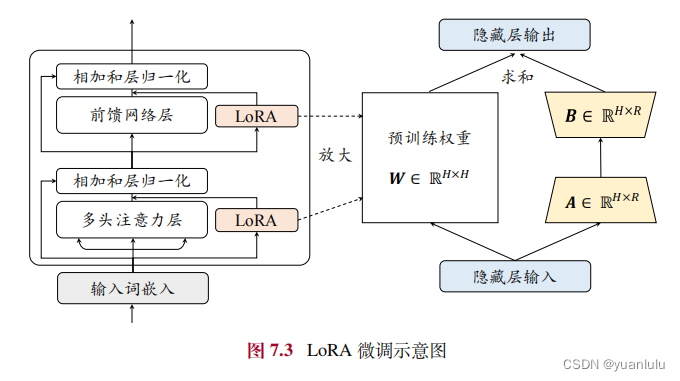
什么是lora微调
LoRA 提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。
环境准备
这次使用到的微调框架是llama-factory。这个框架集成了对多种模型进行各种训练的代码,少量修改就可使用。
我是在昇腾上使用docker安装的,装 Ascend CANN Toolkit and Kernels已经提前装好了,如果没有的话需要另外安装
然后安装llama-factory:
git clone https://gitee.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e '.[torch-npu,metrics]'
要是缺什么再pi install 来安装。
准备数据
LLaMA Factory工程目录的data目录下有已经有各种实例数据集了,仿照格式自己做一个就行。比如alpaca格式如下(必须有"instruction"、"output"2个字段)
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
比如:
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"
},
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""
},
{
"instruction": "比较以下两位著名人物,使用特征列表并以句子形式提供输出。",
"input": "人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响",
"output": "阿尔伯特·爱因斯坦和斯蒂芬·霍金都是拥有极其出色智力的人物。两人都取得过非常高的教育成就,他们推进了科学发展并在世界范围内产生了深远的影响。爱因斯坦以其相对论和质能关系公式而闻名,而霍金以其关于黑洞和宇宙的发现而著称。两位科学家都以其深厚的学识和非凡的贡献影响了世界。"
},
{
"instruction": "请根据以下文章构建一个需要回答的问题。",
"input": "",
"output": "我不好意思,您没有提供任何信息或文章来供我根据它构建问题。 请提供相应的文章或信息,以便我能够帮助您构建问题。"
}
]
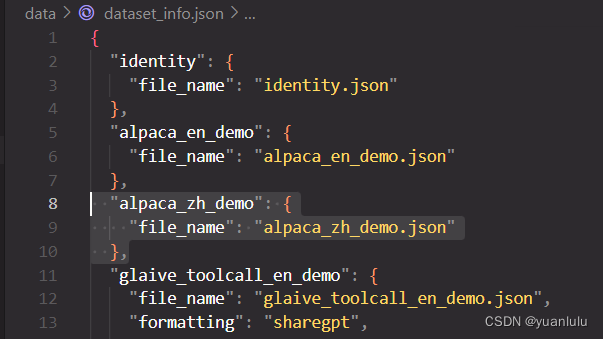
将训练数据集文件放到llama-factory工程下的data目录下,然后修改data/dataset_info.json文件,增加数据集的入口和目录,如果我们在data下放了一个alpaca_zh_demo.json文件,则要增加的内容如下:
修改训练任务的配置文件
在examples\lora_multi_npu\目录下新建一个配置文件(可以从已有的文件拷贝过去修改)。比如 我新建的文件叫baichuan2_lora_sft_ds.yaml,内容如下:
### model
model_name_or_path: /home/xxxx/Baichuan2-13B-Chat/
#/home/mindformer_share/baichuan-inc/Baichuan2-13B-Chat/
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### ddp
ddp_timeout: 180000000
deepspeed: examples/deepspeed/ds_z0_config.json
### dataset
dataset: summary_data_lora
template: baichuan2
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/Baichuan2-13B-lora-checkpoint
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 5.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
需要修改的几个字段如下:
- 模型目录:model_name_or_path
- 输出目录:output_dir
- 训练轮数:num_train_epochs
- 使用的数据集名称(也就是在dataset_info.json增加的数据集入口):dataset
- 模型架构(constants.py文件中有所有支持的模型架构名称):template
其它参数可以看自己需要来修改。
执行训练命令
上面已经准备了数据集,也新增了训练的配置文件,下面就可以执行训练命令:
ASCEND_RT_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/lora_multi_npu/baichuan2_lora_sft_ds.yaml
用到几张显卡,在ASCEND_RT_VISIBLE_DEVICES后面指定就好了。
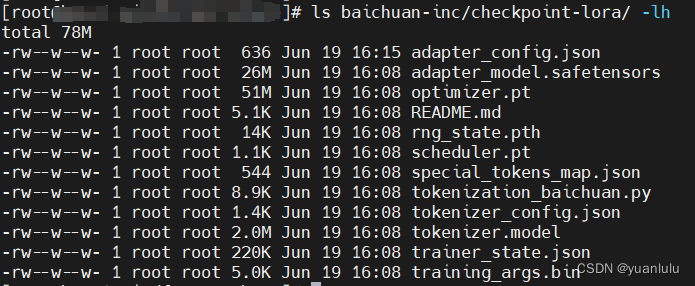
训练执行完毕,在baichuan2_lora_sft_ds.yaml的out配置的目录下回生成训练好的lora模型:
如何使用lora训练的模型
参考我前面一篇博客《在昇腾开发环境合并baichuan2-13B模型的lora文件》
参考资料
什么是指令微调(LLM)
LLaMA-Factory