#ai夏令营#datawhale#夏令营
Day1:入门级demo运行
这个其实比较简单,按照操作来做就行了,特征工程和调参暂时都没有做,后续的才是重头戏。
Day2:正式比赛开始
赛题:数据挖掘赛道——利用机器学习方法根据给定的特征判断PROTACs的降解能力
这里我想分几个板块进行讲解我个人的一个学习过程和心得吧:
PartA:数据处理
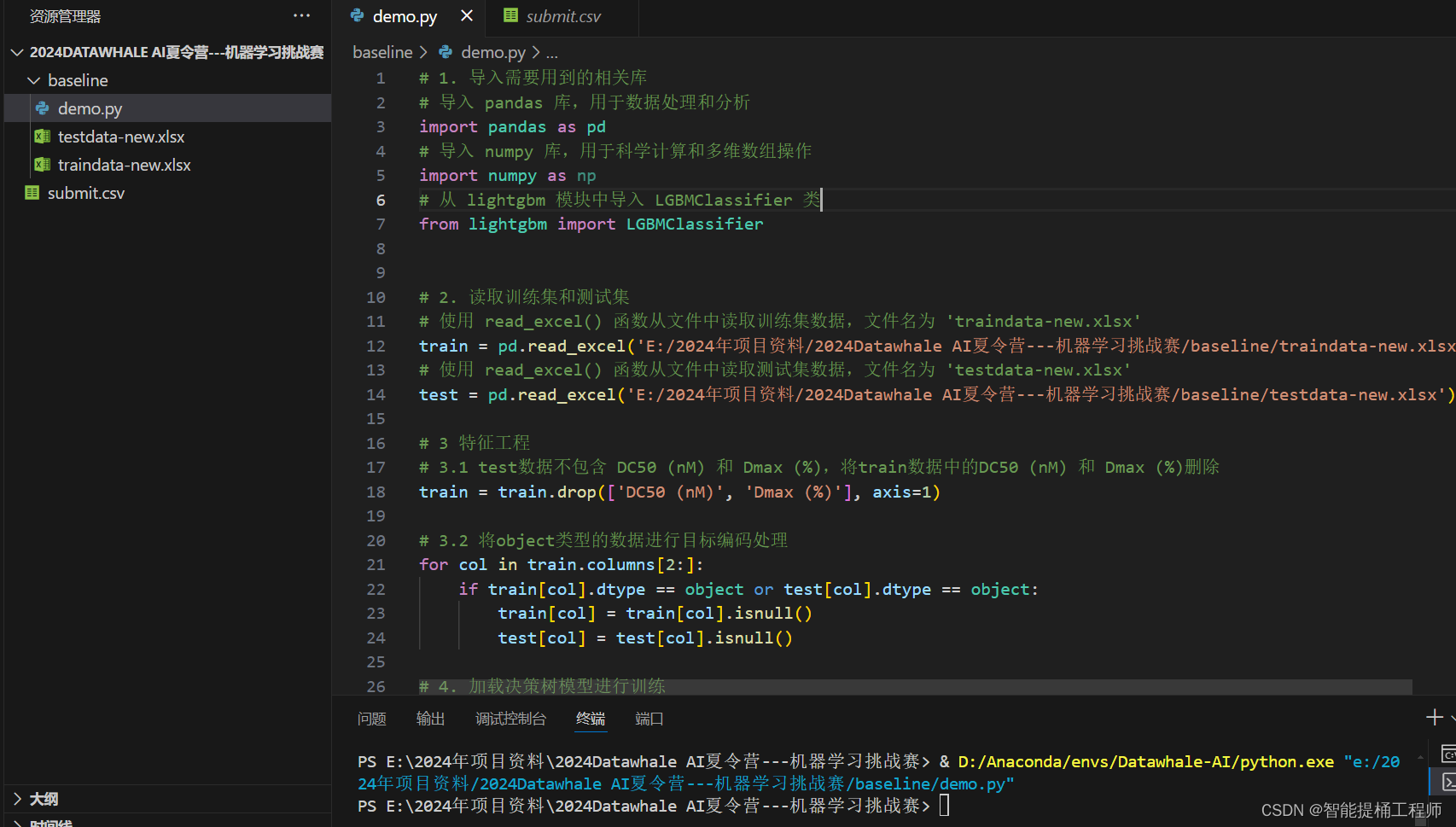
由于啊,看过这数据的人都知道,这数据的质量实在是说不上什么高质量,不仅缺漏,而且是大量缺漏数据,我们需要将过度缺漏数据的特征进行删除,清洗一下数据,这里参考代码用非空值是否小于10个来判断(这个比例应该单纯就是经验之谈了),也就是这一个特征参数如果连10个数据值都没有,那就删了吧,这能分析个啥呢?
train = pd.read_excel('./dataset-new/traindata-new.xlsx')
test = pd.read_excel('./dataset-new/testdata-new.xlsx')
# test数据不包含 DC50 (nM) 和 Dmax (%)
train = train.drop(['DC50 (nM)', 'Dmax (%)'], axis=1)
# 定义了一个空列表drop_cols,用于存储在测试数据集中非空值小于10个的列名。
drop_cols = []
for f in test.columns:
if test[f].notnull().sum() < 10:
drop_cols.append(f)
# 使用drop方法从训练集和测试集中删除了这些列,以避免在后续的分析或建模中使用这些包含大量缺失值的列
train = train.drop(drop_cols, axis=1)
test = test.drop(drop_cols, axis=1)
# 使用pd.concat将清洗后的训练集和测试集合并成一个名为data的DataFrame,便于进行统一的特征工程处理
data = pd.concat([train, test], axis=0, ignore_index=True)
cols = data.columns[2:]数据预处理之后,开始最关键的特征工程
PartB:特征工程
特征工程这里主要对本项目中的特殊的对象,分子化合物的表达形式分子化学式进行了解码分析,这个比较简单粗暴,就是利用rdkit库里的chem包将分子化学式转为字符串列表,然后再转为单个字符串,最后通过TF-IDF计算来将这些字符串转换为数值向量(这也是词级别向量化的操作之一,其他的还有one-hot编码等)
这部分很明显是可以通过考虑分子化合物的特殊情况,来考虑用哪种词解码方式,可以最大限度的保留分子化学式原本包含的信息的情况下转为数值向量。(待提升ing)
这里还有一步是自然数编码,有点没理解这个自然数编码的意义和作用,后续从这补上
# 自然数编码
def label_encode(series):
unique = list(series.unique())
return series.map(dict(zip(
unique, range(series.nunique())
)))
for col in cols:
if data[col].dtype == 'object':
data[col] = label_encode(data[col])
data.to_csv('E:/2024年项目资料/2024Datawhale AI夏令营---机器学习挑战赛/进阶baseline/data/data-nature-coding.csv')
train = data[data.Label.notnull()].reset_index(drop=True)
test = data[data.Label.isnull()].reset_index(drop=True)
特征工程整合源码如下:
#>>>>>>特征工程
# 将SMILES转换为分子对象列表,并转换为SMILES字符串列表
# 然后保存看看,他处理成啥样了
data['smiles_list'] = data['Smiles'].apply(lambda x:[Chem.MolToSmiles(mol, isomericSmiles=True) for mol in [Chem.MolFromSmiles(x)]])
data['smiles_list'].to_csv("E:/2024年项目资料/2024Datawhale AI夏令营---机器学习挑战赛/进阶baseline/data/smiles_list1.csv")
data['smiles_list'] = data['smiles_list'].map(lambda x: ' '.join(x))
data['smiles_list'].to_csv("E:/2024年项目资料/2024Datawhale AI夏令营---机器学习挑战赛/进阶baseline/data/smiles_list2.csv")
# 使用TfidfVectorizer计算TF-IDF
# TF-IDF其实就是词级别的向量化操作之一
# 把这些词级别的字符串解码成文本向量
# 这块还是要学习一下:https://blog.csdn.net/weixin_36488653/article/details/136720789
tfidf = TfidfVectorizer(max_df = 0.9, min_df = 5, sublinear_tf = True)
res = tfidf.fit_transform(data['smiles_list'])
# 将结果转为dataframe格式
tfidf_df = pd.DataFrame(res.toarray())
tfidf_df.columns = [f'smiles_tfidf_{i}' for i in range(tfidf_df.shape[1])]
tfidf_df.to_csv('E:/2024年项目资料/2024Datawhale AI夏令营---机器学习挑战赛/进阶baseline/data/tfidf_df.csv')
# 按列合并到data数据
data = pd.concat([data, tfidf_df], axis=1)
# 自然数编码
def label_encode(series):
unique = list(series.unique())
return series.map(dict(zip(
unique, range(series.nunique())
)))
for col in cols:
if data[col].dtype == 'object':
data[col] = label_encode(data[col])
train = data[data.Label.notnull()].reset_index(drop=True)
test = data[data.Label.isnull()].reset_index(drop=True)
# 特征筛选
features = [f for f in train.columns if f not in ['uuid','Label','smiles_list']]
# 构建训练集和测试集
x_train = train[features]
x_test = test[features]
# 训练集标签
y_train = train['Label'].astype(int)






![[数据库原理]事务](https://img-blog.csdnimg.cn/direct/9ce3de4307e44d49951acc7b53714f87.jpeg)