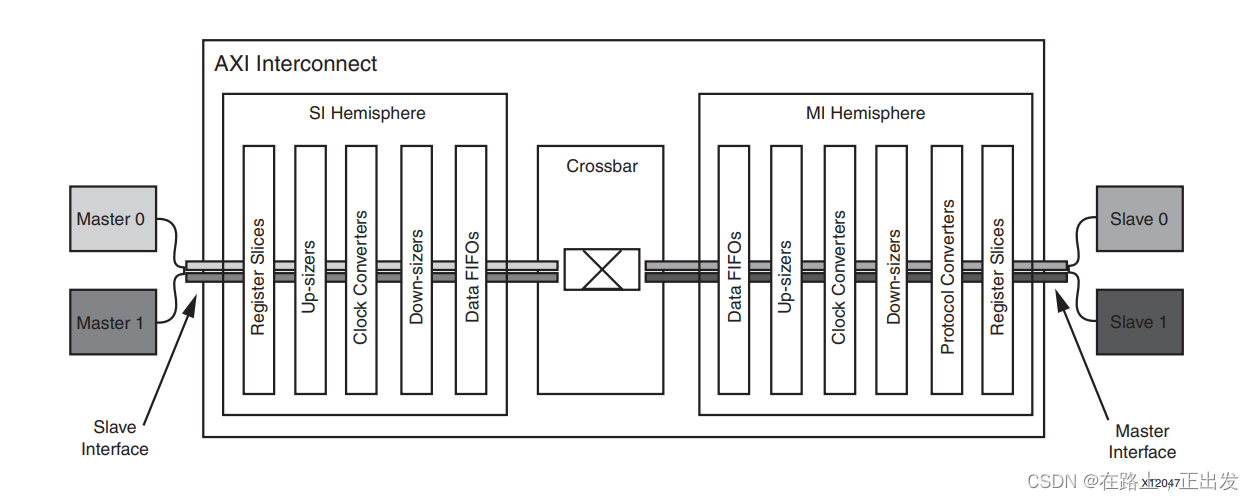
无论是mmdetection、mmtracking、mmdetection3D等框架,在\tools\analysis_tools中均有一个名为browse_dataset.py的文件。该文件能够帮助用户直接可视化 config 文件中的数据处理部分,查看标注文件是否正确,同时可以选择保存可视化图片到指定文件夹内。
调用的基本命令如下:
python tools/analysis_tools/browse_dataset.py \
${CONFIG_FILE} \
[-o, --output-dir ${OUTPUT_DIR}] \
[-p, --phase ${DATASET_PHASE}] \
[-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
[-i, --show-interval ${SHOW_INTERRVAL}] \
[-m, --mode ${DISPLAY_MODE}] \
[--cfg-options ${CFG_OPTIONS}]
参数说明:
-
config: 模型配置文件的路径。 -
-o, --output-dir: 保存图片文件夹,如果没有指定,默认为'./output'。 -
-p, --phase: 可视化数据集的阶段,只能为['train', 'val', 'test']之一,默认为 'train' 。 'val'代表可视化验证集, -
-n, --show-number: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。 -
-m, --mode: 可视化的模式,只能为['original', 'transformed', 'pipeline']之一。 默认为'transformed'。 'original' 代表获取原始图片,'transformed' 代表获取预处理后的图片,'pipeline' 代表获得数据流水线所有中间过程图片。 -
--cfg-options: 对配置文件的修改
比如下面的命令就代表:dataloader构建的数据将会直接弹出显示,每张图片持续 3 秒,并且不进行保存:
python tools/analysis_tools/browse_dataset.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py --show-interval 3
再比如下面的命令就代表:--phase val 代表可视化验证集, 可简化为 -p val ,--output-dir tmp 代表可视化结果保存在 “tmp” 文件夹, 可简化为 -o tmp,--mode original 代表可视化原图, 可简化为 -m original,--show-number 100 代表可视化100张图,可简化为 -n 100
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py --phase val --output-dir tmp --mode original
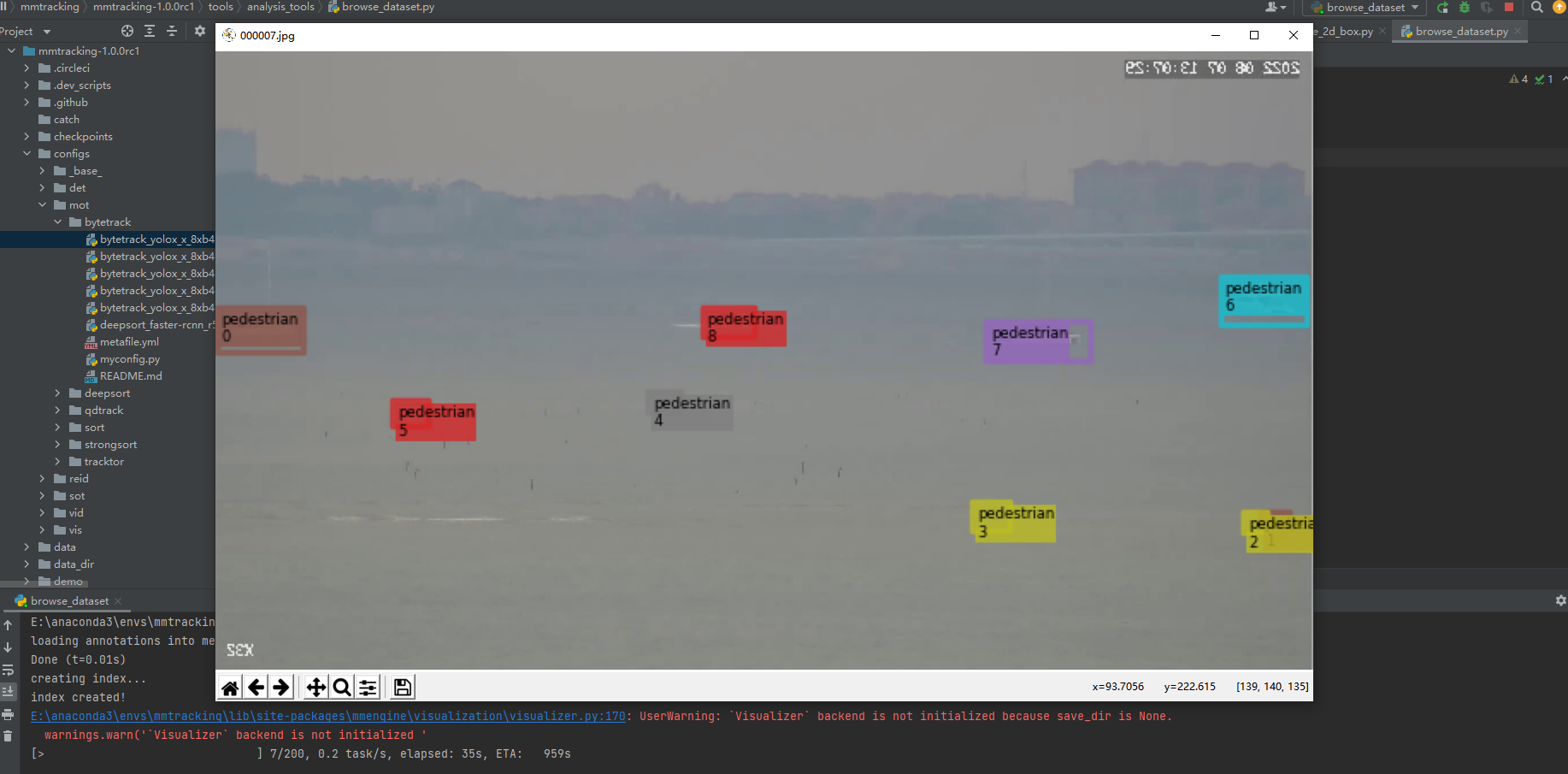
我们来一个更具体的栗子(可视化需要一个json文件): 再config文件中修改 train_pipeline 和 train_dataloader 即可实现MOT任务的数据集可视化(这部分代码其实是抄)mmtracking-1.0.0rc1\configs\_base_\datasets\youtube_vis.py的,当时是为了验证mot2coco的格式是否正确。
train_pipeline = [
dict(
type='TransformBroadcaster',
share_random_params=True,
transforms=[
dict(type='LoadImageFromFile'),
dict(
type='LoadTrackAnnotations',
with_instance_id=True,
with_bbox=True),
dict(type='mmdet.Resize', scale=(640, 360), keep_ratio=True),
dict(type='mmdet.RandomFlip', prob=0.5),
]),
dict(type='PackTrackInputs', ref_prefix='ref', num_key_frames=1)
]
train_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='mmdet.AspectRatioBatchSampler'),
dataset=dict(
type='MOTChallengeDataset',
data_root='../data/xx/',
ann_file='annotations/train_cocoformat.json',
data_prefix=dict(img_path='train'),
pipeline=train_pipeline,
load_as_video=True,
ref_img_sampler=dict(
num_ref_imgs=1,
frame_range=100,
filter_key_img=True,
method='uniform')))效果如下: