💓博主CSDN主页:麻辣韭菜💓
⏩专栏分类:Linux初窥门径⏪
🚚代码仓库:Linux代码练习🚚
🌹关注我🫵带你学习更多Linux知识
🔝

目录
🏳️🌈前言
🏳️⚧️正文
1.线程池概念
1.1 池化技术
1.2 线程池优点
1.3 线程池应用场景
2.线程池的实现
第一步:创建ThreadPool类
第二步:构造、析构、创建线程
第三步:实现push、pop、HandlerTask函数
第四步:main.cc实现调用逻辑
3.单例模式
3.1 单例模式的特点
3.2 懒汉、饿汉实现单例模式
3.3 单例模式的应用场景
4.其他周边问题
4.1 STL中的容器是否是线程安全的?
4.2 智能指针是否是线程安全的?
4.3 其他常见的各种锁
4.4读者、写着问题
使用互斥锁的简单解决方案:
允许多个读者但只有一个写者的解决方案:
带优先级的解决方案:
使用条件变量的解决方案:
避免饥饿的解决方案:
🏳️🌈前言
线程池是一种多线程处理形式,它允许多个线程共享一个线程池中的固定数量的线程。线程池可以提高应用程序的响应速度和线程管理的效率,因为线程的创建和销毁需要消耗资源和时间。使用线程池可以减少这些开销。
线程池的使用场景非常广泛,包括但不限于Web服务器、数据库连接池、并发数据处理等。正确地使用线程池可以显著提升应用程序的性能和稳定性。
🏳️⚧️正文
1.线程池概念
1.1 池化技术
池化技术(Pooling)是一种资源管理策略,用于提高资源使用效率和性能。它通过预先分配一组资源,使得资源可以被多个客户端或任务共享和重复使用,从而减少创建和销毁资源的开销。
线程池利用的就是池化技术的思想,当然不仅仅只有线程池还有很多的池也利用了池化技术
例如:数据库连接池、内存池、对象池、HTTP连接池、文件描述符池、缓存池、套接字池等。
当然还有其他的,这里我就不一一例举了。
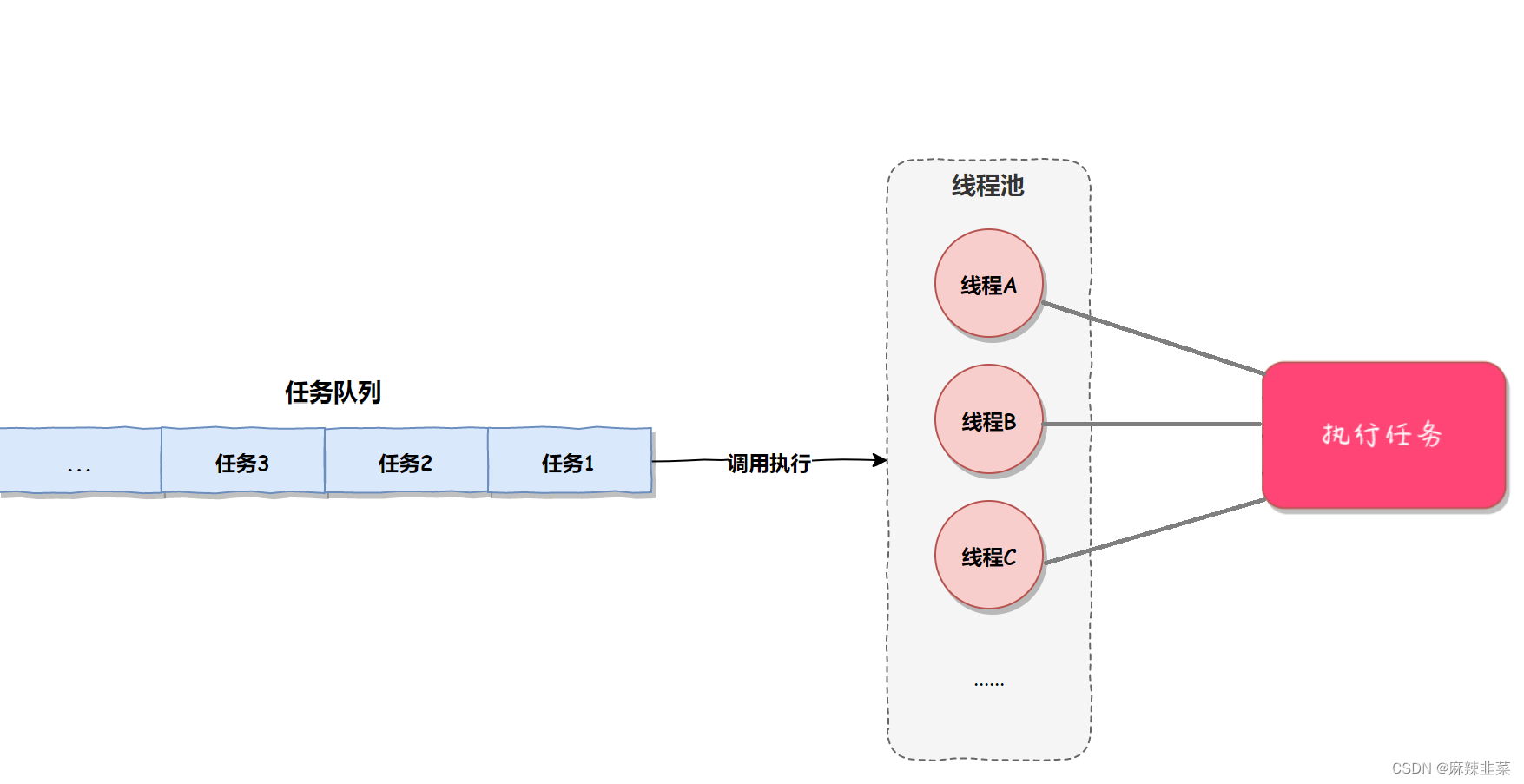 上图像什么?不就是生产者消费模型吗?不理解什么是生产消费者模型请先看Linux 生产消费者模型
上图像什么?不就是生产者消费模型吗?不理解什么是生产消费者模型请先看Linux 生产消费者模型
1.2 线程池优点
-
提高资源利用率:线程池通过预先创建一定数量的线程,避免了频繁创建和销毁线程的开销,从而提高了线程资源的利用率。
-
降低开销:线程的创建和销毁都需要消耗系统资源和时间。线程池通过复用已有的线程,减少了这些开销。
-
提高响应速度:线程池中的线程处于就绪状态,可以快速响应任务请求,减少了等待线程创建的时间。
-
避免资源耗尽:通过限制线程池中的最大线程数,可以防止因创建过多线程而导致的系统资源耗尽。
-
提高线程管理效率:线程池提供了统一的线程管理机制,使得线程的调度和生命周期管理更加高效和有序。
-
减少上下文切换:线程池中的线程可以长时间运行,减少了线程上下文切换的频率,从而提高了系统的整体性能。
-
可扩展性:线程池可以根据系统的需求和资源情况进行扩展,适应不同的工作负载。
-
灵活性和可配置性:线程池允许开发者根据应用程序的需要进行配置,例如设置核心线程数、最大线程数、任务队列容量等。
-
易于监控和调试:线程池提供了统一的接口和机制,使得监控和调试线程相关的问题变得更加容易。
-
支持任务优先级:一些线程池实现支持任务优先级,允许开发者根据任务的重要性分配不同的执行优先级。
-
简化编程模型:使用线程池可以简化并发编程模型,开发者只需要关注任务的提交,而不需要关心线程的创建和管理。
-
支持批量任务处理:线程池可以高效地处理大量任务,特别是当任务可以并行执行时,可以显著提高处理速度。
-
减少锁竞争:通过合理设计线程池,可以减少线程之间的锁竞争,提高并发性能。
-
支持复杂的并发模式:线程池可以支持多种并发模式,如工作窃取、任务调度等,以适应不同的应用场景
总之,线程池是一种有效的资源管理策略,可以提高多线程程序的性能、可伸缩性和可维护性。然而,合理地设计和使用线程池也是非常重要的,以避免潜在的问题,如死锁、资源竞争等。
1.3 线程池应用场景
-
Web服务器:处理来自用户的HTTP请求,线程池可以快速响应并发请求,提高服务器的吞吐量。
-
数据库连接池:管理数据库连接,线程池可以复用连接,减少连接创建和销毁的开销。
-
批处理系统:执行大量独立的任务,如数据导入、导出、报告生成等,线程池可以并行处理这些任务,提高效率。
-
消息队列处理:处理消息队列中的消息,线程池可以并发地消费消息,提高消息处理速度。
-
网络通信:在客户端或服务器端进行网络通信时,线程池可以管理多个网络连接和数据传输任务。
线程池应用场景不止这些,线程池的应用场景非常广泛,关键在于根据具体需求合理配置线程池的大小和特性,以达到最佳的性能和资源利用率。
下面我们就手搓线程池。
2.线程池的实现
我们要创建线程池,那是一批线程,所以我们需要一个容器来存放线程,这里我们选择vector
既然是线程,同步和互斥那也是要安排的上。
到这里线程池这个类的类成员还需要什么?
生产出来的任务,需要一个容器来存放这些任务。这里选择queue先进先出,总不能倒反天罡?
老规矩我们先创建ThreadPool.hpp这个头文件,然后创建ThreadPool这个类
我们先创建一个线程信息的类方便我们等哈做实验时候,打印出来更直观。
class ThreadData
{
public:
pthread_t tid; //线程ID
std::string threadname; //线程名字
};第一步:创建ThreadPool类
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <string>
#include <unistd.h>
#include <pthread.h>
template<class T>
class ThreadPool
{
private:
std::vector<ThreadData> _threads; //线程池
std::queue<T> _tasks; //任务队列
pthread_mutex_t _mutex; //互斥
pthread_cond_t _cond; //同步
};第二步:构造、析构、创建线程
const static int defaultnum = 5; // 默认5个线程
template <class T>
class ThreadPool
{
public:
ThreadPool(int num = default)
: _threads(num)
{
pthread_mutex_init(&_mutex, nullptrnum);
pthread_cond_init(&_cond, nullptr);
}
void *HandlerTask(void *args)
{
while (true)
{ sleep(1);
std::cout << "新线程正在等待任务..." << std::endl;
}
}
void start() // 创建线程
{
int num = _threads.size();
for (int i = 0; i < num; i++)
{
_threads[i].threadname = "thread-" + std::to_string(i + 1);
pthread_create(&(_threads[i].tid), nullptr, HandlerTask, nullptr);
}
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
private:
std::vector<ThreadData> _threads; // 线程池
std::queue<T> _tasks; // 任务队列
pthread_mutex_t _mutex; // 互斥
pthread_cond_t _cond; // 同步
};我们在上层调用链调用,试试我们的框架能不能跑起来。
编写mian.cc调用逻辑
#include "ThreadPool.hpp"
int main()
{
ThreadPool<int> *tp = new ThreadPool<int>(5);
tp->start();
while (true)
{
sleep(1);
std::cout << "主线线程正在运行..." << std::endl;
}
return 0;
}
编译出错了,原因是因为我们的HandlerTask函数是在ThreadPool类中实现的,就是类内函数,而内类函数自带this指针。而pthread_create函数要求的是void* 所以类型不匹配。所以我们需要在HandlerTask 函数前面加static,变成静态成员函数。
static void* HandlerTask(void* args)
框架没有问题,下面实现push和pop
第三步:实现push、pop、HandlerTask函数
push和pop、HandlerTask涉及对临界资源读写,需要对线程同步和互斥,为了方便我们先对锁和条件变量的操作进行封装。
public:
// 加锁
void Lock()
{
pthread_mutex_lock(&_mutex);
}
// 解锁
void UnLock()
{
pthread_mutex_unlock(&_mutex);
}
// 条件满足唤醒线程
void WakeUp()
{
pthread_cond_signal(&_cond);
}
// 条件不满足线程休眠
void ThreadSleep()
{
pthread_cond_wait(&_cond);
}
// 判断任务队列空满
bool IsQueueEmpty()
{
return _tasks.empty();
}
实现push
void push(const T &in)
{
Lock();
_tasks.push(in);
WakeUp();
UnLock();
}这里再push数据完成之后,我们需要唤醒其他线程。来进行任务处理。所以push后面跟着wakeup
实现 HandlerTask
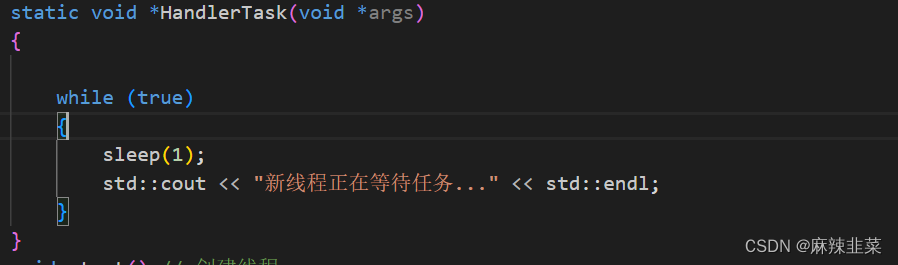 由于回调函数是静态函数,所以我们调不动类内的非静态的函数以及非静态成员。所以我们要想调用这些函数,只有通过实例调用也是指针或者引用。这里我们直接在pthread_create这里回调参数传this指针
由于回调函数是静态函数,所以我们调不动类内的非静态的函数以及非静态成员。所以我们要想调用这些函数,只有通过实例调用也是指针或者引用。这里我们直接在pthread_create这里回调参数传this指针
pthread_create(&(_threads[i].tid), nullptr, HandlerTask, this);static void *HandlerTask(void *args)
{
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args);
while (true)
{
tp->Lock();
while (IsQueueEmpty())
{
tp->ThreadSleep();
}
T t = tp->pop();
tp->UnLock();
t();
std::cout << "新线程正在处理任务..." << endl;
}
}注意:这里用while判断防止伪唤醒。当队列不为空时,线程拿到任务属于线程自己的,所以不用在锁里处理任务,从而提高并发度。
实现pop
T pop()
{
T out = _tasks.front();
_tasks.pop();
return out;
}pop调用逻辑是在回调函数中的,而回调函数是有加锁的,所以pop这里就不用加锁了。
第四步:main.cc实现调用逻辑
实现之前我们直接把Task.hpp这个头文件包含进来。
 这里我们直接用把上篇的Task.hpp拷贝过来。
这里我们直接用把上篇的Task.hpp拷贝过来。
头文件Task.hpp
#pragma once
#include <iostream>
#include <string>
std::string opers = "+-*/%";
enum
{
DivZero = 1,
ModZero,
Unknown
};
class Task
{
public:
Task(){};
Task(int data1, int data2, char oper)
: _data1(data1), _data2(data2), _oper(oper), _result(0), _exitcode(0)
{
}
void run()
{
switch (_oper)
{
case '+':
_result = _data1 + _data2;
break;
case '-':
_result = _data1 - _data2;
break;
case '*':
_result = _data1 * _data2;
break;
case '/':
{
if (_data2 == 0)
_exitcode = DivZero;
else
_result = _data1 / _data2;
}
break;
case '%':
{
if (_data2 == 0)
_exitcode = ModZero;
else
_result = _data1 % _data2;
}
break;
default:
_exitcode = Unknown;
break;
}
}
std::string GetResult()
{
std::string r = std::to_string(_data1);
r += _oper;
r += std::to_string(_data2);
r += "=";
r += std::to_string(_result);
r += "[code: ";
r += std::to_string(_exitcode);
r += "]";
return r;
}
std::string GetTask()
{
std::string r = std::to_string(_data1);
r += _oper;
r += std::to_string(_data2);
r += "=?";
return r;
}
void operator()()
{
run();
}
~Task()
{
}
private:
int _data1;
int _data2;
char _oper;
int _result;
int _exitcode;
};实现调用线程池
#include "ThreadPool.hpp"
#include "Task.hpp"
#include <ctime>
#include <mutex>
std:: mutex mtx;
int main()
{
srand(time(nullptr) ^ getpid());
ThreadPool<Task> *tp = new ThreadPool<Task>(5);
tp->start();
while (true)
{
int x = rand() % 10 + 1;
int y = rand() % 10;
char oper = opers[rand() % opers.size()];
Task t(x, y, oper);
tp->push(t);
std::cout << "主线程发布任务..." << t.GetTask() << std::endl;
sleep(1);
}
return 0;
} 这里不知道是那个线程在处理任务。我们重新改造
这里不知道是那个线程在处理任务。我们重新改造
在头文件ThreadPool增加这段函数
std:: string GetThreadName(pthread_t tid)
{
for(const auto& ti:_threads)
{
if(ti.tid == tid)
{
return ti.threadname;
}
}
return "None";
} static void *HandlerTask(void *args)
{
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args);
std:: string name = tp->GetThreadName(pthread_self());
while (true)
{
tp->Lock();
while (tp->IsQueueEmpty())
{
tp->ThreadSleep();
}
T t = tp->pop();
tp->UnLock();
t();
std::cout << name << "正在处理任务..." <<"运行结果是:" << t.GetResult()<< std::endl;
}
}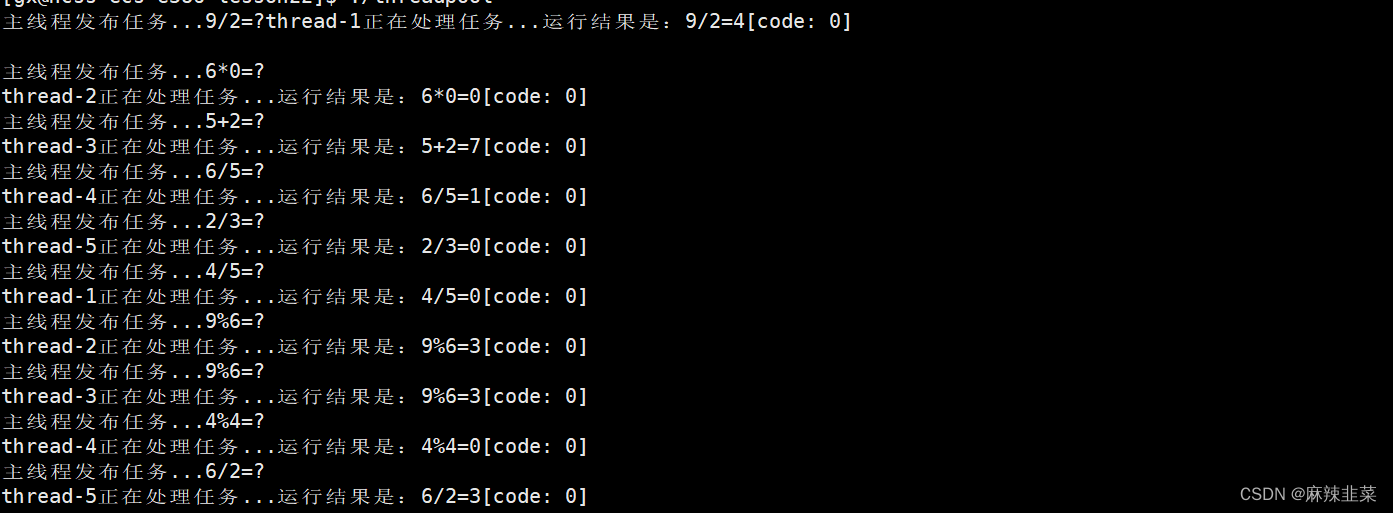
这样就优美很多了,更直观了 ,这里打印错乱很正常,cout本质就是访问临界资源显示器,这里我们不用管。
3.单例模式
那什么又是设计模式?
3.1 单例模式的特点
-
唯一性:单例模式确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。
-
全局访问点:通过一个静态方法(例如
getInstance)来获取类的唯一实例,这个静态方法通常被称为“全局访问点”。 -
延迟实例化:单例模式通常在第一次使用时才创建实例(懒汉式),这有助于节省资源,特别是在实例化成本较高时
3.2 懒汉、饿汉实现单例模式
如何创建一个单例模式?只要外部无法访问类的构造函数,也就是将构造函数私有化,同时删除拷贝构造。
class Singleton {
// 私有化构造函数和拷贝赋值操作符
private:
Singleton() {}
Singleton(const Singleton&) = delete;
};外部无法访问,那我们只有类内创建对象。
class Singleton {
public:
Singleton* getSingleton()
{
if (_stl = nullptr)
{
_stl = new Singleton;
}
return _stl;
}
// 私有化构造函数和拷贝赋值操作符
private:
Singleton() {}
Singleton(const Singleton&) = delete;
private:
Singleton* _stl = nullptr;
};这样创建有问题吗?
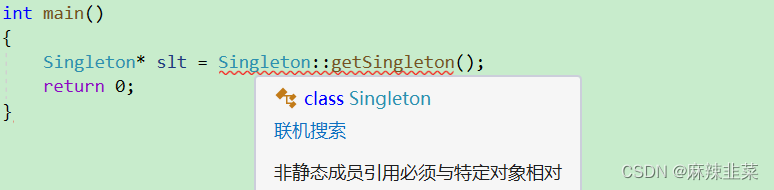
由于我们是非静态成员,这就导致了 访问限制;
非静态成员调用时,是需要实例化的,也就是说,我们调用getSingleton这个非静态成员函数,是需要用对象来调。我们要创建一个对象。这就违反了单例模式的原则。
所以我们需要静态的成员和静态的成员函数。
class Singleton {
public:
static Singleton* getSingleton()
{
if (_stl = nullptr)
{
_stl = new Singleton;
}
return _stl;
}
// 私有化构造函数和拷贝赋值操作符
private:
Singleton() {}
Singleton(const Singleton&) = delete;
private:
static Singleton* _stl; //在内类声明
};
// 在类外定义静态成员变量
Singleton* Singleton::_stl = nullptr;
// 定义静态成员变量
int main()
{
Singleton* slt = Singleton::getSingleton();
return 0;
}上面这种方式就是懒汉式的单例模式,
懒汉式:
- 按需实例化:单例对象在第一次被使用时才创建,因此称为“懒汉式”。
- 线程不安全:由于实例化发生在运行时,如果多个线程同时访问单例对象,可能会创建多个实例,需要额外的同步机制来保证线程安全。
- 节省资源:只有在真正需要使用单例对象时才会创建,节省了资源。
下面我们用饿汉式来创建单例模式
class Singleton {
private:
static Singleton instance;
public:
static Singleton& getInstance() {
return instance;
}
// 私有化构造函数和拷贝赋值操作符
private:
Singleton() {}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
// 定义静态成员变量
Singleton Singleton::instance;饿汉式:
- 类加载时实例化:当类被加载时,单例对象就被创建了,因此称为“饿汉式”。
- 线程安全:由于实例化发生在类加载阶段,这个阶段是线程安全的,因此饿汉式单例是线程安全的。
- 资源消耗:由于实例化时机早,即使后续没有使用到单例对象,它也会被创建,这可能导致资源的浪费。
3.3 单例模式的应用场景
前面我们手的搓的线程池就是单例模式的应用场景,我们调用start函数,至始至终都只实例化了一份对象。
加之线程池的生命周期是要跨越整个进程的生命周期,恰好单例模式的生命周期也是一样。
线程池是要全局的,一个应用程序要随时随地都能调用到线程池,单例模式就是全局的。
居于这样,把之前的线程池变成懒汉模式
先将构造函数私有化、同时禁掉拷贝构造和赋值重载
private:
ThreadPool(int num = defaultnum)
: _threads(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
ThreadPool(const ThreadPool<T> &) = delete;
const ThreadPool<T> &operator=(const ThreadPool<T> &) = delete;声明静态成员指针
static ThreadPool<T> *_tp; // 单例模式类外初始化
template <class T>
ThreadPool<T> *ThreadPool<T>::_tp = nullptr;实现GetInstance()函数
static ThreadPool<T> *GetInstance()
{
if (_tp == nullptr)
{
_tp = new ThreadPool<T>;
}
return _tp;
}这样写有没有没有问题?当然有问题啊,多个线程同时访问判断_tp是不是空。这不乱套了?要加锁!!!
由于都是静态的,是全局的,所以我们的锁也要是全局的。
类成员添加下面这段代码
static pthread_mutex_t _lock; //保证_tp线程安全类外初始化
template <class T>
pthread_mutex_t ThreadPool<T>::_lock = PTHREAD_MUTEX_INITIALIZER;下面我们加锁
static ThreadPool<T> *GetInstance()
{
pthread_mutex_lock(&_lock);
if (_tp == nullptr)
{
_tp = new ThreadPool<T>;
}
pthread_mutex_unlock(&_lock);
return _tp;
}加锁之后还有没有问题?我们是单例模式,也就是说这里只会对_tp进行一次实例化。
后面其他线程其实压根不用加锁解锁操作。加锁解锁操作多了极大降低效率。所以我们需要进行二次判断
static ThreadPool<T> *GetInstance()
{
if (_tp == nullptr)
{
pthread_mutex_lock(&_lock);
if (_tp == nullptr)
{
_tp = new ThreadPool<T>;
}
pthread_mutex_unlock(&_lock);
}
return _tp;
}二次判断后,如果是已经实例化,那么后面的线程再调用就是直接返回_tp。
那我们之前在main.cc调用逻辑也要变了之前是非静态的。现在是静态的
int main()
{
srand(time(nullptr) ^ getpid());
ThreadPool<Task>::GetInstance()->start(); //之前是tp
while (true)
{
int x = rand() % 10 + 1;
int y = rand() % 10;
char oper = opers[rand() % opers.size()];
Task t(x, y, oper);
ThreadPool<Task>::GetInstance()->push(t);
std::cout << "主线程发布任务..." << t.GetTask() << std::endl;
sleep(1);
}
return 0;
} 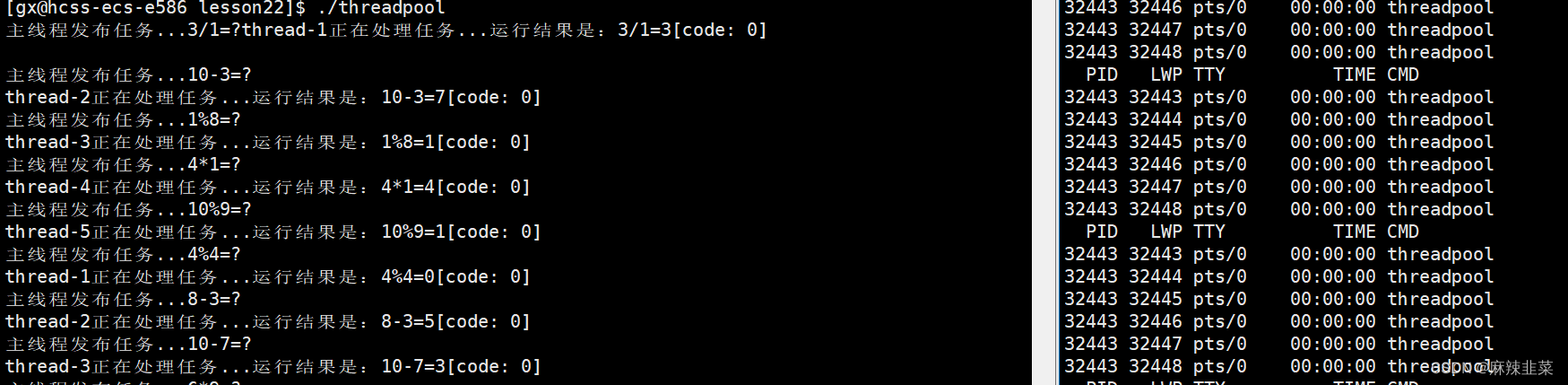
运行没有问题 这里要是有强迫症的铁子,可以在打印加锁。



4.其他周边问题
4.1 STL中的容器是否是线程安全的?
原因是, STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响.而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶).因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全
4.2 智能指针是否是线程安全的?
对于 unique_ptr, 由于只是在当前代码块范围内生效 , 因此不涉及线程安全问题 .对于 shared_ptr, 多个对象需要共用一个引用计数变量 , 所以会存在线程安全问题 . 但是标准库实现的时候考虑到了这个问题, 基于原子操作 (CAS) 的方式保证 shared_ptr 能够高效 , 原子的操作引用计数 .对于 weak_ptr , 是针对share_ptr 循环引用问题而诞生的,它持有一个对象的弱引用,不增加对象的引用计数它不支持原子操作。详情请看 C++ 智能指针_c++智能指针
4.3 其他常见的各种锁
我们从线程控制到线程池用的都是悲观锁
初始化自旋锁:
函数原型:int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
说明:初始化一个自旋锁。pshared 参数定义了自旋锁的作用域,可以是 PTHREAD_PROCESS_PRIVATE(仅在创建它的进程中有效)或 PTHREAD_PROCESS_SHARED(可以在多个进程间共享)。
锁定自旋锁:
函数原型:int pthread_spin_lock(pthread_spinlock_t *lock);
说明:尝试获取(锁定)指定的自旋锁。如果自旋锁当前未被其他线程持有,则调用线程立即获得该自旋锁;如果已被持有,则调用线程将不断循环检查直到自旋锁被释放。
尝试锁定自旋锁(非阻塞):
函数原型:int pthread_spin_trylock(pthread_spinlock_t *lock);
说明:尝试获取自旋锁,如果自旋锁已被其他线程持有,则立即返回错误 EBUSY,而不是持续占用 CPU 资源进行自旋。
解锁自旋锁:
函数原型:int pthread_spin_unlock(pthread_spinlock_t *lock);
说明:释放指定的自旋锁,如果有其他线程正在自旋等待此锁,其中一个线程将获得该锁。
销毁自旋锁:
函数原型:int pthread_spin_destroy(pthread_spinlock_t *lock);
说明:销毁一个已经初始化的自旋锁,释放与锁相关的资源。销毁自旋锁后,不应再使用该锁,除非重新初始化。非公平锁的实现就是基于上面这些锁加条件变量
4.4读者、写着问题
是一个经典的计算机科学问题,涉及到多个线程对共享数据的访问控制。
有多个线程需要访问同一资源(比如文件或数据库),这些线程被分为两类:
- 读者(Readers):只读取数据,不修改数据。
- 写者(Writers):会修改数据。
问题的核心是如何设计同步机制,以满足以下要求:
- 互斥:当写者正在写入数据时,不允许其他写者或读者访问数据。
- 无饿死:保证所有线程最终都能访问到数据,避免某些线程无限期地等待。
- 读者优先或写者优先:根据具体场景,可以优先考虑读者或写者的访问。
读者-写者问题有几种不同的解决方案,包括:
使用互斥锁的简单解决方案:
- 当读者读取数据时,他们之间不需要互斥,但写者需要独占访问。
- 这种方法简单,但可能导致写者饥饿,如果读者持续不断地访问数据。
允许多个读者但只有一个写者的解决方案:
- 使用两个锁,一个用于读者之间的同步(Reader lock),另一个用于写者(Writer lock)。
- 读者在进入和离开读取状态时分别获取和释放Reader lock。
- 写者在写入前获取Writer lock,并在写入完成后释放。
带优先级的解决方案:
- 读者优先:如果有很多读者,可以设计机制让读者优先获取锁,但这可能导致写者饥饿。
- 写者优先:如果写入操作很重要,可以设计机制让写者优先获取锁,但这可能导致读者饥饿。
使用条件变量的解决方案:
- 条件变量可以用于实现更灵活的等待和通知机制。
- 读者可以使用条件变量来等待数据未被写者锁定的通知。
- 写者可以使用条件变量来等待没有读者正在读取或等待读取的通知。
避免饥饿的解决方案:
- 可以使用请求计数器来跟踪读者和写者的请求,确保每个类型的线程都有机会访问资源
下面使用一个互斥锁(mutex)和两个条件变量(cv_reader 和 cv_writer)来分别同步读者和写者。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
const int MAX_READERS = 5;
const int NUM_READERS = 3;
const int NUM_WRITERS = 2;
// 共享资源
int shared_data = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t no_readers = PTHREAD_COND_INITIALIZER;
pthread_cond_t no_writers = PTHREAD_COND_INITIALIZER;
// 线程参数结构体
struct ThreadParam {
int id;
};
// 读者线程函数
void* reader(void* arg) {
ThreadParam* param = static_cast<ThreadParam*>(arg);
int reader_id = param->id;
while (true) {
pthread_mutex_lock(&mutex);
while (shared_data < 0) {
pthread_cond_wait(&no_writers, &mutex);
}
pthread_mutex_unlock(&mutex);
std::cout << "Reader " << reader_id << " reads: " << shared_data << std::endl;
sleep(1); // 模拟读取时间
// 读者读取完毕,唤醒写者
pthread_mutex_lock(&mutex);
pthread_cond_signal(&no_writers);
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
// 写者线程函数
void* writer(void* arg) {
ThreadParam* param = static_cast<ThreadParam*>(arg);
int writer_id = param->id;
while (true) {
pthread_mutex_lock(&mutex);
while (shared_data >= 0) {
pthread_cond_wait(&no_readers, &mutex);
}
shared_data--; // 写者进入
pthread_mutex_unlock(&mutex);
std::cout << "Writer " << writer_id << " writes: " << -shared_data << std::endl;
sleep(2); // 模拟写入时间
pthread_mutex_lock(&mutex);
shared_data++; // 写者退出
pthread_cond_broadcast(&no_writers); // 唤醒所有读者
pthread_mutex_unlock(&mutex);
}
return nullptr;
}
int main() {
pthread_t readers[NUM_READERS], writers[NUM_WRITERS];
ThreadParam params_readers[NUM_READERS], params_writers[NUM_WRITERS];
// 创建读者线程
for (int i = 0; i < NUM_READERS; ++i) {
params_readers[i].id = i;
pthread_create(&readers[i], nullptr, reader, ¶ms_readers[i]);
}
// 创建写者线程
for (int i = 0; i < NUM_WRITERS; ++i) {
params_writers[i].id = i + NUM_READERS;
pthread_create(&writers[i], nullptr, writer, ¶ms_writers[i]);
}
// 等待线程结束
for (int i = 0; i < NUM_READERS + NUM_WRITERS; ++i) {
pthread_join(readers[i], nullptr);
}
return 0;
} 
这个示例中,我们创建了多个读者线程和一个写者线程。读者线程在读取数据时不需要互斥,但写者线程在写入数据时需要独占访问。我们使用互斥锁来保护共享资源,使用条件变量来同步读者和写者之间的访问。
线程章节到此结束,从初始线程,如何控制线程,后面我们认识到了线程并发访问临界资源是有线程安全的问题,从而我们又学习了锁、条件变量、信号量。通过这些我们手搓了生产消费者模型、线程池、最后认识了单例模式、还有读者写者问题。








![[PyTorch]:加速Pytorch 模型训练的几种方法(几行代码),最快提升八倍(附实验记录)](https://img-blog.csdnimg.cn/img_convert/145c4c5115995c7a98da0293ede96bc9.png)