目录
01 学习目标
02 基于内容的过滤算法
03 实现“电影推荐系统”
3.1 问题描述
3.2 算法实现
04 大项目(数据很大)的推荐方法※
4.1 方法原理
4.2 实施示例
05 总结
01 学习目标
(1)理解基于内容的过滤算法(Content-Based Filtering Algorithm)推荐原理
(2)利用基于内容的过滤算法构建“电影推荐系统”
(3)了解大项目(数据集很大)的推荐方法
02 基于内容的过滤算法
基于内容的过滤算法,是采用神经网络架构提取用户特征和物品特征后向用户推荐相似物品。用户特征包括:年龄、性别、国家、喜好和评分等等,物品(比如电影)特征包括:年份、类型、影评及所有评价用户的平均年龄等等。
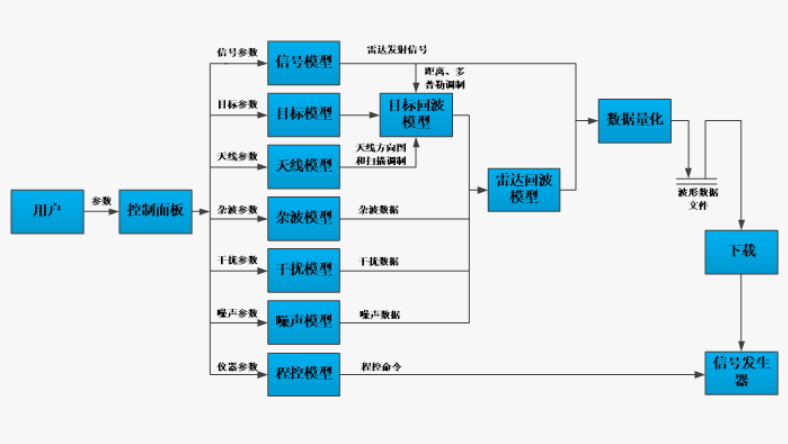
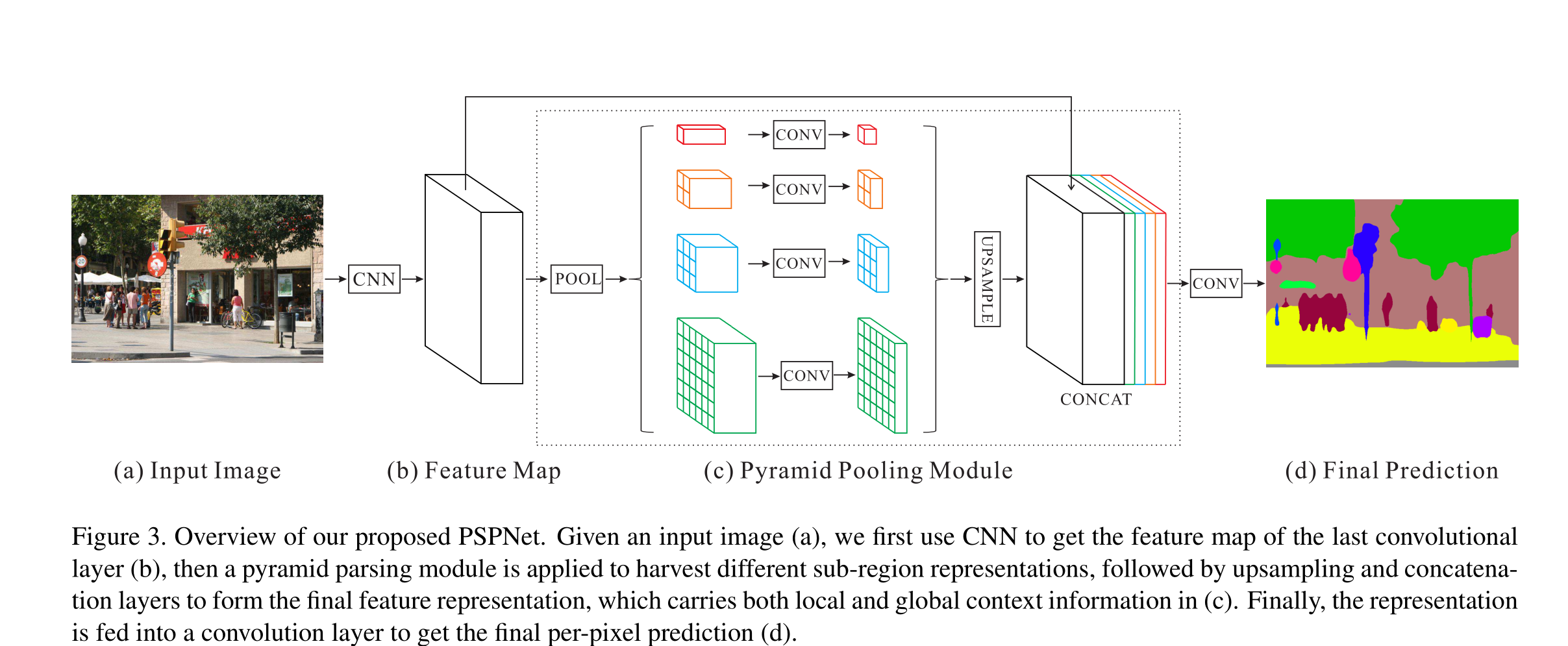
Content-based filtering的原理如下图所示:
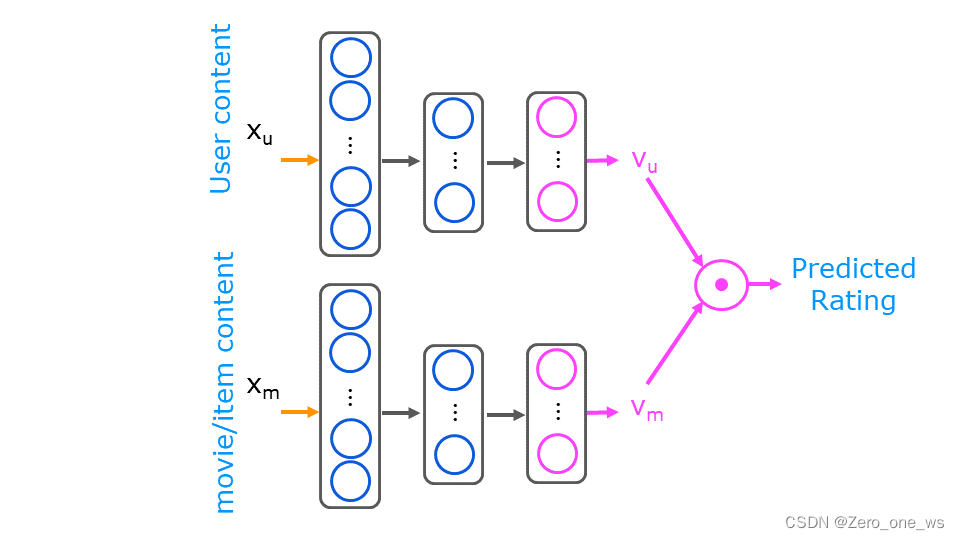
首先(准备内容),准备两组数据,一组是用户内容Xu,一组是物品的内容Xm。(需说明,Xu数组内均为工程特征,即经过处理后的内容,而Xm数组由原始数据和工程特征组合构成)
然后(提取特征),定义神经网络模型,其架构为两个并联的模型,将Xu和Xm作为输入,可分别输出用户特征Vu和物品特征Vm。
接着(用户喜好预测),利用多元线性回归模型,预测用户对所有物品的评分,但Content-based filtering中的回归模型是没有偏置项b的,如下:
式中,Y为预测结果(分数),i为物品的序数,j为用户的序数。
现在(相似度计算),根据物品的特征计算物品之间的相似度,物品相似度有很多计算方法,这里根据课程采用欧氏距离平方:
最后(生成推荐),有了用户对每个物品的预测分数,也有了物品相似度,就可以向用户推荐他喜爱之物的相似物品了。
03 实现“电影推荐系统”
3.1 问题描述
这次,我们依然采用从GroupLens网站的 MovieLens 栏目下载电影数据集来构建“电影推荐系统”。我们的任务是:根据一位用户的行为,预测其喜好,并为其推荐电影。
3.2 算法实现
(1)导入模块
# 导包
import pickle
import csv
import numpy as np
import numpy.ma as ma
from numpy import genfromtxt
from collections import defaultdict
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Model
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
import tabulate
pd.set_option("display.precision", 1)
# Import Lambda layer at the beginning if not already imported
from tensorflow.keras.layers import Lambda(2)读取数据
① 由于数据较多,定义函数读取:
# 定义函数,读取数据
def load_data():
item_train = genfromtxt('./data/content_item_train.csv', delimiter=',')
user_train = genfromtxt('./data/content_user_train.csv', delimiter=',')
y_train = genfromtxt('./data/content_y_train.csv', delimiter=',')
with open('./data/content_item_train_header.txt', newline='') as f:
item_features = list(csv.reader(f))[0]
with open('./data/content_user_train_header.txt', newline='') as f:
user_features = list(csv.reader(f))[0]
item_vecs = genfromtxt('./data/content_item_vecs.csv', delimiter=',')
movie_dict = defaultdict(dict)
count = 0
with open('./data/content_movie_list.csv', newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
for line in reader:
if count == 0:
count +=1 #skip header
else:
count +=1
movie_id = int(line[0])
movie_dict[movie_id]["title"] = line[1]
movie_dict[movie_id]["genres"] =line[2]
with open('./data/content_user_to_genre.pickle', 'rb') as f:
user_to_genre = pickle.load(f)
return(item_train, user_train, y_train, item_features, user_features, item_vecs, movie_dict, user_to_genre)② 读取数据:
# 导入原始数据
item_train, user_train, y_train, item_features, user_features, item_vecs, movie_dict, user_to_genre = load_data()
num_user_features = user_train.shape[1] - 3 # 原始数据移除用户ID、评论总数、平均评分三列
num_item_features = item_train.shape[1] - 1 # 原始数据移除电影ID列
uvs = 3 # 用户特征向量开始索引
ivs = 3 # 物品特征向量开始索引
u_s = 3 # 训练集中用户内容开始列索引
i_s = 1 # 训练集中物品内容开始列索引
scaledata = True # 应用标准化尺度缩放(3)数据处理、拆分
① 数据标准化:
# 原始数据标准化:均值为0、标准差为1
if scaledata:
item_train_save = item_train
user_train_save = user_train
scalerItem = StandardScaler()
scalerItem.fit(item_train)
item_train = scalerItem.transform(item_train)
scalerUser = StandardScaler()
scalerUser.fit(user_train)
user_train = scalerUser.transform(user_train)② 数据拆分为训练集和测试集:
# 数据集拆分,训练集:测试集=8:2
item_train, item_test = train_test_split(item_train, train_size=0.80, shuffle=True, random_state=1)
user_train, user_test = train_test_split(user_train, train_size=0.80, shuffle=True, random_state=1)
y_train, y_test = train_test_split(y_train, train_size=0.80, shuffle=True, random_state=1)③ 数据集的数据归一化:
# 训练集、测试集数据归一化
scaler = MinMaxScaler((-1, 1))
scaler.fit(y_train.reshape(-1, 1))
ynorm_train = scaler.transform(y_train.reshape(-1, 1))
ynorm_test = scaler.transform(y_test.reshape(-1, 1))(4)人工神经网络模型提取特征
① 定义模型架构:
# 定义神经网络模型
num_outputs = 32
tf.random.set_seed(1)
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_outputs)
])
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_outputs)
])
# 创建用户输入并指向基础网络
input_user = tf.keras.layers.Input(shape=(num_user_features,))
vu = user_NN(input_user)
# 创建物品输入并指向基础网络
input_item = tf.keras.layers.Input(shape=(num_item_features,))
vm = item_NN(input_item)
# 使用 Keras Lambda layer计算L2范数标准化向量
norm_user = Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1))(vu)
norm_item = Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1))(vm)
# 点乘计算两个标准化向量
output = tf.keras.layers.Dot(axes=1)([norm_user, norm_item])
# 指定模型的输入和输出
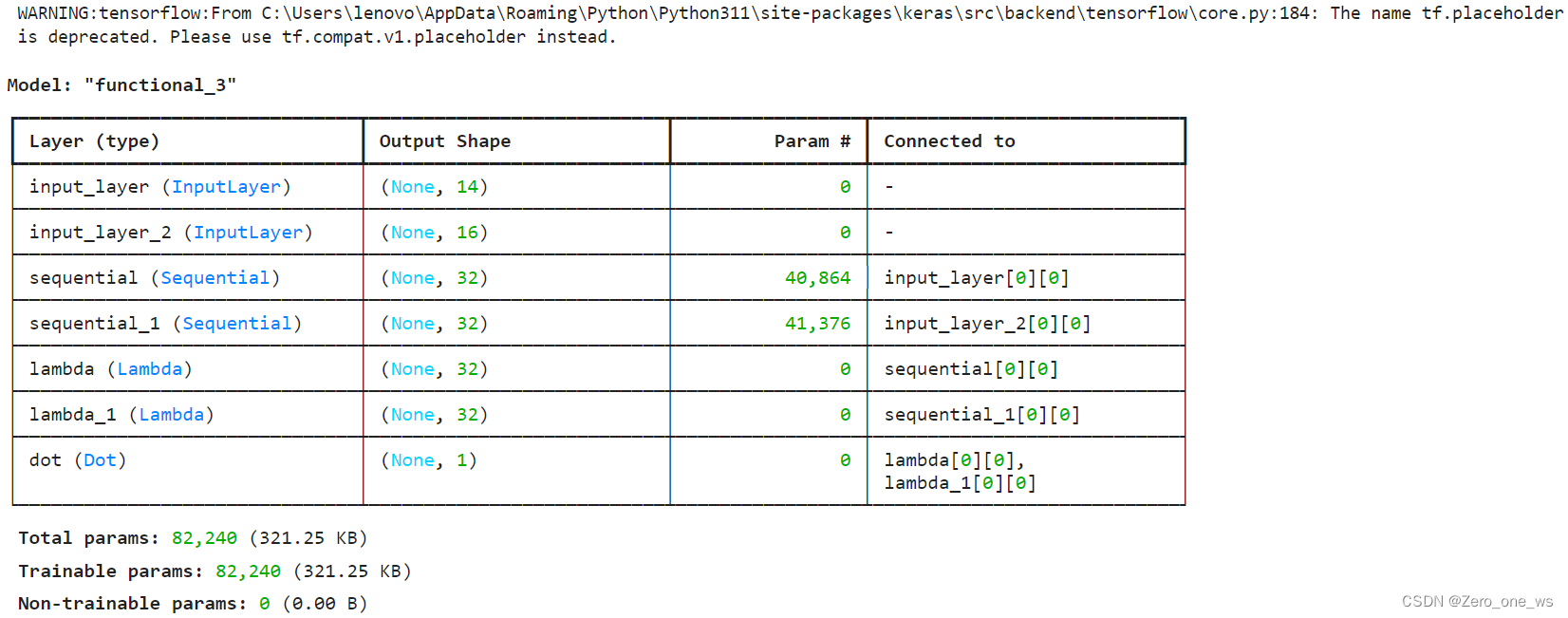
model = Model([input_user, input_item], output)
model.summary()运行以上代码,结果如下(warning不用理会):
② 模型编译及训练:
# 模型编译、训练
tf.random.set_seed(1)
cost_fn = tf.keras.losses.MeanSquaredError()
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt,
loss=cost_fn)
model.fit([user_train[:, u_s:], item_train[:, i_s:]], ynorm_train, epochs=20)运行以上代码,结果如下:

③ 模型评估:
# 模型评估
model.evaluate([user_test[:, u_s:], item_test[:, i_s:]], ynorm_test)运行以上代码,结果如下:
![]()
(5)用户喜好预测
① 定义函数,提取指定用户的信息内容:
def get_user_vecs(user_id, user_train, item_vecs, user_to_genre):
""" 输入user_id, user_train, item_vecs, user_to_genre,返回:
user_vecs:用户特征向量,与电影特征向量item_vecs同尺度
y vector: 用户对所有电影的评分 """
# 判断id是否存在
if user_id not in user_to_genre:
print("error: unknown user id")
return(None)
else:
user_vec_found = False
for i in range(len(user_train)):
if user_train[i, 0] == user_id:
user_vec = user_train[i]
user_vec_found = True
break
if not user_vec_found:
print("error in get_user_vecs, did not find uid in user_train")
num_items = len(item_vecs)
user_vecs = np.tile(user_vec, (num_items, 1))
y = np.zeros(num_items)
for i in range(num_items):
movie_id = item_vecs[i, 0]
if movie_id in user_to_genre[user_id]['movies']:
rating = user_to_genre[user_id]['movies'][movie_id]
else:
rating = 0
y[i] = rating
return(user_vecs, y)② 定义函数,根据用户内容(利用model)预测并对预测结果排序:
# 对预测结果排序
def predict_uservec(user_vecs, item_vecs, model, u_s, i_s, scaler, ScalerUser, ScalerItem, scaledata=False):
""" given a user vector, does the prediction on all movies in item_vecs returns
an array predictions sorted by predicted rating,
arrays of user and item, sorted by predicted rating sorting index
"""
if scaledata:
scaled_user_vecs = ScalerUser.transform(user_vecs)
scaled_item_vecs = ScalerItem.transform(item_vecs)
y_p = model.predict([scaled_user_vecs[:, u_s:], scaled_item_vecs[:, i_s:]])
else:
y_p = model.predict([user_vecs[:, u_s:], item_vecs[:, i_s:]])
y_pu = scaler.inverse_transform(y_p)
if np.any(y_pu < 0) :
print("Error, expected all positive predictions")
sorted_index = np.argsort(-y_pu,axis=0).reshape(-1).tolist() #negate to get largest rating first
sorted_ypu = y_pu[sorted_index]
sorted_items = item_vecs[sorted_index]
sorted_user = user_vecs[sorted_index]
return(sorted_index, sorted_ypu, sorted_items, sorted_user)③ 定义函数,展示(预测的)用户喜好:
def print_existing_user(y_p, y, user, items, item_features, ivs, uvs, movie_dict, maxcount=10):
""" print results of prediction a user who was in the datatbase.
inputs are expected to be in sorted order, unscaled.
"""
count = 0
movies_listed = defaultdict(int)
disp = [["y_p", "y", "user", "user genre ave", "movie rating ave", "title", "genres"]]
listed = []
count = 0
for i in range(0, y.shape[0]):
if y[i, 0] != 0:
if count == maxcount:
break
count += 1
movie_id = items[i, 0].astype(int)
offset = np.where(items[i, ivs:] == 1)[0][0]
genre_rating = user[i, uvs + offset]
genre = item_features[ivs + offset]
disp.append([y_p[i, 0], y[i, 0],
user[i, 0].astype(int), # userid
genre_rating.astype(float),
items[i, 2].astype(float), # movie average rating
movie_dict[movie_id]['title'], genre])
table = tabulate.tabulate(disp, tablefmt='html', headers="firstrow", floatfmt=[".1f", ".1f", ".0f", ".2f", ".2f"])
return(table)④ 开始为ID=18的用户预测其电影喜好:
# 从原始数据中指定一位用户ID进行推荐
uid = 18
# 处理原始数据,形成一组用户内容向量
user_vecs, y_vecs = get_user_vecs(uid, scalerUser.inverse_transform(user_train), item_vecs, user_to_genre)
# 缩放内容向量,并预测该用户对所有电影的评分
sorted_index, sorted_ypu, sorted_items, sorted_user = predict_uservec(user_vecs, item_vecs, model, u_s, i_s, scaler,
scalerUser, scalerItem, scaledata=scaledata)
sorted_y = y_vecs[sorted_index] # 返回按评级排序的结果
# 生成预测排序结果
print_existing_user(sorted_ypu, sorted_y.reshape(-1,1), sorted_user, sorted_items, item_features, ivs, uvs, movie_dict, maxcount = 10)运行以上代码,结果如下:

(6)为用户推荐电影
① 定义函数,计算电影相似度:
def sq_dist(a,b):
"""
Returns the squared distance between two vectors
Args:
a (ndarray (n,)): vector with n features
b (ndarray (n,)): vector with n features
Returns:
d (float) : distance
"""
d = np.sum((a - b) ** 2)
return (d)② 新建模型计算电影特征向量:
# 利用已训练参数新建模型计算物品向量
input_item_m = tf.keras.layers.Input(shape=(num_item_features,)) # input layer
vm_m = item_NN(input_item_m) # use the trained item_NN
# 使用item_NN的输出在Lambda层中定义L2归一化
normalized_output = Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1))(vm_m)
# 使用修正后的逻辑重新定义model_m,确保输入和输出正确关联
model_m = Model(inputs=input_item_m, outputs=normalized_output)
model_m.summary()
# 标准化处理特征向量,并使用model_m预测
scaled_item_vecs = scalerItem.transform(item_vecs)
vms = model_m.predict(scaled_item_vecs[:,i_s:])运行以上代码,结果如下:

(新建一个模型,利用已经训练好的参数进行预测,好处是易于分离职责和维护、效率更高、便于调试和优化)
③ 向用户(ID=18)推荐:
# 向用户推荐
count = 10 # 推荐数量
liked_movie_ids = item_vecs[sorted_index[:10], 0].astype(int) # 实际应用中应根据用户评分数据动态获取
# 使用训练好的模型和标准化的电影特征向量计算喜欢的电影的特征向量
liked_movie_vectors = []
for movie_id in liked_movie_ids:
try:
# 尝试在item_vecs中找到movie_id
movie_index = np.where(item_vecs[:, 0] == movie_id)[0]
if len(movie_index) > 0:
# 如果找到了,进行后续操作
scaled_movie_vec = scalerItem.transform(item_vecs[movie_index, :])[:, i_s:]
liked_movie_vectors.append(model_m.predict(scaled_movie_vec).flatten())
else:
print(f"Warning: Movie ID {movie_id} not found in item vectors despite attempt.")
except Exception as e:
print(f"An unexpected error occurred while processing movie ID {movie_id}: {e}")
# 初始化相似度计算和推荐列表
distances = []
recommendations = []
# 对于每部喜欢的电影,找到与其最相似的未看过的电影
for liked_vector in liked_movie_vectors:
liked_vector_normalized = liked_vector[:32] / np.linalg.norm(liked_vector[:32]) # 取前32个元素并正则化
#
for i, v in enumerate(vms):
v_normalized = v / np.linalg.norm(v) # 正则化处理当前比较的电影向量
sim_score = np.dot(liked_vector_normalized, v_normalized) # 使用点积计算相似度
distances.append((sim_score, i)) # 记录电影索引及其相似度
# 对所有相似度进行排序并选择前N部电影(排除已喜欢的)
top_movies_indices = [idx for _, idx in sorted(distances, reverse=True)[:count]]
unique_top_movies = list(set(top_movies_indices))
# 构建推荐列表
disp = [["Movie Title", "Genres"]]
for movie_idx in unique_top_movies:
movie_id = int(item_vecs[movie_idx, 0])
title, genres = movie_dict[movie_id]['title'], movie_dict[movie_id]['genres']
disp.append([title, genres])
table = tabulate.tabulate(disp, tablefmt='html', headers="firstrow")
table运行以上代码,结果如下:
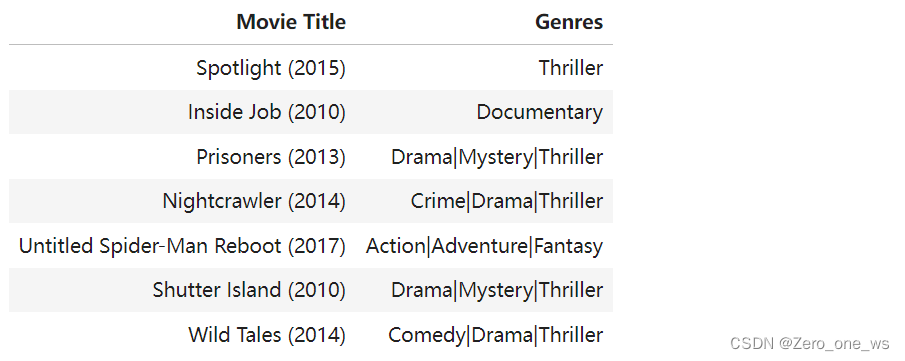
至此,完成了“基于内容过滤的电影推荐系统”搭建任务,上述系统尽量复现了吴恩达机器学习course3(week2)中的课后代码(因为原代码跑不通略作修改),推荐的结果可采纳度较高,预测用户(ID=18)的电影喜好类型为悬疑片(mystery)和恐怖片(thriller),最终推荐的电影也以恐怖片为主。
04 大项目(数据很大)的推荐方法※
4.1 方法原理
针对数据量特别大的推荐系统,课程中给出一种提升推荐效率的方法:检索 + 排序。
4.2 实施示例
假设一个电影视频网站有数万部电影,即使仅为1位用户作推荐,每次从数万部电影中寻找适合的电影也很耗时。
“检索 + 排序”的步骤为:
(1)检索
首先,根据用户最近观看的10部电影,作近似度计算,各取前3;
然后,用户历史记录中选出3类电影类型,找出各类型榜单前10部;
最后,找出该用户所在国家榜单的前10部;
还可以采用其他筛选标准……
(2)排序
假设以上检索出100部电影,将这100部电影的特征输入神经网络模型进行计算,然后采用基于内容的过滤算法向用户推荐。
05 总结
(1)基于内容的过滤算法,其推荐分5个步骤:准备内容>神经网络模型提取特征>用户喜好预测>近似度计算>向用户推荐。
(2)推荐算法的原理易于理解而实际操作较为复杂,根本原因为数据量大,所以各类变量较多,因此数据处理是重点工作。