《易经》:“初九:潜龙勿用”。潜龙的意思是隐藏,阳气潜藏,阳爻位于最下方称为“初九”,龙潜于渊,是学而未成的阶段,此时需要打好基础。
而模块一我们就是讲解推荐系统有关的概念、基础数据体系搭建、埋点上报、用户和物品画像、标签挖掘、AB 测试系统等各基础知识,助你快速了解互联网业务场景及推荐系统的作用。
这一讲作为模块一的第一讲,有必要先来了解一下个性化流量分发体系的整个搭建流程。
在课程开始之前,我们先看一个例子:
在日常生活中,打开 58 同城网站时,我们可能会遇到以下情形:
-
和好友同时打开 App,发现我俩的首页金刚区本地服务的图标和文字不一样?
-
搜索“小区搬家”,发现首页搜索框里的推荐词也发生了变化。

58 同城怎么知道我需要什么样的本地服务?为什么搜索框里的推荐词也发生了变化?这就涉及这一讲要讲的内容——个性化流量分发体系。
以平台是否掌控整体流量分配情况为依据,我们把个性化流量分发体系的模式分为中心化模式和去中心化模式。为了方便你理解,我们再拿 58 同城举例(主要看下中心化模式)。我们知道 58 同城 App 首页有搜索框、分类宫格式导航、部落信息轮播、头条栏目、猜你喜欢推荐等业务模块,流量就是通过这样的设计模式从首页中心化分配到其他各个业务模块。
相信你对个性化流量分发体系已经有了初步了解,接下来我们继续揭开它的真面目。
个性化流量分发体系
那到底什么是个性化流量分发体系呢?个性化流量分发体系是通过、策略手段来平衡用户体验和商业目标。在这个过程中,我们需要把用户的访问流量合理分配到各个流量利用区,促进流量利用最大化,或者说获得流量最大限度转化,最终提升流量价值,从而达到战略意图。因此,个性化流量分发体系的本质就是对整个产品的用户行为路径进行优化。
在个性化流量分发体系搭建过程中,数据是非常重要的资产,也是驱动决策的燃料。这里提及的数据,主要指的是基本信息、显式反馈、隐式反馈这三种。
-
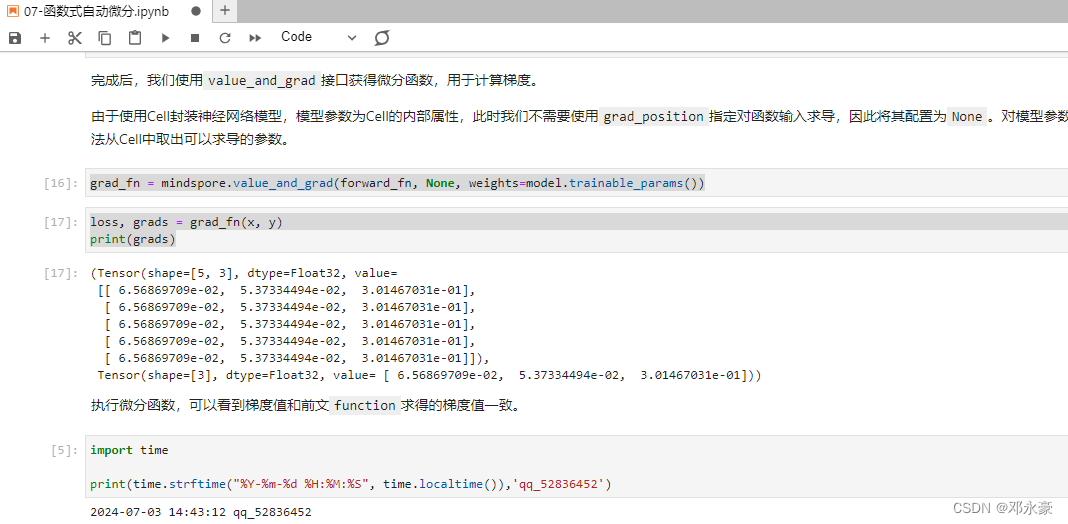
基本信息:主要指用户的性别/年龄/地区、物品的分类/款式/重量等。
-
显式反馈:一般指用户对物品的真实评分,这类数据的特点是用户操作成本高,数据量小,更真实。
-
隐式反馈:一般指除直接评分以外的若干用户行为数据,包括点击、加购、收藏、购买、浏览时长等,这类数据特点是用户操作成本低、数据量大、具有一定的不真实性。用户行为数据还可以进一步通过聚合、梳理形成用户的行为表现数据(如活跃度、回访、复购情况等)。
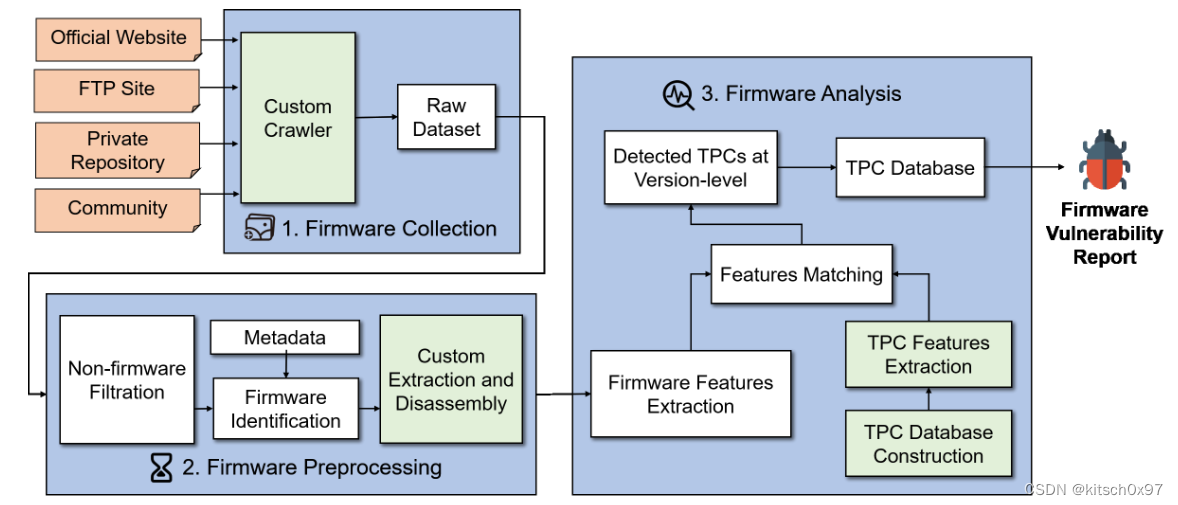
而个性化流量分发的过程,其实就是先对基本数据和反馈数据进行加工,再利用加工结果进行决策的过程。在数据流转的过程中,个性化流量分发体系被划分为数据采集层、数据加工层、数据决策层、效用评价层这 4 层。
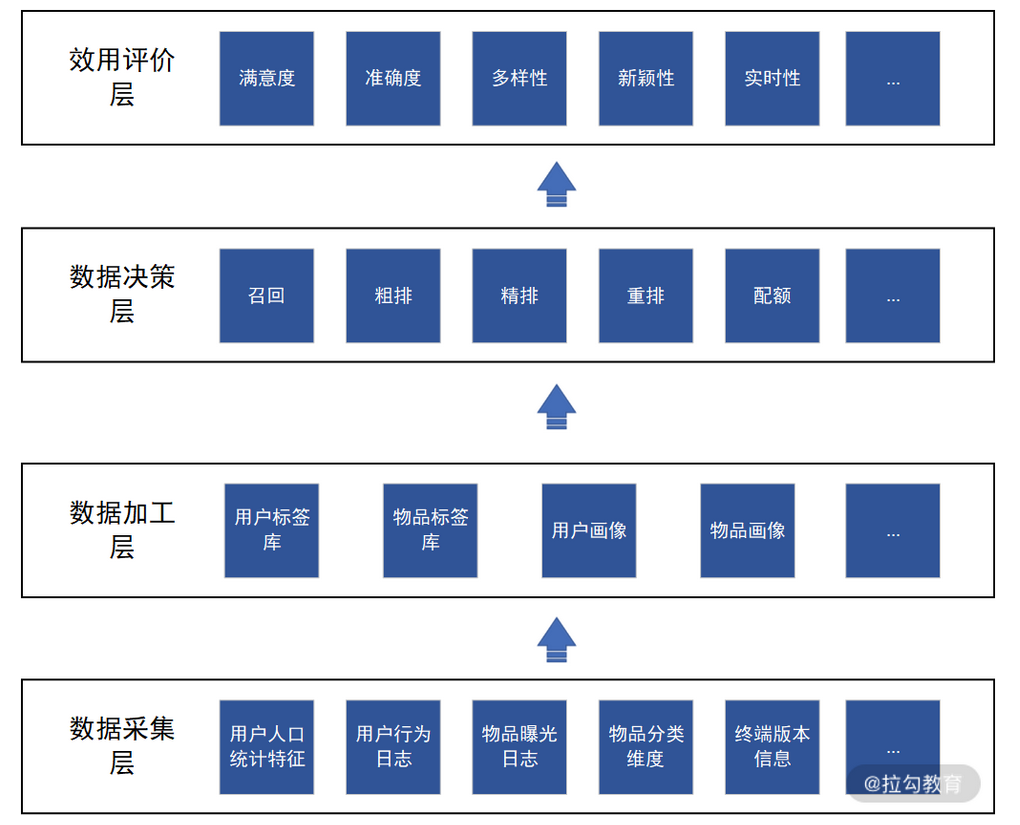
个性化流量分发体系架构
从上图可知,在数据采集阶段,我们的主要工作是全面了解产品和用户。在数据加工阶段,我们的主要工作是对用户和物品分门别类。在数据决策阶段,我们的主要工作是驱动分发方案和产品优化,这也是搜索和推荐等产品的工程和算法能力输出阶段。在效用评价阶段,我们的主要工作是评估流量分发的效果并形成数据反馈。
接下来我们着重讲解在数据采集阶段,我们都需要做哪些工作?
特殊说明:数据加工阶段的内容我们将在 02 讲和 03 讲中着重讲解,效用评价阶段的内容在 04 讲中着重说明,而数据决策阶段因为是推荐系统的核心,也是本专栏的重中之重,所以会放在模块二、三、四、五中进行深度说明。
数据采集阶段
《道德经》中说“九层之台,起于累土”,数据采集阶段作为后面三个阶段的基础,虽然它不涉及复杂算法,但这个阶段的工作内容相对细碎且容易出错,因此我们有必要从细微处着手,先把地基打牢。
在实际业务中,如果我们拥有海量数据,但是采集的数据质量很差,那么此时就算使用再好的算法也是“巧妇难为无米之炊”,并会使得后面三个阶段徒劳无功。由此可见,数据采集阶段的意义重大。
在数据采集阶段,它的最大价值是规范、高效、准确地获取海量数据,以此保证数据的准确性,防止数据出现偏差。
下面,我们通过一张图了解整个数据采集流程,以及在这个阶段我们需要做哪些工作。

数据采集流程
从图中可知,数据采集流程包括数据需求梳理、埋点规范制定、埋点实施、数据上报、生成数据表、数据验收等流程。而在数据采集之前,我们的首要工作是数据需求梳理、埋点规范构建、埋点位置梳理。
(1)数据需求梳理
在真实业务中,数据需求的来源一般都比较广,除推荐系统的需求外,还包括营销、画像、广告、标签等需求。
面对诸多需求时,我们不仅需要构建灵活的数据埋点上报规范,还要满足业务的现有需求,更重要的是要为将来可能出现的需求留出扩展空间。这就要求我们将条理化的业务指标体系(即数据需求)梳理成具体实施需求,而解决该问题的关键在于下面三个步骤。
步骤一:确认事件与变量
事件指的是我们需要分析的数据来源,最终它是一个结果性指标,比如支付成功。而变量指的是事件的维度或属性,比如用户性别、商品的种类。
这里我们可以将事件视为产品中的操作,例如加入购物车、支付成功,然后将变量视为描述事件的属性,比如不同商品的加购次数中,商品名称就是变量。
特殊说明:如果从不同的角度定位一个问题,事件和变量都会发生改变,这就要求我们基于数据需求,找到事件与变量之间搭配的最优解。
步骤二:明确事件的触发时机
在这个过程中,我们需要思考什么时候才是记录事件的合理时机,因为不同的时机其分享成功率也不一样,同时不同的触发时机将带来不同的数据口径。例如分享成功事件面临用户点击微信发生分享动作、用户分享后跳转到相应页面这 2 个时机。因此,数据使用者需要明确事件的触发时机。
时机的选择没有对错之分,我们根据具体的业务需求来制定即可。
步骤三:明确实施优先级
在实际业务中,业务部门必须基于业务指标明确实施埋点的优先级,因为开发部门不可能一次性完成大量事件的埋点。比如电商业务中,我们应该优先实施购买流程这个关键事件,与此冲突的其他事件都应该往后排序。
而且在实际业务中,我们往往需要考虑技术实现成本。如果技术实现成本不一致,我们应该优先落实能够最快落地的,以确保技术的准确性,比如有的埋点需要跨越多个接口;而如果技术实现成本相同则应该优先实施业务数据价值更高的。
(2)埋点规范制定
举个例子:某工程师给双十一活动页面命名时,采用的是拼音与英文相结合的方式,而这种不规范的埋点会让实施人员产生混淆,最终出现错误埋点。埋点规范的价值就在于帮助我们快速理解业务需求,并高效落地埋点方案。
在埋点规范制定过程中,我们通常需要遵循以下三点原则:
-
上报内容格式清晰、简单,目标易于统计和使用;
-
各端各推荐位置上报的请求曝光内容、可见曝光内容、点击内容、自动播放格式统一;
-
所有推荐的内容类型编号,业务需要进行统一编排和维表维护,从请求曝光——>可见曝光——>点击——>落地页这四个阶段均需要保持一致。
(3)埋点实施
埋点规范是埋点实施的前置约束,在埋点实施时,我们需要严格按照埋点规范实施埋点,其中,需要注意三个要点。
-
明确事件上报的条件:比如请求曝光时,我们在埋点规范中明确注明请求成功后立即上报还是在曝光页面停留超过一定时长后再上报等问题。
-
明确字段参数的数据源:通常埋点同学对数据敏感度差,为了防止数据取错,就要求我们与埋点同学一起明确每个参数的正确取数位置。
-
数据采集流程:数据上报后,为方便数据仓库同学高效、便捷地处理日志,我们需要明确每种数据的格式,因为非标准的格式会耗费大量的时间和精力处理格式。
(4)数据上报
埋点完备且上报的数据经过数据仓库处理后就可以直接被应用了。
(5)数据统计
数据统计是非常重要、非常基础的数据应用,例如推荐系统的转化率指标( CTR),它是通过点击数/可见曝光数来计算的。在这个公式中,我们发现如果没有点击事件和可见曝光事件的数据埋点,就不可能产生 CTR 这个数据,推荐系统的效果也就很难量化评估。
(6)埋点验收
在埋点验收阶段,我们需要验收所有推荐位 置、每个位置下的所有参数、每个参数的数据格式。除此之外,我们还需要将不同数据进行连接,把不同系统的数据以报表的形式展现,并对数据的有效性和准确性进行验证。
最后,我们总结一下数据采集的整个流程:首先,我们需要对收集哪些数据进行需求梳理,并建立埋点规范;其次,依据埋点规范实施数据埋点;然后,接收实际上报的数据,并落入数据仓库;紧接着,在数据仓库中生成满足业务需求的数据表;最后,对数据埋点进行验收。
本节总结
学到这里,你已经了解了流量分发的四个阶段和数据采集阶段的完整流程啦,棒棒哒~
《道德经》中说“重为轻根,静为躁君。是以圣人终日行不离辎重。”在流量分发体系中,数据就是这个系统的辎重,而数据驱动思维方式是每个推荐算法工程师必备的思维方式。
根据这种思维方式,我们可以快速获取产品改进的分析流程:首先,确定个人分析目标,从数据规模、数据分布等角度介入发现问题;其次,确定需要分析的数据,将数据细化到数据分析指标,预估数据的有效阈值;然后,寻找并获取评估数据的渠道,得到自己想要的原始数据;接着,对数据进行合理加工和分析,得出分析结论;最后,对得到的结果进行合理分析,指导推荐迭代。
这里插播一道思考题:你还知道哪些流量分发手段呢?欢迎你在留言区进行互动、交流,分享你的个人看法。
另外,如果你觉得本专栏有价值,欢迎分享给更多好友~