一, 深度学习基础知识
1,什么是深度学习?
机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。
2, 传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从经验中学习获取知识。这也是深度学习被看做黑盒子,可解释性差的原因。
随着计算机软硬件的飞速发展,现阶段通过深度学习来模拟人脑来解释数据,包括图像,文本,音频等内容。目前深度学习的主要应用领域有:
* 智能手机
* 语音识别
* 机器翻译
* 拍照翻译
* 自动驾驶
二, 卷积网络
利用全连接神经网络对图像进行处理存在以下两个问题:
- 需要处理的数据量大,效率低
假如我们处理一张 1000×1000 像素的图片,参数量如下:
1000×1000×3=3,000,000
这么大量的数据处理起来是非常消耗资源的
2. 图像在维度调整的过程中很难保留原有的特征,导致图像处理的准确率不高.
假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从图像的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。所以当我们移动图像中的物体,用全连接升降得到的结果会差异很大,这是不符合图像处理的要求的。
1. CNN网络的构成¶
CNN网络受人类视觉神经系统的启发,人类的视觉原理:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只人脸)。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似人工神经网络的部分,用来输出想要的结果。

2. 卷积层¶
卷积层是卷积神经网络中的核心模块,卷积层的目的是提取输入特征图的特征,
卷积层是卷积神经网络中的核心模块,卷积层的目的是提取输入特征图的特征,如下图所示,卷积核可以提取图像中的边缘信息。

3. 卷积层中的一些参数(又称卷积三大件)
1. padding 特征图比原始图减小了很多,我们可以在原图像的周围进行padding,来保证在卷积过程中特征图大小不变
2. stride 按照步长为1来移动卷积核,
3. kernel_size 卷积核大小,
4. 特征图大小的计算
输出特征图的大小与以下参数息息相关: * size:卷积核/过滤器大小,一般会选择为奇数,比如有1 * 1, 3 * 3, 5 * 5 * padding:零填充的方式 * stride:步长
5. 池化层(Pooling)
池化层迎来降低了后续网络层的输入维度,缩减模型大小,提高计算速度,并提高了Feature Map 的鲁棒性,防止过拟合,
它主要对卷积层学习到的特征图进行下采样(subsampling)处理,主要由两种
最大池化 ---->Max Pooling,取窗口内的最大值作为输出,这种方式使用较广泛。
平均池化-----> Avg Pooling,取窗口内的所有值的均值作为输出
6. 全连接层
全连接层位于CNN网络的末端,经过卷积层的特征提取与池化层的降维后,将特征图转换成一维向量送入到全连接层中进行分类或回归的操作。
三, 图像分类
- 图像分类: 图像分类实质上就是从给定的类别集合中为图像分配对应标签的任务。也就是说我们的任务是分析一个输入图像并返回一个该图像类别的标签。
- 分类常用数据集:
- mnist数据集
该数据集是手写数字0-9的集合,共有60k训练图像、10k测试图像、10个类别、图像大小28×28×1.我们可以通过tf.keras直接加载该数据集
2.CIFAR-10和CIFAR-100
CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。
- mnist数据集
- ImageNet
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片,大约有22000个类别的数据。ILSVRC全称ImageNet Large-Scale Visual Recognition Challenge,是视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。从2010年开始举办到2017年最后一届,使用ImageNet数据集的一个子集,总共有1000类。
四,图像分类网络-VGG
- VGG的网络架构特点:
VGG网络:主要贡献是使用很小的卷积核(3×3)构建卷积神经网络结构,能够取得较好的识别精度,常用来提取图像特征的VGG-16和VGG-19。
VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGG中使用的都是小尺寸的卷积核(3×3),

五, Inception

-
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第4条线路则使用3×3最大池化层,后接1×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并向后进行传输。
1×1卷积:
它的计算方法和其他卷积核一样,唯一不同的是它的大小是1×1,没有考虑在特征图局部信息之间的关系。

它的作用主要是:
- 实现跨通道的交互和信息整合
- 卷积核通道数的降维和升维,减少网络参数
- GoogLeNet主要由Inception模块构成,如下图所示:

整个网络架构我们分为五个模块,每个模块之间使用步幅为2的3×33×3最大池化层来减小输出高宽。
InceptionV2
在InceptionV2中将大卷积核拆分为小卷积核,将V1中的5×5的卷积用两个3×3的卷积替代,从而增加网络的深度,减少了参数。
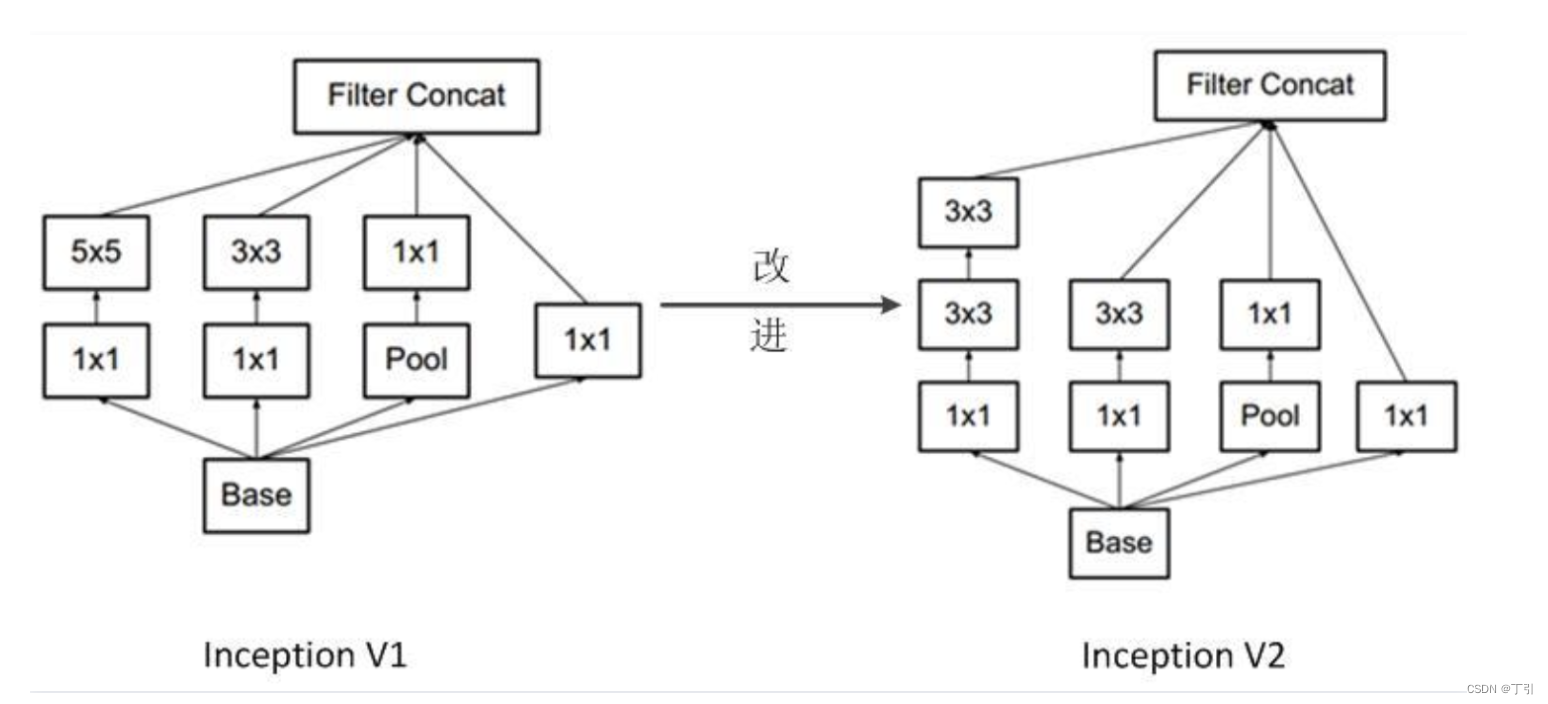
InceptionV3
将n×n卷积分割为1×n和n×1两个卷积,例如,一个的3×3卷积首先执行一个1×3的卷积,然后执行一个3×1的卷积,这种方法的参数量和计算量都比原来降低。
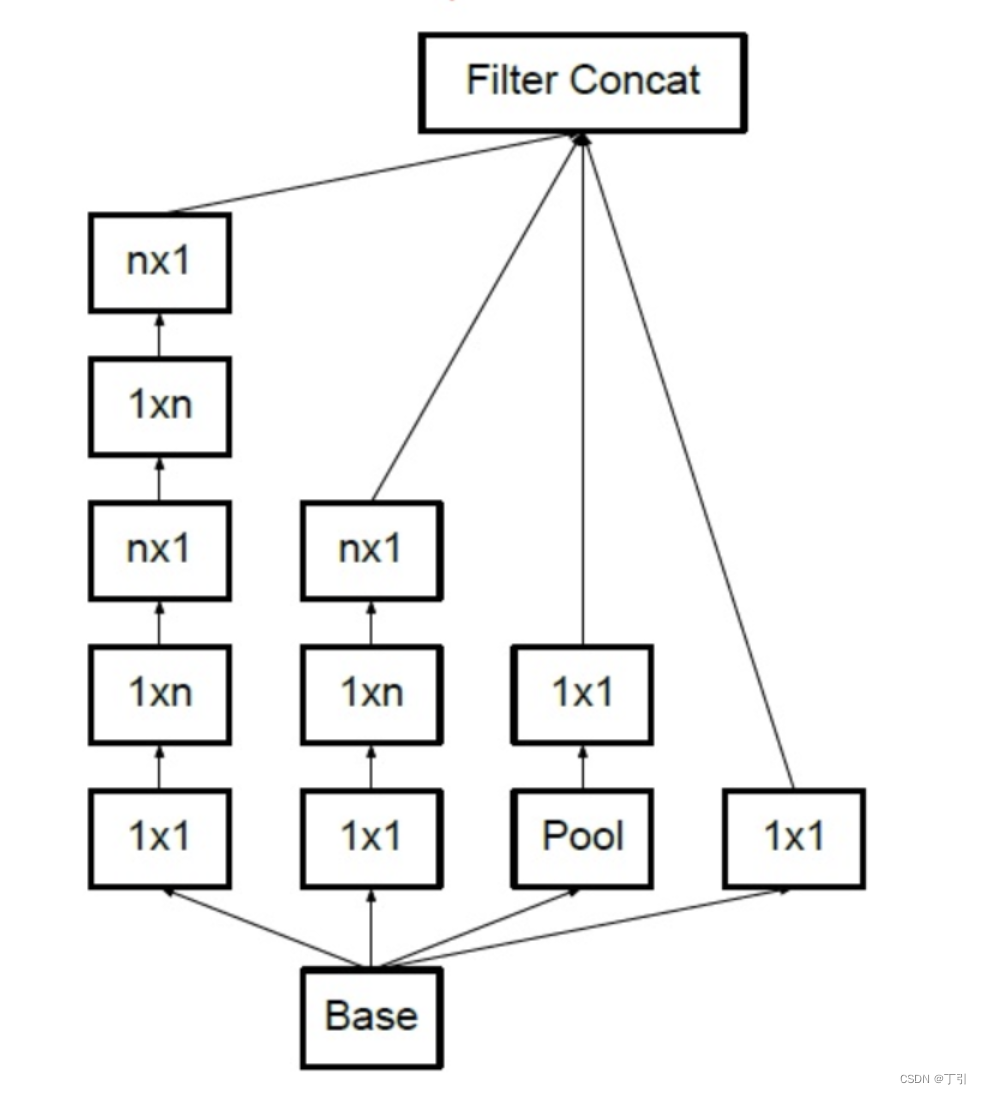
六, ResNet
- 什么是ResNet
ResNet是一种残差网络, - 为什么要引入ResNet?
网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。 - ResNet详细解说
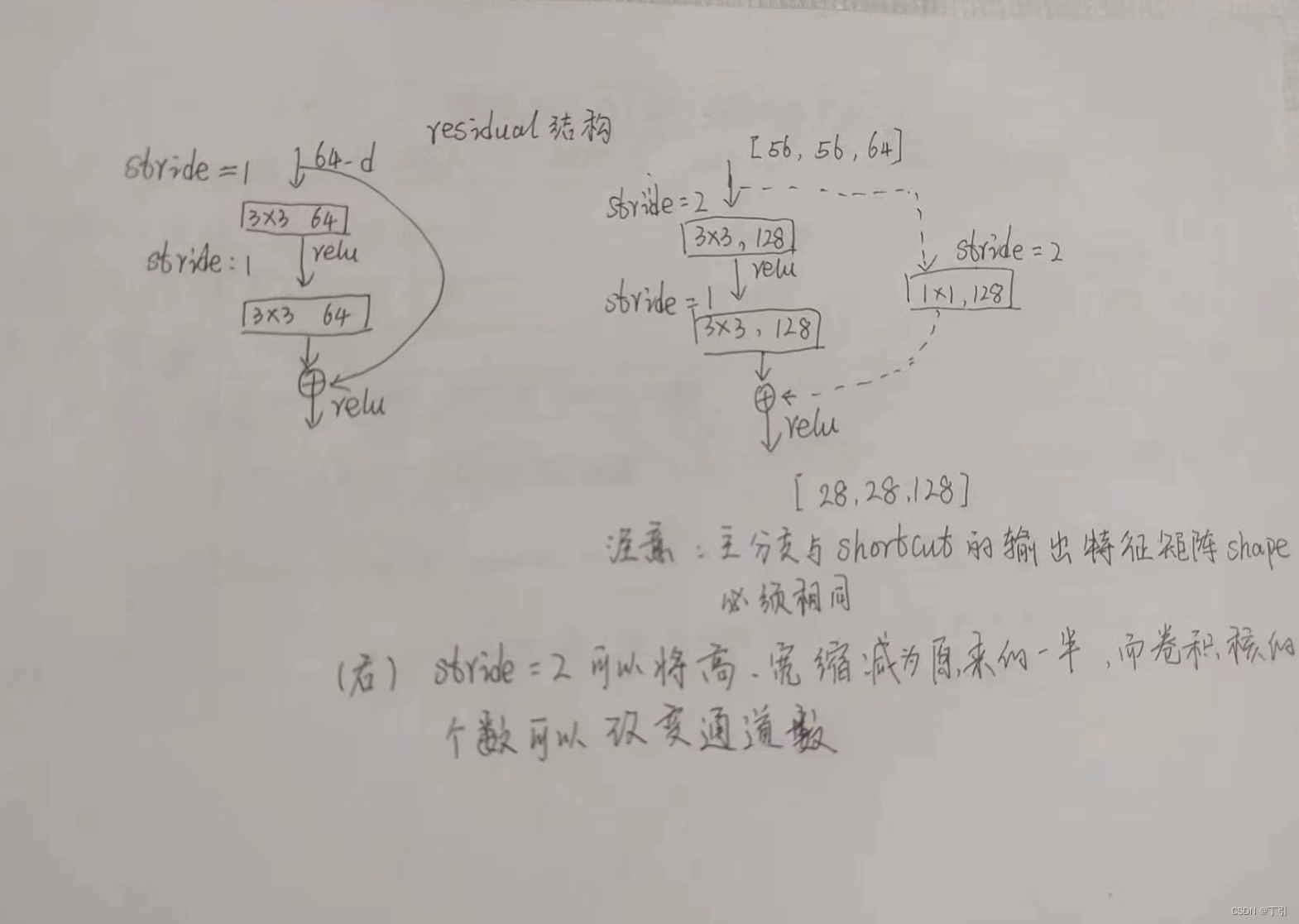
咱们要求解的映射为:H(x)
现在咱们将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。
残差:观测值与估计值之间的差。
这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。
我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。
那么咱们要求解的问题变成了H(x) = F(x)+x。
有小伙伴可能会疑惑,咱们干嘛非要经过F(x)之后在求解H(x)啊!整这么麻烦干嘛!
咱们开始看图说话:如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值对不?那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧?
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了?
当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
全0填充;
采用1*1卷积。
七, 迁移学习
1, 什么是迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务
2. 为什么需要迁移学习?
1. 大数据与少标注的矛盾:虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型。人工进行数据标定太耗时。
2. 大数据与弱计算的矛盾:普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的迁移。
3. 普适化模型与个性化需求的矛盾:即使是在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在不同人之间做模型的适配。
4. 特定应用(如冷启动)的需求。
3. 迁移学习有哪些常用概念?
- 域(Domain):数据特征和特征分布组成,是学习的主体
源域 (Source domain):已有知识的域
目标域 (Target domain):要进行学习的域
-任务 (Task):由目标函数和学习结果组成,是学习的结果
八, Mobilenet网络
- MobileNet系列很重要的轻量级网络家族,出自谷歌,MobileNetV1使用深度可分离卷积来构建轻量级网络,
算法笔记:
1.深度可分离卷积
深度可分离卷积 (depthwise separable convolution) 一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map。相比常规的卷积操作,其参数数量和运算成本比较低。可分离卷积主要有两种类型:空间可分离卷积和深度可分离卷积。
2. 深度可分离卷积= 深度卷积+逐点卷积
2. Mobilenetv2原理
MobileNetV2提出创新的inverted residual with linear bottleneck单元,虽然层数变多了,但是整体网络准确率和速度都有提升,
3. Mobilenetv3原理
MobileNetV3的整体架构基本沿用了MobileNetV2的设计,采用了轻量级的深度可分离卷积和残差块等结构,依然是由多个模块组成,但是每个模块得到了优化和升级,包括瓶颈结构、SE模块和NL模块。
1, MobileNetV3创新点
MobileNetV3的主要创新在于使用了两个重要的组件:候选块和内积激活函数。
- 1.候选块
- 2.内积激活函数
九, 深度学习之—目标检测
计算机视觉中关于图像识别有四大类任务:
分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),语义分割 解决“每一个像素属于哪个目标物或场景”的问题。
十, 目标检测之-iou
- 概念
IOU是旷视科技提出用于定位误差,源于数学中的集合两个Box重合程度,
IoU (Intersection over Union) 是一种测量在特定数据集中检测相应物体准确度的一个标准。IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围)
我们的算法得出的结果范围。
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。如下图所示。绿色标线是人为标记的正确结果(g