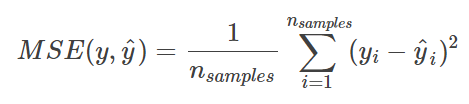ABSTRACT
个体树木分割 (ITS) 或树木计数是精准林业和农业过程中的一项基础工作。与费时费力的人工检查不同,计算机视觉在基于无人机 (UAV) 的应用中显示出巨大的前景;此类应用之一包括森林资源清单中的自动树木计数问题。然而,由于树冠冠层的特殊性,如颜色渐变、形状不确定、重叠等,很难获得单株树。在这项研究中,我们提出了一个基于监督数据聚类的学习框架。在这里,ITS 和树木计数都可以从二维 (2D) 顶视图树冠中准确并同时获得,无论它们是孤立的、重叠的还是两者兼而有之。像素精度分类器用于识别树像素或超像素(一组有意义的像素),而不是使用复杂的图像预处理或特征构建技术。然后通过所提出的监督聚类方法将获得的树超像素分组为单独的树。为了获得准确的 ITS 和树数,用于聚类的相似性是从用户提供的监督中“学习”的,而不是像现有的最先进方法那样“预先指定”或“网格搜索” .这项研究还包括对同质和异质高分辨率图像的广泛实验比较。结果表明,我们的方法在可视化 ITS 和数字树木计数结果方面均优于最先进的方法,甚至可与人类视觉相媲美。它在 R 2 R^2 R2值方面实现了 99.16% 的计数精度,在像素平均绝对误差 (MAE) 方面实现了 2.2923。这些分别比第二好的方法高 22.04% 和低 8.727%。
1. Introduction
森林在维持水循环、涵养土壤、固碳、保护人畜栖息地等方面,在世界生态环境中发挥着不可替代的作用(Yao et al, 2021)。为了实现这些目标,各国政府和组织在全球范围内对植树造林、环境管理、生态保护和恢复投入了更多的精力(Sun 等人,2022a,2022b)。作为一些最重要的遥感 (RS) 技术,基于无人机的技术已普遍用于树木覆盖率百分比、土地覆盖测绘、土壤管理以及植物和树木的疾病检测(Donmez 等人,2021 年)。其中,个体树木分割和树木计数是精准林业和农业的一项基础性工作。
个体树木分割 (ITS) 是林业和农业实践的有效应用。它涉及森林生物量预测(Xu 等人,2021 年)、荒漠化控制(Ng 等人,2017 年)、绿色覆盖或碳储量估算(Sun 等人,2019 年)、品种中个体树木或植物的数量(Graves et al, 2018),树种分类(Yan et al, 2021)。在这项研究中,我们关注与 ITS 相关的树木计数问题,以便于可视化。在机器学习领域,现有的方法可以分为三类:形态学或图像处理、数据聚类和基于模型的方法。在第一类中,典型的技术包括分水岭分割、区域生长、模板匹配(Norzaki 和 Tahar,2019;Koc-San 等,2018)和形态学方法(Jing 等,2012;Santoso 等,2016;Hui 等2022 年)。例如,多尺度勾画或分割旨在获得多个分割图,例如通过分水岭分割或区域生长,然后将它们整合在一起生成整体树冠图(Jing et al, 2012; Hu et al, 2014; Yang 等人,2016 年;Miraki 等人,2021 年;Hui 等人,2022 年)。相比之下,基于聚类的方法更直观,它试图通过算法本身来识别植物冠的特征,找出每个簇形成的个体,从而摆脱高度依赖给定数据的困境。例如, Reza 等人 (2019) 使用 k-means 检测水稻的籽粒面积以进行产量估算。同时,Diez 等人 (2020) 将多种数据聚类方法引入树梢检测,并通过实验得出结论,基于聚类数不固定密度的噪声应用空间聚类 (DBSCAN) 优于聚类数固定的 k 均值和模糊C 均值 (FCM)。此外,Grados 等人 (2020) 旨在对简单线性迭代聚类 (SLIC) 超像素(一组有意义的像素)进行聚类,以通过亲和传播 (AP) 来描绘单个植物。后来,Li等(2022)实现了城市行道树的完整个体提取,其中层次聚类(HC)用于分割重叠的树冠。基于模型的方法,尤其是深度网络,现在在林业和农业应用中占据主导地位,随着计算机视觉和二维(2D)和三维(3D)图像数据采集以及激光雷达的快速发展点云 (Sun et al, 2022a, 2022b; Xue et al, 2022)。 Fan 等人 (2018) 采用深度神经网络 (DNN) 从无人机图像中检测烟草植物。 Bayraktar 等人 (2020) 提出了一种使用 VGGNet–RetinaNet–YoloV3 对观赏植物进行计数的组合方法。为了对农作物进行计数,Valente 等人 (2020) 引入了 AlexNet 来识别所谓的植物单元。此后,使用像素比估计植物的数量。在刚性物体的检测中也可以观察到类似的计数问题;我们在这里举几个例子。
这些方法对于具有等面积树冠或明显的个体间间隙的植物(例如,烟草、观赏植物、农作物和油棕)可能是有效的。为了获得等面积的树冠,例如,Santoso 等人(2016)将油棕树分为多个年龄组,然后他们针对不同的组采用不同的树木检测方法。然而,这些等面积方法不适合我们关注的 ITS 和树木计数问题。原因有四:(1) 在实际应用中没有间隙或等面积树冠,因为在 2D 顶视图图像中,某些树冠树冠相互遮挡或重叠,而另一些树冠可能是孤立的。 (2) 俯视个体的树冠形状往往不清晰,尤其是同一树种的树冠。 (3) 子图分区可能会出现重复计数或漏计数的问题。这意味着对于高分辨率图像,牙冠可能会被分成多个部分(子牙冠)并出现在不同的子图像中。在这种情况下,由于对每个子图像进行树计数,即使准确检测到个体部分,也会导致重复计数问题。同样,也可能导致遗漏计数问题,例如,通过使用深度基于学习的方法,如果检测到的包含多个小区域个体的图像块样本被计为一棵树。 (4) 难度也来源于收集的数据,不管是2D图像还是3D点云。采集到的 RS 数据中肯定会出现冠部遮挡和重叠现象。此外,由于顶视图中的遮挡和投影,给定牙冠的形状也可能从准椭圆形变为不规则形。
在此,我们的目标是为 ITS 和树木计数问题开发一种新方法,无论这些树冠是孤立的、重叠的还是两者兼而有之。受数据聚类和人类视觉的启发,以下似乎是可行的:如果一组相似的树像素可以合并或浓缩成一个称为原型的点,并且在获得的原型上重复这种合并直到出现“差距”(原型合并不能cross) 时,最终的原型和原型总数可以作为我们想要的 ITS 和树数。在这种情况下,分割后的单个牙冠也可以准确地近似,例如,通过其原型的“中心”和“半径”。也就是说,我们的方法旨在通过监督聚类从重叠的树冠区域提高 ITS 的性能。更重要的是,应该“找到”一个合适的相似性度量,用于区分单个原型和冠的重叠区域。另一方面,为了充分利用高分辨率,树冠分割的精度要求很高,例如在像素精度级别,这与多尺度描绘有本质区别。为了实现这一目标,我们训练了一个像素分类器来识别树像素或原型,然后将它们馈送到建议的监督聚类中以进行最终的 ITS 和树木计数。总之,我们的工作与现有方法有三处不同: (1) 我们的方法使用监督聚类方法来分割个体,用学习的度量来掌握个体间的相似性。但是,现有的基于聚类的方法(例如,k-means 和 FCM)无法分割冠,因为这些需要预先指定的簇数 (NoC)。此 NoC 是所需的计数数。相比之下,尽管 NoC-unknown 聚类方法不需要预先指定 NoC,例如 DBSCAN,但由于没有适当的终止条件,迭代通常难以控制。对于重叠的树冠尤其如此,它们可能聚集在一起,因此被错误地算作一棵树。 (2) 为方便起见,在收集到的像素模式样本上训练像素分类器对树像素或超像素进行分类,而不是像现有的基于模型的方法那样进行复杂的图像预处理、特征构建或多方法组合。 (3) 我们采用浅层学习以获得高精度和可解释性。与主流深度网络相比,计算机视觉领域的科学家和技术人员普遍认为这些缺乏可解释性、鲁棒性和泛化性。更糟糕的是,单像素攻击可以完全逆转深度网络的判别结果(Su 等人,2019)。
为了阐明我们的动机,图 1 显示了一个示例。超像素分割后,树超像素被识别,即初始原型,如图 1(b)中的青色区域所示。然后使用 DBSCAN 和我们的监督聚类方法对这些原型进行分组。最终结果分别如图 1(c)和(d)所示。在这里,每个带有红色数字的青色区域代表一个单独的树分割。然而,一些重叠的树冠被 DBSCAN 过度合并,例如,图 1(c)中的错误区域“1”和“3”。相比之下,由于在监督聚类中使用了“学习”指标,我们的 ITS 结果更加准确,无论这些冠是孤立的还是重叠的。
本文的其余部分安排如下。第 2 节描述了研究地点和基于无人机的图像采集设备。第 3 节详细介绍了我们提出的方法,包括像素分类器、树超像素提取和用于准确 ITS 或树计数的监督聚类。第 4 节介绍了实验结果。本研究的讨论和结论分别在第 5 节和第 6 节中介绍。
2. Study materials
研究区位于河北省保定市雄安新区与中国林业科学研究院合作建设的试验林场内(见图2(a))。它是名为千年森林的造林项目的一部分,该项目已在 302 平方公里的土地上种植了 2300 万棵树。作为城市街区之间重要的生态缓冲区,该造林区旨在形成一个主要树种的森林系统:槐树(槐树)、白皮松(白皮松)、香柏(Sabina chinensis)、和 Liriodendron chinense(中国郁金香杨)。研究区树木分布密度不均匀。而且,会出现一个区域被大量树木覆盖,而相邻区域的树木分布均匀的情况。
在这项研究中,使用配备专业航拍相机(Zenmuse X4S)和多光谱相机(Parrot Sequoia)的 DJI Phantom 2 无人机进行图像采集。一体化无人机的有效载荷约为300克,安全飞行时间约为25分钟。机载设备还包括全球定位系统(GPS)接收器、惯性测量单元(IMU)和大疆制导视觉传感系统Matrice 100。Zenmuse X4S拥有1英寸传感器,有效像素2000万,动态范围11.6停止。水平方向可旋转±320°,垂直方向可旋转+40°–130°,控制精度为±0.01°。地面采样距离为 3.27 厘米/像素,飞行高度为 120 米。获得的高分辨率图像中有 29988 × 35547 RGB 像素(3.95 GB)。去除冗余区域,然后将其分成 144 个不相交的子图像 1,大小相等,大小为 2840 × 2400 像素(见图 2(b1)和(b2))。

图 1. 个体树分割和树计数示例。 (a) 是顶视图 RGB 图像,其中树冠重叠或隔离。 (b) 显示了由在 (a) 中的像素模式样本上训练的像素分类器检测到的树超像素。通过 DBSCAN 和我们提出的监督聚类方法获得的个体分割和树计数的结果分别显示在 © 和 (d) 中。
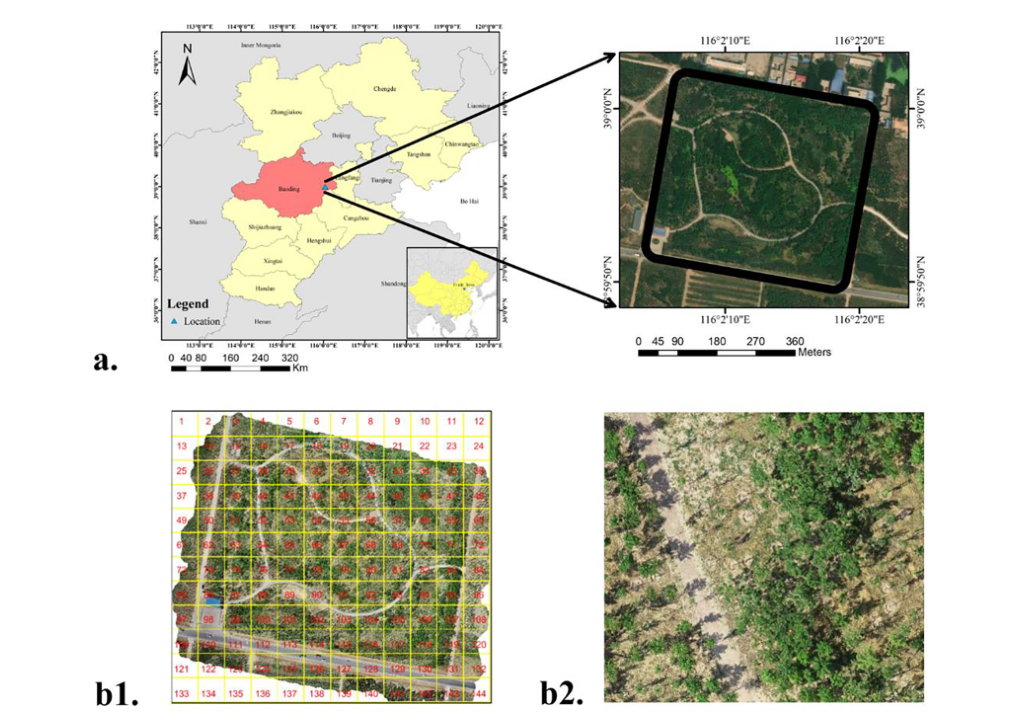
图 2. 研究区位置(中国保定)(a)(左)和顶视图卫星图像(右)。整个无人机图像及其不相交的分区如(b1)所示,而(b2)是子图像“42”的放大图。
3. Methods
我们的方法包括三个步骤:像素分类器训练、树超像素识别和监督聚类(见图 3)。在第一步中,训练了一个像素精度分类器来注释图像,这些图像将用于对树像素或超像素进行分类。其次,为了减少像素的数量并对有意义的像素进行分组,本研究采用 SLIC 技术(Achanta 等,2012)来形成粗粒度的超像素。然后由像素分类器识别树超像素。最后,所提出的监督聚类用于准确的 ITS 和树木计数。该过程的流程图如图 3 所示。
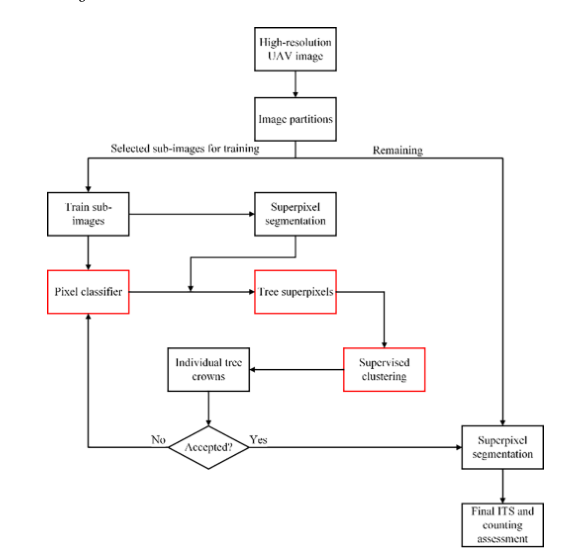
图 3. 我们提出的方法的流程图。在这里,三个主要步骤用红色框突出显示。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
3.1. Pixel classifier
我们尝试使用像素分类器来识别树像素,而不是应用复杂的图像预处理。选择基于 K 维 (K-d) 树的 k 最近邻 (kNN) 模型来实现这一目标,原因如下:(1) kNN 是机器学习中的一种无分布方法。即使树像素不是严格独立同分布的,它也是高效的。 (2) 可以在人机交互模式下进行训练,由于K-d树结构,训练集的大小是自适应的。即训练一个kNN像素分类器就是构造一个K-d树。 (3) 与训练集中的全局搜索相比,K-d树可以加快树像素检测速度。对于候选像素,可以通过查询从构造的K-d树的根到第一个节点的子树来确定其第一个kNN该候选像素所在的单元格(或子空间)。此后,它将分配或注释给大多数 kNN。有关详细信息,请参阅我们之前的研究(Yang 等,2021)。
图 4 提供了一个例子来解释这个像素分类器。假设我们的兴趣对象 (IO) 是绿树和杂草。用户用鼠标单击图像时,会从该区域生成一组顶点。将顶点组成的多边形中的像素带入训练集中。首先选择红色或蓝色多边形中的像素并标记为“1”和“2”(见图 4(b))。选择一类新的样本(例如,品红色多边形中的对象“阴影”)并标记为“3”以删除不感兴趣的对象(NIO)。此时训练集中有三类像素样本:前两类作为正样本,最后一类作为负样本。构建K-d树,对所有像素进行像素检测。此处,kNN 的数量设置为 k = 3。检测结果如图 4(d)所示,其中如果这些像素被检测为正,则像素将填充原始像素。否则,这些填充有白色值。重复此操作,直到获得良好的结果,如图 4 (h) 所示。最后,这个kNN模型就是想要的像素分类器,五类训练样本存储在K-d树中。对对象“杂草”的解释是某些杂草的颜色与树木的颜色非常接近。因此,如果将其视为NIO,则可能会删除某些树像素。事实上,大多数杂草对象都可以通过树超像素识别步骤进一步过滤。
3.2. Tree superpixel identification
在人类视觉中,ITS 或树木计数的识别是对象级(或原型)任务,而不是像素级任务。然而,考虑到高分辨率的含义,原型很可能是在像素信息损失最小的情况下获得的。因此,我们需要一种可以在细粒度和粗粒度原型之间自由切换的切换机制。由于以下因素,超像素技术 (Stutz et al, 2018) 可以弥补这一差距:(1) 每个超像素通常由一组有意义的像素组成,这些像素通常来自同一对象。 (2) 图像超像素分割后得到的超像素标签可以逆向跟踪原始像素。 (3) 在pixel-pattern sample representation中,如果超像素按照原始像素的顺序排列,也可以看作是像素。这类似于图 1(b)中所示的树超像素。因此,可以减少计算和内存存储的容量。这对接下来的步骤非常有利。
在模式表示中,二维像素通常由五元组表示,例如,(l’, p’),其中 l = (x, y) ’ 和 p = (r, g, b) ‘,表示像素坐标和颜色值,分别。在整篇论文中,上标“’”表示矩阵转置。在这项工作中,由于简单的计算和更好的对象边界粘附,我们的超像素是通过 SLIC 分割获得的。平衡像素和超像素之间差异的一种简单但有效的方法是,超像素也使用五元组模式表示,例如,(lm,pm)。为简单起见,这里可以将 (l ′ m, p ′ m) ′ 解释为该超像素的中心。此外,为了提高表示的准确性,超像素的面积不应过大以减少欠分割问题。

图 5 显示了一个用经过训练的像素分类器解释树超像素识别的示例。在图 5(a) 中,我们通过 SLIC 分割获得了 2840 个超像素。由于良好的边界粘附性,来自同一超像素区域的像素填充有相同的颜色值,例如,像素的平均值。因此,超像素也可以表示为五元组模式。这些被送入像素分类器,并识别树超像素。结果,总共识别出 743 个树超像素,如图 5(b)所示。此过程的优点有三方面:(1)某些杂草像素可以通过均值运算符过滤,例如,这些像素与其他非绿色像素混合。 (2) 无论是聚类速度还是计算效率,都对下一步的数据聚类非常有利。在这种情况下,对 ITS 的 743 个超像素样本进行聚类比对原始 6,816,000 个像素(2400 × 2840)进行聚类要方便得多,其中样本比例约为 1:9173。 (3) 这种五元组表示也适用于针对重复计数问题对跨图像超像素进行聚类。这在下一小节中描述。
3.3. Supervised clustering
受人类视觉的启发,将 ITS 视为数据聚类问题似乎是可行的,这在引言部分中有所提及。数据聚类系列中的大多数方法都需要为 NoC(用 K 表示)预定义参数,例如 k-means 和 FCM。然而,这些方法不适合我们的 ITS 问题,因为 K 是所需的树数。当 K 未知时,即使在机器学习和计算机视觉社区中,确定 K 的最佳值(例如,通过模型选择标准)也可能在计算上变得昂贵。相比之下,虽然那些方法,例如 DBSCAN、AP (Zhou, 2015) 和 HC (Roux, 2018) 不需要预定义 K,但如何确定树超像素之间的相似性至关重要。在这项工作中,由于像素或超像素模式表示的固定维度,如果相似性(度量)可以“学习”而不是像上述方法那样“定义”,则这个问题可能会得到简化。
3.3.1. Adaptive metric for superpixel similarity
受计算机视觉的启发,对这个问题进行了预研。研究表明,一对树超像素 vi 和 vj (vi = (l ′ i, p ′ i)) 之间的相似度可以定义为。

其中距离 d1(⋅, ⋅) 和 d2(⋅, ⋅) 分别用于测量位置接近度和颜色接近度。这里,λ 是两种距离之间的权衡。
文献中,位置相似度一般采用欧几里德距离来度量,而颜色相似度采用马氏距离(Zhang et al, 2015; Li et al, 2020)。因此,我们将式(1)改写为矩阵形式如下:
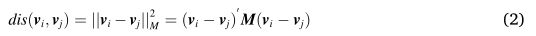
其中 M = diag(I, λΣ) 称为自适应度量,对应于 Euclidian 和 Mahalanobis。如前所述,M 有望从用户提供的监督中“学习”。此后,它将用于指导数据聚类。
3.3.2. Supervision for supervised clustering
在 NoC 未知方法(例如 DBSCAN)中,为数据聚类选择合适的“标准”至关重要。该标准包括相似性度量矩阵和聚类参数。受度量学习(Xiong 等人,2022 年;Nguyen 和 De Baets,2019 年)和监督聚类(Law 等人,2016 年)的启发,我们试图学习这种相似性以进行准确的 ITS 估计。
考虑方程式中定义的距离。 (2),监督聚类的监督应该由两部分组成:位置和颜色信息。此外,为了确保监督的准确性,以监督学习模式提供此信息会更有效,例如,通过用户提供的监督(见图 6)。在这种情况下,用户可以选择任何子区域,如果它可以包含几棵树,如图6中的红色矩形区域所示。实际上,这样的子区域和子区域的形状可以自由选择,这里矩形区域只是为了方便操作。例如,如果将形状指定为矩形,则只需通过一对用户提供的顶点(例如,左上坐标和右下坐标)就可以轻松裁剪子区域。假设所选区域中有八棵树,编号为“1”到“8”。监督聚类的监督包括用户提供的集群(个体)和集群标签,如右图所示。
如图 6 所示,如果所选像素或超像素来自同一个人,则这些像素或超像素将使用相同的标签进行标记。否则,这些标记有不同的数字。在这种情况下,训练样本是从八个标记的簇中提取的。在下一小节中,将定义的距离和监督结合起来,然后从数学上定义最佳标准。

图 5. 子图像“42”中的树超像素识别。 (a) 和 (b) 分别显示超像素分割和识别的树超像素的结果。
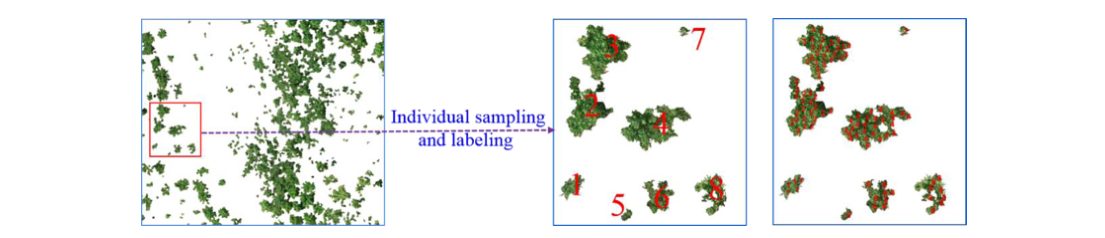
图 6. 监督聚类监督的解释。左侧面板中的红色框显示采样区域。最右边的两个面板分别说明了此采样和标记的结果。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
3.3.3. Metric learning for supervised clustering
令 X = [x1, x2…, xn] ′ ∈ Rn×d 为训练集。此外,设 Y = {0, 1}n×K 为分配矩阵,如果 xi 属于第 c 个个体,则 Yic = 1,否则为零。这里,n 和 d 分别表示训练样本的数量和维度。 K 表示监督集群的数量。在这种情况下,聚类中心定义为 Z = [z1, z2…, zK] ′ ∈ RK×d,其中 zj = ∑ iYijxi/∑ iYij。因此,可以通过以下最小化 MSE 的优化来学习所需的度量:

其中 ||A||2 M = tr(AMA ′ ),tr(⋅) 表示矩阵迹的算子。
在 Law 等人 (2016) 的工作之后,(3) 的闭式解 M1 被描述为。

其中 A+ 表示矩阵 A 的广义逆运算符。在本研究中,A+ 定义为 A+ = (A ′ A)−1A ′。比例符号“A∝B”表示存在正实数 σ(> 0),使得 A = σB。可见,得到的M1是实对称半正定矩阵。一般来说,它也是一个 Hermite 矩阵。然而,由于非对角性,M1 不是我们想要的矩阵。值得注意的是,它可以用来推导M。这在定理1中给出。为了阅读方便,令M1 = εX+YY+(X+) ′,ε > 0。此外,ε也可以纳入权衡λ。
定理 1. 除了前面的符号外,对于给定的矩阵 M1 和 M,必须存在一个可逆矩阵 P,满足 PM1P ′ = M。
证明在附录中提供。使用定理 1,可以通过 M = PM1P ′ 准确获得所需的度量 M,其中 P = diag(P1, P2) 和 P*i 由 (A.4) 计算。此外,参数对 ε 和 λ 以 ε / λ 的比例出现在 (A.4) 的最终方程中。该参数 ε 也可以使用 (A.4) 的第一个方程求解。因此,我们提出的监督学习方法只存在一个权衡参数。如图 6 中所解释的,在样本提取和标记之后,标记的样本可用于计算封闭解 M1。然后可以使用定理 1“学习”我们想要的度量 M。
图 7 显示了 ITS 的示例。结果是通过 DBSCAN(Diez 等人,2020)和我们的监督聚类获得的,分别如图 7(b)和(c)所示。为了便于理解,每个分段的冠都用一个圆圈(带有红色中心点和蓝色圆弧)来形象化。此外,为了表明分割的准确性,图 7(c)中的这些个体也与图 7(d)中的聚类边界一起显示。由于学习的度量,我们的方法在三个方面优于 DBSCAN:(1)它能够掌握树冠的颜色和形状特征(例如,基于椭圆分布的形状和颜色),而 DBSCAN 则无能为力。 (2) 我们的指标是自适应的。例如,形状和颜色之间的权衡是通过用户提供的监督来学习的。同时,用于 DBSCAN 的度量是各向同性欧几里得。 (3) 更重要的是,尽管 DBSCAN 适用于任意形状的数据聚类,但此属性也是 ITS 错误分割的原因。例如,那些重叠的冠通常聚集在一起,最后被误认为是一个冠。值得注意的是,在图 7(c)中有两个典型的错误分割区域,显示为带有洋红色箭头的蓝色弧线。相比之下,我们的方法更准确,甚至可以与人类视觉相媲美。
6. Conclusions
在这项工作中,我们讨论了一个更具挑战性的问题,即从 2D 顶视图树冠树冠进行个体树分割和树计数,无论它们是孤立的、重叠的还是两者兼而有之。考虑到树冠树冠在颜色和形状方面的特殊性,提出了基于视觉的框架。它可以方便地用于去除 NIO、提供监督和调整参数。重要的是,我们的方法可以实现高度准确的个体分割和树木计数,甚至可以与人类视觉相媲美。我们从理论上证明了监督聚类中学习的度量等同于树像素或超像素的形状和颜色的度量组合。
我们还应该指出,我们的方法受到超像素技术的影响,例如 SLIC 中的分割不足和分割过度问题。为了便于解释和可视化,我们没有将其与深度方法进行比较(Bayraktar 等人,2020 年;Valente 等人,2020 年)。在这项工作中,我们仅将“绿色”颜色作为个体分割的内在特征。此外,为简单起见,本研究仅利用像素或超像素位置和颜色中的冠信息。但在人类视觉中,正如文献中所述,IO 的特征和结构信息也值得关注,例如局部或纹理特征高-订单统计、转换信息等(Norzaki and Tahar, 2019; Santoso et al, 2016; Zhang et al, 2022)。我们未来的工作还包括树种分类和特定或所有树种的树木计数。