论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

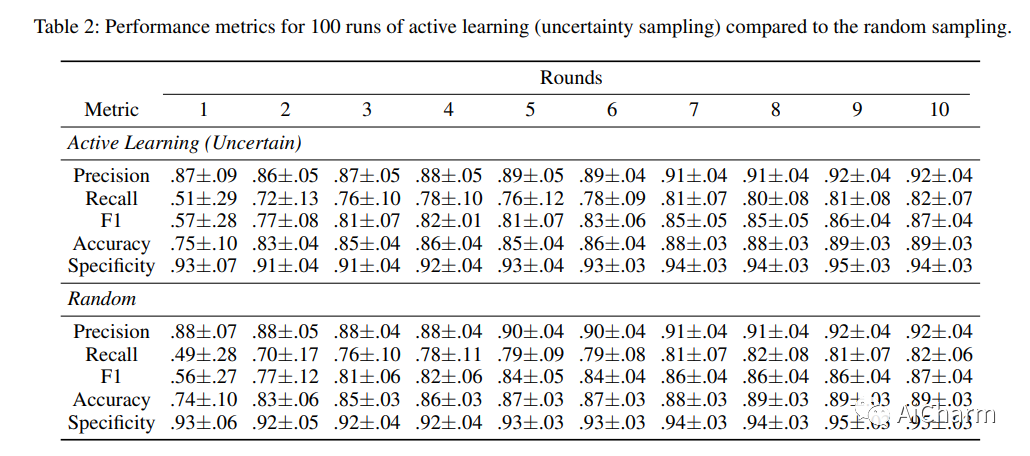
从 TPUv3-core-days 可以看到,ViT 所需的训练时间比 ResNet 更短,同时 ViT 取得了更高的准确率
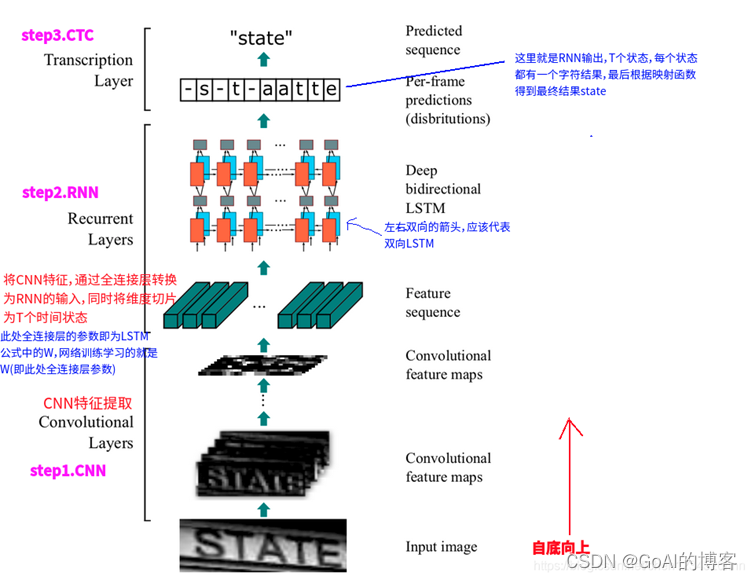
ViT 的基本思想是,把一张图片拆分成若干个 patch (16×16),每个 patch 当作 NLP 中的一个单词,若干个 patch 组成一个句子,用 Transformer 进行处理
ViT 的核心计算模块有:Multihead Attention (torch.nn.MultiheadAttention),Transformer Encoder (torch.nn.TransformerEncoder),Patch Embedding
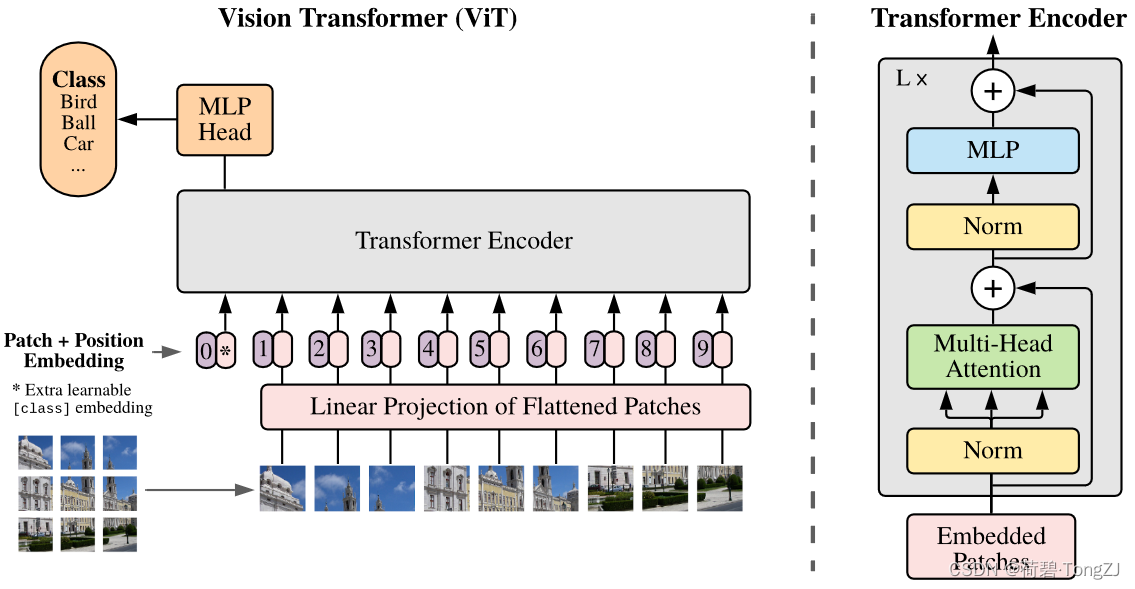
其中两个可以在 torch.nn 中找到,但是其源代码是由 Python 写的,而且非常冗长。比如: torch.nn.MultiheadAttention 的 forward 函数需要输入 query, key, value,并进行相互间的数值比较,但很多情况下这三者是相等的 (共用一个 tensor),这样的比较显然不必要;而且 torch.nn.TransformerEncoder 又调用了 torch.nn.MultiheadAttention,这也意味着要简化 torch.nn.MultiheadAttention 的话两者都必须重新编写
Multihead Attention
我阅读了 torch 官方的源代码,也参考了其它大佬的代码,整理出了如下的计算流程图。其中 L, B, C 分别表示 Sequence length、Batch size、Channel。N 表示注意力头的个数,并满足
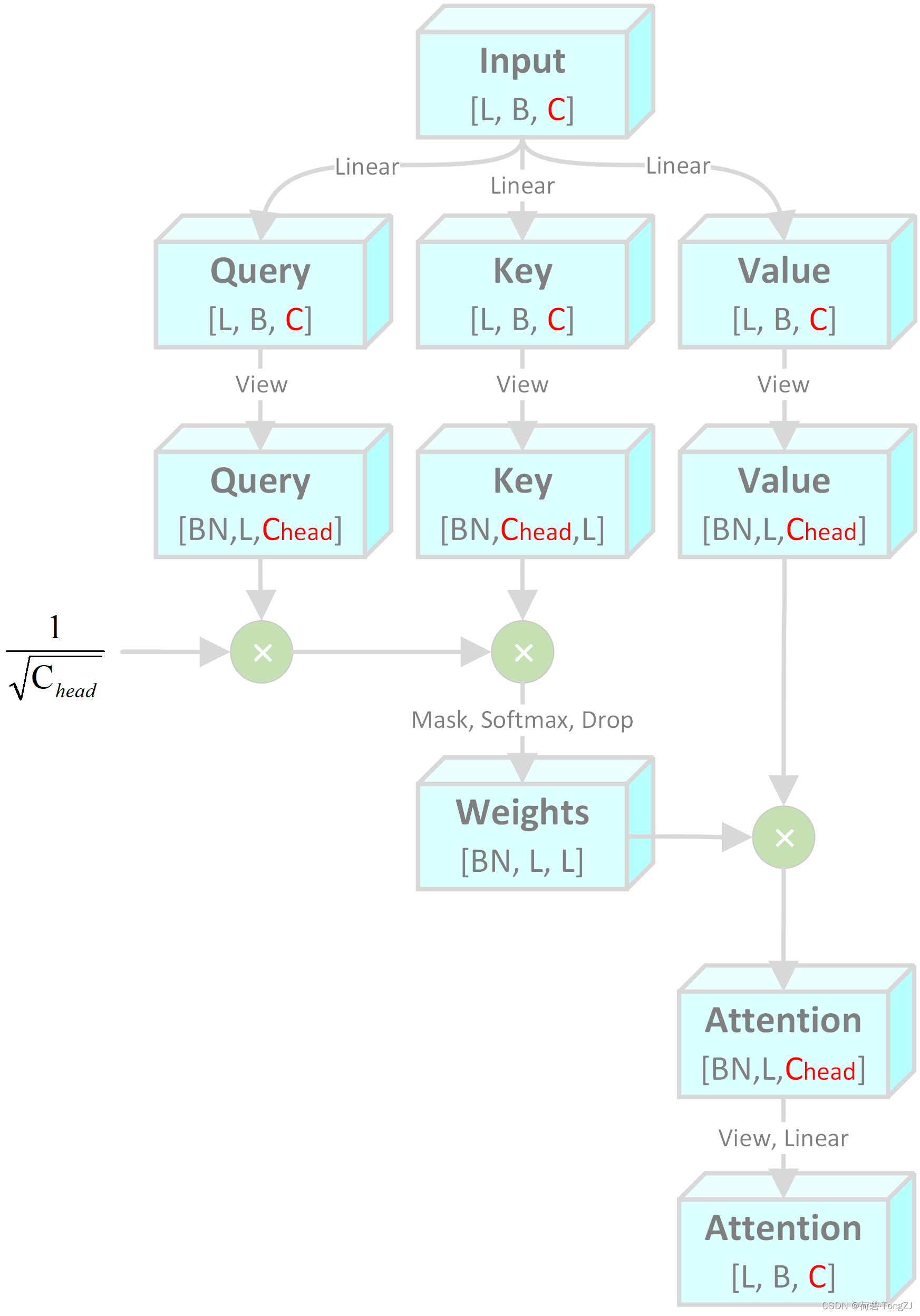
Multihead Attention 所涉及到的乘法计算有:
- Input 的线性变换 (Linear [C, 3C])
- Query 的逐元素乘法
- Query 和 Key 的矩阵乘法,可看作 Linear
- Weights 的 softmax 运算
- Weights 和 Value 的矩阵乘法,可看作 Linear
- Attention 的线性变换 (Linear [C, C])
其乘法次数可表示为 (含幂运算):
虽然 Multihead Attention 的输入通道数 = 输出通道数 (输入输出 shape 相同),但注意力头的个数 N 对乘法次数的影响还是相当大的 (源于 softmax 运算)
class MultiheadAttention(nn.Module):
''' n: 注意力头数'''
def __init__(self, c1, n, drop=0.1):
super().__init__()
self.c_head = c1 // n
assert n * self.c_head == c1, 'c1 must be divisible by n'
self.scale = self.c_head ** -0.5
self.qkv = nn.Linear(in_features=c1, out_features=3 * c1, bias=False)
self.dropout = nn.Dropout(p=drop)
self.proj = nn.Linear(in_features=c1, out_features=c1)
def forward(self, x):
L, B, C = x.shape
# view: [L, B, C] -> [L, BN, C_head]
q, k, v = map(lambda t: t.contiguous().view(L, -1, self.c_head), self.qkv(x).chunk(3, dim=-1))
q, k, v = q.transpose(0, 1), k.permute(1, 2, 0), v.transpose(0, 1)
# q[BN, L, C_head] × k[BN, C_head, L] = w[BN, L, L]
# N 对浮点运算量的影响主要在 softmax
weight = self.dropout((q * self.scale @ k).softmax(dim=-1))
# w[BN, L, L] × v[BN, L, C_head] = a[BN, L, C_head] -> a[L, B, C]
attention = (weight @ v).transpose(0, 1).contiguous().view(L, B, C)
return self.proj(attention)Transformer Encoder
在参考了 torch 官方的源代码后,我对 LayerNorm 的位置进行了调整,也就是在每次张量与残差相加时才进行层标准化
class TransformerEncoder(nn.Module):
''' n: 注意力头数
e: 全连接层通道膨胀比'''
def __init__(self, c1, n, e=1., drop=0.1):
super().__init__()
self.attn = nn.Sequential(
MultiheadAttention(c1, n, drop),
nn.Dropout(p=drop)
)
c_ = max([1, round(c1 * e)])
self.mlp = nn.Sequential(
nn.Linear(c1, c_),
nn.GELU(),
nn.Dropout(p=drop),
nn.Linear(c_, c1),
nn.Dropout(p=drop)
)
self.norm1 = nn.LayerNorm(c1)
self.norm2 = nn.LayerNorm(c1)
def forward(self, x):
# x[L, B, C]
x = self.norm1(x + self.attn(x))
return self.norm2(x + self.mlp(x))Vision Transformer
在论文中,作者用四个等式表述了 ViT 的计算过程 (先不考虑 Batch size),其中的符号意义为:
:一幅图像所包含的 patch 的数量
:可训练的 embedding,shape 为
:第 i 个 patch 的特征图
:每一个 patch 的边长
:二维卷积核 (in_channels=
, out_channels=
, k_size=
, stride=
变换为
:可训练的 embedding,表征每一个 patch 在图像中的位置
:第 i 个 Transformer Encoder 的输出,shape 为
;
的 shape 为
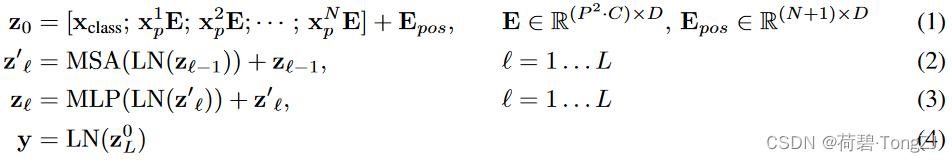
ViT 所完成的操作如下 (其中 为 Batch size):
- 用 torch.nn.Conv2d 把图像分割成若干个 patch,每个 patch 用一个向量表示 (可看作 NLP 中的单词),展平后得到 shape 为
的“句子”
- 拼接
,并与
- transpose 将 shape 变为
,输入若干个 Transformer Encoder 之后取
输出
class VisionTransformer(nn.Module):
''' n: 注意力头数
l: TransformerEncoder 堆叠数
e: TransformerEncoder 全连接层通道膨胀比'''
def __init__(self, c1, c2, n, l, img_size, patch_size, e=1., drop=0.1):
super().__init__()
# 校验 img_size 和 patch_size
self.img_size = (img_size,) * 2 if isinstance(img_size, int) else img_size
self.patch_size = (patch_size,) * 2 if isinstance(patch_size, int) else patch_size
assert sum([self.img_size[i] % self.patch_size[i] for i in range(2)]
) == 0, 'img_size must be divisible by patch_size'
n_patch = math.prod([self.img_size[i] // self.patch_size[i] for i in range(2)])
self.cls_embed = nn.Parameter(torch.empty(1, 1, c2))
self.pos_embed = nn.Parameter(torch.empty(n_patch + 1, c2))
self.patch_embed = nn.Conv2d(c1, c2, kernel_size=patch_size, stride=patch_size)
assert c2 % n == 0, 'c2 must be divisible by n'
self.encoders = nn.Sequential(*[TransformerEncoder(c2, n, e, drop) for _ in range(l)])
def forward(self, x):
B, C, H, W = x.shape
# view: [B, C, N_patch] -> [B, N_patch, C]
x = self.patch_embed(x).flatten(2).transpose(1, 2)
cls_embed = self.cls_embed.repeat(B, 1, 1)
x = torch.cat([cls_embed, x], dim=1) + self.pos_embed
# view: [B, N_patch + 1, C] -> [N_patch + 1, B, C]
return self.encoders(x.transpose(0, 1))[0]