率:二叉树的结构使得查找操作在平均情况下可以在对数时间内完成(O(log n)),大大优于线性查找的O(n)时间复杂度。
举例
对于句子“now is the time for all good men to come to the aid of their party”,我们依次插入每个单词,构建的二叉树如下:
- 第一个单词“now”成为根节点。
- 第二个单词“is”小于“now”,插入左子树。
- 第三个单词“the”大于“now”,插入右子树。
- 依此类推,构建整个树结构。
二叉树示意图
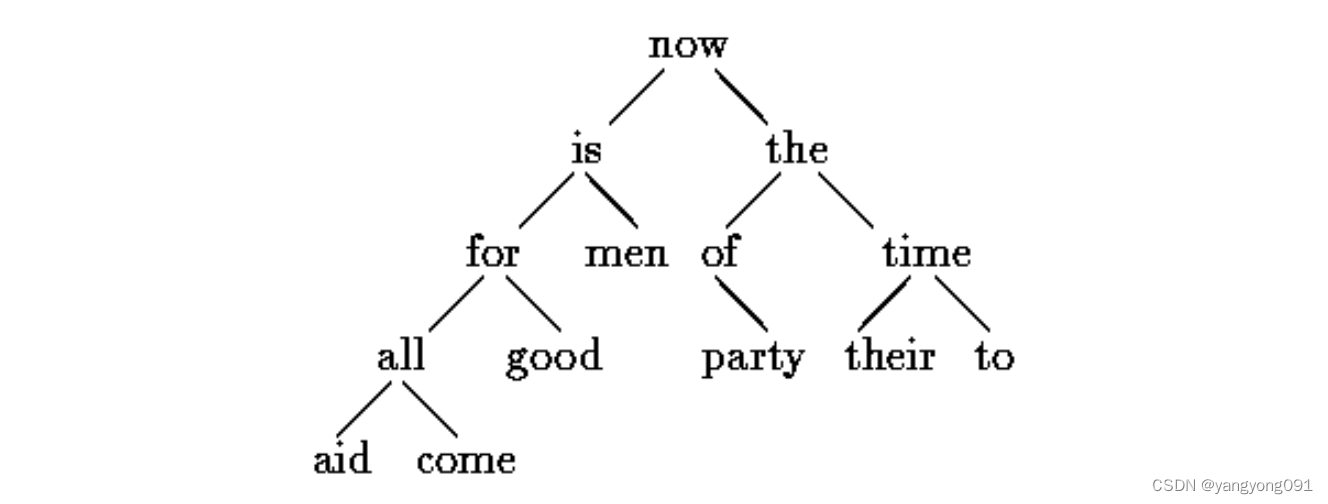
这个示意图展示了单词按插入顺序构建的二叉树结构,每个节点按上述规则插入。
实现
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
int getword(char *, int);
// struct tnode *talloc(void);
struct tnode {
char *word;
int count;
struct tnode *left;
struct tnode *right;
};
// 函数声明
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
int getword(char *, int);
/*
* 主函数,统计单词频率
*/
int main() {
struct tnode *root; // 根节点指针
char word[MAXWORD]; // 存储单词的字符数组
root = NULL; // 初始化根节点为空
// 获取单词并检查是否为字母开头
while (getword(word, MAXWORD) > 0) {
if (isalpha(word[0])) {
root = addtree(root, word); // 添加单词到二叉树
}
}
printf("%s\n", root->word);
treeprint(root); // 打印二叉树中的单词及其频率
return 0; // 返回0表示程序正常结束
}
int getword(char *s, int lim) {
int i;
for (i = 0; i < lim && (*s = getchar()) != EOF && !isblank(*s); s++, i++)
;
*s = '\0';
return i;
}
#include <stdlib.h> // 标准库,包含 malloc 和相关函数
// 函数声明
struct tnode *talloc(void);
char *strdup(char *);
/*
* addtree: 在节点 p 及其以下位置添加一个包含单词 w 的节点
*/
struct tnode *addtree(struct tnode *p, char *w) {
int cond;
if (p == NULL) { // 如果节点为空,说明新单词到达
p = talloc(); // 创建一个新节点
p->word = strdup(w); // 复制单词到新节点
p->count = 1; // 初始化计数为 1
p->left = p->right = NULL; // 左右子节点设为空
} else if ((cond = strcmp(w, p->word)) == 0) {
p->count++; // 如果单词已存在,计数递增
} else if (cond < 0) {
p->left = addtree(p->left, w); // 如果小于当前节点单词,递归添加到左子树
} else {
p->right = addtree(p->right, w); // 如果大于当前节点单词,递归添加到右子树
}
return p; // 返回节点指针
}
/*
* talloc: 分配一个 tnode 节点的空间
*/
struct tnode *talloc(void) {
return (struct tnode *) malloc(sizeof(struct tnode)); // 分配内存并转换为 tnode 指针
}
/*
* strdup: 复制字符串 s
*/
char *strdup(char *s) {
char *p;
p = (char *) malloc(strlen(s) + 1); // 为字符串分配空间,+1 用于 '\0' 终止符
if (p != NULL)
strcpy(p, s); // 复制字符串到分配的空间
return p; // 返回指向新字符串的指针
}
/*
* treeprint: 以中序遍历方式打印树 p
*/
void treeprint(struct tnode *p) {
if (p != NULL) {
treeprint(p->left); // 打印左子树
printf("%4d %s\n", p->count, p->word); // 打印当前节点
treeprint(p->right); // 打印右子树
}
}
运行
now is the time for all good men to come to the aid of their party
1 aid
1 all
1 come
1 for
1 good
1 is
1 men
1 now
1 of
1 party
2 the
1 their
1 time
2 to









![[激光原理与应用-98]:南京科耐激光-激光焊接-焊中检测-智能制程监测系统IPM介绍 - 2 - 什么是激光器焊接](https://img-blog.csdnimg.cn/direct/cb6a02565e544d97a705d3a6dd7ddcc9.png)