文章目录
- Style GAN
- Deeplab-v3+
- FCN
- Adversarial Autoencoders
- High-Resolution Image Synthesis with Latent Diffusion Models
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- Pyramid Scene Parsing Network
Style GAN
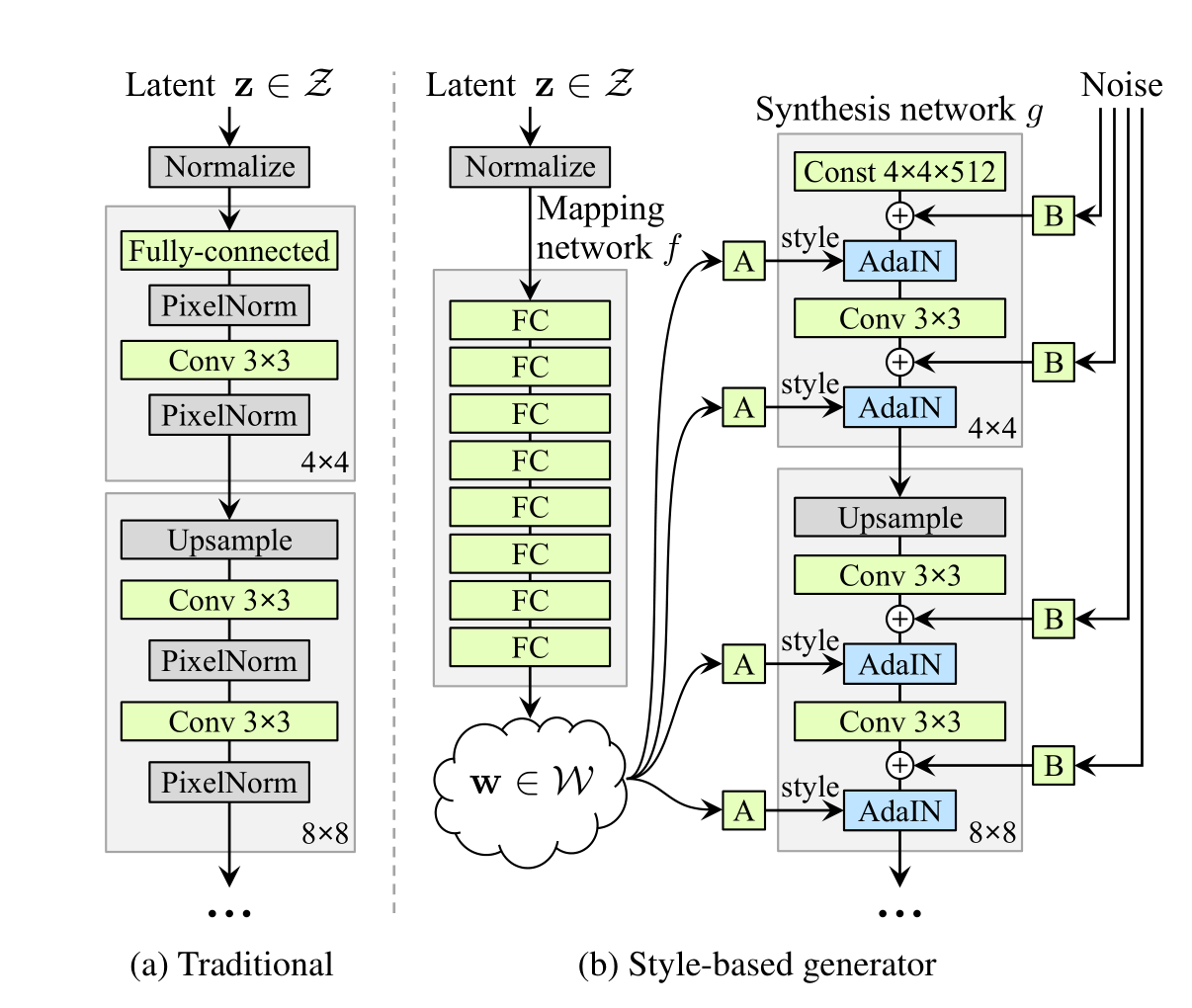
输入是一个潜在向量 (z),通常从标准正态分布中随机采样。
输出:生成器的最终输出是一个RGB图像。
在传统的生成器中,潜在代码(latent code)只在输入层使用。而在本文的生成器架构中,首先将输入映射到一个中间潜在空间W,然后通过自适应实例归一化(Adaptive Instance Normalization, AdaIN)在每个卷积层控制生成器。此外,每次卷积后都会添加高斯噪声,然后进行非线性计算。图中的“A”代表学习的仿射变换,“B”则代表对噪声输入应用的每通道学习缩放因子。映射网络f由8层组成,合成网络g由18层组成——每个分辨率(从4x4到1024x1024)各两层。最后一层的输出使用一个独立的1×1卷积转换为RGB。
数据流动:在网络中的数据流程中,首先将输入的潜在向量 (z) 通过由8个全连接层组成的映射网络 (f) 转换为中间潜在向量 (w)。接着,中间潜在向量 (w) 被输入到合成网络 (g) 中,合成网络包含多个分辨率的卷积层,从4x4到1024x1024,每个分辨率各包含两个卷积层,总共18层。在每个卷积层中,首先进行标准的卷积操作,然后通过自适应实例归一化(AdaIN)使用 (w) 生成的仿射变换参数调整归一化后的激活值。接下来,在每个卷积层之后添加高斯噪声,这些噪声经过学习的缩放因子调整,以提高生成图像的细节和多样性。添加噪声之后,对每个卷积层的输出进行非线性激活(如ReLU)。最后,通过一个1×1卷积层将最后一个卷积层的输出转换为RGB图像,这个1×1卷积层类似于Karras等人[29]的方法,将生成的特征映射到最终的RGB颜色空间。
结构特点:该生成器架构通过引入中间潜在空间W、自适应实例归一化(AdaIN)、高斯噪声添加以及仿射变换和缩放因子,显著提升了生成图像的质量和多样性。中间潜在空间W提高了生成器对输入潜在向量的控制力,使生成的图像更加细致和多样化;AdaIN在每个卷积层进行控制,使得风格和内容的分离更加明显,从而实现更精细的风格迁移;在每个卷积层添加高斯噪声有助于提高图像的多样性和细节;通过学习的仿射变换和缩放因子对归一化和噪声进行调整,使得模型可以生成更加逼真的图像。
Deeplab-v3+
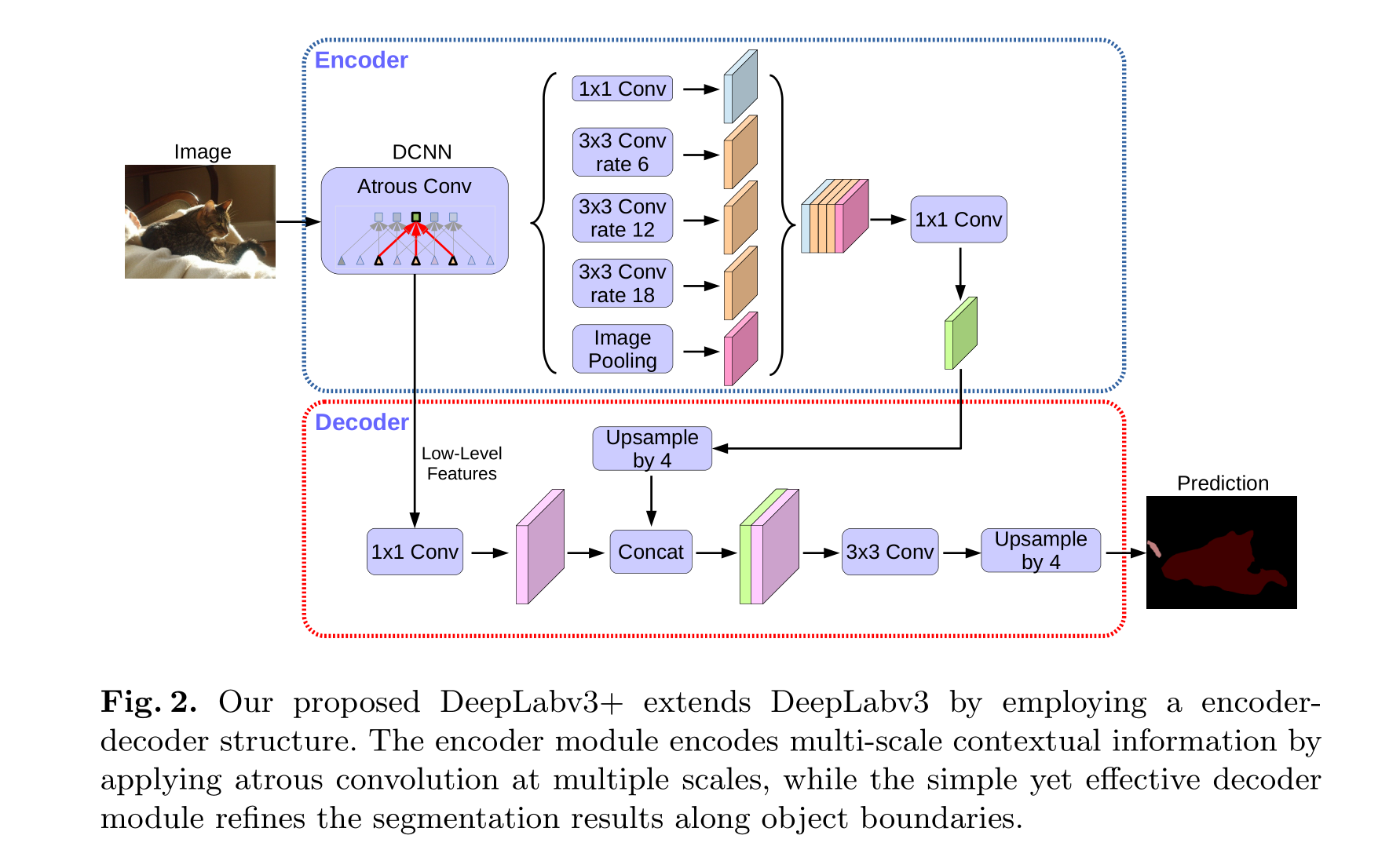
输入是一张RGB图像,通常为任意分辨率的彩色图像。
输出是一张与输入图像大小相同的分割图,每个像素点包含对应类别的预测概率。
数据流程:彩色图像输入后,经过带了空洞卷积(Atrous Conv)的DCNN(Deep Convolutional Neural Network)特征提取网络,生成特征图。特征图会被特征金字塔池化网络(Feature Pyramid Network, FPN)进一步提取特征,然后将不同尺度的特征图Cancat起来送入1x1卷积网络改变通道,然后给入Upsample网络上采样4倍大小,此时特征图需要与DCNN出来的低层次特征(需经过1x1卷积网络改变通道)再次Cancat起来,这里属于利用残差连接的思想将高层次特征和低层次特征融合,然后给入3x3卷积与上采样网络得到最终预测的分割图。而图像到高层次特征的走向为编码器流程,从高层次特征解码为分割图是解码器流程,整体看就是就是一个编解码器的架构。
结构特点:首先,使用空洞卷积(Dilated Convolution)来扩展卷积核的感受野,从而捕捉更丰富的上下文信息;其次,集成了特征金字塔池化网络(SPP,Spatial Pyramid Pooling),以多尺度处理图像特征,提高模型对不同尺度目标的感知能力;此外,采用编解码结构(Encoder-Decoder),在编码阶段提取高层次语义信息,解码阶段逐步恢复空间分辨率,实现精细分割;并且,通过残差连接(Residual Connection)有效缓解深层网络训练中的信息消失问题,提升模型的训练效率和准确性。
FCN
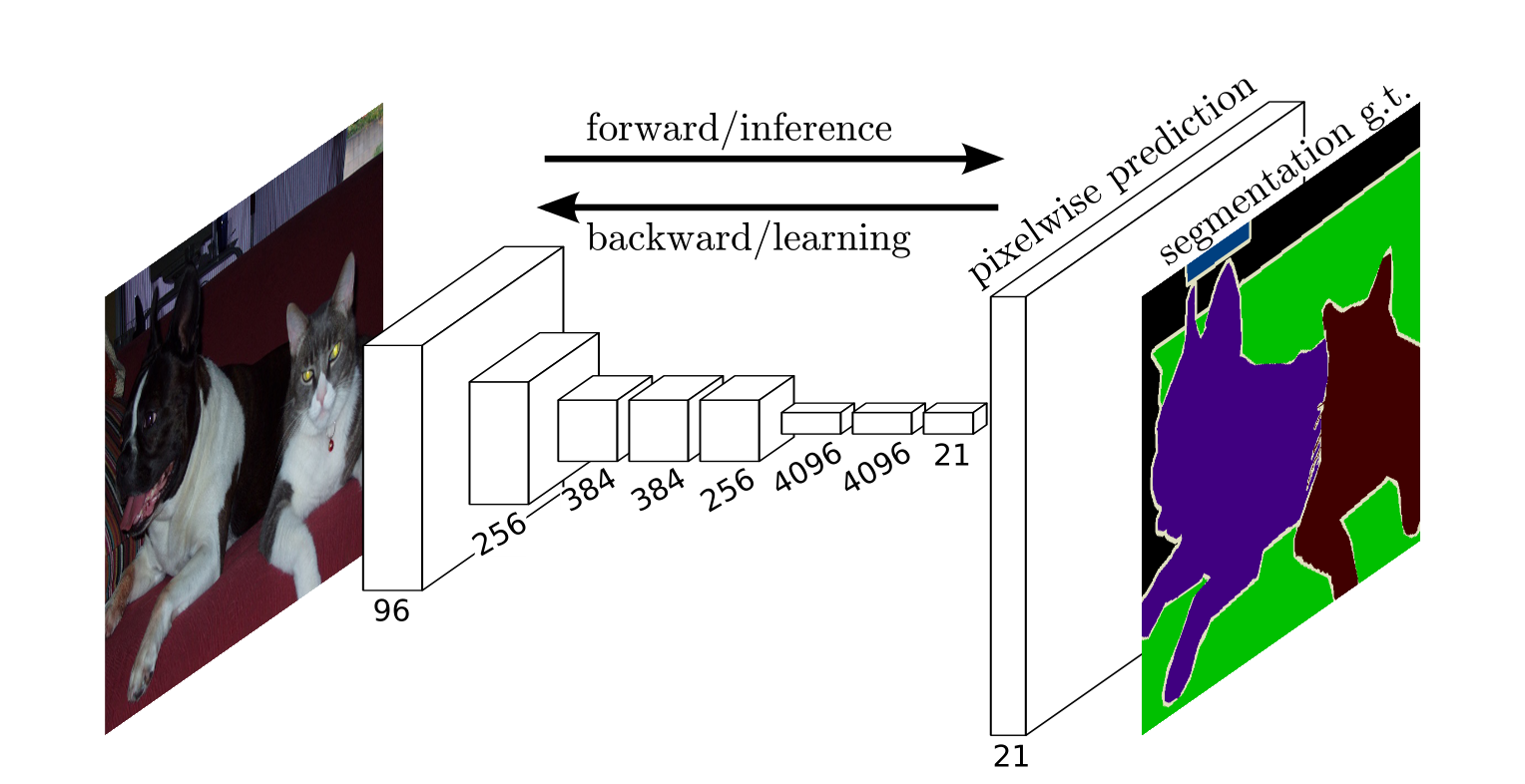
输入是一张RGB图像,通常为任意分辨率的彩色图像。
输出是一张与输入图像大小相同的分割图,每个像素点包含对应类别的预测概率。
数据流程:彩色图像输入后,首先经过一系列标准的卷积层(Convolutional Layers)和池化层(Pooling Layers),生成一张高层次的特征图。在这个特征提取过程中,卷积层负责提取局部特征,而池化层逐步减小空间分辨率,但增加特征的语义信息。然后,这些特征图通过1x1卷积层进行通道数的调整,将高维特征映射到分类空间。接着,使用上采样(Upsampling)操作逐步恢复图像的空间分辨率。上采样通过反卷积(Transposed Convolution)或双线性插值(Bilinear Interpolation)等方法,将低分辨率的特征图逐步放大,直至与输入图像同样大小,最终生成逐像素的分类结果。
结构特点:首先,FCN完全基于卷积神经网络(CNN),不包含任何全连接层(Fully Connected Layer),使得其能够处理任意尺寸的输入图像。其次,FCN通过跳跃连接(Skip Connections)将高层语义信息和低层空间信息进行融合,从而实现更精细的分割效果。例如,可以将卷积网络早期层次的特征图与上采样后的高层次特征图相结合,使得分割结果既包含丰富的语义信息,又保留了精细的边缘信息。此外,FCN利用了转置卷积(Transposed Convolution)进行上采样,这种方法能够较好地恢复原始图像的空间分辨率。总体来说,FCN是一个端到端的训练模型,通过全卷积的架构,实现了从图像到逐像素分类结果的直接映射,在语义分割任务中具有重要的基础性作用。
Adversarial Autoencoders
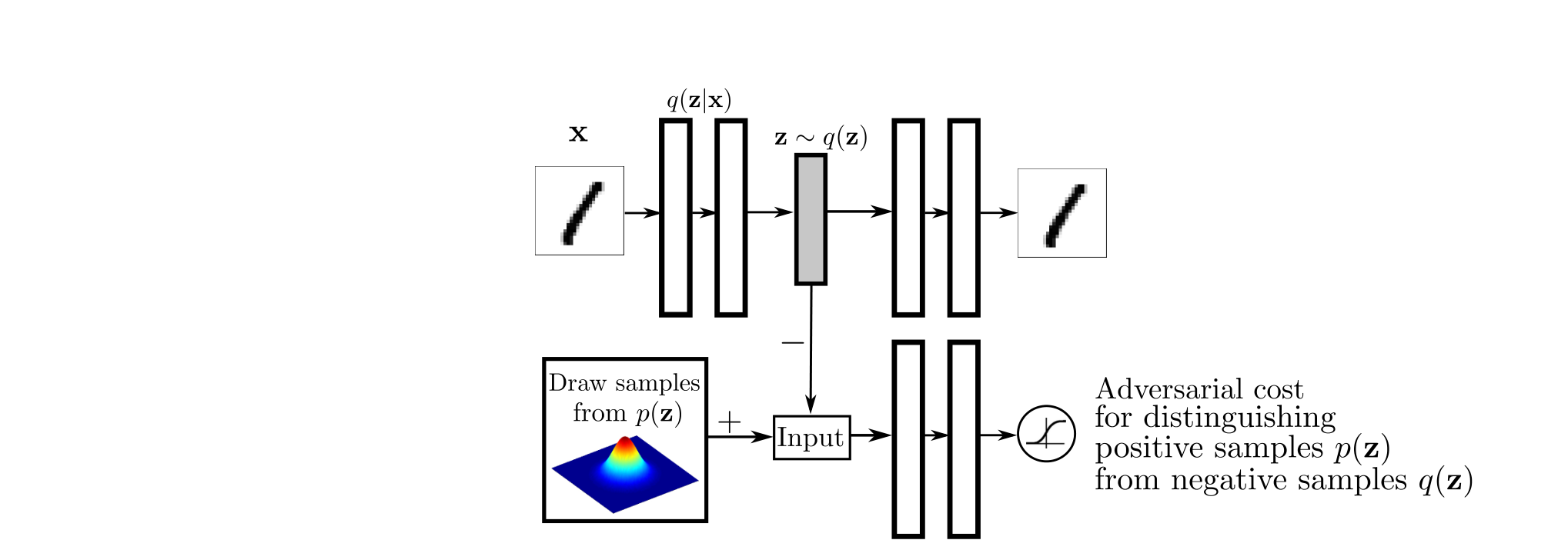
Adversarial Autoencoders(对抗自编码器,AAE)是一种结合了生成对抗网络(Generative Adversarial Networks, GAN)和自编码器(Autoencoder)的方法,用于生成高质量的图像和数据。
输入是一张RGB图像或一个数据样本,通常为任意分辨率的彩色图像或多维数据向量。
输出是一个与输入图像或数据样本同样大小的重建图像或数据向量,且包含对应数据分布的预测概率。
数据流程:输入的图像或数据样本首先经过编码器(Encoder),被压缩为一个低维的潜在表示(Latent Representation)。随后,这个潜在表示会被送入解码器(Decoder)进行重建,以生成与原始输入相似的图像或数据样本。为了确保潜在表示符合预期的分布,AAE引入了对抗训练的思想,将潜在表示送入判别器(Discriminator),判别器的目标是区分出真实分布的潜在表示和编码器生成的潜在表示,而编码器的目标则是使判别器无法区分。
结构特点:首先,AAE结合了自编码器的重建能力和GAN的生成对抗机制,通过对抗训练使潜在空间更具结构化;其次,编码器在潜在空间生成的表示通过对抗性训练逼近先验分布,从而增强生成数据的多样性和逼真度;此外,解码器在生成过程中利用编码器的低维潜在表示逐步恢复空间分辨率,实现高质量的数据生成;并且,通过对抗训练可以有效控制生成样本的分布,使模型不仅能够进行数据重建,还能进行数据生成、数据填充、异常检测等多种任务,提高模型的泛化能力和应用范围。
High-Resolution Image Synthesis with Latent Diffusion Models
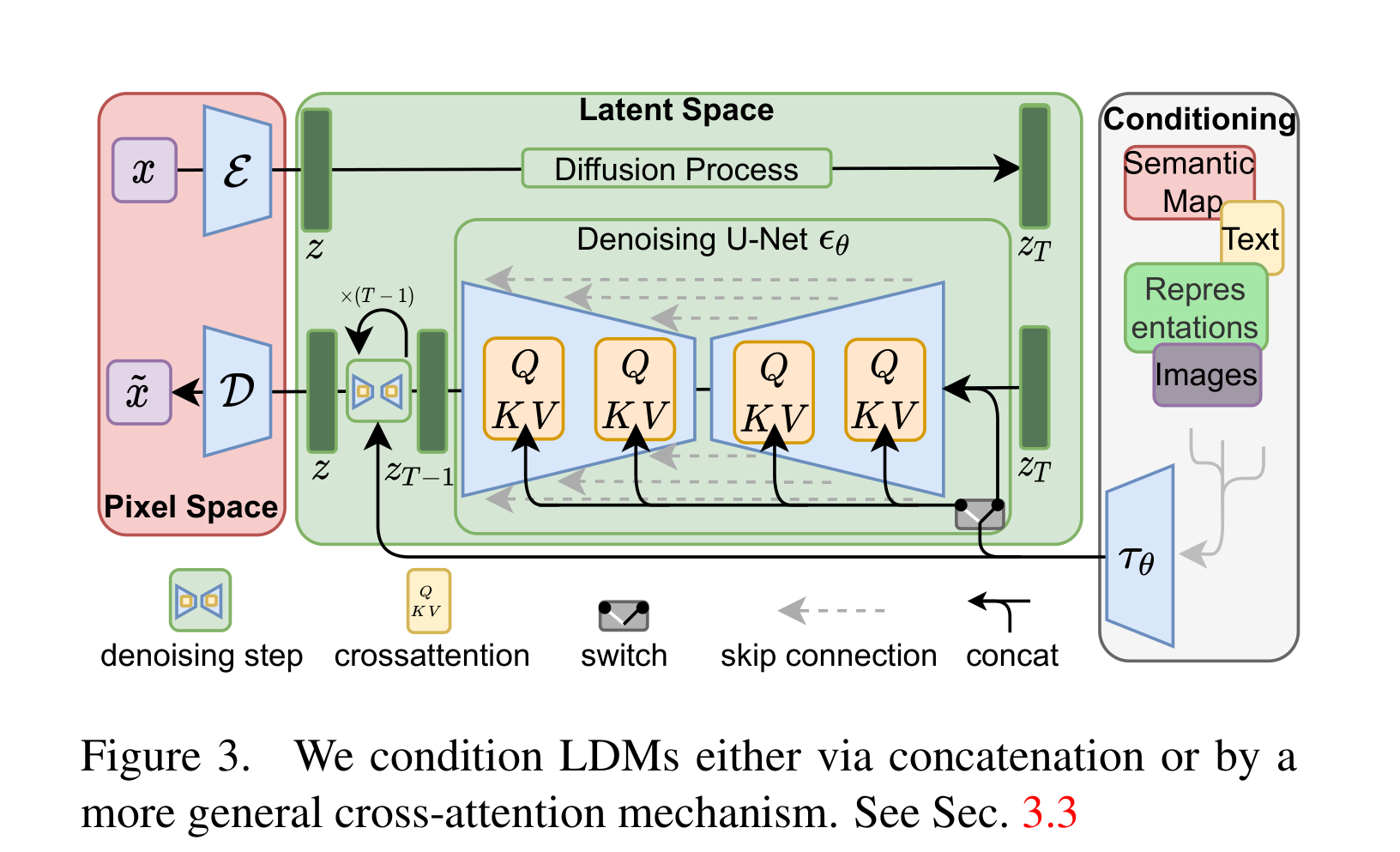
在训练阶段,数据集是图像和图像对应的文本描述(captioning),图像需要经过编码器映射到潜空间特征图(Latent Space),训练阶段的输入就是潜空间特征图z0加T次噪声的图,输出是由U-net网络去噪后的潜空间特征图z0’,文本描述通过CLIP编码后的特征会以交叉注意力方式指导U-net网络的去噪。通过不断训练U-net网络的去噪能力得到训练好的U-net网络。
在推理阶段,输入是一张标准正态分布中采样的噪声图,以及用户输入的条件特征(可以是文本通过CLIP得到特征、也可以是别的表征特征)。输出就是U-net网络不断对噪声图去噪得到最终的去噪后的潜空间特征图z0’,经过解码器网络D得到像素空间的RGB图。
数据流程:输入图像首先通过一个卷积神经网络提取初步特征,然后进入潜在空间(Latent Space),而训练阶段需要前向加噪声并以加噪图为训练输入。在潜在空间中,利用扩散模型(Diffusion Model)逐步细化和提升图像的分辨率。在每个扩散步骤中,通过随机噪声的注入和去噪过程,逐渐生成逼真的高分辨率图像。最后,通过解码器将潜在特征映射回高分辨率图像空间。
结构特点:首先,利用潜在扩散模型(Latent Diffusion Model)在潜在空间中进行处理,可以显著降低计算复杂度和内存占用,同时保持生成图像的高质量。其次,通过多尺度处理和特征融合,模型可以在不同尺度上捕捉细节信息,提高生成图像的细腻度和一致性。此外,扩散模型通过逐步去噪过程,能够有效生成复杂结构和纹理的图像,提升生成结果的真实感和多样性。最后,通过使用高分辨率的解码器,可以将潜在空间中的特征高效地映射到高分辨率图像中,实现高质量的图像合成。
去噪的训练目标可以用以下公式描述:
L ( θ ) = E z 0 , y , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t , y ) ∥ 2 2 ] L(\theta) = \mathbb{E}_{z_0, y, \epsilon \sim \mathcal{N}(0,1), t} \left[ \| \epsilon - \epsilon_\theta(z_t, t, y) \|_2^2 \right] L(θ)=Ez0,y,ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t,y)∥22]
其中:
- L ( θ ) L(\theta) L(θ)是训练U-net网络的损失函数。
- z 0 z_0 z0是原始的潜空间特征图。
- y y y是通过CLIP编码器得到的文本特征。
- ϵ \epsilon ϵ是从标准正态分布中采样的噪声。
- t t t是噪声注入的时间步长。
- z t z_t zt是加噪后的潜空间特征图,在时间 t t t处,由 z 0 z_0 z0和 ϵ \epsilon ϵ通过扩散过程得到。
- ϵ θ ( z t , t , y ) \epsilon_\theta(z_t, t, y) ϵθ(zt,t,y)是U-net网络预测的去噪噪声。
- ∥ ⋅ ∥ 2 \| \cdot \|_2 ∥⋅∥2表示L2范数。
这个损失函数的目标是最小化U-net网络在去噪过程中预测噪声和实际注入噪声之间的L2距离,从而提高U-net网络的去噪能力。通过不断训练和优化$ \theta $,我们可以得到训练好的U-net网络,用于高质量的图像生成。
好的,让我们用公式详细描述T次加噪的图和T-1次加噪的图,以及如何通过U-net预测的噪声还原T次噪声图到T-1次噪声图。
T次加噪的图和T-1次加噪的图:
假设我们有一个初始的潜空间特征图 z 0 z_0 z0,在每个时间步 t t t加入噪声 ϵ \epsilon ϵ,得到 z t z_t zt。加噪过程可以描述为:
z t = α t z 0 + 1 − α t ϵ z_t = \sqrt{\alpha_t} z_0 + \sqrt{1 - \alpha_t} \epsilon zt=αtz0+1−αtϵ
其中 α t \alpha_t αt是一个随时间步长变化的参数, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)表示从标准正态分布中采样的噪声。
那么在T次加噪的情况下,我们有:
z T = α T z 0 + 1 − α T ϵ T z_T = \sqrt{\alpha_T} z_0 + \sqrt{1 - \alpha_T} \epsilon_T zT=αTz0+1−αTϵT
而在 T − 1 T-1 T−1次加噪的情况下,我们有:
z T − 1 = α T − 1 z 0 + 1 − α T − 1 ϵ T − 1 z_{T-1} = \sqrt{\alpha_{T-1}} z_0 + \sqrt{1 - \alpha_{T-1}} \epsilon_{T-1} zT−1=αT−1z0+1−αT−1ϵT−1
从T次噪声图到T-1次噪声图的还原:
U-net网络的任务是预测在每个时间步长 t t t的噪声 ϵ t \epsilon_t ϵt,通过去噪过程还原前一步的特征图。假设U-net网络的参数为 θ \theta θ,其输出为 ϵ θ ( z t , t , y ) \epsilon_\theta(z_t, t, y) ϵθ(zt,t,y),其中 y y y是文本特征。则在时间步长 t t t,U-net预测的噪声为:
ϵ ^ t = ϵ θ ( z t , t , y ) \hat{\epsilon}_t = \epsilon_\theta(z_t, t, y) ϵ^t=ϵθ(zt,t,y)
使用U-net预测的噪声 ϵ ^ t \hat{\epsilon}_t ϵ^t,我们可以将 z t z_t zt还原到 z t − 1 z_{t-1} zt−1,还原公式为:
z t − 1 = 1 α t ( z t − 1 − α t ϵ ^ t ) z_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( z_t - \sqrt{1 - \alpha_t} \hat{\epsilon}_t \right) zt−1=αt1(zt−1−αtϵ^t)
这个公式的推导过程基于反向扩散过程:
- 通过当前的噪声图 z t z_t zt减去U-net预测的噪声 ϵ ^ t \hat{\epsilon}_t ϵ^t,得到去噪后的特征。
- 根据时间步长参数 α t \alpha_t αt进行缩放,得到前一步的噪声图 z t − 1 z_{t-1} zt−1。
通过上述公式,我们可以在训练阶段不断优化U-net网络的参数 θ \theta θ,以提高其预测噪声的准确性,从而在推理阶段实现高质量的图像合成。
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
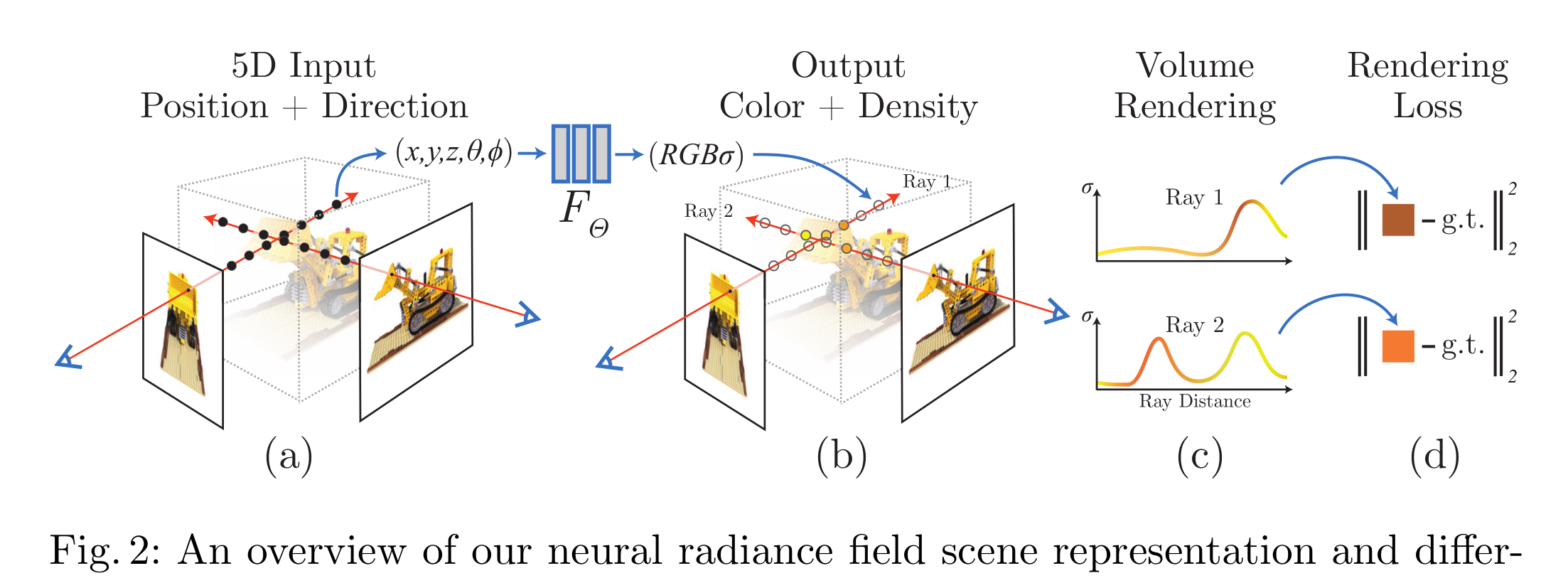
输入:NeRF的输入是一组图像及其对应的相机参数(5D:相机位置3个参数,相机拍摄朝向2个参数),这些图像可以是从不同角度拍摄的同一场景。
输出:NeRF的输出是一个神经辐射场,该场能够合成从任意角度观看的3D场景图像。
数据流程:NeRF首先从一组2D图像及其相应的相机参数开始。每个像素的光线通过相机射入场景,NeRF将每条光线表示为一个5D坐标:3D空间坐标和2D视角方向。将这些坐标输入到一个多层感知器(MLP)中,MLP将输出光线在该点的颜色和密度。通过在光线上进行积分,计算出该光线最终的颜色值,从而生成相应视角的图像。NeRF通过优化训练,使得合成图像与输入图像之间的差异最小。
结构特点:NeRF的关键在于使用一个全连接的神经网络(MLP)来表示整个3D场景,并通过对不同视角下的2D图像进行优化训练,实现对3D场景的精确建模。具体来说,NeRF通过将每条光线的5D坐标(空间位置和视角方向)输入到MLP中,输出该点的颜色和密度,并利用体积渲染技术将这些值综合成最终的图像。NeRF采用体积渲染技术(Volume Rendering)来模拟光线在场景中的传播,通过对空间中的多个采样点进行积分计算,生成最终的图像。这样的设计使得NeRF能够在合成图像时保留高细节和真实感。并且,NeRF通过优化每条光线的颜色和密度,使得合成图像与实际图像之间的误差最小化,从而实现高精度的3D场景重建和新视角合成。此外,NeRF通过使用分层采样策略(Hierarchical Volume Sampling),有效提高了渲染效率和图像质量,使得模型在复杂场景中也能表现出色。总体而言,NeRF是一种通过神经网络直接表示3D场景的方法,其结构和训练策略使其能够高效地生成高质量的视角合成图像。
Pyramid Scene Parsing Network
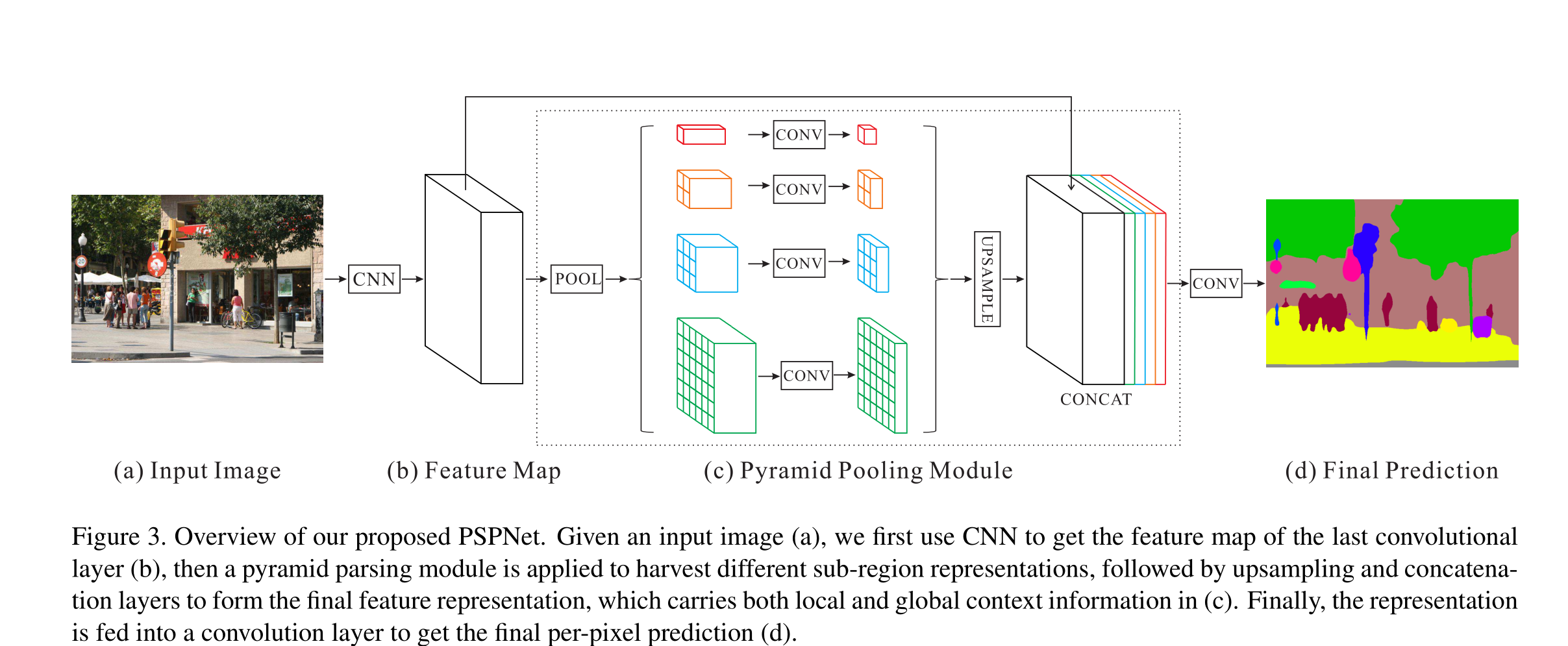
Pyramid Scene Parsing Network(PSPNet)是一种用于图像分割的深度学习模型,其设计目的是提升图像分割的效果,尤其是在处理复杂场景时。PSPNet主要通过利用金字塔池化(Pyramid Pooling)策略来捕捉不同尺度的上下文信息,从而提高模型对多尺度目标的感知能力。
输入是一张RGB图像,通常为任意分辨率的彩色图像。
输出是一张与输入图像大小相同的分割图,每个像素点包含对应类别的预测概率。
彩色图像输入后,首先经过一个卷积神经网络(CNN),例如ResNet,进行特征提取,生成特征图。然后,这些特征图会经过一个特征金字塔池化模块(Pyramid Pooling Module,PPM),该模块通过不同大小的池化窗口来提取不同尺度的上下文信息,生成多个不同尺度的特征图。这些特征图经过1x1卷积网络调整通道数后,再通过双线性插值(Bilinear Interpolation)上采样至原始特征图的尺寸,最后与原始特征图进行拼接(Concat)。拼接后的特征图再经过一系列卷积操作,生成最终的分割预测。整个过程可以视为一种编码器-解码器(Encoder-Decoder)的架构,其中编码器负责提取高层次语义信息,而解码器逐步恢复空间分辨率,实现精细分割。
PSPNet的一个重要特点是通过金字塔池化(Pyramid Pooling)来捕捉不同尺度的上下文信息。这种方法在特征图上应用多尺度的池化操作,使得模型能够处理复杂场景中的多尺度目标,提升了分割精度。其次,PSPNet通常采用ResNet作为其基础网络,利用其强大的特征提取能力来生成高质量的特征图。多尺度特征的有效融合是PSPNet的另一大优势,通过将不同尺度的池化特征与原始特征图进行拼接,模型能够更好地理解和分割图像中的复杂场景。此外,通过全局平均池化,PSPNet能够捕捉到整个图像的全局上下文信息,这对于分割一些具有全局一致性的目标非常重要。最后,PSPNet采用双线性插值和卷积操作,实现了高效的解码过程,使得特征图能够恢复到与输入图像相同的分辨率,从而生成精细的分割图。