支持向量机(SVM)是一种监督机器学习算法,可用于分类和回归任务。在本文中,我们将重点关注使用SVM进行图像分类。
当计算机处理图像时,它将其视为二维像素阵列。数组的大小对应于图像的分辨率,例如,如果图像是200像素宽和200像素高,则数组的尺寸为200 x 200 x 3。前两个维度分别表示图像的宽度和高度,而第三个维度表示RGB颜色通道。数组中的值范围为0到255,表示每个点处像素的强度。
为了使用SVM对图像进行分类,我们首先需要从图像中提取特征。这些特征可以是像素的颜色值、边缘检测,甚至是图像中存在的纹理。一旦提取了特征,我们就可以将它们用作SVM算法的输入。
SVM算法通过寻找在特征空间中分离不同类的超平面来工作。支持向量机背后的关键思想是找到最大化边缘的超平面,边缘是不同类的最近点之间的距离。最接近超平面的点称为支持向量。
使用SVM进行图像分类的主要优点之一是它们可以有效地处理高维数据,例如图像。此外,SVM比其他算法(如神经网络)更不容易过拟合。
在机器学习中,模型由输入数据和预期输出数据训练。
步骤1:导入所需的库
import pandas as pd
import os
from skimage.transform import resize
from skimage.io import imread
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
步骤2:加载图像并将其转换为数据帧
Categories=['cats','dogs']
flat_data_arr=[] #input array
target_arr=[] #output array
datadir='IMAGES/'
#path which contains all the categories of images
for i in Categories:
print(f'loading... category : {i}')
path=os.path.join(datadir,i)
for img in os.listdir(path):
img_array=imread(os.path.join(path,img))
img_resized=resize(img_array,(150,150,3))
flat_data_arr.append(img_resized.flatten())
target_arr.append(Categories.index(i))
print(f'loaded category:{i} successfully')
flat_data=np.array(flat_data_arr)
target=np.array(target_arr)
输出
loading... category : cats
loaded category:Cats successfully
loading... category : dogs
loaded category:Dogs successfully
上面提供的代码执行了一系列必要的步骤来读取,预处理和组织机器学习的图像数据。首先,导入必要的包,包括用于图像处理的scikit-image,用于数据操作的pandas和用于数学计算的numpy。定义“类别”列表以表示将用于训练机器学习模型的图像类别。创建两个空数组来存储图像数据及其对应的标签。然后从指定的路径加载图像,读取并调整大小为150×150像素的固定大小,具有3个颜色通道,并展平为1D阵列。将展平的图像数据及其对应的标签(0表示“猫”,1表示“狗”)添加到数组中。数组被转换为pandas DataFrame,然后将其拆分为输入数据’x’(除最后一列外的所有列)和输出数据’y’(最后一列)。然后,可以使用得到的“x”和“y”数据来训练机器学习模型。使用的变量名是不言自明的,使代码易于理解和理解。总的来说,这段代码为机器学习提供了一种加载、处理和组织图像数据的清晰简洁的方式。
#dataframe
df=pd.DataFrame(flat_data)
df['Target']=target
df.shape
输出
(500, 67501)
步骤3:分离输入特征和目标
#input data
x=df.iloc[:,:-1]
#output data
y=df.iloc[:,-1]
步骤4:划分训练集和测试集
# Splitting the data into training and testing sets
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.20,
random_state=77,
stratify=y)
步骤5:构建和训练模型
这里的模型是支持向量机,它看起来像这样
# Defining the parameters grid for GridSearchCV
param_grid={'C':[0.1,1,10,100],
'gamma':[0.0001,0.001,0.1,1],
'kernel':['rbf','poly']}
# Creating a support vector classifier
svc=svm.SVC(probability=True)
# Creating a model using GridSearchCV with the parameters grid
model=GridSearchCV(svc,param_grid)
在上面提供的代码片段中,我们为GridSearchCV定义了参数grid。参数网格指定了我们想要调优的超参数,包括C、gamma和kernel。C是误差项的惩罚参数,gamma是核系数,并且核是核类型。我们为每个超参数提供一系列值,GridSearchCV将对所有可能的超参数组合进行穷举搜索,以找到最佳值。
接下来,我们创建一个SVM分类器的实例,并将“probability”参数设置为True。这是因为我们稍后将使用分类器的“predict_proba()”方法来获取类概率。然后将SVM分类器和参数网格传递给GridSearchCV,以创建一个模型,该模型将为SVM算法找到最佳超参数。
通过使用GridSearchCV,我们可以找到超参数的最佳组合,这将导致模型的最高精度。这将有助于我们从SVM模型中获得最佳性能。
我们将数据分为训练集和测试集,然后使用训练数据训练模型。
# Training the model using the training data
model.fit(x_train,y_train)
在预处理数据集并使用GridSearchCV创建SVM模型之后,我们可以使用scikit-learn库中的train_test_split函数将数据集分为训练集和测试集。此函数根据指定的测试大小和随机状态将数据随机拆分为训练集和测试集。在这种情况下,我们将测试大小设置为0.20,这意味着20%的数据将用于测试,随机状态设置为77以获得再现性。
分割数据后,我们可以使用训练数据来训练模型,方法是在我们使用GridSearchCV创建的模型对象上调用fit方法。这将使用从GridSearchCV获得的超参数的最佳组合来训练模型。
我们可以打印一条消息,表明模型已经使用给定的图像成功训练。
我们还可以使用模型对象的best_params_属性打印从GridSearchCV获得的最佳参数。这将显示我们在参数网格中定义的C、gamma和内核参数的最佳值。
我们可以评估SVM模型对未知数据的性能。这有助于我们确保模型能够很好地泛化,并且不会过度拟合训练数据。
步骤6:模型评估
现在使用测试数据以这种方式对模型进行测试,模型的准确性可以使用sklearn.metrics中的accuracy_score()方法计算。
# Testing the model using the testing data
y_pred = model.predict(x_test)
# Calculating the accuracy of the model
accuracy = accuracy_score(y_pred, y_test)
# Print the accuracy of the model
print(f"The model is {accuracy*100}% accurate")
输出
The model is 59.0% accurate
在训练SVM模型之后,我们需要测试模型,看看它在新的、看不见的数据上的表现如何。为了测试模型,我们将使用之前使用scikit-learn库中的train_test_split函数分割的测试数据。
我们使用训练模型的预测方法来预测测试数据的类标签。预测的标签存储在y_pred变量中。
为了评估模型的性能,我们使用scikit-learn metrics模块中的accuracy_score方法计算模型的准确度。准确性分数测量所有数据点中正确分类的数据点的百分比。准确性分数的计算方法是将预测的标签与实际标签进行比较,然后将正确预测的数量除以数据点的总数。
我们打印测试数据的预测和实际标签,然后是模型对测试数据的准确性。
现在我们可以使用scikit-learn的classification_report函数为SVM模型生成分类报告。下面是一个示例代码片段:
print(classification_report(y_test, y_pred, target_names=['cat', 'dog']))
输出
precision recall f1-score support
cat 0.57 0.72 0.64 50
dog 0.62 0.46 0.53 50
accuracy 0.59 100
macro avg 0.60 0.59 0.58 100
weighted avg 0.60 0.59 0.58 100
步骤7:预测
path='dataset/test_set/dogs/dog.4001.jpg'
img=imread(path)
plt.imshow(img)
plt.show()
img_resize=resize(img,(150,150,3))
l=[img_resize.flatten()]
probability=model.predict_proba(l)
for ind,val in enumerate(Categories):
print(f'{val} = {probability[0][ind]*100}%')
print("The predicted image is : "+Categories[model.predict(l)[0]])
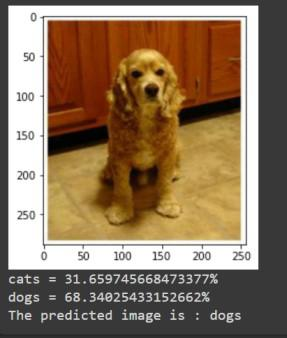
我们的模型的准确率为0.59,这意味着它正确地分类了测试集中59%的图像。这两个类的F1分数在0.5和0.7之间,这表明模型的性能是中等的。
总结
本文的目标是创建和训练支持向量机(SVM)模型,以准确地分类猫和狗的图像。使用GridSearchCV确定SVM模型的最佳参数,并测量模型的准确性。