1 常见部署方式
- 包安装
RHEL系统: https://packagecloud.io/app/prometheus-rpm/release/search
- 二进制安装
https://prometheus.io/download/
- 基于 Docker 运行
https://prometheus.io/docs/prometheus/latest/installation/
1.1 Docker 镜像直接启动
[root@120 ~]# docker run -d --name prometheus -p 9000:9090 prom/prometheus
#浏览器访问:http://prometheus服务器:9000/1.2二进制安装
1.2.1下载二进制包并安装
[root@prometheus local]#pwd
/usr/local/
[root@prometheus local]#wget
https://github.com/prometheus/prometheus/releases/download/v2.19.2/prometheus-
2.19.2.linux-amd64.tar.gz
[root@prometheus local]#tar zxvf prometheus-2.19.2.linux-amd64.tar.gz
[root@prometheus local]#mv prometheus-2.19.2.linux-amd64 prometheus
[root@prometheus local]#cd prometheus/
[root@prometheus prometheus]#mkdir bin conf data
[root@prometheus prometheus]#mv prometheus promtool bin/
[root@prometheus prometheus]#mv prometheus.yml conf/
[root@prometheus prometheus]#useradd -r -s /sbin/nologin prometheus
[root@prometheus prometheus]#chown -R prometheus.prometheus
/usr/local/prometheus/
#查看配置文件,默认可不修改
[root@prometheus ~]#grep -Ev "^ *#|^$" /usr/local/prometheus/conf/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is
every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is
every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
#属性解析:主要是global和 scrape_configs 两部分的配置,在这里目前我们保持默认即可
#检查配置文件是否正确
[root@prometheus ~]#promtool check config /usr/local/prometheus/conf/prometheus.yml
Checking /usr/local/prometheus/conf/prometheus.yml
SUCCESS: 0 rule files found1.2.2 创建 service 文件
[root@prometheus ~]#vim /lib/systemd/system/prometheus.service
[root@prometheus ~]#cat /lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Restart=on-failure
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/prometheus/
ExecStart=/usr/local/prometheus/bin/prometheus --
config.file=/usr/local/prometheus/conf/prometheus.yml
ExecReload=/bin/kill -HUP $MAINPID
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
[root@prometheus ~]#systemctl daemon-reload
[root@prometheus ~]#systemctl enable --now prometheus.service
[root@prometheus ~]#ss -tnlp |grep prometheus
LISTEN 0 128 *:9090 *:*
users:(("prometheus",pid=84755,fd=10))
#结果显示:可以看到当前主机上可以看到一个端口9090,可通过本机ip+9090看到prometheus的服务页面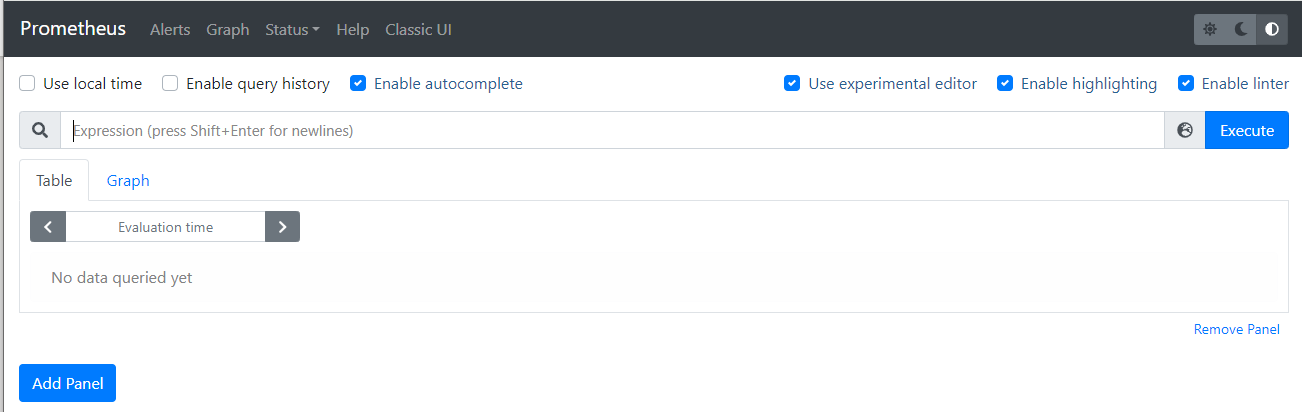
1.2.3 Dashboard 菜单说明
#一级目录解析
Alerts #Prometheus的告警信息菜单
Graph #Prometheus的图形展示界面,这是prometheus默认访问的界面
Status #Prometheus的状态数据界面
Help #Prometheus的帮助信息界面
#Status子菜单,在Status菜单下存在很多的子选项,其名称和功能效果如下:
Runtime & Build Information 服务主机的运行状态信息及内部的监控项基本信息
Command-Line Flags 启动时候从配置文件中加载的属性信息
Configuration 配置文件的具体内容(yaml格式)
Rules 查询、告警、可视化等数据分析动作的规则记录
Targets 监控的目标对象,包括主机、服务等以endpoint形式存在
Service Discovery 自动发现的各种Targets对象列表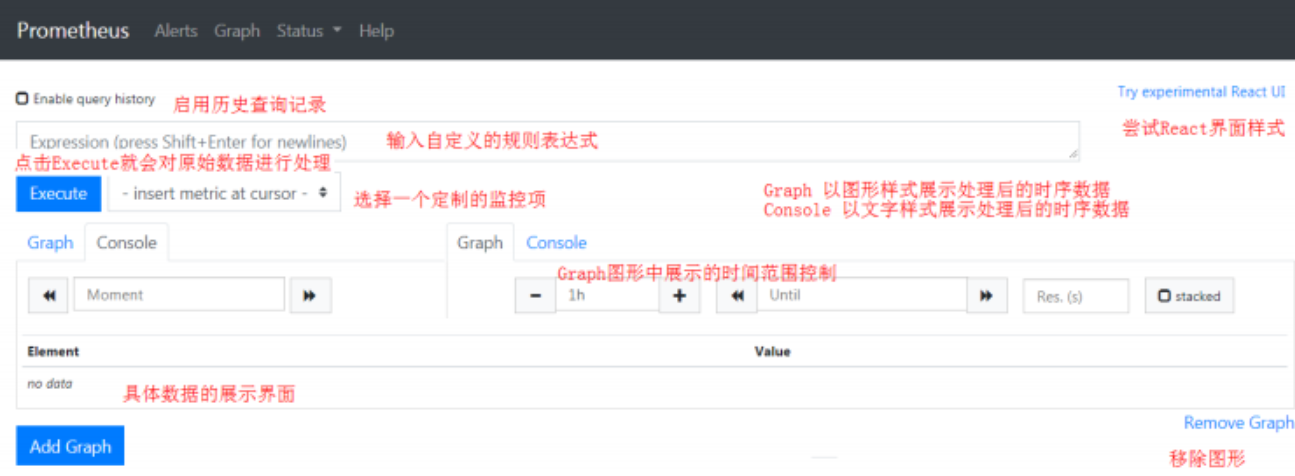
2. Prometheus 配置
2.1.配置文件说明
默认情况下,Prometheus 的配置文件有四部分组成,效果如下:
[root@prometheus ~]# egrep -v '^#| #|^$' prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default
is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is
every 1 minute.
# scrape_timeout is set to the global default (10s).
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']配置解析:
#核心配置:
global #全局配置内容
alerting #触发告警相关的配置,主要是与Alertmanager相关的设置。
rule_files #各种各样的外置规则文件配置,包含了各种告警表达式、数据查询表达式等
scrape_configs #监控项的配置列表,这是最核心的配置
#除了默认的四项配置之外,prometheus还有另外可选的其它配置如下
#扩展配置(8项)
tls_config、static_config、relabel_config、metric_relabel_configs、
alert_relabel_configs、alertmanager_config、remote_write、remote_read
#平台集成配置(12项)
azure_sd_config、consul_sd_config、dns_sd_config、ec2_sd_config、
openstack_sd_config、file_sd_config、gce_sd_config、kubernetes_sd_config、
marathon_sd_config、nerve_sd_config、serverset_sd_config、triton_sd_config
scrape_configs 管理
scrape_configs 是操作最多的一个配置段,它指定了一组监控目标及其细节配置参数,这些目标和参数
描述了如何获取指定主机上的时序数据。配置样例如下:
scrape_configs:
- job_name: '<job_name>'
static_configs:
- targets: [ '<host_ip:host_port>', ... ]
labels: { <labelname>: <labelvalue> ... }
#配置解析:
#在一般情况下,一个scrape_configs配置需要指定一个或者多个job,根据我们之前对基本概念的了解, 每一个job都是一系列的instance集合,借助job我们可以将目标主机进行分组管理。
#对于job内部的每一个instance的配置,都需要借助于static_configs参数获取目标列表,只要在该列表位置的目标,都可以被Prometheus动态服务自动发现。
#static_configs可以借助于 targets 以ip+port 方式发现目标,也可以使用labels以标签方式发现目标。
2.2.标签
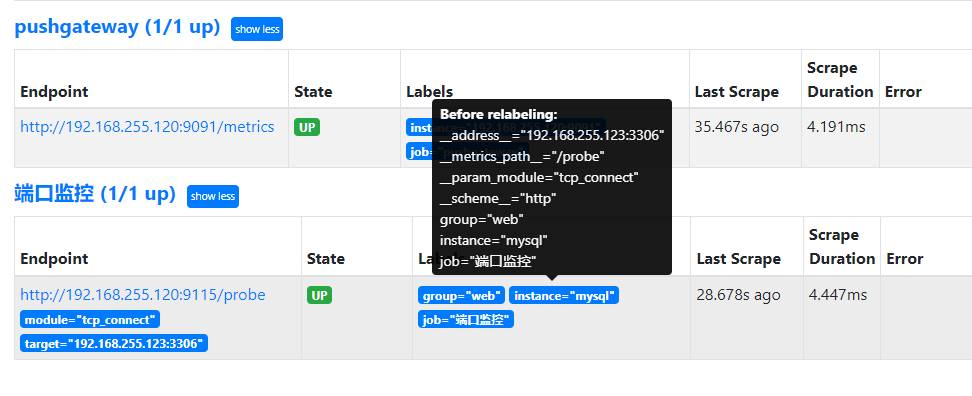
标签功能: 用于对数据分组和分类,利用标签可以将数据进行过滤筛选
标签的常见场景:
- 删除不必要的指标
- 从指标中删除敏感或不需要的标签
- 添加、编辑或修改指标的标签值或标签格式
标签分类:
- 默认标签: Prometheus 自身内置
- 形式: __keyname__
- 应用标签: 应用本身内置
- 形式: keyname
- 自定义标签: 用户定义
- 形式: keyname
范例: 添加主机节点
#编辑prometheus.yml配置文件
scrape_configs:
...
- job_name: "prometheus"
static_configs:
- targets: ['10.0.0.101:9100']
- job_name: 'node_exporter'
static_configs:
- targets: ['10.0.0.104:9100','10.0.0.105:9100','10.0.0.106:9100']
#- '10.0.0.104:9100' #或者下面格式
#- '10.0.0.105:9100'
#- '10.0.0.106:9100'
#配置解析:static_configs 用于手工定制要监控的target
#重启服务
systemctl restart prometheus.service #查看效果,可以看到如下的内置的标签
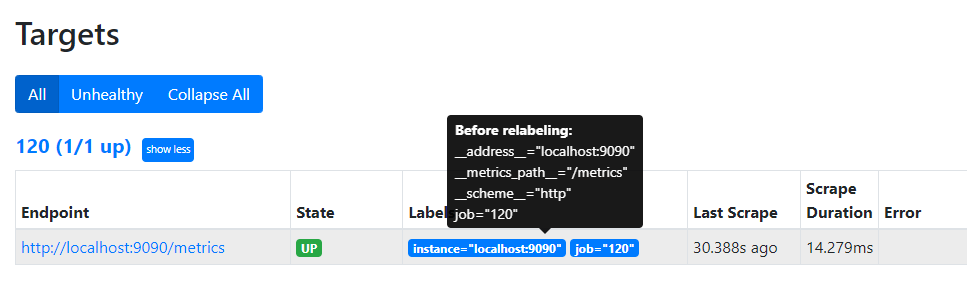
范例: 添加主机标签
#编辑prometheus.yml配置文件
[root@prometheus ~]#vim /usr/local/prometheus/conf/prometheus.yml
- job_name: 'node_exporter'
static_configs:
- targets: ['10.0.0.104:9100','10.0.0.105:9100','10.0.0.106:9100']
labels:
node: "worker node"
type: "test"
- job_name: 'zookeeper'
static_configs:
- targets: ['10.0.0.105:7000','10.0.0.106:7000']
labels: {app: 'zookeeper', type: 'dev'}
#app: 'zookeeper' #或者这种格式也支持
#type: 'dev'
#配置解析:labels: 的编写方法,在此处遵循 yaml的字典格式
#重启服务
[root@prometheus ~]#systemctl restart prometheus.service