主题建模评估:连贯性分数(Coherence Score)
1.主题连贯性分数
主题连贯性分数(Coherence Score)是一种客观的衡量标准,它基于语言学的分布假设:具有相似含义的词往往出现在相似的上下文中。 如果所有或大部分单词都密切相关,则主题被认为是连贯的。
推荐阅读:Full-Text or Abstract ? Examining Topic Coherence Scores Using Latent Dirichlet Allocation
2.计算 LDA 模型的 Coherence Score
2.1 导入包
import pandas as pd
import numpy as np
from gensim.corpora import Dictionary
from gensim.models import LdaMulticore
2.2 数据预处理
# cast tweets to numpy array
docs = df.tweet_text.to_numpy()
# create dictionary of all words in all documents
dictionary = Dictionary(docs)
# filter extreme cases out of dictionary
dictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=100000)
# create BOW dictionary
bow_corpus = [dictionary.doc2bow(doc) for doc in docs]
2.3 构建模型
LdaMulticore:使用所有 CPU 内核并行化并加速模型训练。
workers:用于并行化的工作进程数。passes:训练期间通过语料库的次数。
# create LDA model using preferred hyperparameters
lda_model = LdaMulticore(bow_corpus, num_topics=5, id2word=dictionary, passes=4, workers=2, random_state=21)
# Save LDA model to disk
path_to_model = ""
lda_model.save(path_to_model)
# for each topic, print words occuring in that topic
for idx, topic in lda_model.print_topics(-1):
print('Topic: {} \nWords: {}'.format(idx, topic))
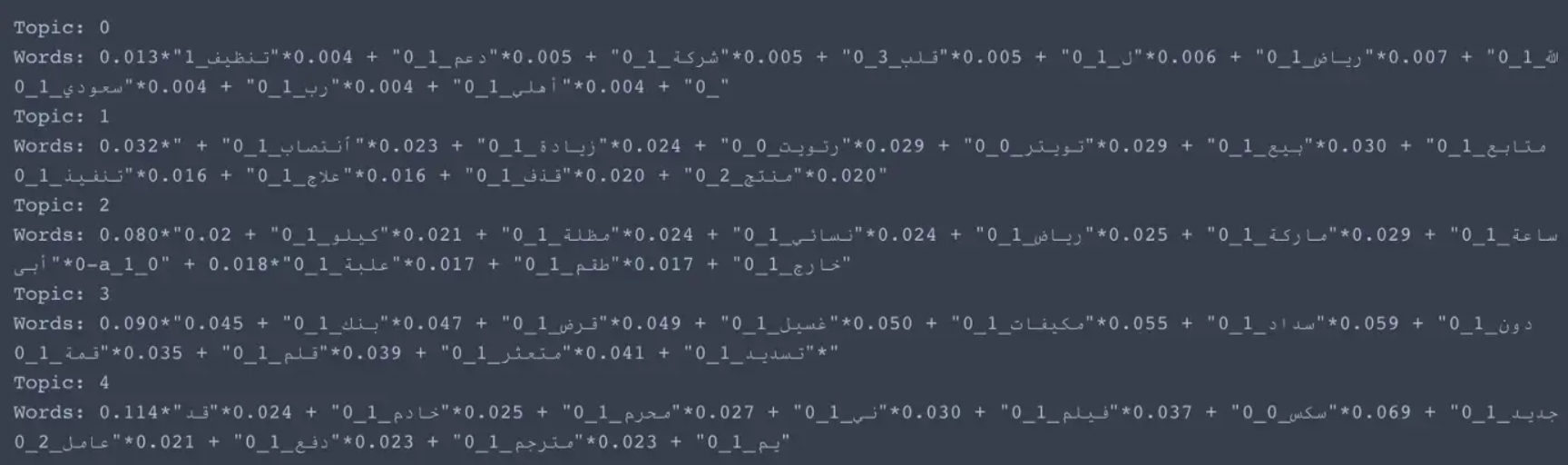
2.4 计算 Coherence Score
我们可以使用 Gensim 库中的 CoherenceModel 轻松计算主题连贯性分数。 对于 LDA,它的实现比较简单:
# import library from gensim
from gensim.models import CoherenceModel
# instantiate topic coherence model
cm = CoherenceModel(model=lda_model, corpus=bow_corpus, texts=docs, coherence='c_v')
# get topic coherence score
coherence_lda = cm.get_coherence()
print(coherence_lda)
3.计算 GSDMM 模型的 Coherence Score
GSDMM(Gibbs Sampling Dirichlet Multinomial Mixture)是一种基于狄利克雷多项式混合模型的收缩型吉布斯采样算法(a collapsed Gibbs Sampling algorithm for the Dirichlet Multinomial Mixture model)的简称,它是发表在 2014 2014 2014 年 KDD 上的论文《A Dirichlet Multinomial Mixture Model-based Approach for Short Text Clustering》的数学模型。
GSDMM 主要用于短文本聚类,短文本聚类是将大量的短文本(例如微博、评论等)根据计算某种相似度进行聚集,最终划分到几个类中的过程。GSDMM 主要具备以下优点:
- 可以自动推断聚类的个数,并且可以快速地收敛;
- 可以在完备性和一致性之间保持平衡;
- 可以很好的处理稀疏、高纬度的短文本,可以得到每一类的代表词汇;
- 较其它的聚类算法,在性能上表现更为突出。
3.1 安装并导入包
pip install git+https://github.com/rwalk/gsdmm.git
import pandas as pd
import numpy as np
from gensim.corpora import Dictionary
from gsdmm import MovieGroupProcess
3.2 数据预处理
# cast tweets to numpy array
docs = df.tweet_text.to_numpy()
# create dictionary of all words in all documents
dictionary = Dictionary(docs)
# filter extreme cases out of dictionary
dictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=100000)
# create variable containing length of dictionary/vocab
vocab_length = len(dictionary)
# create BOW dictionary
bow_corpus = [dictionary.doc2bow(doc) for doc in docs]
3.3 构建模型
# initialize GSDMM
gsdmm = MovieGroupProcess(K=15, alpha=0.1, beta=0.3, n_iters=15)
# fit GSDMM model
y = gsdmm.fit(docs, vocab_length)
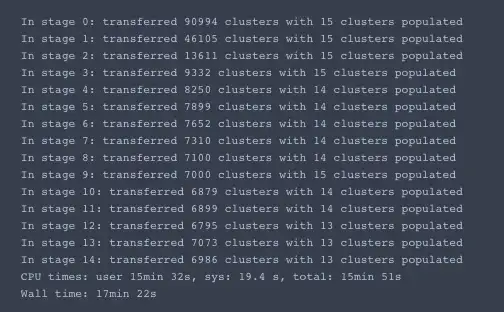
# print number of documents per topic
doc_count = np.array(gsdmm.cluster_doc_count)
print('Number of documents per topic :', doc_count)
# Topics sorted by the number of document they are allocated to
top_index = doc_count.argsort()[-15:][::-1]
print('Most important clusters (by number of docs inside):', top_index)
# define function to get top words per topic
def top_words(cluster_word_distribution, top_cluster, values):
for cluster in top_cluster:
sort_dicts = sorted(cluster_word_distribution[cluster].items(), key=lambda k: k[1], reverse=True)[:values]
print("\nCluster %s : %s"%(cluster, sort_dicts))
# get top words in topics
top_words(gsdmm.cluster_word_distribution, top_index, 20)
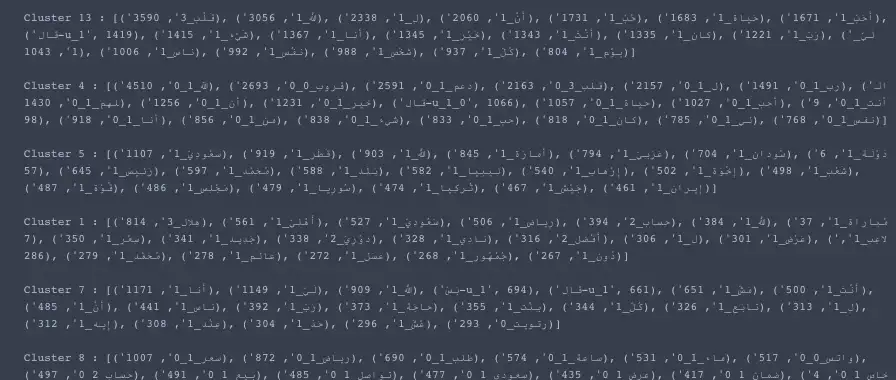
3.4 结果可视化
# Import wordcloud library
from wordcloud import WordCloud
# Get topic word distributions from gsdmm model
cluster_word_distribution = gsdmm.cluster_word_distribution
# Select topic you want to output as dictionary (using topic_number)
topic_dict = sorted(cluster_word_distribution[topic_number].items(), key=lambda k: k[1], reverse=True)[:values]
# Generate a word cloud image
wordcloud = WordCloud(background_color='#fcf2ed',
width=1800,
height=700,
font_path=path_to_font,
colormap='flag').generate_from_frequencies(topic_dict)
# Print to screen
fig, ax = plt.subplots(figsize=[20,10])
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off");
# Save to disk
wordcloud_24.to_file(path_to_file)

3.5 计算 Coherence Score
Gensim 官网对 LDA 之外的模型使用另一种方法计算 连贯性分数。
from gensim.test.utils import common_corpus, common_dictionary
from gensim.models.coherencemodel import CoherenceModel
topics = [
['human', 'computer', 'system', 'interface'],
['graph', 'minors', 'trees', 'eps']
]
cm = CoherenceModel(topics=topics, corpus=common_corpus, dictionary=common_dictionary, coherence='u_mass')
coherence = cm.get_coherence() # get coherence value
GSDMM 的实现需要更多的工作,因为我们首先必须将 主题中的单词作为列表(变量主题)获取,然后将其输入 CoherenceModel。
# import library from gensim
from gensim.models import CoherenceModel
# define function to get words in topics
def get_topics_lists(model, top_clusters, n_words):
'''
Gets lists of words in topics as a list of lists.
model: gsdmm instance
top_clusters: numpy array containing indices of top_clusters
n_words: top n number of words to include
'''
# create empty list to contain topics
topics = []
# iterate over top n clusters
for cluster in top_clusters:
# create sorted dictionary of word distributions
sorted_dict = sorted(model.cluster_word_distribution[cluster].items(), key=lambda k: k[1], reverse=True)[:n_words]
# create empty list to contain words
topic = []
# iterate over top n words in topic
for k,v in sorted_dict:
# append words to topic list
topic.append(k)
# append topics to topics list
topics.append(topic)
return topics
# get topics to feed to coherence model
topics = get_topics_lists(gsdmm, top_index, 20)
# evaluate model using Topic Coherence score
cm_gsdmm = CoherenceModel(topics=topics, dictionary=dictionary, corpus=bow_corpus, texts=docs, coherence='c_v')
# get coherence value
coherence_gsdmm = cm_gsdmm.get_coherence()
print(coherence_gsdmm)
原文:Short-Text Topic Modelling: LDA vs GSDMM