MongoDB
本文介绍非关系型数据库MongoDB的基础知识和常见面试题。
(一)基础知识
1. 介绍:MongoDB是一个基于分布式文件存储的数据库,由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
2.特点
| 特点 | 说明 |
|---|---|
| 文档存储 | 使用 BSON(二进制 JSON)格式存储文档,支持嵌套结构和数组。 |
| 灵活的模式(Schema-less) | 支持动态模式设计,文档结构可以不固定,适合快速迭代开发。 |
| 高性能 | 通过内存映射文件和高效的索引机制,提供高性能读写操作。 |
| 高可用性 | 支持复制集(Replica Set),提供自动故障转移和数据冗余。 |
| 横向扩展 | 支持分片(Sharding)功能,通过分布式架构实现数据的水平扩展。 |
| 强一致性 | 默认提供强一致性保证,通过复制集配置可以调整一致性级别。 |
| 丰富的查询语言 | 提供丰富的查询语言,支持字段、范围、正则表达式查询以及聚合框架。 |
| 原子操作 | 支持单文档级别的原子操作,确保数据修改的一致性和完整性。 |
| 支持事务 | 4.0 版本开始支持多文档 ACID 事务,增强数据操作的可靠性。 |
| 跨平台 | 支持多种操作系统,包括 Windows、Linux 和 macOS。 |
| 易于集成 | 提供多种官方驱动程序,支持多种编程语言,如 JavaScript、Python、Java、C# 等。 |
| 强大的社区支持 | 拥有活跃的社区和丰富的文档资料,便于开发者学习和使用。 |
| 灵活的索引 | 支持多种类型的索引,如单字段索引、复合索引、地理空间索引和全文索引。 |
| 聚合框架 | 提供强大的聚合框架,支持数据处理和分析操作,如过滤、排序、分组、投影等。 |
| 文件存储 | 通过 GridFS 实现大文件存储,适用于存储图片、视频等大文件数据。 |
| 安全性 | 提供认证和授权机制,支持基于角色的访问控制(RBAC),确保数据安全。 |
| 备份与恢复 | 提供多种备份与恢复机制,包括快照备份、导入导出工具和云备份服务。 |
| 可视化工具 | 提供官方的 MongoDB Compass 可视化工具,便于管理和分析数据库。 |
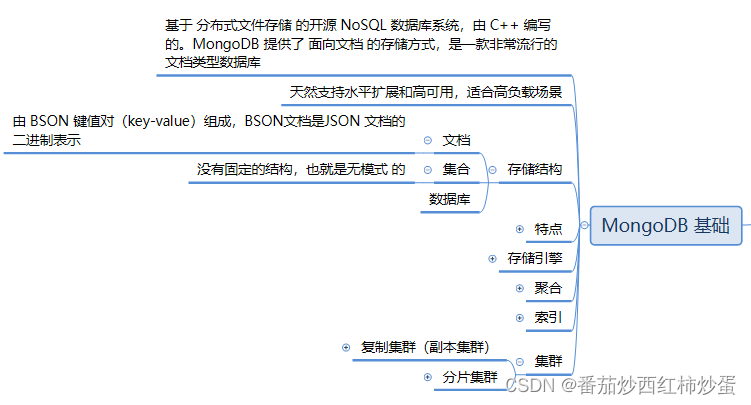
3. 存储结构
(1)文档
文档是 MongoDB 的基本数据单位,使用 BSON 格式存储。每个文档包含键值对,类似于 JSON 对象.
注:BSON文档是JSON 文档的二进制表示
(2)集合
集合是一组文档的容器,相当于关系型数据库中的表。集合中的文档可以具有不同的结构。
(3)数据库
数据库是集合的命名空间,相当于关系型数据库中的数据库,每个数据库包含集合、索引和一些元数据。
4. 存储引擎
MangoDB的默认存储引擎是 WiredTiger,支持文档级别的并发控制和压缩。除此之外,MangoDB还支持 MMAPv1(旧版本)和其他第三方存储引擎。
(1)WiredTiger存储引擎
① WiredTiger是MongoDB 3.2 版本开始默认的存储引擎,提供了更高的并发性、压缩和高效的内存使用。
② 特点
- 文档级锁定:WiredTiger 使用文档级锁定,提高了并发写操作的性能
- 数据压缩:支持数据和索引压缩,减少磁盘空间的使用
- 缓存管理:WiredTiger 使用自适应缓存管理,优化内存使用
- 事务支持:提供多文档 ACID 事务支持,保证数据一致性(与InnoDB事务不相同)
③ 配置
storage:
dbPath: /var/lib/mongodb
engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 1
statisticsLogDelaySecs: 0
journalCompressor: snappy
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
(2)MMAPv1 存储引擎
① MMAPv1 是 MongoDB 的原始存储引擎,在 MongoDB 3.0 之前是默认存储引擎,它使用内存映射文件来存储数据。
② 特点
- 集合级锁定:MMAPv1 使用集合级锁定,适用于读操作较多的场景。
- 简单实现:设计简单,适合需要快速读取的大量数据
③ 配置
storage:
dbPath: /var/lib/mongodb
engine: mmapv1
mmapv1:
nsSize: 16
smallFiles: true
journal:
enabled: true
(3)In-Memory 存储引擎((在 MongoDB Enterprise 中可用))
① In-Memory 存储引擎将所有数据存储在内存中,适用于需要极高性能和低延迟的场景。
② 特点
- 高性能:由于数据全部存储在内存中,读写操作速度极快。
- 无持久化:数据仅在内存中存储,服务器重启后数据会丢失。
③ 配置
storage:
dbPath: /var/lib/mongodb
engine: inMemory
inMemory:
engineConfig:
inMemorySizeGB: 2
5. 索引
- 单字段索引
- 复合索引:遵循最左前缀原则
- 多键索引:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引;多键索引为数组中每一个值创建索引
- 哈希索引:按数据的哈希值索引,用在哈希分片集群上
- 文本索引: 支持对字符串内容的文本搜索查询,一个集合一个
- TTL索引:参考MongoDB索引
- 地理位置索引
(二)常见面试题
1. MongoDB 集群
(1)复制集群
- 是一组维护相同数据集合的 mongodb 进程
- 组成:包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)
- 主节点负责写和读,从节点负责读,仲裁节点不存储数据,只负责选举时投票
- 主节点与备节点之间是通过 oplog(操作日志) 来同步数据的( local 库下的一个特殊的 上限集合(Capped Collection) ,用来保存写操作所产生的增量日志)
(2)分片集群
- 数据被均衡的分布在不同分片中
- 组成
① Config Servers:配置服务器,本质上是一个 MongoDB 的副本集,负责存储集群的各种元数据和配置,如分片地址、Chunks 等
② Mongos:路由服务,不存具体数据,从 Config 获取集群配置讲请求转发到特定的分片,并且整合分片结果返回给客户端
③ Shard:每个分片是整体数据的一部分子集 - 分片算法
① 基于范围的分片:适合分片键的值不是单调递增或单调递减、分片键的值基数大且重复的频率低、需要范围查询等业务场景。
② 基于 Hash 值的分片:适合分片键的值存在单调递增或递减、片键的值基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大等业务场景。
2. MongoDB聚合
(1)介绍
① MongoDB 的聚合框架是一个强大的工具,用于处理数据并生成汇总结果。它允许在文档集合上执行复杂的数据处理和分析操作。
② 聚合管道:是一系列数据处理阶段的组合,每个阶段会对输入文档进行操作,并将结果传递给下一个阶段。
(2)聚合管道常用阶段操作符
- $match:过滤文档,类似于查询的 find 操作
- $group:将文档分组,并可对每个分组进行计算
- $sort:对文档排序
- $project:重新定义文档的结构,可以添加、删除字段
- $limit:限制返回的文档数量
- $skip:跳过指定数量的文档
- $unwind:将数组类型字段拆分为多个文档
(3)聚合框架的性能优化
- 使用索引:在 $match 阶段尽量使用索引,以提高过滤数据的速度
- 限制返回数据量:使用 $limit 和 $skip 控制返回的数据量,避免一次性处理大量数据
- 简化管道阶段:尽量减少管道阶段的数量,每个阶段只处理必要的数据
- 适当使用 $project:在数据进入聚合管道时尽早使用 $project 只保留需要的字段,以减少数据传递的开销
3. MongoDB的数据备份和恢复
(1)备份
- mongodump 命令将 MongoDB 数据导出为 BSON 格式的文件
- 可以备份整个数据库或指定的集合
- 示例
mongodump --db <database_name> --out <backup_directory>
(2)恢复
- mongorestore 命令将 BSON 文件导入到 MongoDB 中,用于恢复数据
- 示例
mongorestore --db <database_name> <backup_directory>
(3)文件级备份
- 通过复制 MongoDB 数据存储文件来实现,适用于使用 WiredTiger 存储引擎的 MongoDB 数据库
- 步骤
① 锁定数据库:使用 fsync 锁定数据库以确保数据一致性
② 复制数据文件:复制 MongoDB 数据存储文件
③ 解锁数据库:解锁数据库
4. MongoDB事务
- MongoDB 在 4.0 版本开始支持多文档 ACID 事务,使其在操作多个文档和集合时能够保证数据的一致性。
- 复制集环境:MongoDB 的多文档事务需要在复制集环境中才能使用。
- 跨分片事务:MongoDB 4.2 及以上版本支持跨分片事务,但需要配置分片集群。
5. 如何处理 MongoDB 中的慢查询
(1)慢查询日志
- MongoDB 具有内置的慢查询日志功能,可以记录超过指定时间的查询。配置方法如下:
# mongod.conf
operationProfiling:
slowOpThresholdMs: 100 # 设置慢查询阈值为 100 毫秒
mode: slowOp
- db.currentOp() :可以查看当前正在执行的操作,包括运行时间长的查询
- db.system.profile:数据库的性能分析器,捕获详细的操作信息
(2)慢查询分析
使用 explain() 分析查询计划,帮助分析查询是如何执行的,包括使用的索引、扫描的文档数等












![[Leetcode 136][Easy]-只出现一次的数字](https://img-blog.csdnimg.cn/direct/9683f9b9cb97453e9b4a0ba9a726db96.png)