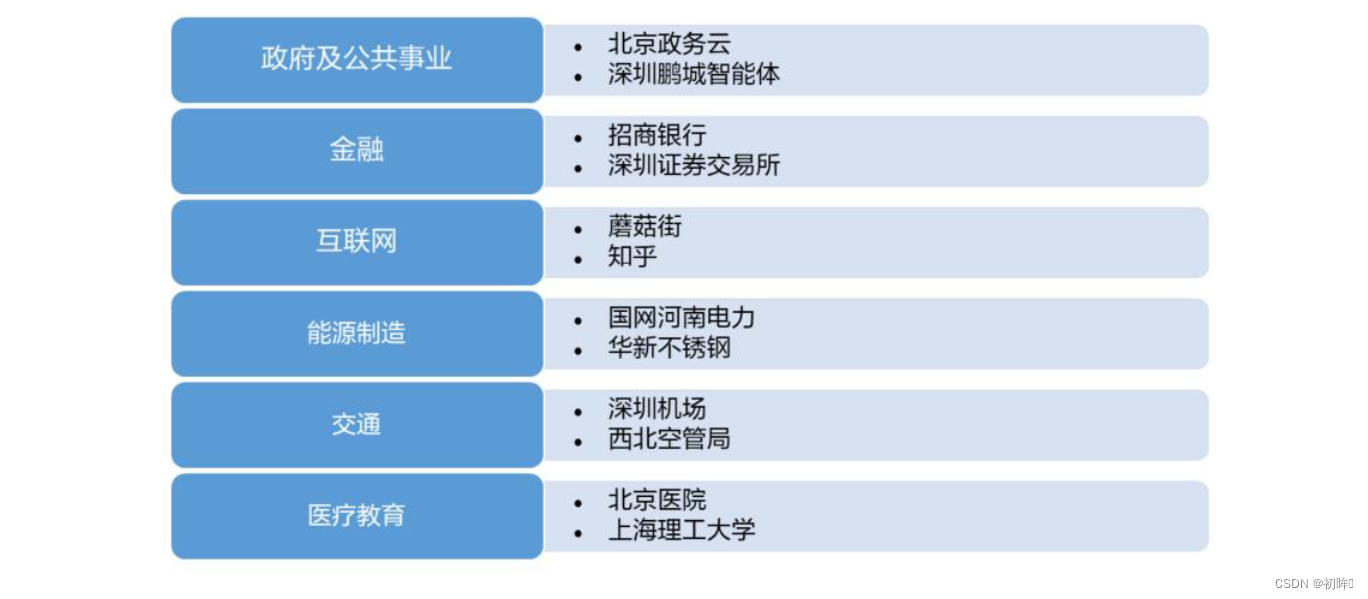
0 引言
随着水质自动站的普及,监测频次越来越高,自动监测越来越准确。
水质站点增多,连续的水质监测数据,给水质预测提供更多的训练基础。
长短时记忆网络(LSTM)适用于多变量、连续、自相关的数据预测。
人工神经网络模型特点为的非线性映射,是广泛应用的水质预测方法。
1.长短时记忆网络(LSTM)介绍
1.1起源
1997年,Hochreiter等提出了长短时记忆网络(LSTM),作为深度学习的一种,LSTM既考虑了多元变量间的非线性映射关系,又可以解决传统人工神经网络不能解决的时间序列长期依赖问题,应用场景包括:金融交易、交通预测、机器翻译、水质预测等。
1.2原理
长短时记忆网络(LSTM)是在循环神经网络(RNN)的基础上改进而来。
循环神经网络(RNN)作为深度学习方法的一种,其主要用途是对序列数据处理。RNN具有自连接隐层,其t时刻隐层状态依靠t-1时刻隐层状态进行更新,因此能够解决时间序列长期依赖的问题。RNN理论上可以进行非线性时间序列的有效处理,但实际对较长时间序列进行建模应用中,存在梯度消失及梯度爆炸的问题。
LSTM是RNN的一种变体,与RNN一样,LSTM隐藏层具有随时间序列的重复节点。LSTM节点相较RNN更为复杂,它将RNN中隐含层中的神经元替换为记忆体,以此实现序列信息的保留与长期记忆。
一个标准的LSTM记忆体见图1。
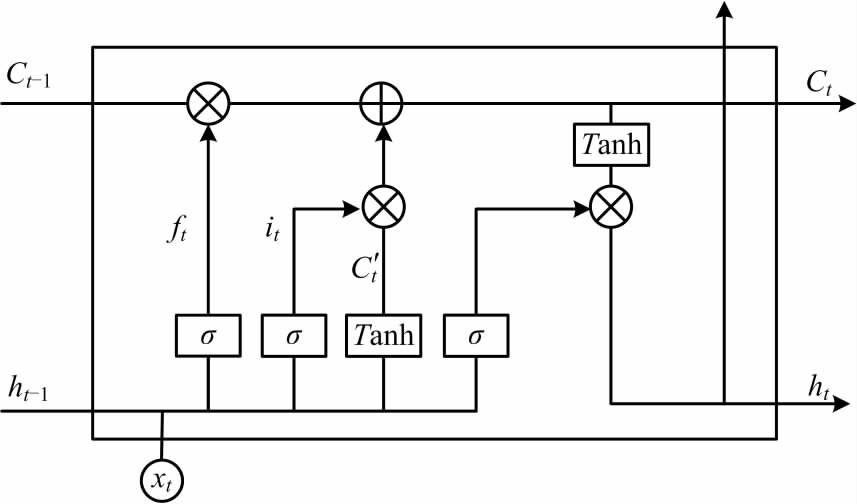
图 1 中,C 为 LSTM 记忆体的细胞状态,h 为节点的隐藏层状态。每个记忆体包含一到多个记忆细胞和 3 种“门”,LSTM 通过记忆细胞进行细胞状态信息存储,门结构负责细胞状态的更新与保持,3 种 “门”包括“遗忘门”“输入门”和“输出门”。“遗忘门”控制历史信息对当前细胞状态的影响。
f
t
f_t
ft 决定了上一时刻细胞状态
C
t
−
1
C_{t -1}
Ct−1 的通过程度。
f
t
=
σ
(
w
f
[
h
t
−
1
,
x
i
]
+
b
i
)
(01)
f_t=σ(w_f[h_{t-1},x_i]+bi)\tag{01}
ft=σ(wf[ht−1,xi]+bi)(01)
C
t
−
1
C_{t -1}
Ct−1为t - 1 时刻细胞状态;ht - 1为t - 1 时刻隐藏层状态; σ 为sigmoid 激活函数; wf 为输入循环权重; Xt 为当前时刻节点的输入值;bf 为偏置项。“输入门”决定了进入记忆细胞的是哪些信息,“遗忘门”与“输入门”结合可以实现细胞状态Ct 的更新。
i
t
=
σ
(
w
i
[
h
t
−
1
,
x
i
]
+
b
i
)
(02)
i_t=σ(w_i[h_{t-1},x_i]+b_i)\tag{02}
it=σ(wi[ht−1,xi]+bi)(02)
C
t
‘
=
T
a
n
h
(
w
C
[
h
t
−
1
,
x
i
]
+
b
C
)
(03)
C_t^‘=Tanh(w_C[h_{t-1},x_i]+b_C)\tag{03}
Ct‘=Tanh(wC[ht−1,xi]+bC)(03)
C
t
=
f
i
C
t
−
1
+
i
t
C
t
‘
(04)
C_t=f_iC_{t-1}+i_tC_t^‘\tag{04}
Ct=fiCt−1+itCt‘(04)
式中it 为输入门向量值; C’t为新信息; Ct 为t 时刻,细胞状态; bi、bC 为偏置项; wC 为输入权重。
“输出门”控制细胞状态值的输出,用Tanh 激活函数处理细胞状态后,与记忆单元状态值相乘得到输出信息。
σ
t
=
σ
(
w
o
[
h
t
−
1
,
x
t
]
+
b
o
)
(05)
σ_t=σ(w_o[h_{t-1},x_t]+b_o)\tag{05}
σt=σ(wo[ht−1,xt]+bo)(05)
h
t
=
o
t
×
T
a
n
h
(
C
t
)
(06)
h_t=o_t×Tanh(C_t)\tag{06}
ht=ot×Tanh(Ct)(06)
式中
h
t
h_t
ht为t 时刻隐藏层状态;
w
o
w_o
wo为输入权重;
o
t
o_t
ot为输出值;
b
o
b_o
bo为偏置项。
由上式可以看出,LSTM 节点通过门结构对细胞状态上的信息进行线性修改,从而保证在时间序列变长的情况下,依然能够保持时间相关性不会衰减。
2.算法流程及评价指标
2.1 算法流程
模型包括2个部分,分别为模型预处理与模型训练与评价。
2.1.1 数据预处理
数据预处理分为引入前处理及引入后处理。
引入前处理
引入前使用sql语句进行预处理,主要是去除0值、空值、异常值。这里异常值判断依据基于设备上下限、及经验。
select * FROM
(SELECT
CASE device_id
WHEN '87d39a3c' THEN '站点D'
WHEN '2ab9a08e' THEN '站点C'
WHEN '17b96c2b' THEN '站点B'
WHEN 'e83005a1' THEN '站点A'
END AS 'device_name' ,
data_time AS 'data_time',
CASE factor_code
WHEN 'w01003-Avg' THEN '浊度'
WHEN 'w21003-Avg' THEN '氨氮'
WHEN 'w01010-Avg' THEN '水温'
WHEN 'w01014-Avg' THEN '电导率'
WHEN 'w01019-Avg' THEN '高指'
WHEN 'w01001-Avg' THEN 'PH'
WHEN 'w21011-Avg' THEN '总磷'
WHEN 'w01009-Avg' THEN '溶解氧'
WHEN 'w21001-Avg' THEN '总氮'
END AS 'fator_code',
value as 'value'
FROM iot_devices_detail
where device_id in ('87d39a3c','2ab9a08e','17b96c2b','e83005a1')
and data_time > '2021-01-01 00:00:00'
and factor_code in ('w21003-Avg','w21011-Avg','w01019-Avg')
and frequency='h4'
and value>0
AND value is not null
and flag='1'
group by data_time,factor_code,device_id
order by device_id,factor_code) d
WHERE
d.fator_code='高指' and d.value between 2 and 20
or d.fator_code='总磷' and d.value between 0 and 1.5
or d.fator_code='氨氮' and d.value between 0 and 150
or d.fator_code='浊度' and d.value between 0 and 4000
or d.fator_code='水温' and d.value between 0 and 60
or d.fator_code='电导率' and d.value between 0 and 2000
or d.fator_code='PH' and d.value between 0 and 14
or d.fator_code='溶解氧' and d.value between 0 and 20
or d.fator_code='总氮' and d.value between 0 and 100
py引入可使用MySQL语句
其中sql为上面的代码,注意去掉换行符
def conn_sql(sql):
conn = pymysql.connect(host="",
port=3306,
user="",
password="",
db="",
charset="utf8")
sql = sql
read_sql = pd.read_sql(sql, conn)
return read_sql
# read_sql=conn_sql()
# 定义链接数据库
df = conn_sql(sql)
引入后处理
py数据处理内容为空值补全,补全方法为生成连续一小时时间序列index,数据拼接,数据线性插值。
def dataprocess_en(df, s, y):
"""
df:DataFrame时间序列数据;
s:device_name
y:fator_code
"""
aidunqiao = df.loc[df["device_name"] == s, :]
ai_cod = aidunqiao.loc[df["fator_code"] == y, :]
ai_cod_mn = ai_cod.loc[:, ["data_time", "value"]]
baseline = ai_cod.loc[:, ["data_time", "value"]]
ai_cod_mn.set_index("data_time", inplace=True)
interp_cod_mn = ai_cod_mn["value"].interpolate()
ai_cod_mn["value_2"] = interp_cod_mn
starttime = baseline.iloc[0, 0]
rows = baseline.shape[0]
endtime = baseline.iloc[rows - 1, 0]
year_month_day = pd.date_range(starttime, endtime, freq="h").strftime(
"%Y%m%d%h%m%s"
)
a_ser = pd.DataFrame({"data_time": year_month_day})
a_ser.set_index("data_time", inplace=True)
df = pd.concat([a_ser, ai_cod_mn], axis=0, join="outer")
df = df.reset_index(drop=False)
df["data_time"] = pd.to_datetime(df["data_time"])
df1 = df.drop_duplicates(subset="data_time", keep="last", ignore_index=True)
df2 = df1.sort_values(by="data_time", ignore_index=True)
df2["value_2"] = df2["value"].interpolate()
df2.drop(columns="value", inplace=True)
df2.set_index("data_time", inplace=True)
df2.columns = [s]
return df2
数据输出结果为,指定站点,制定因子的连续一小时监测结果。
引入数据后根据dataprocess_en,计算并拼接为最终预测基础数据。
station = df["device_name"].unique()
factors = df["fator_code"].unique()
dfn= pd.DataFrame()
for j in range(len(factors)):
dfn= pd.DataFrame()
for i in range(len(station)):
globals()['df_{}_{}'.format(i,j)] = data_process.dataprocess_en(df,station[i],factors[j])
globals()['dm{}'.format(j)] = pd.concat([dfn, globals()['df_{}_{}'.format(i,j)]],axis=1)
dfn=globals()['dm{}'.format(j)]
以上代码将输出dm0,dm1,dm2,不同因子的预测数据集
# 将需要预测的数据放在首列
pred_col= ['站点A']
all_cols = dm0.columns.values.tolist()
new_cols = pred_col + all_cols
new_cols = pd.Series(pred_col + all_cols).drop_duplicates()
当然也可以用比较直接的方式拼接数据集。
yx ="站点B"
fh ="站点C"
bl ="站点D"
cb = "站点A"
cod ="高指"
tp ="总磷"
nh3 ="氨氮"
df_cb_tp =data_process.dataprocess_en(df,cb,tp)
df_yx_tp =data_process.dataprocess_en(df,yx,tp)
df_fh_tp =data_process.dataprocess_en(df,fh,tp)
df_bl_tp =data_process.dataprocess_en(df,bl,tp)
df2 = pd.concat([df_cb_tp ,df_yx_tp,df_fh_tp,df_bl_tp],axis=1)
df2=df2[-3000:] # 取近3000个数据,保证运算速度和数据的更新程度
# df2=df2[::4] 可以取逐4小时值
以上数据准备结束,总磷预测数据集示例如下,第一列站点A为预测因变量。data_time为index
| data_time(index) | 站点A | 站点B | 站点C | 站点D |
|---|---|---|---|---|
| 2022-05-17 05:00:00 | 0.1955 | 0.250125 | 0.24355 | 0.247800 |
| 2022-05-17 06:00:00 | 0.1950 | 0.247950 | 0.24340 | 0.243100 |
| 2022-05-17 07:00:00 | 0.1945 | 0.245775 | 0.24325 | 0.238400 |
| 2022-05-17 08:00:00 | 0.1940 | 0.243600 | 0.24310 | 0.233700 |
| 2022-05-17 09:00:00 | 0.1885 | 0.240850 | 0.24290 | 0.230225 |
2.1.2 模型搭建与训练
模型框架为
训练阶段 预测站点窗口滑动,
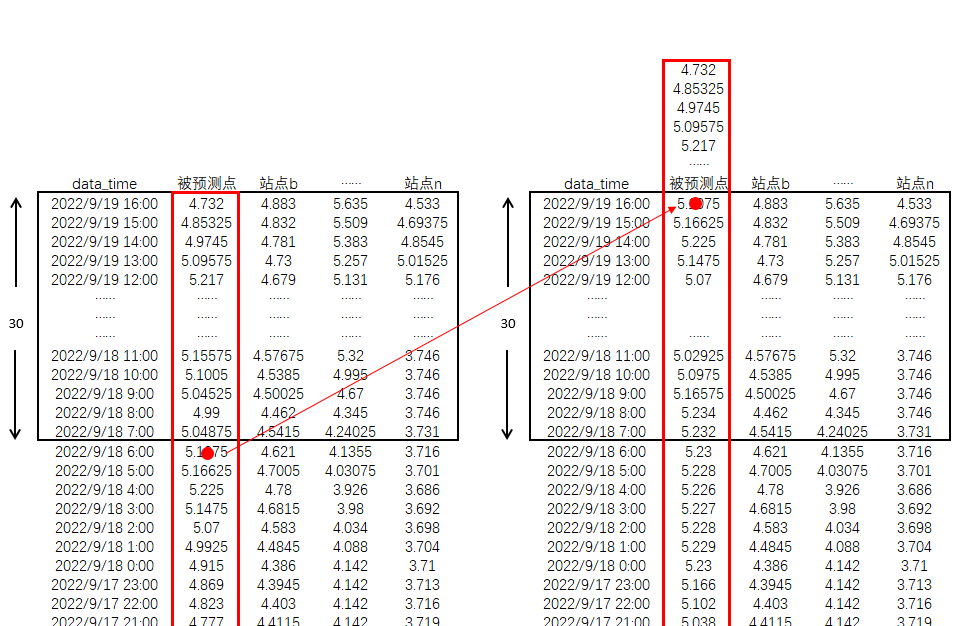
从结构示例图看,若样本窗口数量为30,样本列数(含预测站点)为n,则框中红点数据为预测数据,其余数据为训练因变量,通过模型建立非线性关系。
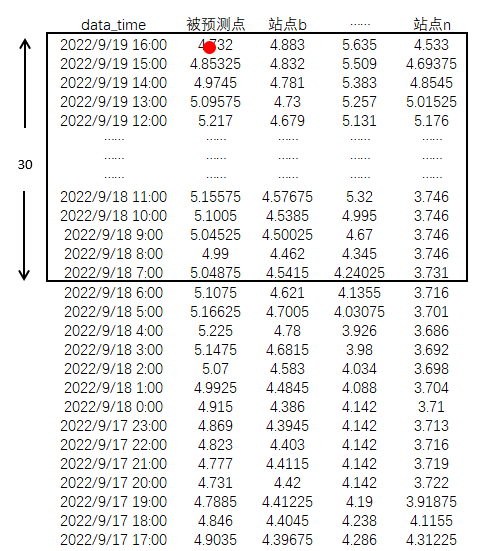
为了实现预测效果,采用滑动时间滑动技术,生成训练基础数据。
本次模型搭建采用tensorflower框架,面向对象编程。
# 导入相关包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
plt.rcParams["font.sans-serif"] = ["Simhei"] # 解决坐标轴刻度负号乱码
plt.rcParams["axes.unicode_minus"] = False
from datetime import date, datetime, timedelta
from sklearn.model_selection import GridSearchCV
# 训练模型,使用 girdsearchCV 进行参数调整以找到基础模型。
定义本体,主要参数包括,预测数据集,预测时长,预测窗口数,预测步长
预测时间和预测窗口数最好一致,
预测数据集可为多参数,第一列为预测参数,
预测步长可以理解为逐小时,还是逐4小时,默认逐小时。
class LSTMTimePredictor:
def __init__(self, df, shift_n=30, test_ratio=0.2, n_past=30,p_step=1 ,optimizer="adam"):
"""
df:DataFrame时间序列数据;
test_ratio:测试比率
n_past:预测的窗口数;
optimizer:优化器;
n_features:特征数;
feature_names:特征名称;
shirt_n:预测时长
"""
self.df = df
self.test_ratio = test_ratio
self.n_past = n_past
self.shift_n = shift_n
self.optimizer = optimizer
self.n_features = self.df.shape[1]
self.feature_names = self.df.columns
self.p_step = p_step
时间滑动生成新的数据集。
def shift_date_new(self):
"""
时间滑动
下一段滑动函数 n 为移动参数,即为预测长度
df4都有的数据集用于训练和测试
df9向后预测的数据需要的未知数据集;
"""
df1 = self.df
n = self.shift_n
bl_fh = df1.iloc[:, 1: self.n_features]
cb = df1.iloc[:, 0]
cb.to_frame
df2 = cb.shift(periods=-n, axis=0)
df3 = pd.concat([df2, bl_fh], join="outer", axis=1)
df9 = df3[-n:]
df4 = df3[:-n]
return df4, df9
数据集划分,归一化
def _train_test_split(self):
"""
训练测试划分;
"""
df = self.shift_date_new()[0]
test_split = round(len(self.df) * self.test_ratio) # 计算测试集中的样本数量
df_training = df[:-test_split]
df_testing = df[-test_split:]
# 进行最小最大归一化
scaler = MinMaxScaler(feature_range=(0, 1))
df_training_scaled = scaler.fit_transform(df_training)
df_testing_scaled = scaler.transform(df_testing)
# 获取训练集和测试集的样本数量
self.train_length = len(df_training_scaled)
self.test_length = len(df_testing_scaled)
# 获取归一化后的训练样本和测试样本
self.scaler = scaler
return df_training_scaled, df_testing_scaled
区分自变量,因变量
def createXY(self, datasets):
"""
生成用于LSTM输入的多元数据,例如时间窗口n_past=30,则一个样本的维度为(30,5)
30代表时间窗口,5代表特征数量
将数据分为x y
n_past 我们在预测下一个目标值时将在过去查看的步骤数 粒度
n_past使用30,意味着将使用过去的30个值
dataX 代表目标预测值dataY前所有因子,包括预测因子30个数据
若n_past越小,则预测的平滑度越低,越注重于短期预测,若n_past越大则越注重长期预测
"""
dataX = []
dataY = []
for i in range(self.n_past, len(datasets)):
dataX.append(datasets[i - self.n_past : i, 0 : datasets.shape[1]])
dataY.append(datasets[i, 0])
return np.array(dataX), np.array(dataY)
建立模型,并查找最优参数
def grid_search(
self,
):
"""
根据数据训练模型,并查找最优的参数
"""
df_training_scaled = self._train_test_split()[0]
df_testing_scaled = self._train_test_split()[1]
X_train, y_train = self.createXY(df_training_scaled)
X_test, y_test = self.createXY(df_testing_scaled)
grid_model = KerasRegressor(
build_fn=self._build_model, verbose=1, validation_data=(X_test, y_test)
)
parameters = {
"batch_size": [16, 20],
"epochs": [8, 10],
# , "Adadelta" "optimizer": ["adam"],
}
# 这里前文设置了optimizer为adam
grid_search = GridSearchCV(estimator=grid_model, param_grid=parameters, cv=2)
grid_search = grid_search.fit(
X_train, y_train, validation_data=(X_test, y_test)
)
self.model = grid_search.best_estimator_.model
至此模型建立。
2.1.3 模型评价与模型预测
本次采用4种方法评价模型精度,分别是MSE、MAE、R2、准确率。
测试集模型预测精度评价及绘图代码如下:
def evaluate(self, plot=True):
"""
制图及模型评价
"""
df_testing_scaled = self._train_test_split()[1]
X_test, y_test = self.createXY(df_testing_scaled)
# 预测值
prediction = self.model.predict(X_test)
prediction_copy_array = np.repeat(prediction, self.n_features, axis=-1)
pred = self.scaler.inverse_transform(
np.reshape(prediction_copy_array, (len(prediction), self.n_features))
)[:, 0]
# 实际值
original_copies_array = np.repeat(y_test, self.n_features, axis=-1)
original = self.scaler.inverse_transform(
np.reshape(original_copies_array, (len(y_test), self.n_features))
)[:, 0]
# 序号还原
df = self.shift_date_new()[0]
test_split = round(len(self.df) * self.test_ratio) # 计算测试集中的样本数量
df_training = df[:-test_split]
df_testing = df[-test_split:]
index1 = df_testing.index
starttime = index1[30]
delta = timedelta(hours=30) # 时间序号还原
starttime = starttime + delta
starttime = starttime.strftime("%Y-%m-%d %H:%M:%S")
endtime = index1[-1]
endtime = endtime + delta
endtime = endtime.strftime("%Y-%m-%d %H:%M:%S")
time_nu = pd.date_range(starttime, endtime, freq="h").strftime(
"%Y-%m-%d %H:%M:%S"
)
time_nu = time_nu[::self.p_step]
original_2 = pd.DataFrame(original)
col_2 = ["真实值"]
original_2.columns = col_2
original_3 = original_2.set_index(time_nu)
pred_2 = pd.DataFrame(pred)
col_1 = ["预测值"]
pred_2.columns = col_1
pred_3 = pred_2.set_index(time_nu)
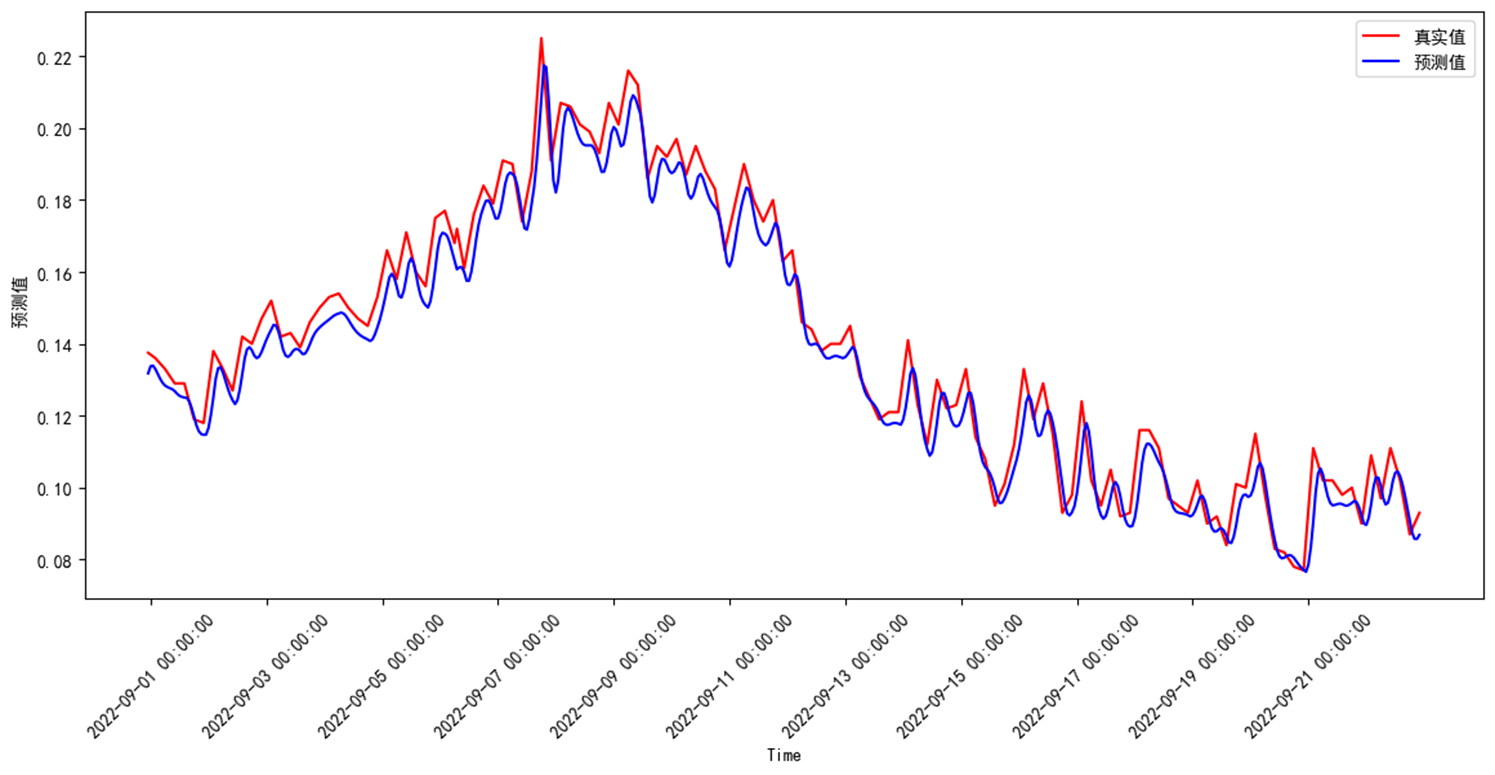
if plot:
plt.figure(figsize=(14, 6))
plt.plot(original_3, color="red", label="真实值")
plt.plot(pred_3, color="blue", label="预测值")
# plt.title(" 站点A氨氮预测")
plt.xlabel("Time")
plt.ylabel(" 预测值")
plt.locator_params(axis="x", nbins=10)
plt.xticks(range(1, len(time_nu), 48), rotation=45) # 刻度线显示优化
plt.legend()
plt.show()
mae = mean_absolute_error(original, pred)
mse = mean_squared_error(original, pred)
mape = np.mean(np.abs(original - pred) / original)
r2 = r2_score(original, pred)
acc = 1 - abs((pred - original) / original)
acc = np.mean(acc)
print(
"MSE : {},MAE : {}, MAPE : {}, r2 : {}, 准确率:{}".format(
mse, mae, mape, r2, acc
)
)
return pred
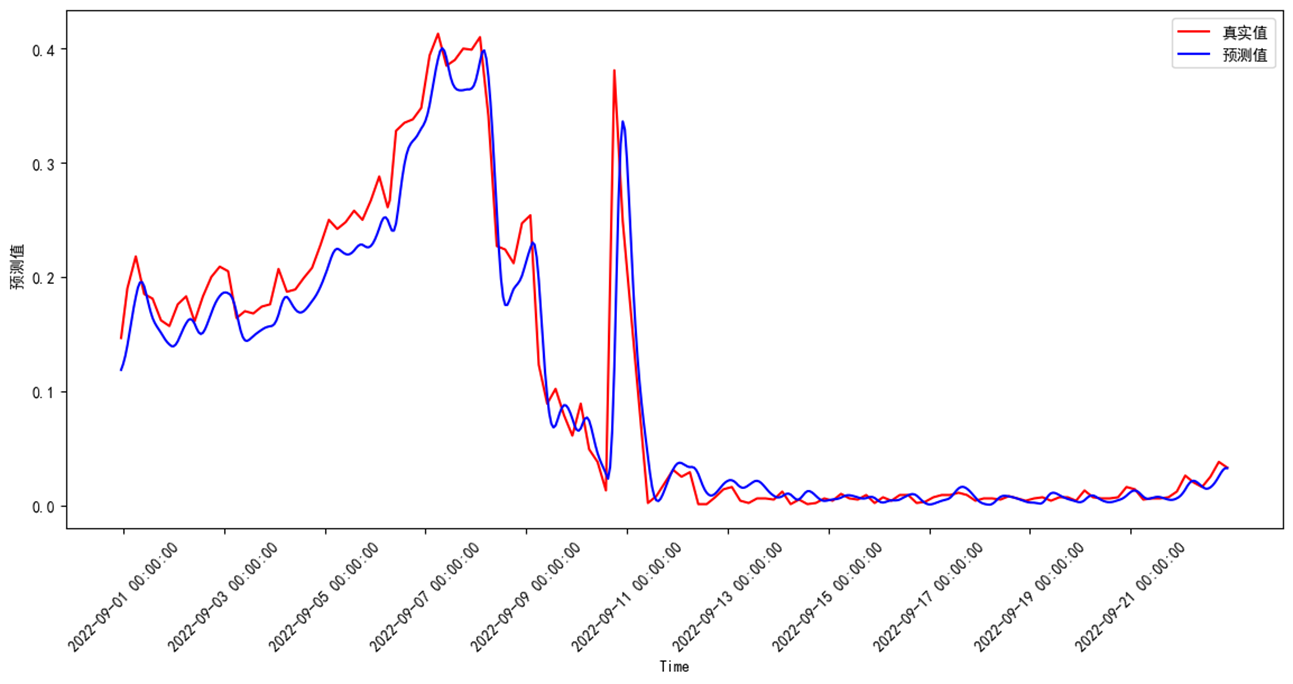
数据集采用临江河站点A、站点B、站点C、站点D等4个站点,预测站点A高指、氨氮、总磷3个因子。数据范围为2022/5/19 5:00:00 至 2022/9/21 4:00:00。共3000个数据。测试集占比0.2。
测试集预测评价结果如下:MSE、MAE、R2均表现较好,总磷准确率、MAPE较差,与水质浓度波动大,关系密切,可以通过进一步优化数据清理减少数据波动。
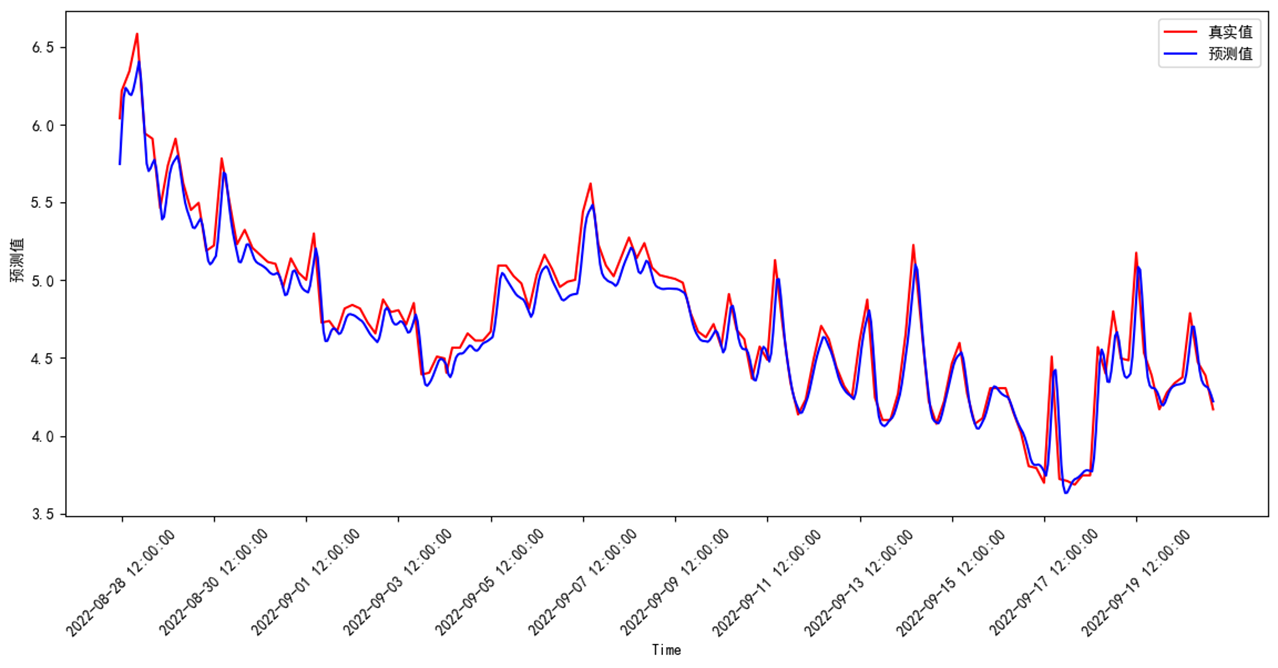
| 因子 | MSE | MAE | MAPE | r2 | 准确率 |
|---|---|---|---|---|---|
| 高指 | 0.00004273 | 0.00521874 | 0.037992 | 0.968379 | 0.962008 |
| 氨氮 | 0.01103716 | 0.07946250 | 0.016475 | 0.959818 | 0.983525 |
| 总磷 | 0.00081064 | 0.01672249 | 0.698055 | 0.947509 | 0.301945 |
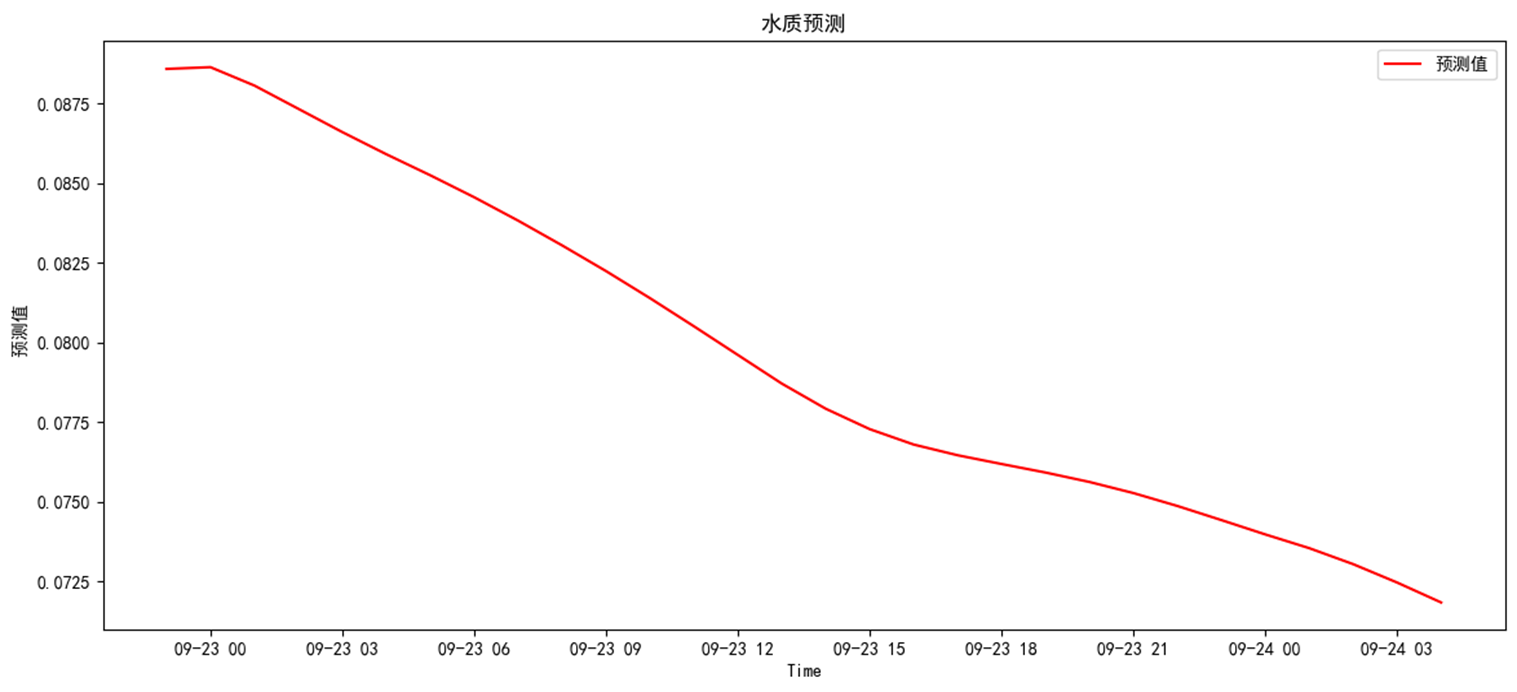
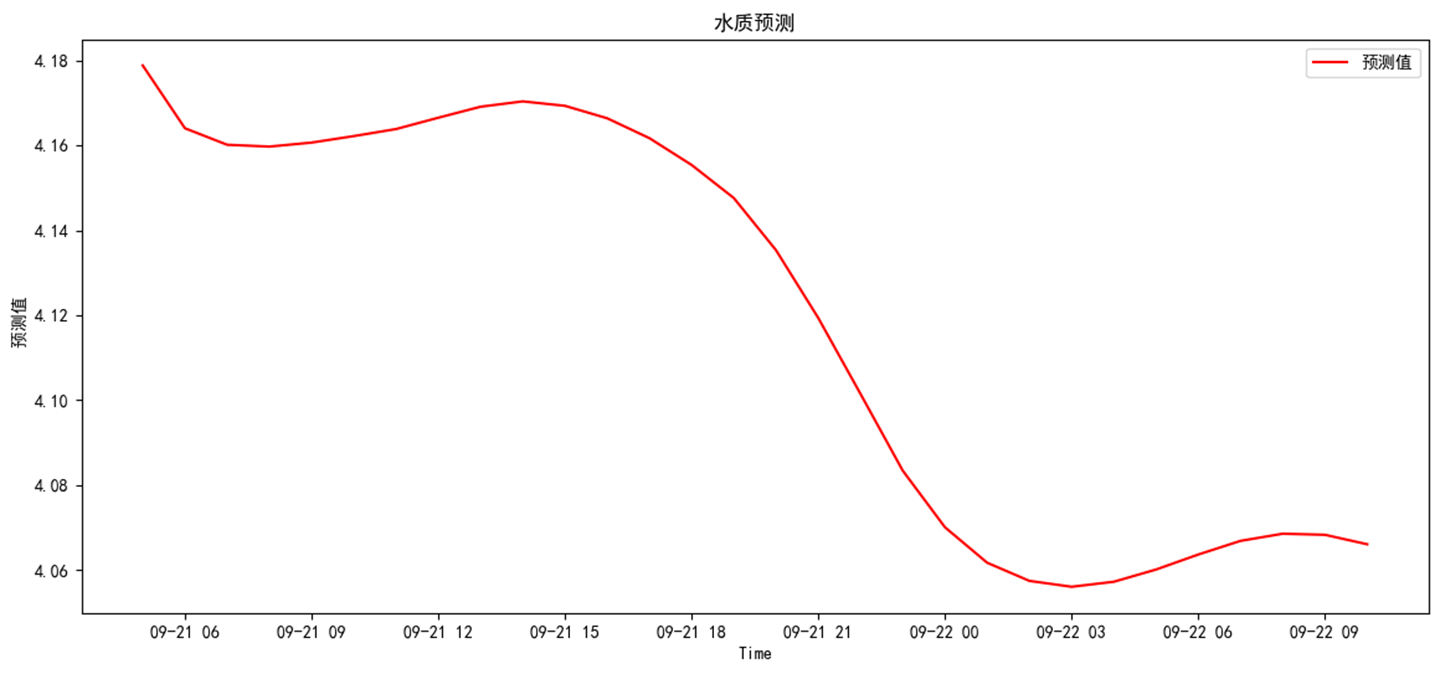
对未来的预测
模型可以自定义模型预测时长,本次以72小时为例。运行预测评价模块
lstm2 = LSTMTimePredictor(dm2,test_ratio=0.2,n_past=72,p_step=1 )
lstm2.grid_search()
lstm2.evaluate()
lstm2.fig_predict()
def fig_predict(self):
"""
查看数据概览图;
"""
df = self.predict()
plt.figure(figsize=(14, 6))
plt.plot(df, color="red", label="预测值")
plt.xlabel("Time")
plt.ylabel(" 预测值")
plt.title("水质预测")
plt.locator_params(axis="x", nbins=10)
# plt.xticks(range(1,len(time_nu),48),rotation=45) # 刻度线显示优化
plt.legend()
plt.show()
预测结果分别为,整体呈下降趋势
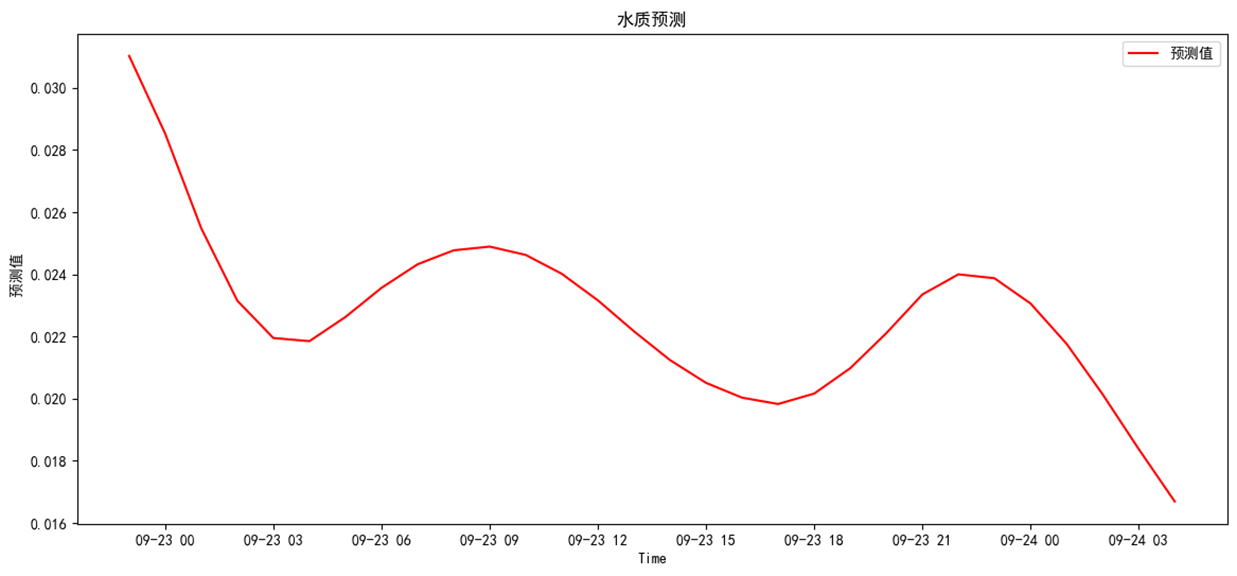
3 应用场景及展望
LSTM作为成熟的神经网络模型,可以实现多因子,连续时间序列预测,可以应用在有一定连续水质检测数据的平台上,预测结果较准确。因子关联可根据实际情况选择,例如上下游关系,机理关系等。
shuju ,与RNN一样,LSTM隐藏层具有随时间序列的重复节点。LSTM节点相较RNN更
为复杂,它将RNN中隐含层中的神经元替换为记忆体,以此实现序列信息的保留与长期记忆。TM是RNN的一种变体,与RNN一样,LSTM隐藏层具有随时间序列的重复节点。LSTM节点相较RNN更为复杂,它将RNN中隐含层中的神经元替换为记忆体,以此实现序列信息的保留与长期记忆。
短的的多连续适用于时记忆网络(LSTM)应用
BY
如有帮助,请收藏点赞,如需引用转载请注明出处。
微信公众号:环境猫 er
CSDN:细节处有神明
个人博客:wallflowers (maoyu92.github.io)
![[Leetcode 136][Easy]-只出现一次的数字](https://img-blog.csdnimg.cn/direct/9683f9b9cb97453e9b4a0ba9a726db96.png)