有了之前的经验(【神经网络】python实现神经网络(二)——正向推理的模拟演练),我们继续来介绍如何正向训练神经网络中的超参(包含权重以及偏置),本章大致的流程图如下:

一.损失函数
神经网络以某个指标为基准寻求最优权重参数,而这个指标即可称之为 “损失函数” 。(例如:在使用神经网络进行识别手写数字时,在学习阶段找出最佳参数中,最常用的方法是通过梯度下降法找出最优参数,使得通过损失函数计算的值降到最低),在之前写过的一篇文章:【机器学习】几个简单的损失函数 已经大致介绍了几种常用的损失函数,不再赘述,本章将使用交叉熵误差作为本次的损失函数。
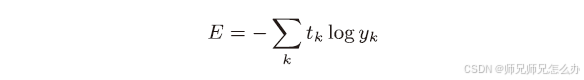
与之前不同的是,前面介绍的损失函数的例子中考虑的都是针对单个数据的损失函数。如果要求计算所有训练数据的损失函数的总和,那么公式应该更新成这样:
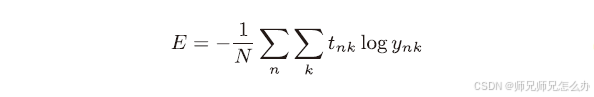
这里, 假设数据有N个,tnk 表示第n个数据的第k 个元素的值(ynk 是神经网络的输出,tnk 是监督数据),通过除以N,可以求单个数据的“平均损失函数”。通过这样的平均化,可以获得和训练数据的数量无关的统一指标。这里其实和普通的交叉熵误差没有什么太大区别&#x






![[Redis]Redis学习开篇概述](https://i-blog.csdnimg.cn/direct/6e4a2e62989c48af80449bb86c15b99d.png)