mysql 中文乱码问题分析
一、问题分析:
MySQL 中文乱码通常是因为字符集设置不正确导致的。MySQL 有多种字符集,如 latin1、utf8、utf8mb4 等,如果在创建数据库、数据表或者字段时没有指定正确的字符集,或者在插入数据时使用了与数据库字符集不一致的编码,就可能出现乱码。
二、解决方法:
1、确认当前 MySQL 的默认字符集。
在创建数据库、数据表或字段时,明确指定字符集为 utf8(MySQL 5.5.3以前)或 utf8mb4(MySQL 5.5.3及以后,支持存储4字节字符,如部分表情符号)。
例如:
# 创建数据库:order_db, order_db_1, order_db_2, user_db 4个数据库。
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
CREATE DATABASE `order_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
CREATE DATABASE `order_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
# 在 数据库 order_db_1 中,创建两张表。
USE `order_db_1`;
# 创建 t_order_1 表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
# 创建 t_order_2 表
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
# 在数据库 user_db, order_db_1, order_db_2 三个数据库中,创建公共表 t_dict
USE user_db;
DROP TABLE IF EXISTS `t_dict`;
CREATE TABLE `t_dict` (
`dict_id` BIGINT(20) NOT NULL COMMENT '字典id',
`type` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 COLLATE = utf8_general_ci ROW_FORMAT=DYNAMIC;
USE order_db_1;
DROP TABLE IF EXISTS `t_dict`;
CREATE TABLE `t_dict` (
`dict_id` BIGINT(20) NOT NULL COMMENT '字典id',
`type` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 COLLATE = utf8_general_ci ROW_FORMAT=DYNAMIC;
USE order_db_2;
DROP TABLE IF EXISTS `t_dict`;
CREATE TABLE `t_dict` (
`dict_id` BIGINT(20) NOT NULL COMMENT '字典id',
`type` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8 COLLATE = utf8_general_ci ROW_FORMAT=DYNAMIC;
# 在 user_db 数据库中,创建 t_user 表:
USE `user_db`;
# 创建 t_user 表
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` BIGINT(20) NOT NULL COMMENT '用户id',
`fullname` VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户姓名',
`user_type` CHAR(1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY(`user_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
2、如果已经出现乱码,可以通过以下 SQL 命令修改数据表或列的字符集:
# 查看字符编码:
SHOW VARIABLES LIKE "char%";
# 修改数据表或列的字符集
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# 例如:在 user_db 数据库中,修改表 t_user
ALTER TABLE t_user CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE t_user CHANGE fullname fullname VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci;
3、确保在插入数据时使用的客户端和连接字符串中指定了正确的字符集,例如在 MySQL 客户端连接时使用SET NAMES ‘utf8mb4’。
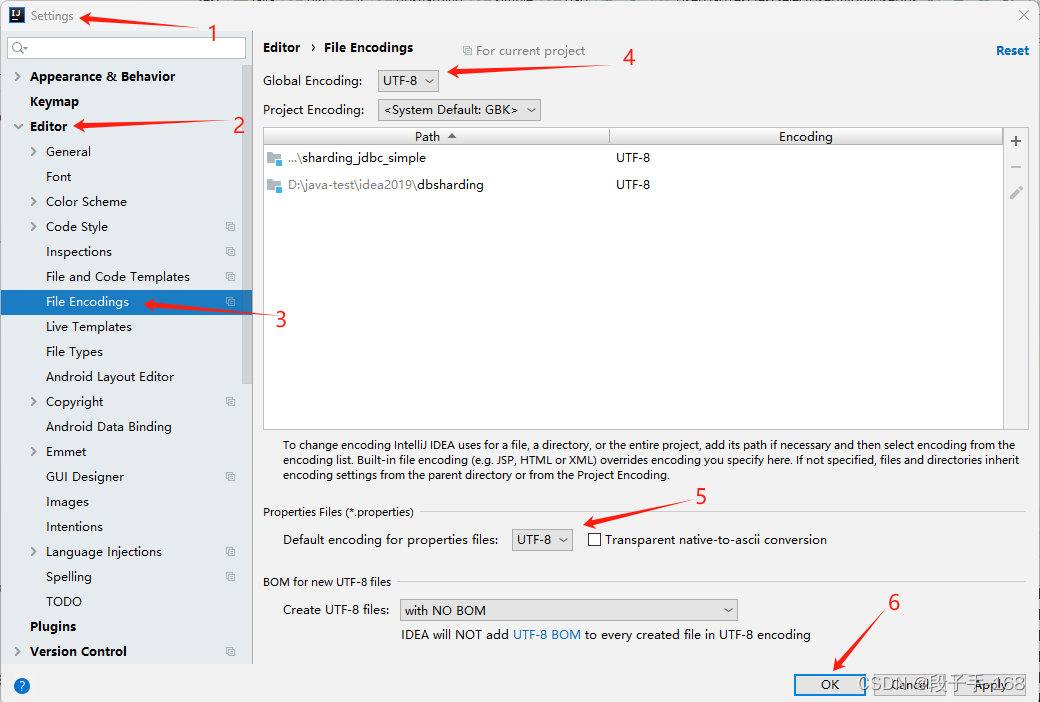
如:在 idea 中设置字符集:
idea ---> File ---> Setting...
---> Editor
---> File Encodings
---> utf8
4、如果是从文件导入数据出现乱码,确保文件的编码格式正确,并且在导入时指定了正确的字符集。
5、检查 MySQL 的配置文件 my.cnf(linux) 或 my.ini(windows),确保在 [mysqld] 部分设置了正确的字符集,例如:
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
6、修改配置后需要重启 MySQL 服务。
net stop mysql80
net start mysql80
7、注意:在修改字符集时,需要确保数据库中数据的兼容性,避免数据损坏。在做任何修改前,应该备份数据库。
8、java 后台代码 设置 utf8 字符编码乱码问题
乱码问题通常发生在字符编码不一致时,导致字符显示不正确。在 Java 后端设置 UTF-8 编码主要涉及到以下几个方面:
-
1)设置服务器接收请求和发送响应时使用UTF-8编码。
-
2)设置数据库连接和查询使用 UTF-8 编码。
-
3)设置应用服务器(如Tomcat)的默认编码为 UTF-8。
8.1 在 Servlet 中设置请求和响应编码:
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");
8.2 在数据库连接中设置编码:
String url = "jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8";
8.3 设置 Tomcat 默认编码(在 server.xml 中):
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
URIEncoding="UTF-8" />
<!-- 如果使用 Spring 框架,可以在配置文件中设置:-->
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="properties">
<props>
<prop key="fileEncoding">UTF-8</prop>
</props>
</property>
</bean>