【自动驾驶】是近年来在深度学习领域中备受关注的一项技术,它通过整合传感器数据、计算机视觉和机器学习算法,实现车辆的自主导航和决策。自动驾驶技术已经在路径规划、环境感知和车辆控制等多个领域取得了显著成果,其独特的方法和有效的表现使其成为研究热点之一。
为了帮助大家全面掌握自动驾驶的方法并寻找创新点,本文总结了最近两年【自动驾驶】相关的20篇顶会顶刊的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望能为各位的研究工作提供有价值的参考。
需要的同学扫码添加我
回复“自动驾驶20”即可全部领取

1、UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
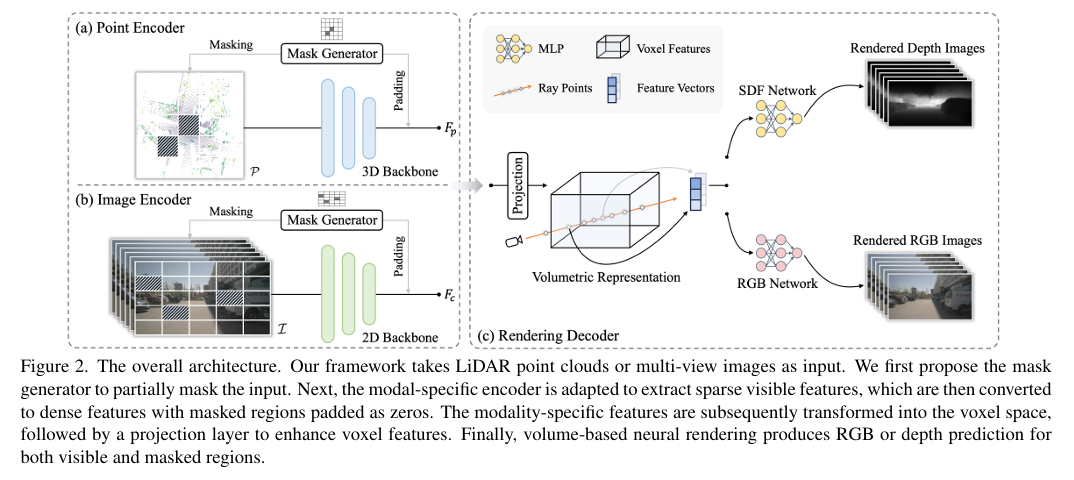
-这篇文章提出了一个名为UniPAD的新型自监督学习范式,旨在提高自动驾驶领域中特征学习的有效性。文章指出,尽管传统的3D自监督预训练方法已取得广泛成功,但大多数方法都是基于2D图像的原始设计。因此,作者们设计了UniPAD,它利用3D体积可微渲染技术,隐式编码3D空间,从而促进连续3D形状结构及其2D投影的复杂外观特征的重建。
-UniPAD的灵活性使其能够无缝集成到2D和3D框架中,实现对场景的更全面理解。通过在各种3D感知任务上进行广泛的实验,证明了UniPAD的可行性和有效性。该方法显著提高了基于激光雷达、相机和激光雷达-相机的基线的NDS(nuScenes Detection Score)分别达到了9.1、7.7和6.9。特别值得注意的是,UniPAD的预训练流水线在nuScenes验证集上达到了73.2 NDS的3D目标检测和79.4 mIoU的3D语义分割,与先前方法相比取得了最先进的结果。
-文章还详细介绍了UniPAD的工作原理,包括如何使用3D编码器提取分层特征,并通过体素化将3D特征转换到体素空间,然后应用可微体积渲染方法重建完整的几何表示。此外,为了在训练阶段保持效率,作者提出了一种针对自动驾驶应用特别设计的内存高效光线采样策略,这可以大幅降低训练成本和内存消耗。
-在相关工作部分,文章回顾了点云的自监督学习以及图像中的表示学习的最新进展,并讨论了神经渲染在自动驾驶中的应用。在方法论部分,详细描述了UniPAD框架的两个主要组成部分:模态特定编码器和体积渲染解码器,以及如何通过最小化渲染的2D投影与输入之间的差异来鼓励模型学习输入数据的连续几何或外观特征。
-在实验部分,作者在nuScenes数据集上进行了实验,并与现有的最先进方法进行了比较。结果表明,UniPAD在3D目标检测和3D语义分割任务上均取得了显著的性能提升。此外,文章还进行了一系列的消融研究,以评估不同组件和设计选择对模型性能的影响。
-最后,文章总结了UniPAD的主要贡献,并指出了该方法的一些限制,例如需要将点和图像特征显式转换为体积表示,这可能会随着体素分辨率的增加而增加内存使用量。文章的结论强调了UniPAD在各种3D感知任务中的卓越性能,并展望了通过在其他领域取得的进步来促进表示学习的可能性。
2、VLP: Vision Language Planning for Autonomous Driving
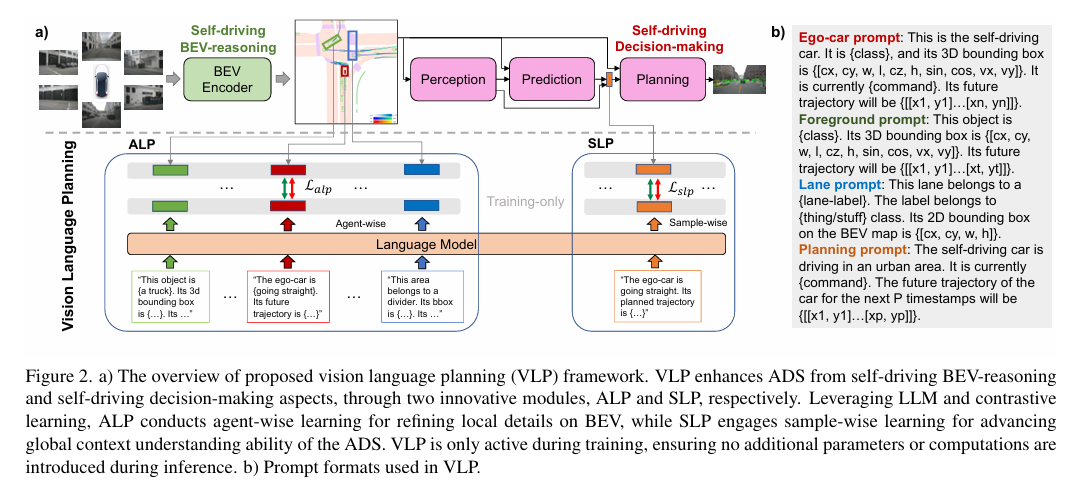
-这篇文章介绍了一个名为VLP(Vision Language Planning)的新型框架,旨在通过结合视觉和语言模型来增强自动驾驶系统(ADS)的规划能力。VLP框架利用大型语言模型(LLMs)的常识理解和推理能力,以改善自动驾驶中的源记忆基础和自我驾驶汽车的上下文理解,从而提升系统的安全性和泛化能力。
-文章首先指出,尽管基于视觉的自动驾驶方法在场景理解方面取得了显著进展,但在推理能力、泛化性能和长尾场景等方面仍存在不足。为了解决这些问题,VLP框架通过两个关键组件——Agent-centric Learning Paradigm(ALP)和Self-driving-car-centric Learning Paradigm(SLP)——来加强ADS。ALP模块专注于提升局部语义表示和BEV(鸟瞰视图)的推理能力,而SLP模块则致力于指导规划过程,以提高自我驾驶汽车的决策能力。
-在ALP中,通过将预训练语言模型的一致特征空间整合到BEV中的代理特征上,利用语言模型中嵌入的常识和逻辑流程,增强了ADS在多样化驾驶场景中的有效性。SLP则通过利用预训练语言模型中编码的知识,将规划查询与预期目标和自我驾驶汽车的驾驶状态对齐,从而在规划阶段做出更明智的决策。
-通过在具有挑战性的NuScenes数据集上的实验,VLP在端到端规划性能上达到了最先进的水平,与之前的最佳方法相比,在平均L2误差和碰撞率方面分别降低了35.9%和60.5%。此外,VLP在面对新的城市环境时显示出改进的性能和强大的泛化能力。
-文章还进行了新城市泛化能力的研究,通过在波士顿和新加坡两个城市之间进行训练和测试,证明了VLP在新城市泛化方面的能力,显著优于仅基于视觉的方法。此外,这是首次在ADS的多个阶段引入LLMs,以提高在新城市和长尾情况下的泛化能力。
-在相关工作部分,文章回顾了端到端自动驾驶、视觉-语言模型以及将语言模型应用于自动驾驶的研究进展。在方法论部分,详细介绍了VLP模型的工作原理,包括ALP和SLP的设计和实现。
-实验部分展示了VLP在开放环路规划、感知/预测任务中的有效性,并通过一系列消融研究来验证各个组件和设计选择对模型性能的影响。最后,文章总结了VLP的主要贡献,并指出了未来的研究方向,包括在更广泛的数据集和传感器模态上评估VLP的性能。
需要的同学扫码添加我
回复“自动驾驶20”即可全部领取
3、DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
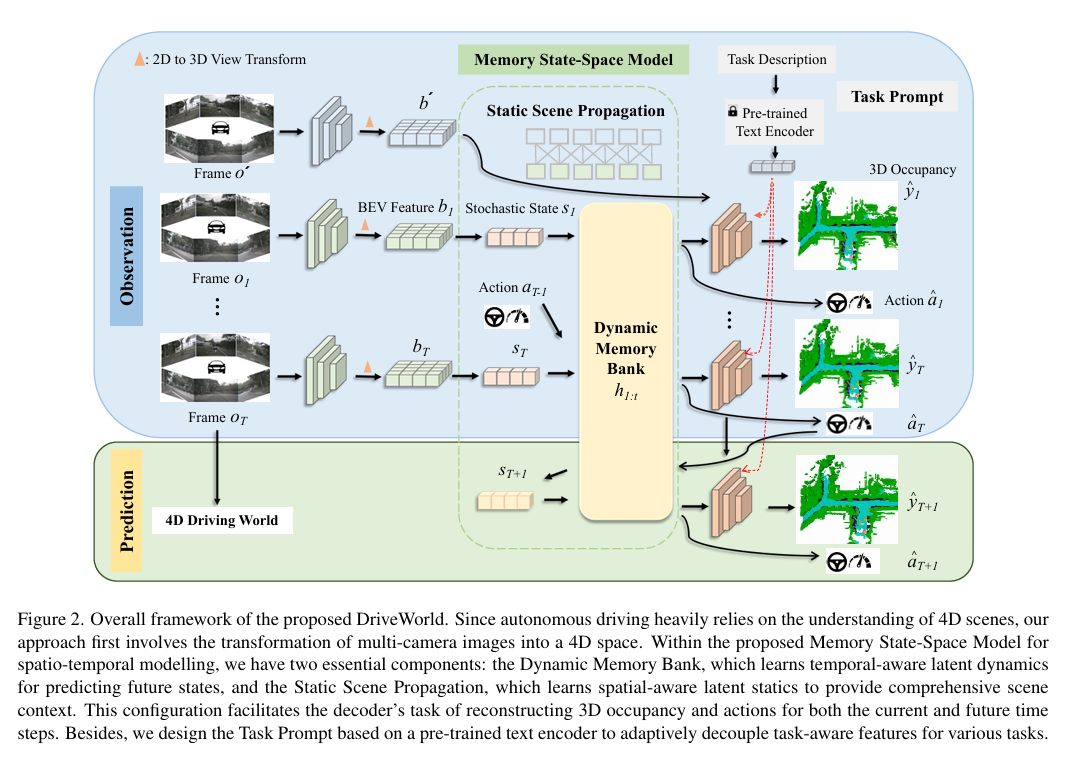
-这篇文章介绍了一个名为DriveWorld的新型4D预训练场景理解框架,专门针对以视觉为中心的自动驾驶任务。与传统的2D或3D预训练方法不同,DriveWorld利用多摄像头驾驶视频,通过时空方式进行预训练,以学习能够理解4D场景的表示。
-文章首先指出,自动驾驶是一个复杂的任务,需要对场景进行全面的四维(4D)理解,包括感知、预测和规划。传统的视觉中心自动驾驶预训练方法主要依赖于2D或3D的预训练任务,而忽略了自动驾驶作为4D场景理解任务的时间特性。为了解决这一挑战,文章提出了基于世界模型的自动驾驶4D表示学习框架DriveWorld。
-DriveWorld框架的核心是Memory State-Space Model,包含Dynamic Memory Bank模块和Static Scene Propagation模块。Dynamic Memory Bank模块用于学习时间感知的潜在动态,以预测未来状态的变化;Static Scene Propagation模块用于学习空间感知的潜在静态特征,以提供全面的场景上下文。此外,文章还引入了Task Prompt,通过语义提示调整特征提取网络,以适应不同的下游任务。
-在实验部分,作者在nuScenes数据集上进行了预训练,并在OpenScene数据集上进行了测试。实验结果表明,与2D ImageNet预训练、3D占用预训练和知识蒸馏算法相比,DriveWorld在3D目标检测、在线映射、多目标跟踪、运动预测、占用预测和规划等多个自动驾驶任务上都取得了显著的性能提升。例如,在OpenScene数据集上预训练后,DriveWorld在3D目标检测的mAP上提高了7.5%,在在线映射的IoU上提高了3.0%,在多目标跟踪的AMOTA上提高了5.0%,在运动预测的minADE上降低了0.1m,在占用预测的IoU上提高了3.0%,在规划的平均L2误差上降低了0.34m。
-文章还进行了消融研究,以验证DriveWorld中每个组件的有效性。结果表明,Memory State-Space Model的各个组成部分,包括Dynamic Memory Bank、Static Scene Propagation和Task Prompt,都对性能提升有重要贡献。此外,文章还探讨了数据集规模对性能的影响,发现使用更多的数据进行预训练可以提高下游任务的性能。
-最后,文章总结了DriveWorld的主要贡献,并指出了未来的研究方向。尽管DriveWorld在自动驾驶的4D场景理解方面取得了显著进展,但当前的标注仍然基于激光雷达点云,未来需要探索自我监督学习以实现视觉中心的预训练。此外,DriveWorld的有效性目前仅在轻量级的ResNet101骨干网络上得到了验证,未来值得考虑扩大数据集和骨干网络的规模。作者希望提出的4D预训练方法能为自动驾驶基础模型的发展做出贡献。
需要的同学扫码添加我
回复“自动驾驶20”即可全部领取