学习率是神经网络训练中最重要的超参数之一,影响学习过程的速度和有效性。学习率过高会导致模型在最小值附近震荡,而学习率过低会导致训练过程非常缓慢甚至停滞。本文直观地介绍了学习率调度程序,它是用于在训练期间调整学习率的技术。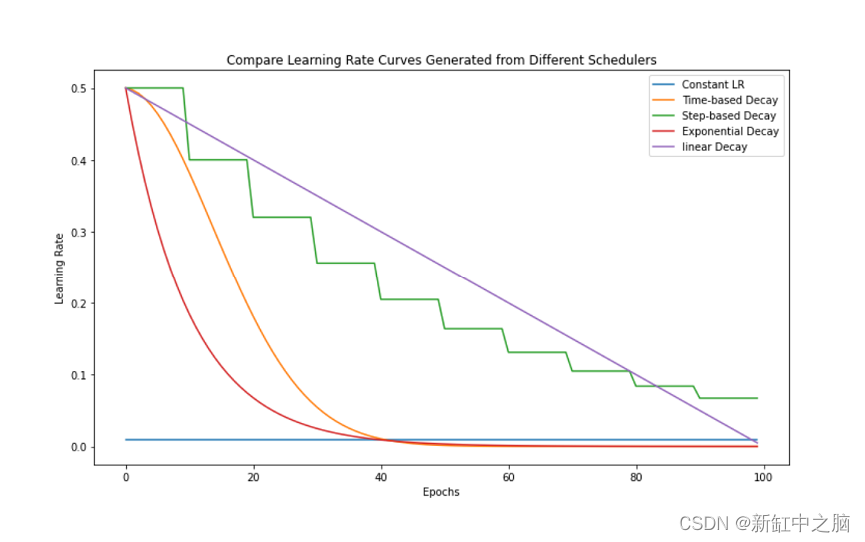
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是学习率?
在机器学习的背景下,学习率(learning rate)是一个超参数,它决定了优化算法(如梯度下降)在尝试最小化损失函数时进行的步长。
现在,让我们继续讨论学习率调度程序。
2、什么是学习率调度器?
学习率调度器(learning rate scheduler)是一种在训练过程中调整学习率的方法,通常会随着训练的进展而降低学习率。这有助于模型在训练开始时当参数远离其最佳值时进行大量更新,并在稍后当参数更接近其最佳值时进行较小的更新,从而允许进行更多微调。
实践中广泛使用了几种学习率调度器。在本文中,我们将重点介绍三种流行的调度器:阶跃衰减、指数衰减和余弦退火。
让我们通过直观的示例深入研究这些调度器中的每一个。
3、阶跃衰减调度器
阶跃衰减(step decay)调度器每隔几个时期将学习率降低一个常数因子。阶跃衰减的形式定义为:
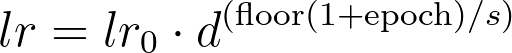
其中:
- lr_0 是初始学习率,
- d 是衰减率,
- s 是步长,
- epoch 是训练周期的索引。
让我们用一个玩具示例来直观地展示这一点:
# Parameters
initial_lr = 1.0
decay_factor = 0.5
step_size = 10
max_epochs = 100
# Generate learning rate schedule
lr = [
initial_lr * (decay_factor ** np.floor((1+epoch)/step_size))
for epoch in range(max_epochs)
]
# Plot
plt.figure(figsize=(10, 7))
plt.plot(lr)
plt.title('Step Decay Learning Rate Scheduler')
plt.ylabel('Learning Rate')
plt.xlabel('Epoch')
plt.grid()
plt.show()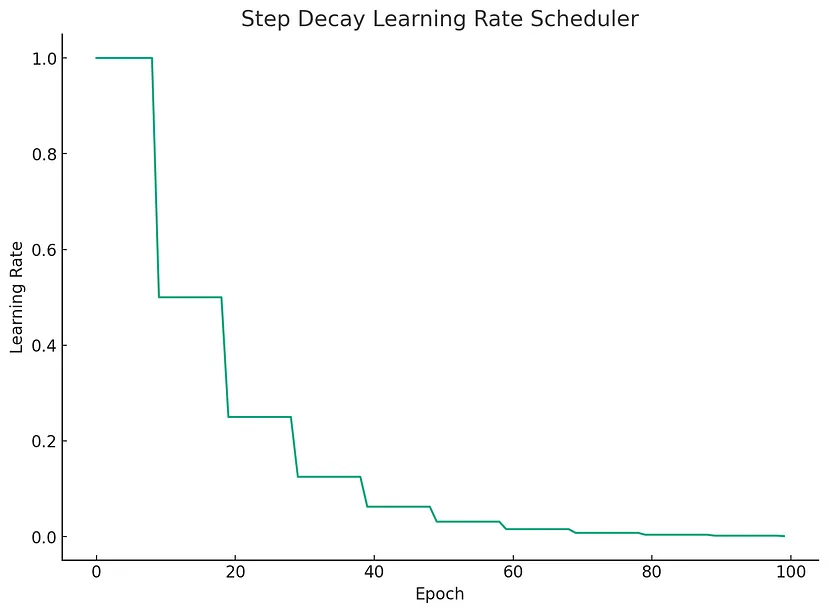
现在,该图更清楚地展示了步进衰减调度程序的性质,学习率每 5 个时期下降 0.5 倍。
4、指数衰减调度器
让我们修改指数衰减(exponential decay)调度器的参数,使衰减更加明显。我们将使用更大的初始学习率和更大的衰减率。

其中:
- lr_0 是初始学习率,
- k 是衰减率,
- epoch 是训练周期的索引。
# Parameters
initial_lr = 1.0
decay_rate = 0.05
max_epochs = 100
# Generate learning rate schedule
lr = [
initial_lr * np.exp(-decay_rate * epoch)
for epoch in range(max_epochs)
]
# Plot
plt.figure(figsize=(10, 7))
plt.plot(lr)
plt.title('Exponential Decay Learning Rate Scheduler')
plt.ylabel('Learning Rate')
plt.xlabel('Epoch')
plt.grid()
plt.show()
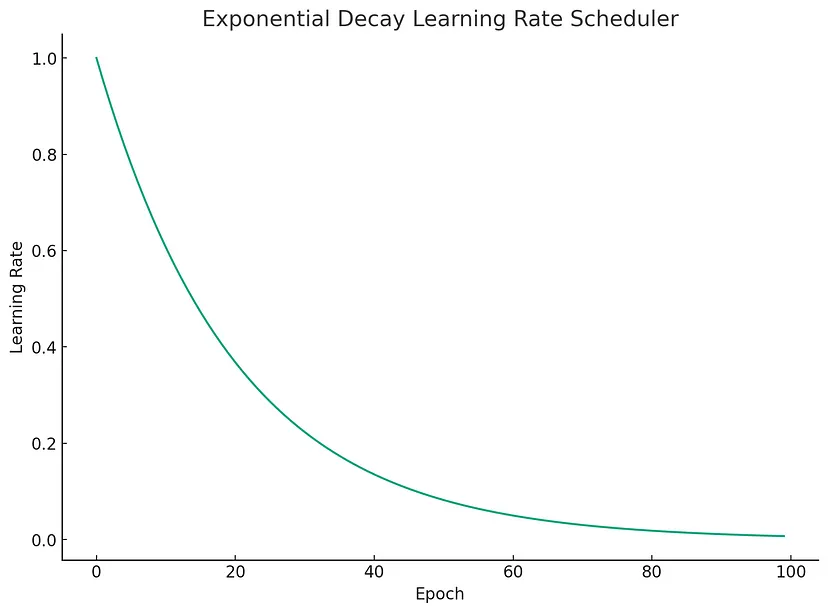
该图更清楚地显示了随着 epoch 数量的增加,学习率呈指数衰减。
5、余弦退火调度器
余弦退火(cosine annealing)调度器使用基于余弦的计划降低学习率。余弦退火的形式定义为:
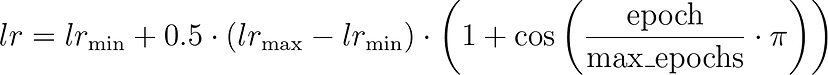
其中:
- lr_min 是最小学习率,
- lr_max 是最大学习率,
- epoch 和 max_epochs 分别是当前和最大 epoch 数值。
# Parameters
lr_min = 0.001
lr_max = 0.1
max_epochs = 100
# Generate learning rate schedule
lr = [
lr_min + 0.5 * (lr_max - lr_min) * (1 + np.cos(epoch / max_epochs * np.pi))
for epoch in range(max_epochs)
]
# Plot
plt.figure(figsize=(10, 7))
plt.plot(lr)
plt.title("Cosine Annealing Learning Rate Scheduler")
plt.ylabel("Learning Rate")
plt.xlabel("Epoch")
plt.show()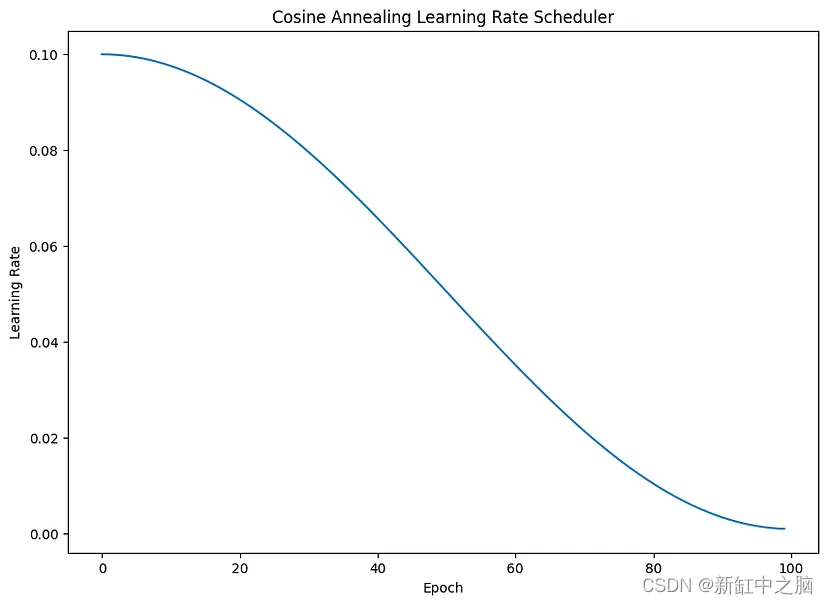
如图所示,学习率按照余弦函数下降,从最大学习率开始下降到最小学习率。这是余弦退火学习率调度器的特点。
6、结束语
学习率调度器是机器学习从业者工具包中的一个重要工具,它提供了一种随时间调整学习率的机制,有助于提高训练过程的效率和效果。最佳学习率调度器可能取决于具体问题和数据集,尝试不同的调度器以查看哪种调度器效果最好通常会有所帮助。
在一张图上显示更多的学习率调度函数: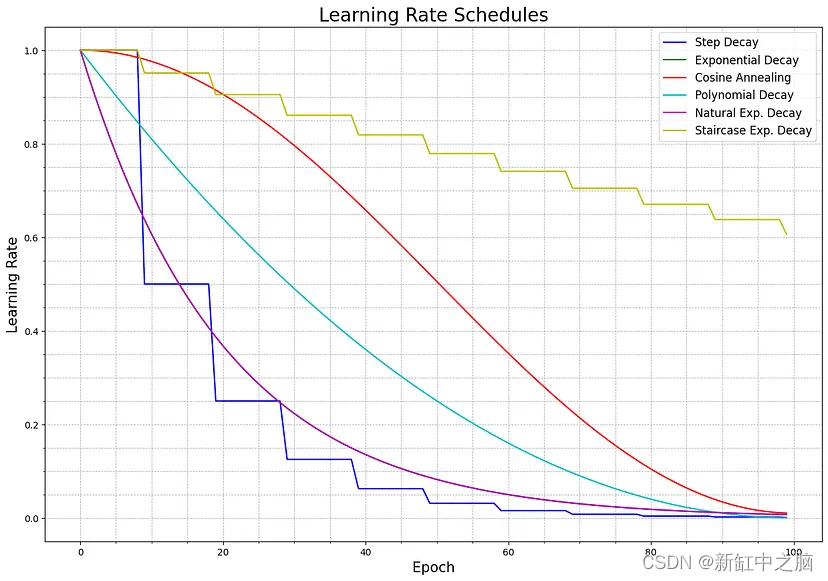
代码如下:
import numpy as np
import matplotlib.pyplot as plt
def polynomial_decay_schedule(initial_lr: float, power: float, max_epochs: int = 100) -> np.ndarray:
"""
Generate a polynomial decay learning rate schedule.
Args:
initial_lr: The initial learning rate.
power: The power of the polynomial.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = initial_lr * ((1 - (epochs / max_epochs)) ** power)
return lr
def natural_exp_decay_schedule(initial_lr: float, decay_rate: float, max_epochs: int = 100) -> np.ndarray:
"""
Generate a natural exponential decay learning rate schedule.
Args:
initial_lr: The initial learning rate.
decay_rate: The decay rate.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = initial_lr * np.exp(-decay_rate * epochs)
return lr
def staircase_exp_decay_schedule(initial_lr: float, decay_rate: float, step_size: int, max_epochs: int = 100) -> np.ndarray:
"""
Generate a staircase exponential decay learning rate schedule.
Args:
initial_lr: The initial learning rate.
decay_rate: The decay rate.
step_size: The step size.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = initial_lr * np.exp(-decay_rate * np.floor((1 + epochs) / step_size))
return lr
def step_decay_schedule(initial_lr: float, decay_factor: float, step_size: int, max_epochs: int = 100) -> np.ndarray:
"""
Generate a step decay learning rate schedule.
Args:
initial_lr: The initial learning rate.
decay_factor: The decay factor.
step_size: The step size.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = initial_lr * (decay_factor ** np.floor((1 + epochs) / step_size))
return lr
def cosine_annealing_schedule(lr_min: float, lr_max: float, max_epochs: int = 100) -> np.ndarray:
"""
Generate a cosine annealing learning rate schedule.
Args:
lr_min: The minimum learning rate.
lr_max: The maximum learning rate.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = lr_min + 0.5 * (lr_max - lr_min) * (1 + np.cos(epochs / max_epochs * np.pi))
return lr
def exponential_decay_schedule(initial_lr: float, decay_rate: float, max_epochs: int = 100) -> np.ndarray:
"""
Generate an exponential decay learning rate schedule.
Args:
initial_lr: The initial learning rate.
decay_rate: The decay rate.
max_epochs: The maximum number of epochs.
Returns:
An array of learning rates for each epoch.
"""
epochs = np.arange(max_epochs)
lr = initial_lr * np.exp(-decay_rate * epochs)
return lr
# Define the learning rate schedules
schedules = {
"Step Decay": step_decay_schedule(initial_lr=1.0, decay_factor=0.5, step_size=10),
"Exponential Decay": exponential_decay_schedule(initial_lr=1.0, decay_rate=0.05),
"Cosine Annealing": cosine_annealing_schedule(lr_min=0.01, lr_max=1.0),
"Polynomial Decay": polynomial_decay_schedule(initial_lr=1.0, power=2),
"Natural Exp. Decay": natural_exp_decay_schedule(initial_lr=1.0, decay_rate=0.05),
"Staircase Exp. Decay": staircase_exp_decay_schedule(initial_lr=1.0, decay_rate=0.05, step_size=10),
}
# Define a color palette
colors = ['b', 'g', 'r', 'c', 'm', 'y']
# Plot with defined colors
plt.figure(figsize=(15, 10))
for color, (schedule_name, schedule) in zip(colors, schedules.items()):
plt.plot(schedule, label=schedule_name, color=color)
plt.title('Learning Rate Schedules', fontsize=20)
plt.ylabel('Learning Rate', fontsize=15)
plt.xlabel('Epoch', fontsize=15)
plt.grid(True, which='both', linestyle='--', linewidth=0.6)
plt.minorticks_on()
plt.legend(prop={'size': 12})
plt.show()原文链接:学习率调度器 - BimAnt