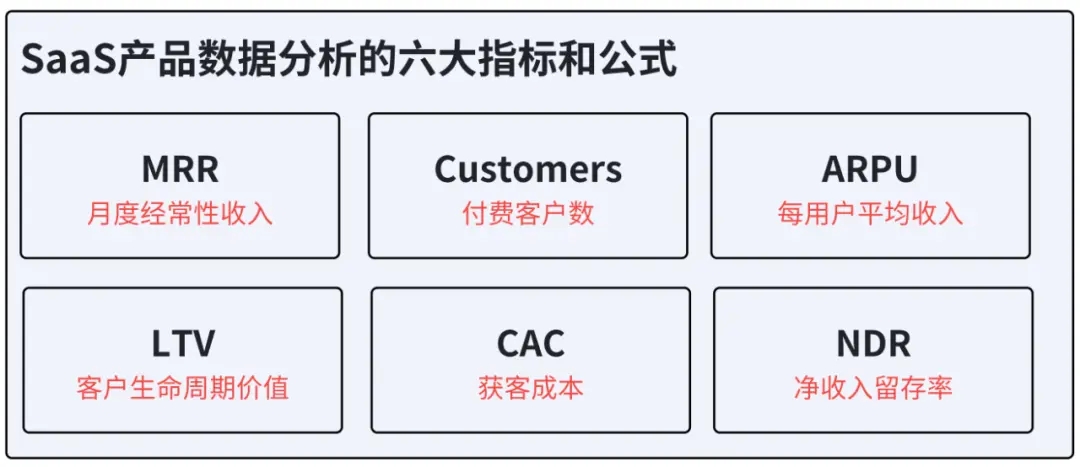
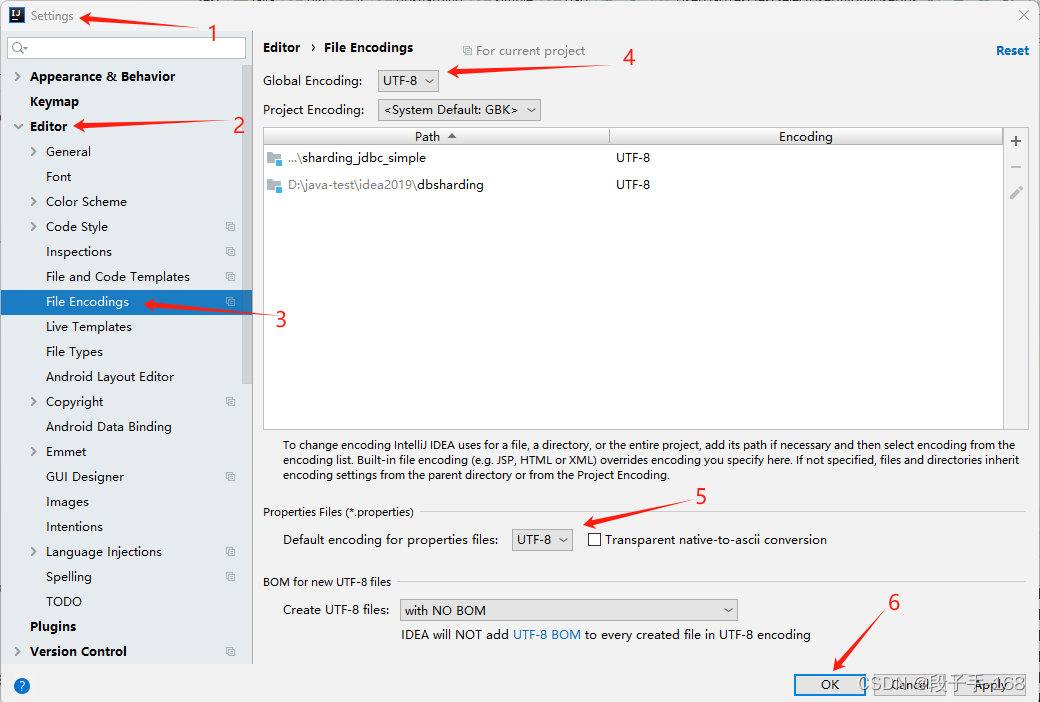
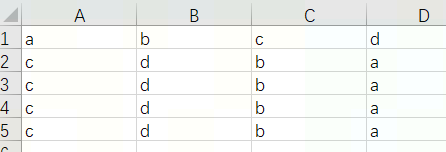
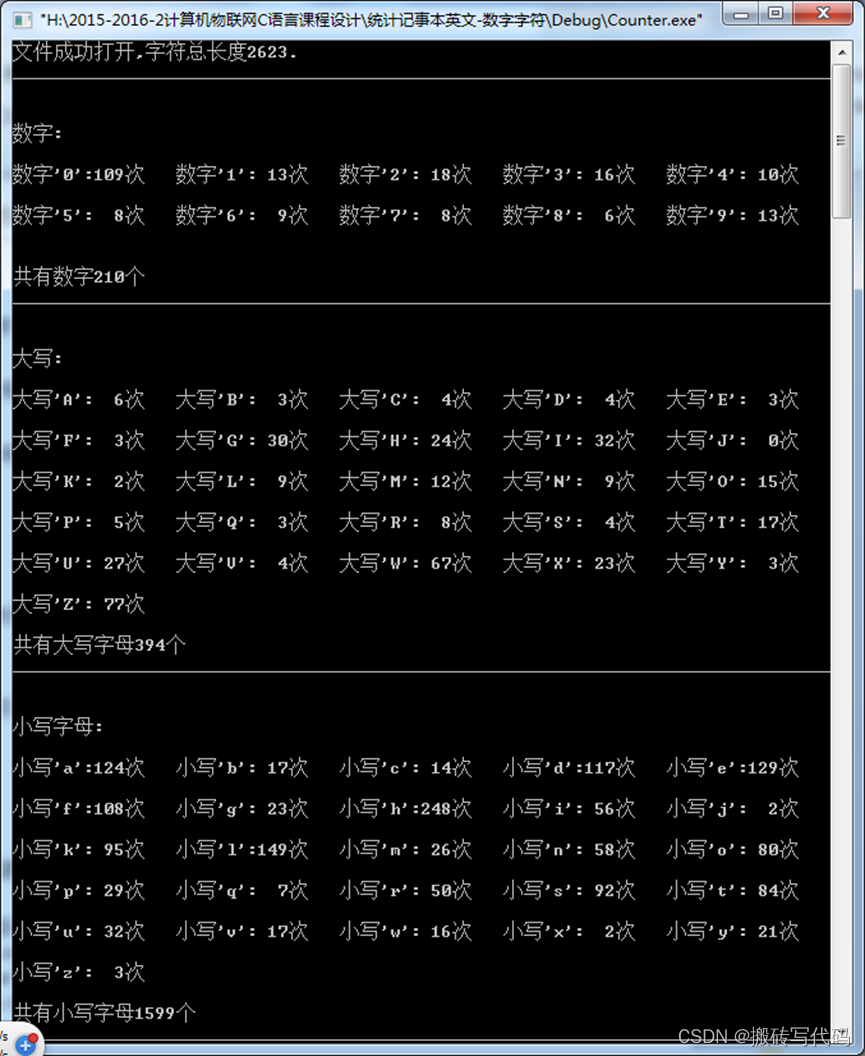
论文“”https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_DUSt3R_Geometric_3D_Vision_Made_Easy_CVPR_2024_paper.pdf
代码:GitHub - naver/dust3r: DUSt3R: Geometric 3D Vision Made Easy
DUSt3R是一种旨在简化几何3D视觉任务的新框架。作者着重于使3D重建过程更加易于使用和高效。该框架利用深度学习和几何处理的最新进展,提高了准确性并降低了计算复杂性。
1 摘要
本文提出了DUSt3R,一种无需相机校准或视点位置信息即可处理任意图像集合的密集、无约束立体3D重建的全新范式。我们将成对重建问题视为点图的回归,放宽了传统投影相机模型的硬约束。这种方法统一了单目和双目重建案例。
在提供多于两张图像的情况下,我们进一步提出了一种简单但有效的全局对齐策略,将所有成对点图表达在一个共同的参考框架中。我们基于标准Transformer编码器和解码器的网络架构,利用强大的预训练模型。
我们的方法直接提供了场景的3D模型以及深度信息,并且可以从中无缝地恢复像素匹配、焦距、相对和绝对相机参数。在单目和多视图深度估计以及相对姿态估计方面的广泛实验展示了DUSt3R如何有效地统一各种3D视觉任务,创造新的性能记录。总而言之,DUSt3R使许多几何3D视觉任务变得简单。
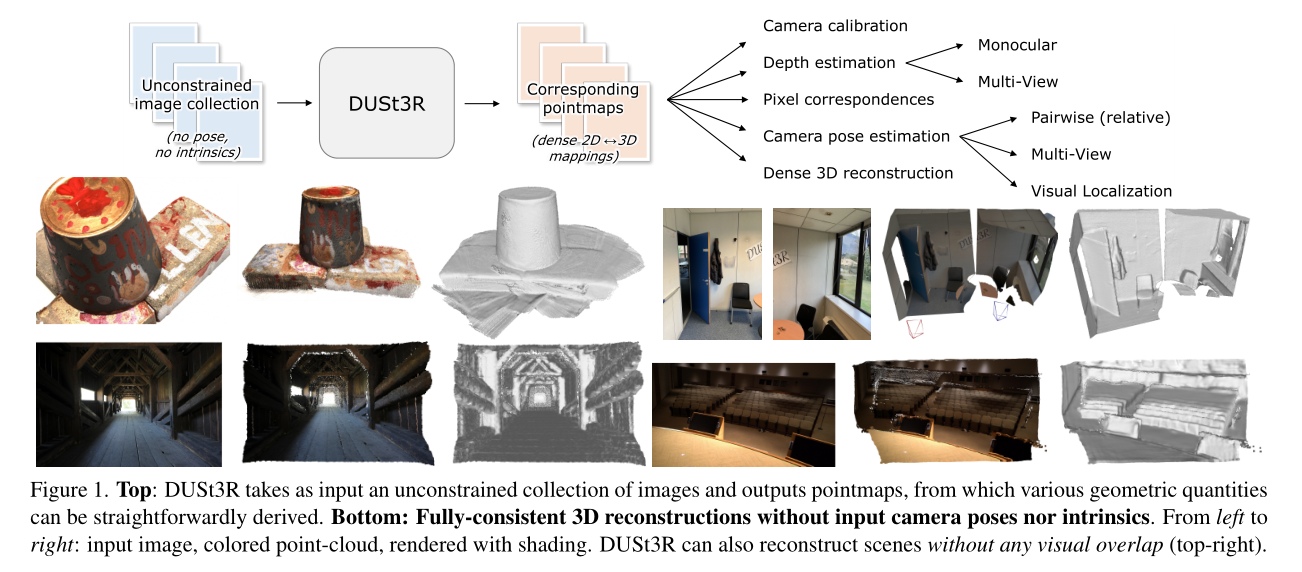
图1展示了DUSt3R的工作流程和重建效果。
上半部分:DUSt3R以一组不受约束的图像为输入,输出点图(pointmaps),从这些点图可以直接推导出各种几何量。
下半部分:展示了DUSt3R在没有输入相机位姿或内参的情况下进行的一致3D重建。从左到右依次是输入图像、彩色点云、带有阴影的渲染。右上角的图示例展示了DUSt3R在没有视觉重叠的情况下也能进行场景重建。
2 主要贡献
- 简化的流程:DUSt3R将传统的多步骤3D视觉流程简化为一个更直接的过程。这种简化有助于减少错误并提高可用性。
- 鲁棒性:该框架在各种数据集和场景中表现出鲁棒性,包括不同的光照条件和遮挡情况。
- 高效性:通过优化算法组件和实现方式,DUSt3R在不牺牲准确性的情况下,实现了显著的计算效率提升。
3 核心算法:

DUSt3R算法结合了现代深度学习技术和传统几何方法,通过高效的点云生成和三维重建技术,提供高精度和高鲁棒性的三维重建结果。
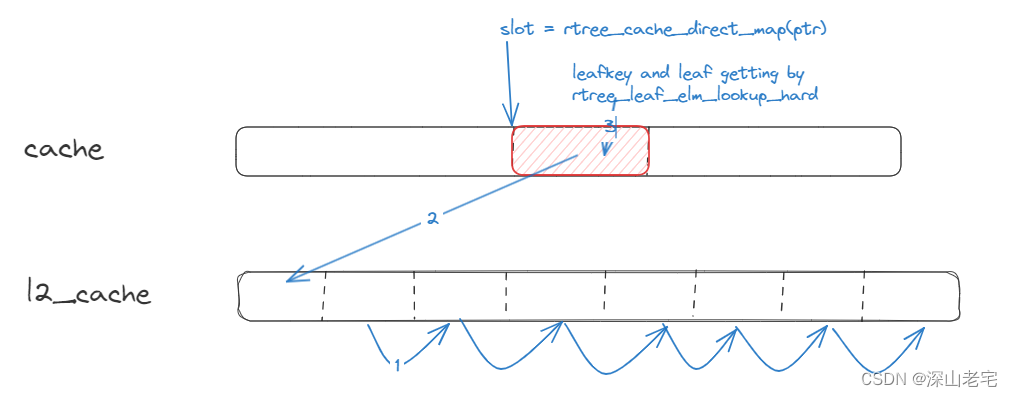
4 DUSt3R网络的架构及其主要组件
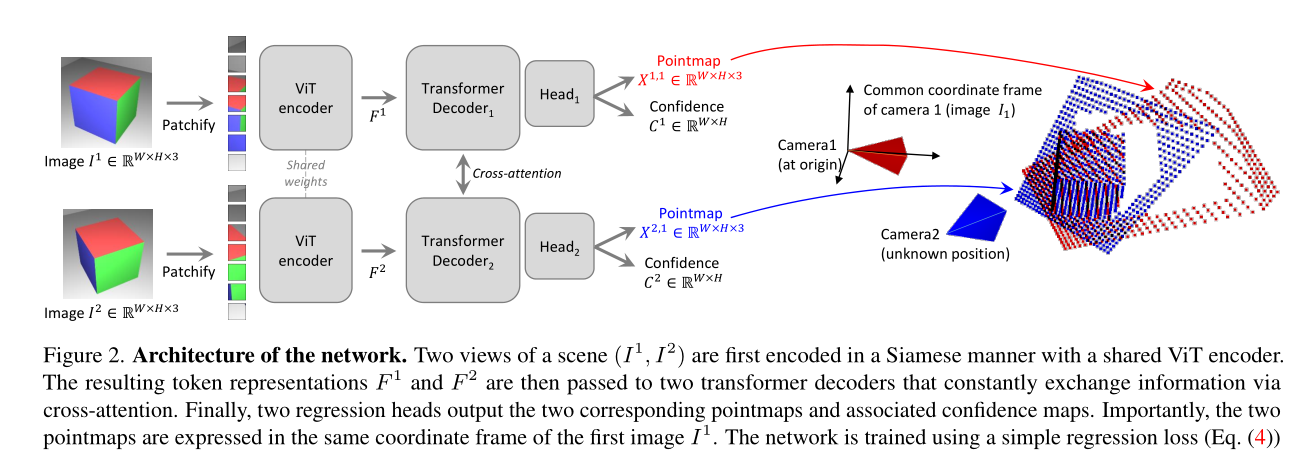
图2展示了DUSt3R网络的架构及其主要组件。这张图形象地说明了网络如何处理输入的两张RGB图像(I1和I2),并生成对应的点云图(Pointmap)和置信度图(Confidence Map)。
网络架构
-
输入图像
输入是两张RGB图像,分别表示为I1和I2。I1表示由第一个相机拍摄的图像,I2表示由第二个相机拍摄的图像。
-
ViT编码器(ViT Encoder)
输入图像I1和I2首先经过一个共享权重的ViT编码器进行特征提取。ViT编码器是一种基于视觉Transformer(ViT)的模型,用于将图像转化为Token表示(Token Representation)。编码后的特征表示分别为F1和F2。
-
Patchify
编码器输出的Token表示F1和F2会被划分成小块(Patchify),每个块表示图像的一部分。
-
Transformer解码器(Transformer Decoder)
经过Patchify处理后的特征表示F1和F2分别输入到两个Transformer解码器中,这两个解码器通过交叉注意力机制不断交换信息。交叉注意力机制允许解码器在解码过程中综合两张图像的信息,从而提高点云图的精度。
-
回归头(Regression Head)
Transformer解码器的输出结果传递给两个回归头,分别对应输入的两张图像。回归头负责生成最终的点云图(X1,1和X2,1)和置信度图(C1,1和C2,1)。
-
输出
最终输出的点云图(X1,1和X2,1)和置信度图(C1,1和C2,1)都以第一张图像(I1)的坐标系为基准。这种设计简化了后续的处理步骤,使得点云图可以直接在同一坐标系下进行操作和分析。
训练过程
- 损失函数
- 网络使用简单的回归损失函数(公式4)进行训练。损失函数基于预测的点云图和真实点云图之间的欧几里得距离进行计算。
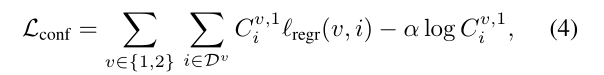
- 为了应对尺度模糊性,网络对预测和真实的点云图进行归一化处理,通过计算所有有效点到原点的平均距离来确定缩放因子。
- 网络还会学习为每个像素预测一个置信度分数,这个置信度分数表示网络对该像素预测的可靠程度。最终的训练目标是置信度加权的回归损失。
5 实验评估
5.1 无地图视觉定位
数据集:使用了Map-free relocalization benchmark,这是一项非常具有挑战性的测试,其中目标是在没有地图的情况下,仅凭一张参考图像确定相机在公制空间中的位置。测试集包括65个验证场景和130个测试场景。每个场景中,每帧视频剪辑的姿势必须相对于单个参考图像独立估计。
协议:评价标准包括绝对相机姿态准确性(以5°和25厘米为阈值)和虚拟对应重投影误差(VCRE),后者测量虚拟3D点根据真实和估计相机姿态重投影误差的平均欧氏距离。
结果:DUSt3R在测试集上的表现优于所有现有方法,有时优势显著,定位误差小于1米。
5.2 恢复未知相机内参
数据集:使用了BLUBB数据集来评估DUSt3R在没有内参信息的情况下恢复相机内参的能力。数据集提供了一系列场景,每个场景都具有已知的地面真实相机内参和3D点云。
协议:评价标准包括相机内参的准确性和重建的3D点云的完整性。DUSt3R通过估计场景的相对姿态和尺度,结合已知的地面真实3D点云来恢复内参。
结果:在没有先验相机信息的情况下,DUSt3R达到了平均2.7毫米的准确性,0.8毫米的完整性,总体平均距离为1.7毫米。这个精度水平在实际应用中非常有用,考虑到其即插即用的特性。
5.3 总结
DUSt3R在多个3D视觉任务中展示了其卓越的性能,无需对特定下游任务进行微调。该模型在零样本设置下取得了令人印象深刻的结果,特别是在无地图视觉定位和未知相机内参恢复任务中表现出色。实验结果表明,DUSt3R不仅适用于3D重建任务,还能有效处理各种3D视觉任务,展示了其广泛的应用潜力和实际使用价值。
5.4 可视化
论文包含了大量可视化内容,有助于理解概念和结果。这些包括流程图、架构细节和重建3D模型的视觉比较。

图3展示了两个场景的重建例子,这两个场景在训练期间从未见过。图像从左到右依次是:RGB图像、深度图、置信度图和重建结果。以下是对每部分的详细解析:
RGB图像:
- 这是输入的彩色图像,为网络提供了丰富的纹理和颜色信息,帮助进行3D重建。
深度图:
- 这是网络预测的深度图,表示场景中每个像素到相机的距离。深度值越大,像素点离相机越远。深度图为重建提供了基础的几何信息。
置信度图:
- 置信度图表示网络对每个像素深度预测的信心。高置信度区域通常表示预测较为准确的区域,而低置信度区域可能包含难以预测的部分,如天空、透明物体或反光表面。
重建结果:
- 左边的场景显示了直接从网络f(I1, I2)输出的原始结果。可以看到,网络已经能够较为准确地重建场景的3D形状。
- 右边的场景显示了经过全局对齐(第3.4节)的结果。全局对齐步骤进一步优化了重建结果,使其更加精确和一致。
通过展示这些结果,图3强调了DUSt3R方法在不同场景中的鲁棒性和有效性,尤其是其在未见过的场景中的表现。此外,置信度图的引入使得网络能够在不确定区域进行自适应调整,提高了重建的整体质量。
结论
DUSt3R在几何3D视觉领域提供了显著的进步。其简化流程、结合鲁棒性和高效性,使其成为计算机视觉研究人员和从业者的宝贵工具。详细的实验评估和全面的可视化进一步加强了论文的贡献。
![错误 [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试 python ping](https://img-blog.csdnimg.cn/direct/d496784cf37d49e389ad0b8eaa503578.png)