这篇论文的标题是《STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis》,由Wenbin Li等人撰写。本文提出了一个名为STBench的基准,用于评估大型语言模型(LLMs)在时空分析中的能力。以下是对论文的摘要、主要方法、贡献、创新方面以及方法的优缺点的评论:
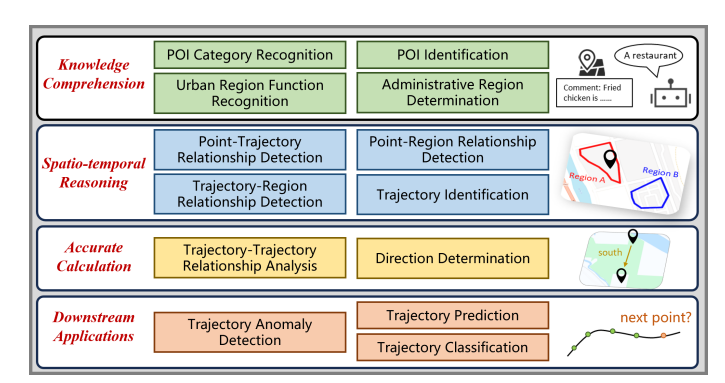
STBench概述。它包括四个维度的13个不同任务:知识理解、时空推理、精确计算和下游应用。
摘要
论文旨在评估LLMs在时空数据挖掘中的能力。作者指出,目前的评估方法存在局限性和偏见,缺乏对最新语言模型的评估,且主要集中于记忆化的时空知识评估。为此,本文将LLMs的时空数据能力分为知识理解、时空推理、精确计算和下游应用四个维度,并为每个类别设计了自然语言问答任务,构建了包含13个不同任务和超过60,000个问答对的基准数据集STBench。实验结果显示,现有LLMs在知识理解和时空推理任务上表现优异,但在其他任务上仍有提升空间。STBench的代码和数据集已公开发布。
主要方法
论文将LLMs的时空分析能力分为四个维度:
知识理解任务
- 兴趣点类别识别(POI Category Recognition, PCR):
- 评估模型理解兴趣点(POI)语义的能力。数据样本基于Yelp数据集,模型需要根据兴趣点的坐标和评论预测其类别。
- 兴趣点识别(POI Identification, PI):
- 判断两个给定的POI是否为同一个。模型需要根据坐标和评论来确定两者是否描述相同的POI。
- 城市区域功能识别(Urban Region Function Recognition, URFR):
- 根据区域边界和区域内POI预测城市区域功能。数据样本从New Orleans区域数据集中提取,模型需要根据提供的坐标和评论来预测区域功能。
- 行政区划确定(Administrative Region Determination, ARD):
- 确定给定坐标所在的行政区划。数据样本基于Yelp数据集,模型需要回答给定坐标属于哪个城市。
时空推理任务
- 点-轨迹关系检测(Point-Trajectory Relationship Detection, PTRD):
- 判断一条轨迹是否经过某个点。数据样本基于西安数据集,模型需要确定轨迹是否经过给定的选项点。
- 点-区域关系检测(Point-Region Relationship Detection, PRRD):
- 判断给定的点落在哪个区域。数据样本基于EULUC数据集,模型需要根据点的坐标和区域边界来推断点所在的区域。
- 轨迹-区域关系检测(Trajectory-Region Relationship Detection, TRRD):
- 判断一条轨迹经过哪些区域。数据样本基于EULUC数据集,模型需要根据轨迹和区域信息来确定轨迹经过的区域序列。
- 轨迹识别(Trajectory Identification, TI):
- 判断两条轨迹是否来自同一条轨迹。数据样本基于西安数据集,模型需要通过下采样和错位采样策略来确定两条轨迹是否相同。
精确计算任务
- 方向确定(Direction Determination, DD):
- 确定两个地理点之间的方向。数据样本基于Yelp数据集,模型需要计算方位角并确定相对方向。
- 轨迹-轨迹关系分析(Trajectory-Trajectory Relationship Analysis, TTRA):
- 计算两条轨迹相遇的次数。数据样本通过在特定区域内的随机游走生成,模型需要确定轨迹在空间和时间上的相交次数。
下游应用任务
- 轨迹异常检测(Trajectory Anomaly Detection, TAD):
- 检测异常轨迹。数据样本基于西安数据集,模型需要识别正常和异常的轨迹样本。
- 轨迹分类(Trajectory Classification, TC):
- 根据轨迹的坐标、长度和速度等信息区分不同的轨迹。数据样本基于Geolife数据集,模型需要根据下采样后的轨迹推断其产生方式(自行车、汽车或行人)。
- 轨迹预测(Trajectory Prediction, TP):
- 根据历史轨迹点预测下一个点。数据样本基于西安数据集,模型需要根据提供的历史点预测轨迹的下一个点的坐标。
通过这些任务,STBench能够全面评估大型语言模型在处理时空数据方面的能力,揭示其在知识理解和时空推理任务上的优势以及在精确计算和下游应用任务上的不足 。
贡献
- 提出了一套全面评估LLMs在时空分析能力的基准数据集STBench。
- 系统地评估了13个最新的LLMs在不同任务上的表现,揭示了它们在知识理解和时空推理任务上的优异表现,以及在精确计算和下游应用任务上的不足。
- 验证了在情境学习、思维链提示和微调等技术对提升模型表现的潜力。
创新方面
- 系统化地将时空数据能力分为四个维度进行评估,比以往仅关注单一维度的评估方法更全面。
- 创建了一个大规模的基准数据集,包含60,000多个QA对,覆盖了多种时空任务。
方法的优缺点
优点:
- 全面性:评估维度全面,覆盖了知识理解、时空推理、精确计算和下游应用四个方面。
- 规模大:数据集规模大,提供了丰富的评估样本,有助于全面评估模型的能力。
- 公开性:数据集和代码公开,方便研究人员复现和进一步研究。
缺点:
- 计算成本高:全面评估LLMs需要高昂的计算资源,尤其是在处理大规模数据集和进行多模型比较时。
- 模型更新快:由于LLMs发展迅速,新模型不断出现,评估结果可能很快过时。
结论
本文提出的STBench为评估LLMs在时空数据分析中的能力提供了一个系统和全面的方法。通过实验验证,现有LLMs在知识理解和时空推理任务上表现优异,但在精确计算和下游应用上仍需改进。通过情境学习、思维链提示和微调等技术,有望进一步提升模型在这些任务上的表现。
下载地址
链接:https://pan.quark.cn/s/7d4f538d1778