conda activate DL
conda deactivate
课程链接
一 一些包的安装
1 stanfordcorenlp

-
在anoconda prompt 里面:进入自己的conda环境,pip install stanfordcorenlp
进入方式 -
相关包下载,Jar包我没有下载下来,太慢了,这个可下可不下,不下就是默认英文模式
添加链接描述

- 调用包来进行输入数据的处理,实体识别,词性识别,还有很多其他的功能
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'stanfordcorenlp',lang = 'en')
fin = open('news.txt', 'r', encoding = 'utf8') #输入数据
fner = open('ner.txt', 'w', encoding = 'utf8') ## 进行命名实体识别结果
ftag = open('pos_tag.txt', 'w', encoding = 'utf8') #装词性识别的结果
for line in fin:
line = line.strip()
#判断是不是空行
if len(line) < 1:
continue
# 进行命名实体识别(这个词语属于什么类别)
fner.write(" ".join([each[0] + "/" + each[1] for each in nlp.ner(line) if len(each) == 2]) + "\n")
# 词性识别
ftag.write(" ".join([each[0] + "/" + each[1] for each in nlp.pos_tag(line) if len(each) == 2]) + "\n")
fner.close()
ftag.close()
!!!!!!!!! 注意,要将下载的包放在运行程序一个路径,并且重命名才可以,ner.txt呵pos_tag文件要提前创建,是空文件夹,

2 hanlp

- java下载地址
- anaconda prompt 内,进入conda激活的环境之后,
pip install JPype1 - `pip install pyhanlp,
- 程序里调用的时候
from pyhanlp import HanLP
3 fasttext软件包训练模型 模型的保存和加载方法
import fasttext
#模型加载并开始训练
model= = fasttext.train_unsupervised('data/fil9', "cbow", dim=300, epoch=1, lr=0.1, thread=8)
# 模型保存
model.save_model('fil9.bin')
#模型直接加载
model= fasttext.load_model('fil9.bin')
#打印the的词向量表示矩阵,默认是矩阵大小是100
print(model.get_word_vector('the'))
#模型的验证,打印相似高的词汇做初步验证
print(model1.get_nearest_neighbors('sports'))

`
二 文本预处理
1 分词

a 有些专有名词分词不准如何处理----人为添加字典–结合正则
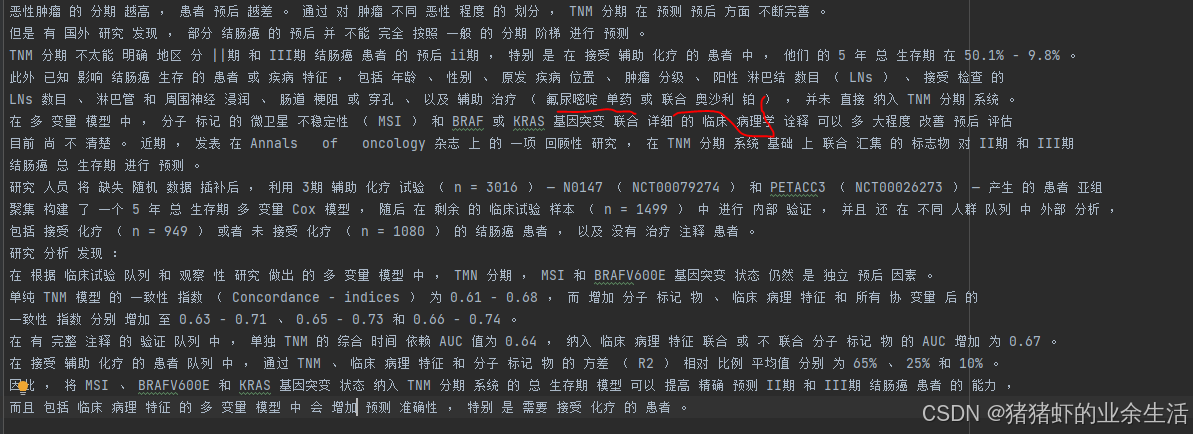

- 如何从上面的第一张图到第2张图在程序中加入
jieba.load_userdict("dict.txt")语句,其中,dict是人为建立的
dict.txt内的内容如下
联合奥沙利铂
氟尿嘧啶单药
- text.txt内容如下,这些文件都和.py文件放在一个目录下即可
恶性肿瘤的分期越高,患者预后越差。通过对肿瘤不同恶性程度的划分,TNM分期在预测预后方面不断完善。
但是有国外研究发现,部分结肠癌的预后并不能完全按照一般的分期阶梯进行预测。
TNM分期不太能明确地区分||期和III期结肠癌患者的预后ii期,特别是在接受辅助化疗的患者中,他们的5年总生存期在50.1%-9.8%。
此外已知影响结肠癌生存的患者或疾病特征,包括年龄、性别、原发疾病位置、肿瘤分级、阳性淋巴结数目(LNs)、接受检查的
LNs数目、淋巴管和周围神经浸润、肠道梗阻或穿孔、以及辅助治疗(氟尿嘧啶单药或联合奥沙利铂),并未直接纳入TNM分期系统。
在多变量模型中,分子标记的微卫星不稳定性(MSI)和BRAF或KRAS基因突变联合详细的临床病理学诠释可以多大程度改善预后评估
目前尚不清楚。近期,发表在Annals of oncology杂志上的一项回顾性研究,在TNM分期系统基础上联合汇集的标志物对II期和III期
结肠癌总生存期进行预测。
研究人员将缺失随机数据插补后,利用3期辅助化疗试验(n=3016)—N0147(NCT00079274)和PETACC3(NCT00026273)—产生的患者亚组
聚集构建了一个5年总生存期多变量Cox模型,随后在剩余的临床试验样本(n=1499)中进行内部验证,并且还在不同人群队列中外部分析,
包括接受化疗(n=949)或者未接受化疗(n=1080)的结肠癌患者,以及没有治疗注释患者。
研究分析发现:
在根据临床试验队列和观察性研究做出的多变量模型中,TMN分期,MSI和BRAFV600E基因突变状态仍然是独立预后因素。
单纯TNM模型的一致性指数(Concordance-indices)为0.61-0.68,而增加分子标记物、临床病理特征和所有协变量后的
一致性指数分别增加至0.63-0.71、0.65-0.73和0.66-0.74。
在有完整注释的验证队列中,单独TNM的综合时间依赖AUC值为0.64,纳入临床病理特征联合或不联合分子标记物的AUC增加为0.67。
在接受辅助化疗的患者队列中,通过TNM、临床病理特征和分子标记物的方差(R2)相对比例平均值分别为65%、25%和10%。
因此,将MSI、BRAFV600E和KRAS基因突变状态纳入TNM分期系统的总生存期模型可以提高精确预测II期和III期结肠癌患者的能力,
而且包括临床病理特征的多变量模型中会增加预测准确性,特别是需要接受化疗的患者。
- 有时候字典也不行,尤其是中英文结合的词汇,TMI分期,这种时候就需要正则约束
#-*- coding=utf8 -*-
import jieba
import re
import hanlp
#from tokenizer import cut_hanlp
from pyhanlp import HanLP
jieba.load_userdict("dict.txt") #jieba的处理方式
def merge_two_list(a, b):
c=[]
len_a, len_b = len(a), len(b)
minlen = min(len_a, len_b)
for i in range(minlen):
c.append(a[i])
c.append(b[i])
if len_a > len_b:
for i in range(minlen, len_a):
c.append(a[i])
else:
for i in range(minlen, len_b):
c.append(b[i])
return c
if __name__=="__main__":
fp=open("text.txt","r",encoding="utf8")
fout=open("result_cut.txt","w",encoding="utf8")
#定义正则表达式:regex1 匹配的模式是:包含1到5个非中文字符、非特殊符号(例如括号、星号等)后面跟着一个“期”字的字符串。
#regex2 匹配的模式是:一个数字(最多有3位整数部分,后面可以有一个小数点和最多3位小数部分)后面跟着一个百分号
#使用 re.compile 将上述正则表达式编译为正则表达式对象 p1 和 p2。
#[^\u4e00-\u9fa5()*&……%¥$,,。.@! !表示非汉字
regex1=u'(?:[^\u4e00-\u9fa5()*&……%¥$,,。.@! !]){1,5}期'
#[0-9]{1,3}[.]?[0-9]{1,3}小数点前面小于3以及小数点后面小于3位
regex2=r'(?:[0-9]{1,3}[.]?[0-9]{1,3})%'
p1=re.compile(regex1)
p2=re.compile(regex2)
for line in fp.readlines():
result1=p1.findall(line) #在当前行中查找匹配 regex1 的所有字符串。
if result1:
line=p1.sub("FLAG1",line) #如果找到了匹配的字符串,则将这些字符串替换为 "FLAG1"。
result2=p2.findall(line)
if result2:
line=p2.sub("FLAG2",line)
#调用jieba分词需要下面两个语句结合使用
words = jieba.cut(line) #调用jieba进行分词
result = " ".join(words) # 将分词结果转换为字符串格式
words1 = HanLP.segment(line) #调用hanlp进行分词
if "FLAG1" in result:
result=result.split("FLAG1")
result=merge_two_list(result,result1)
result="".join(result)
if "FLAG2" in result:
result=result.split("FLAG2")
result=merge_two_list(result,result2)
result="".join(result)
#print(result)
fout.write(result)
fout.close()
b 有时候添加词典不管用,还可以调整词频
一句话可以调整词频,但是,这个语句一次只能处理一个词
jieba.suggest_freq('台中', tune=True)
dict.txt里面的内容是 台中
# -*- coding=utf8 -*-
import jieba
import re
jieba.load_userdict("dict.txt")
#方法1-------------
# fp=open("dict.txt",'r',encoding='utf8')
# for line in fp:
# line=line.strip() #去掉换行符
# jieba.suggest_freq(line, tune=True)
#方法1-------------
[jieba.suggest_freq(line, tune=True) for line in open("dict.txt",'r',encoding='utf8')]
#jieba.suggest_freq('台中', tune=True)
[jieba.suggest_freq(line.strip(), tune=True) for line in open("dict.txt", 'r', encoding='utf8')]
if __name__ == "__main__":
string = "台中正确应该不会被切开。"
words = jieba.cut(string)
words = " ".join(words) # 将分词结果转换为字符串格式
print(words)
c 词库最好是按照长度来进行排序,因为切词是按照文件内文字的位置前后顺序,优先匹配前面的词,
下面案例,数据库设计,和数据库设计工程师,如果数据库设计工程师在数据库设计后面,那么就不会切出数据库设计工程师的分词
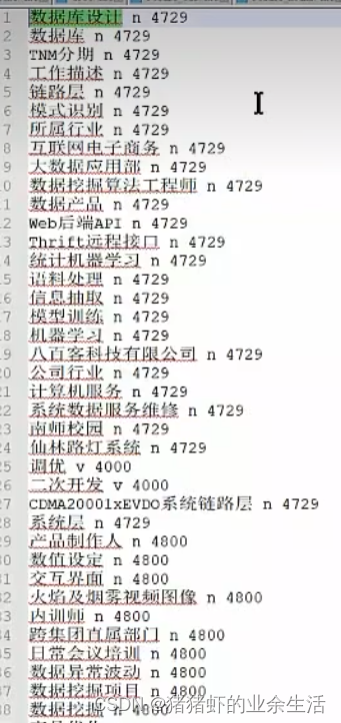
- 代码完成词典的排序
dict_file=open("resume_nouns.txt",'r',encoding='utf8')
d={}
[d.update({line:len(line.split(" ")[0])}) for line in dict_file]
f=sorted(d.items(), key=lambda x:x[1], reverse=True)
dict_file=open("resume_nouns1.txt",'w',encoding='utf8')
[dict_file.write(item[0]) for item in f]
dict_file.close()
2. 词性标注,hanlp实现只挑选一些特定的词性

#-*- coding=utf8 -*-
import jieba
import re
import os,gc,re,sys
from jpype import *
import hanlp
from pyhanlp import HanLP
keep_pos="q,qg,qt,qv,s,t,tg,g,gb,gbc,gc,gg,gm,gp,m,mg,Mg,mq,n,an,vn,ude1,nr,ns,nt,nz,nb,nba,nbc,nbp,nf,ng,nh,nhd,o,nz,nx,ntu,nts,nto,nth,ntch,ntcf,ntcb,ntc,nt,nsf,ns,nrj,nrf,nr2,nr1,nr,nnt,nnd,nn,nmc,nm,nl,nit,nis,nic,ni,nhm,nhd"
keep_pos_nouns=set(keep_pos.split(","))
keep_pos_v="v,vd,vg,vf,vl,vshi,vyou,vx,vi"
keep_pos_v=set(keep_pos_v.split(","))
keep_pos_p=set(['p','pbei','pba'])
drop_pos_set=set(['xu','xx','y','yg','wh','wky','wkz','wp','ws','wyy','wyz','wb','u','ud','ude1','ude2','ude3','udeng','udh','p','rr'])
han_pattern=re.compile(r'[^\dA-Za-z\u3007\u4E00-\u9FCB\uE815-\uE864]+')
#根据需要选择返回生成器还是列表,从而灵活地处理分词结果
def to_string(sentence,return_generator=False):
if return_generator:
# 返回生成器
return (word_pos_item.toString().split('/') for word_pos_item in HanLP.segment(sentence))
else:
# 并将结果作为一个二元组 (词, 词性) 加入到最终返回的列表中。
return [(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in HanLP.segment(sentence)]
#根据 with_filter 参数的值,选择是否对分词结果进行过滤
def seg_sentences(sentence,with_filter=True,return_generator=False):
segs=to_string(sentence,return_generator=return_generator)
if with_filter:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ' and word_pos_pair[1] not in drop_pos_set]
else:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ']
return iter(g) if return_generator else g
#*****************************************************************************
fp = open("text.txt", 'r', encoding='utf8')
fout = open("out.txt", 'w', encoding='utf8')
for line in fp:
line = line.strip()
if len(line) > 0:
fout.write(' '.join(seg_sentences(line)) + "\n")
fout.close()
if __name__ == "__main__":
pass
- 输入txt文本
自我评价
本人诚实正直,对工作认真负责,吃苦耐劳,善于创新,敢于迎接挑战及承担责任,富有工作热情,乐业敬业,善于与人沟通。营造和谐的工作氛围,注重人性化管理,能带动下属充分发挥团队合作精神,为公司创造效益!
求职意向
到岗时间:一个月之内
工作性质:全职
希望行业:通信/电信运营
目标地点:广州
期望月薪:面议/月
目标职能:数据分析专员
工作经验
2014/11 — 2015/9:XX有限公司[10个月]
所属行业:通信/电信运营
数据部 数据分析专员
1. 数据库日常简单维护,熟悉SQL查询语句。
2. 数据分析,协助客户定位网络疑问问题。
3. 投诉建模,通过匹配大量的投诉用户及其上网行为,分析其可能投诉的原因并进行建模。
2013/5 — 2014/10:XX有限公司[1年5个月]
所属行业:通信/电信运营
数据部 数据分析专员
1. 日常办公用品采购,基站租赁合同处理及工程物资采购。
2. ERP项目支出入账及物资装配,投诉工单处理,通信基站故障处理。
3. 按排会议室,会议记要记录及整理,公文编辑分发。
- 输出txt文本

3.命名实体识别

- net.py
import jieba
import re
from rules import grammer_parse
fp = open("text.txt", 'r', encoding = 'utf8')
fout = open("out.txt",'w', encoding = 'utf8')
[grammer_parse(line.strip(), fout) for line in fp if len(line.strip()) >0]
fout.close()
if __name__ == "__main__":
pass
- rules.py
#encoding=utf8
import nltk
import json
from tools import ner_stanford
keep_pos="q,qg,qt,qv,s,t,tg,g,gb,gbc,gc,gg,gm,gp,m,mg,Mg,mq,n,an,vn,ude1,nr,ns,nt,nz,nb,nba,nbc,nbp,nf,ng,nh,nhd,o,nz,nx,ntu,nts,nto,nth,ntch,ntcf,ntcb,ntc,nt,nsf,ns,nrj,nrf,nr2,nr1,nr,nnt,nnd,nn,nmc,nm,nl,nit,nis,nic,ni,nhm,nhd"
keep_pos_nouns=set(keep_pos.split(","))
keep_pos_v="v,vd,vg,vf,vl,vshi,vyou,vx,vi"
keep_pos_v=set(keep_pos_v.split(","))
keep_pos_p=set(['p','pbei','pba'])
def get_stanford_ner_nodes(parent):
date=''
org=''
loc=''
for node in parent:
if type(node) is nltk.Tree:
if node.label() == 'DATE' :
date=date+" "+''.join([i[0] for i in node])
elif node.label() == 'ORGANIZATIONL' :
org=org+" "+''.join([i[0] for i in node])
elif node.label() == 'LOCATION':
loc=loc+" "+''.join([i[0] for i in node])
if len(date)>0 or len(org)>0 or len(loc)>0 : #len(num)>0 or
return {'date':date,'org':org,'loc':loc}
else:
return {}
# def grammer_parse(raw_sentence=None,file_object=None):
# if len(raw_sentence.strip())<1:
# return False
# grammer_dict = {
# 'stanford_ner_drop': r"""
# DATE: {<DATE>+<MISC>?<DATE>*}
# {<DATE>+}
# TIME: {<TIME>+}
# ORGANIZATION: {<ORGANIZATION>+}
# LOCATION: {<LOCATION|STATE_OR_PROVINCE|CITY|COUNTRY>+}
# """
# }
# # 初始化正则表达式解析器
# stanford_ner_drop_rp = nltk.RegexpParser(grammer_dict['stanford_ner_drop'])
#
# try :
# stanford_ner_drop_result = stanford_ner_drop_rp.parse(ner_stanford(raw_sentence) )
#
# except:
# print("the error sentence is {}".format(raw_sentence))
# else:
#
# stanford_keep_drop_dict=get_stanford_ner_nodes(stanford_ner_drop_result)
# if len(stanford_keep_drop_dict)>0 :
# file_object.write(json.dumps(stanford_keep_drop_dict, skipkeys=False,
# ensure_ascii=False,
# check_circular=True,
# allow_nan=True,
# cls=None,
# indent=4,
# separators=None,
# default=None,
# sort_keys=False))
def grammer_parse(raw_sentence=None, file_object=None):
if not raw_sentence or len(raw_sentence.strip()) < 1:
return False
grammer_dict = {
'stanford_ner_drop': r"""
DATE: {<DATE>+<MISC>?<DATE>*}
{<DATE>+}
TIME: {<TIME>+}
ORGANIZATION: {<ORGANIZATION>+}
LOCATION: {<LOCATION|STATE_OR_PROVINCE|CITY|COUNTRY>+}
"""
}
# 初始化正则表达式解析器
stanford_ner_drop_rp = nltk.RegexpParser(grammer_dict['stanford_ner_drop'])
try:
# 调用命名实体识别函数,这里使用 ner_stanford(raw_sentence) 作为示例
# 替换成您实际使用的命名实体识别函数
ner_result = ner_stanford(raw_sentence)
# 使用正则表达式解析器进行命名实体解析
stanford_ner_drop_result = stanford_ner_drop_rp.parse(ner_result)
# 打印解析结果,方便调试
print(stanford_ner_drop_result)
return stanford_ner_drop_result
except Exception as e:
print(f"Error occurred: {e}")
print(f"The error sentence is: {raw_sentence}")
return False
- tools.py
#encoding=utf8
#encoding=utf8
import os,gc,re,sys
from stanfordcorenlp import StanfordCoreNLP
stanford_nlp = StanfordCoreNLP(r'stanfordcorenlp',lang = 'en')
drop_pos_set=set(['xu','xx','y','yg','wh','wky','wkz','wp','ws','wyy','wyz','wb','u','ud','ude1','ude2','ude3','udeng','udh'])
han_pattern=re.compile(r'[^\dA-Za-z\u3007\u4E00-\u9FCB\uE815-\uE864]+')
def to_string(sentence,return_generator=False):
if return_generator:
return (word_pos_item.toString().split('/') for word_pos_item in Tokenizer.segment(sentence))
else:
# res=[(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)]
return [(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)]
def to_string_hanlp(sentence,return_generator=False):
if return_generator:
return (word_pos_item.toString().split('/') for word_pos_item in HanLP.segment(sentence))
else:
# res=[(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)]
return [(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)]
def seg_sentences(sentence,with_filter=True,return_generator=False):
segs=to_string(sentence,return_generator=return_generator)
#print(segs)
#g=[]
if with_filter:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ' and word_pos_pair[1] not in drop_pos_set]
else:
g = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ']
return iter(g) if return_generator else g
def ner_stanford(raw_sentence,return_list=True):
if len(raw_sentence.strip())>0:
return stanford_nlp.ner(raw_sentence) if return_list else iter(stanford_nlp.ner(raw_sentence))
def ner_hanlp(raw_sentence,return_list=True):
if len(raw_sentence.strip())>0:
return NLPTokenizer.segment(raw_sentence) if return_list else iter(NLPTokenizer.segment(raw_sentence))
def cut_stanford(raw_sentence,return_list=True):
if len(raw_sentence.strip())>0:
return stanford_nlp.pos_tag(raw_sentence) if return_list else iter(stanford_nlp.pos_tag(raw_sentence))
4 名词短语块,名词合并
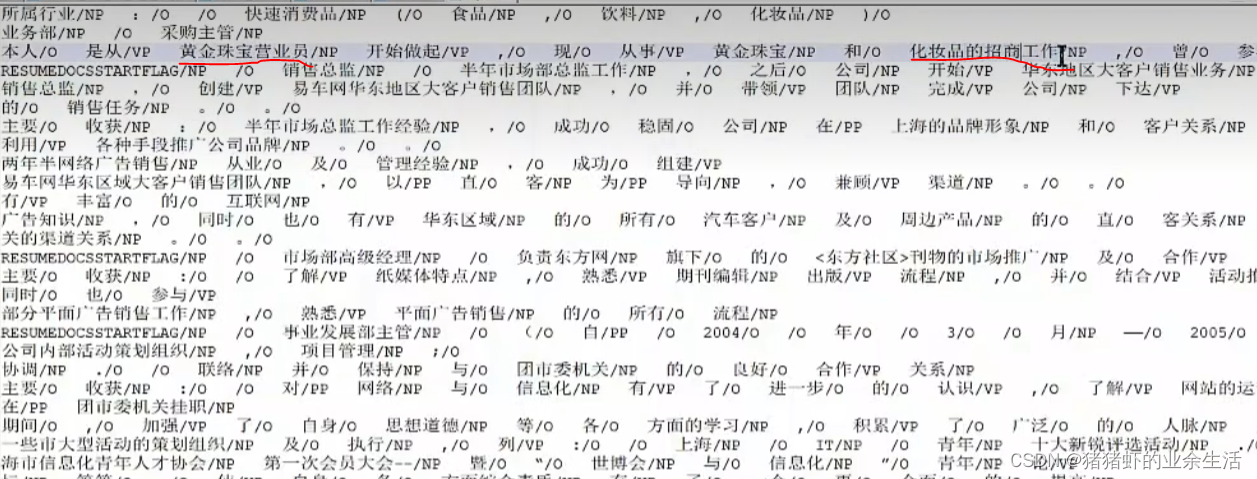
合并的原则是有一个核心词,下面案例有些名词比如黄金珠宝营业员,营业员是核心词,围绕这个词,把其周围的类似定语的东西提取出来。在NLP内是经常用到的,都则很多意思表达都不完整
4 word embedding 词嵌入

# # todo 3: 词嵌入的生成过程和可视化
# 导入torch和tensorboard的摘要写入方法
import torch
import json
import fileinput
from torch.utils.tensorboard import SummaryWriter
# 实例化一个摘要写入对象
writer = SummaryWriter()
# 随机初始化一个100x50的矩阵, 认为它是我们已经得到的词嵌入矩阵
# 代表100个词汇, 每个词汇被表示成50维的向量 这里的100需要和100个词对应
embedded = torch.randn(100, 60)
# 导入事先准备好的100个中文词汇文件, 形成meta列表原始词汇
# print('====', len(list(fileinput.FileInput("./vocab100.csv"))))
# meta = list(map(lambda x: x.strip(), fileinput.FileInput("./vocab100.csv")))
# 打开文件并指定编码
with open("./vocab100.csv", encoding='utf-8') as f:
# 去除每行两端的空白字符
meta = [line.strip() for line in f]
print(meta)
writer.add_embedding(embedded, metadata=meta)
writer.close()
print('close.....')
三 文本数据分析
- 句子长度分布: 如果大量句子都是十几,那么就是短文本,倾向于选择处理短文本处理更好的模型;如果句子长度分布差距很大,那就可能需要截断补齐等操作



训练模型
A.材料说明



B 句子长度分布打印
import seaborn as sns #统计标签数量
import pandas as pd
import matplotlib.pyplot as plt
# 设置显示风格
plt.style.use('fivethirtyeight')
# 分别读取训练tsv和验证tsv
train_data = pd.read_csv("./cn_data/train.tsv", sep="\t")
valid_data = pd.read_csv("./cn_data/dev.tsv", sep="\t")
# #获取训练集不同标签数量
sns.countplot(x="label", data=train_data)
plt.title("train data")
plt.show()
# #获取测试集不同标签数量
sns.countplot(x ="label", data=valid_data)
plt.title("valid data")
plt.show()

- 语句
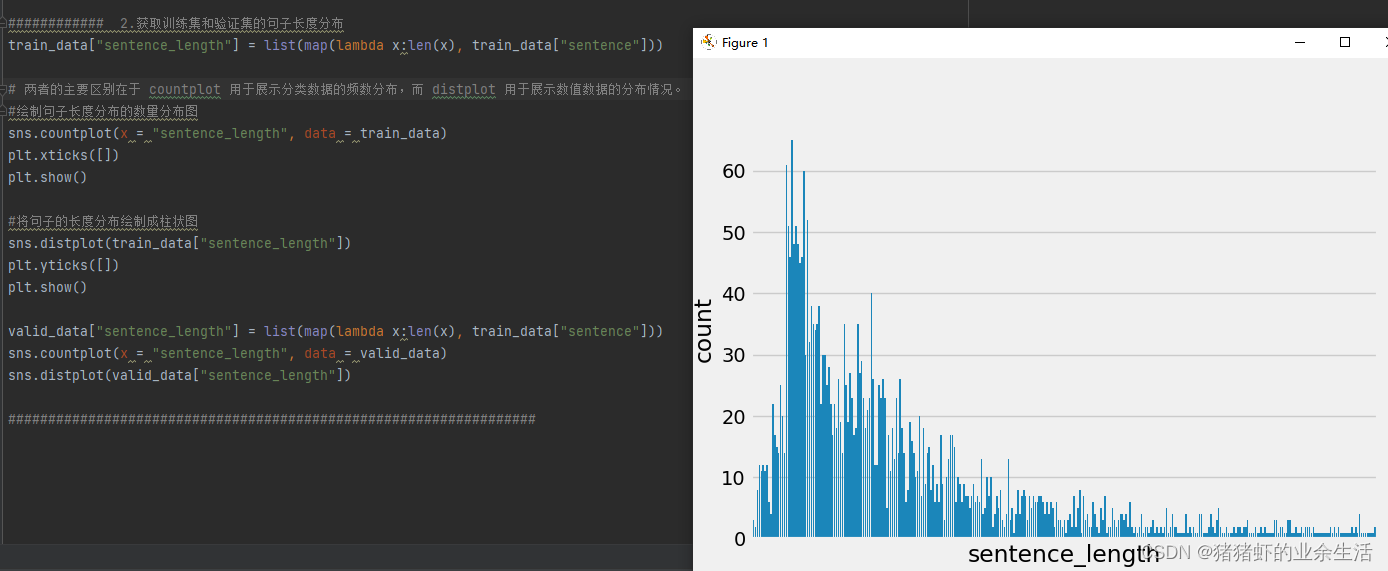
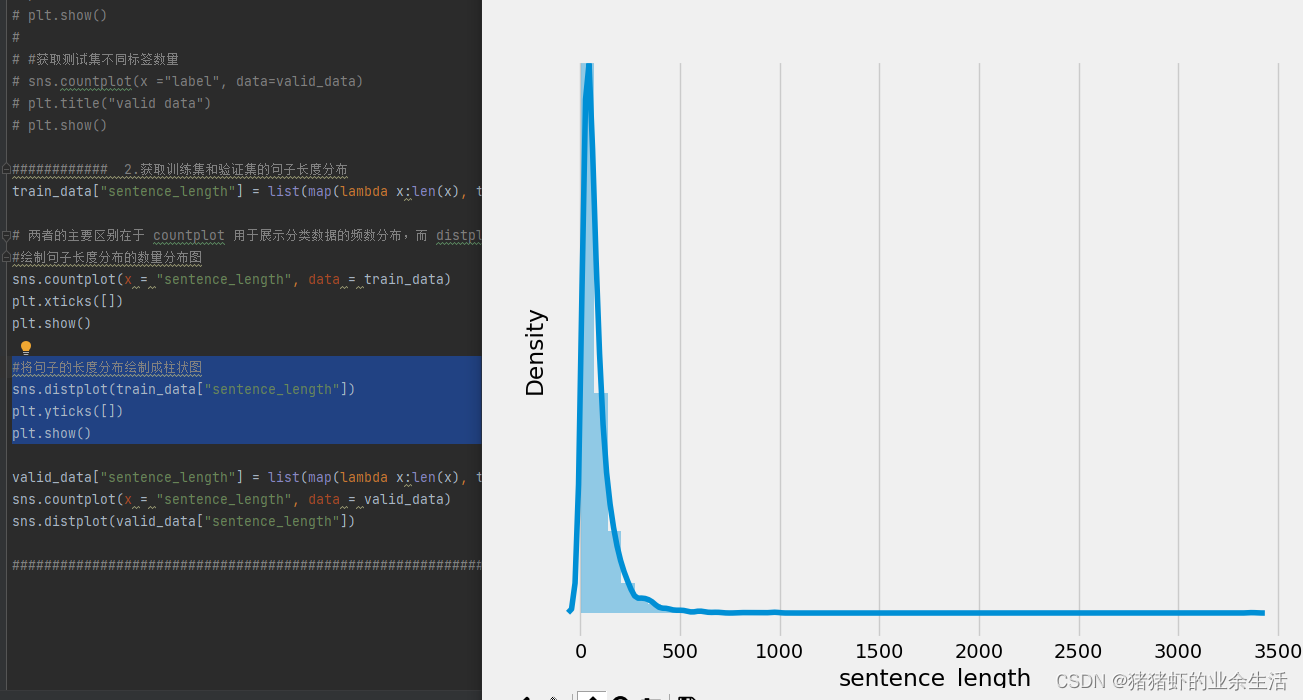
sns.countplot(x = "sentence_length", data = train_data) plt.xticks([]) plt.show()和语句sns.distplot(train_data["sentence_length"]) plt.yticks([]) plt.show()之间的区别在于 countplot 用于展示分类数据的频数分布,而 distplot 用于展示数值数据的分布情况。绘制句子长度分布的数量分布图 - 从绘图结果来看,可以知道数据的长度分布基本上是在300左右偏多
train_data["sentence_length"] = list(map(lambda x:len(x), train_data["sentence"]))
# 两者的主要区别在于 countplot 用于展示分类数据的频数分布,而 distplot 用于展示数值数据的分布情况。
#绘制句子长度分布的数量分布图
sns.countplot(x = "sentence_length", data = train_data)
plt.xticks([])
plt.show()
#将句子的长度分布绘制成柱状图
sns.distplot(train_data["sentence_length"])
plt.yticks([])
plt.show()
valid_data["sentence_length"] = list(map(lambda x:len(x), valid_data["sentence"]))
sns.countplot(x = "sentence_length", data = valid_data)
sns.distplot(valid_data["sentence_length"])
C 正负样本长度分布
sns.stripplot(y='sentence_length', x = 'label',data=train_data)
plt.title("train data")
plt.show()
sns.stripplot(y='sentence_length', x = 'label',data=valid_data)
plt.title("valid data")
plt.show()


D 获取数据集 不同(不重复)词汇的总数统计
# # # # todo 5: 不同词汇总数统计
import jieba
from itertools import chain
import seaborn as sns #统计标签数量
import pandas as pd
import matplotlib.pyplot as plt
# # 设置显示风格
plt.style.use('fivethirtyeight')
# 分别读取训练tsv和验证tsv
train_data = pd.read_csv("./cn_data/train.tsv", sep="\t")
valid_data = pd.read_csv("./cn_data/dev.tsv", sep="\t")
#对句子进行分词,然后统计出不同词汇的总数
train_vocab = set(chain(*map(lambda x:jieba.lcut(x), train_data["sentence"])))
print("训练集共包含不同词汇总数为:",len(train_vocab))
valid_vocab = set(chain(*map(lambda x:jieba.lcut(x), valid_data["sentence"])))
print("测试集共包含不同词汇总数为:",len(valid_vocab))

E 获取训练集中,正负样本的高频形容词词云

import jieba
from itertools import chain
import seaborn as sns #统计标签数量
import pandas as pd
import matplotlib.pyplot as plt
import jieba.posseg as pseg
from wordcloud import WordCloud
def get_a_list(text):
### 获取形容词列表
r = []
for g in pseg.lcut(text):
if g.flag == "a": #判断是不是形容词
r.append(g.word)
return r
def get_word_cloud(keyword_list):
#font_path字体路径,自己指定的
#max_words:指词云图像最多显示多少词汇
#实例化一个类对象
wordcloud = WordCloud(font_path="./SimHei.ttf", max_words=100,background_color="white")
#将传入的列表转换成字符串
keyword_string = " ".join(keyword_list)
#生成词云
wordcloud.generate(keyword_string)
#绘制并显示
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# # 设置显示风格
plt.style.use('fivethirtyeight')
# 分别读取训练tsv和验证tsv
train_data = pd.read_csv("./cn_data/train.tsv", sep="\t")
valid_data = pd.read_csv("./cn_data/dev.tsv", sep="\t")
#获取训练样本上的正/负样本
#train_data[train_data["label"] == 1]找到label等于1的列,然后取出对应的行里面的sentence里面的数据
#训练数据是分成了两列,一列是sentence,一列是label,是人为给的名字
p_train_data = train_data[train_data["label"] == 1]["sentence"] #sentence是自定义数据列名称
n_train_data = train_data[train_data["label"] == 0]["sentence"]
#对正样本的每个句子的
train_p_a_vocab = chain(*map(lambda x: get_a_list(x),p_train_data))
train_n_a_vocab = chain(*map(lambda x: get_a_list(x),n_train_data))
#绘制词云
get_word_cloud(train_p_a_vocab)
get_word_cloud(train_n_a_vocab)


四 文本特征处理

1 n-gram特征


- 实现代码
def create_ngram_set(input_list):
ngram_range = 2
#zip配对的意思,相邻元素组成一个对,
#input_list[i:]表示当前如果循环到i,就取input_list里面的第i个元素到最后一个元素
return set(zip(*[input_list[i:] for i in range(ngram_range)]))
input_list = [1,3,2,1,5,3]
res = create_ngram_set(input_list)
print(res)
- 输出结果
{(2, 1), (1, 5), (5, 3), (3, 2), (1, 3)}
2 文本长度规范

from keras.preprocessing import sequence
def padding(x_train):
cutlen = 10
return sequence.pad_sequences(x_train,cutlen)
x_train = [[1,2,3,4,5,6,7,8,9,10,11,12],
[21,22,23,24,25]]
res = padding(x_train)
print(res)
- 输出
[[ 3 4 5 6 7 8 9 10 11 12] [ 0 0 0 0 0 21 22 23 24 25]]
五 文本增强


import jieba
from itertools import chain
import seaborn as sns #统计标签数量
import pandas as pd
import matplotlib.pyplot as plt
import jieba.posseg as pseg
from wordcloud import WordCloud
from keras.preprocessing import sequence
from googletrans import Translator
p_samples1 = "酒店设施非常不错"
p_samples2 = "这家价格很便宜"
n_samples1 = "拖鞋都发霉了,太差了"
n_samples2 = "电视不好用,没有看到足球"
translator = Translator()
#
#[p_samples1,p_samples2, n_samples1,n_samples2]传入要翻译的语句
translations = translator.translate([p_samples1,p_samples2, n_samples1,n_samples2], dest='ko')
#x.text取出translations里面的text的结果
ko_res = list(map(lambda x:x.text, translations))
print("中文翻译成韩文的结果:")
print(ko_res)
translations = translator.translate([p_samples1,p_samples2, n_samples1,n_samples2], dest = 'zh-cn')
cn_res = list(map(lambda x:x.text, translations))
print("韩文翻译成中文结果:")
print(cn_res)