CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
今天带来的arXiv上最新发表的3篇NLP论文。
Subjects: cs.CL、cs.AI、cs.DB、cs.LG
1.Editing Language Model-based Knowledge Graph Embeddings

标题:编辑基于语言模型的知识图谱嵌入
作者: Siyuan Cheng, Ningyu Zhang, Bozhong Tian, Zelin Dai, Feiyu Xiong, Wei Guo, Huajun Chen
文章L接:arxiv.org/abs/2301.10405v1
项目代码:github.com/zjunlp/promptkg
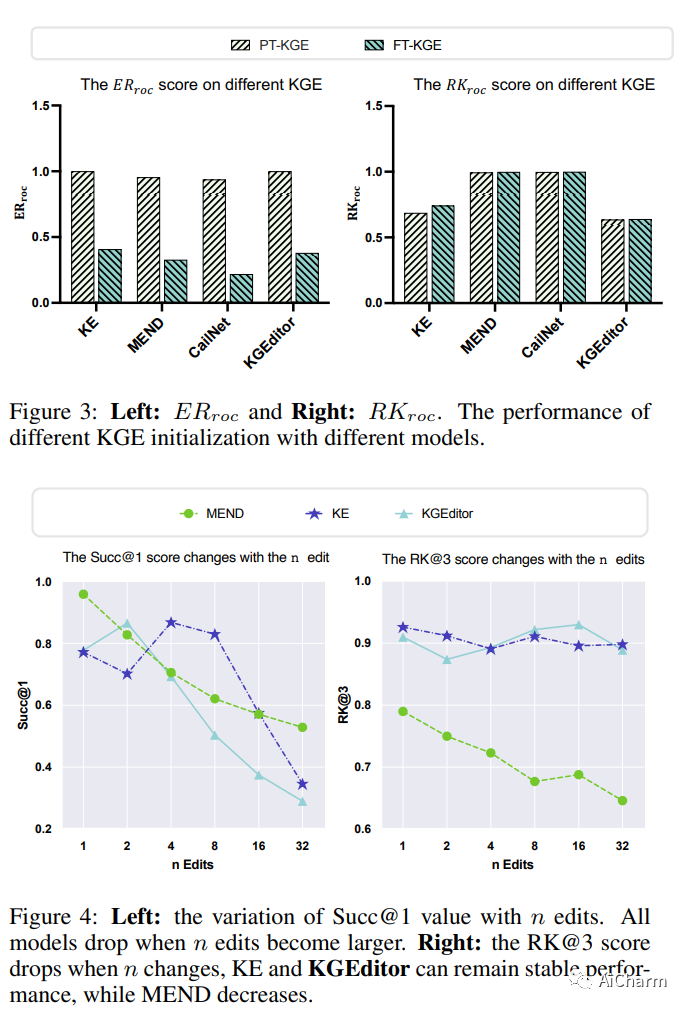

摘要:
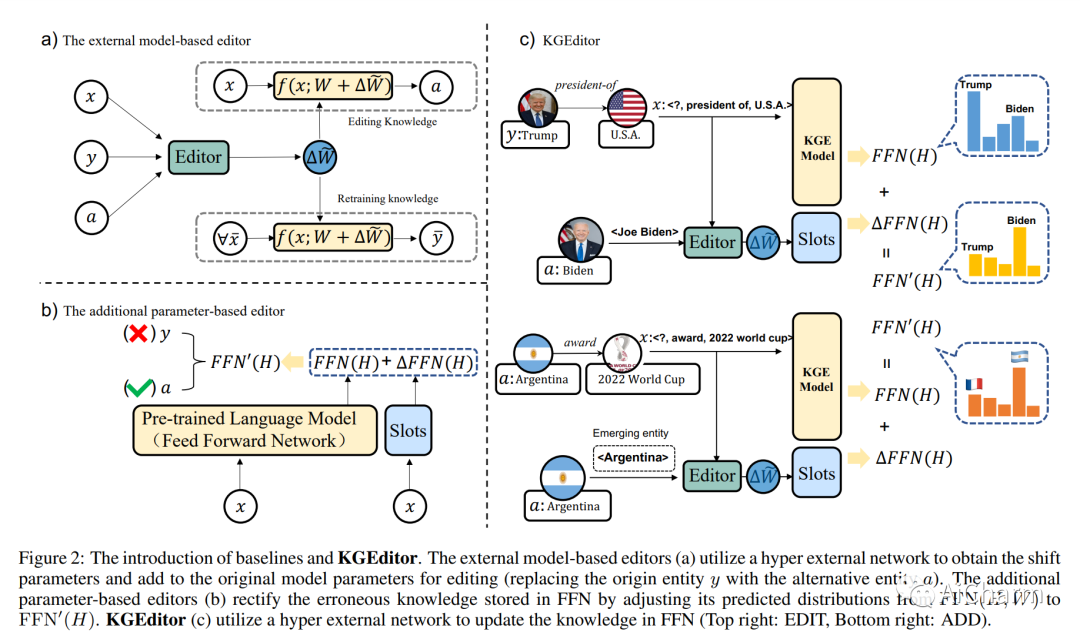
最近几十年来,通过语言模型构建知识图谱(KG)嵌入取得了经验上的成功。然而,基于语言模型的KG嵌入通常被部署为静态的人工制品,在部署后不重新训练的情况下进行修改是具有挑战性的。为了解决这个问题,我们在本文中提出了一个编辑基于语言模型的KG嵌入的新任务。所提出的任务旨在实现对KG嵌入的数据高效和快速更新,而不损害其余部分的性能。我们建立了四个新的数据集。E-FB15k237、A-FB15k237、E-WN18RR和A-WN18RR,并评估了几个知识编辑基线,证明了以前的模型处理拟议的挑战性任务的能力有限。我们进一步提出了一个简单而强大的基线,称为KGEditor,它利用超网络的额外参数层来编辑/添加事实。综合实验结果表明,KGEditor在更新特定的事实时可以表现得更好,同时不影响其他低训练资源。
Recently decades have witnessed the empirical success of framing Knowledge Graph (KG) embeddings via language models. However, language model-based KG embeddings are usually deployed as static artifacts, which are challenging to modify without re-training after deployment. To address this issue, we propose a new task of editing language model-based KG embeddings in this paper. The proposed task aims to enable data-efficient and fast updates to KG embeddings without damaging the performance of the rest. We build four new datasets: E-FB15k237, A-FB15k237, E-WN18RR, and A-WN18RR, and evaluate several knowledge editing baselines demonstrating the limited ability of previous models to handle the proposed challenging task. We further propose a simple yet strong baseline dubbed KGEditor, which utilizes additional parametric layers of the hyper network to edit/add facts. Comprehensive experimental results demonstrate that KGEditor can perform better when updating specific facts while not affecting the rest with low training resources.
2.ExaRanker: Explanation-Augmented Neural Ranker

标题:解释增强型神经排行器
作者: Fernando Ferraretto, Thiago Laitz, Roberto Lotufo, Rodrigo Nogueira
文章L接:arxiv.org/abs/2301.10521v1
项目代码:github.com/unicamp-dl/exaranker
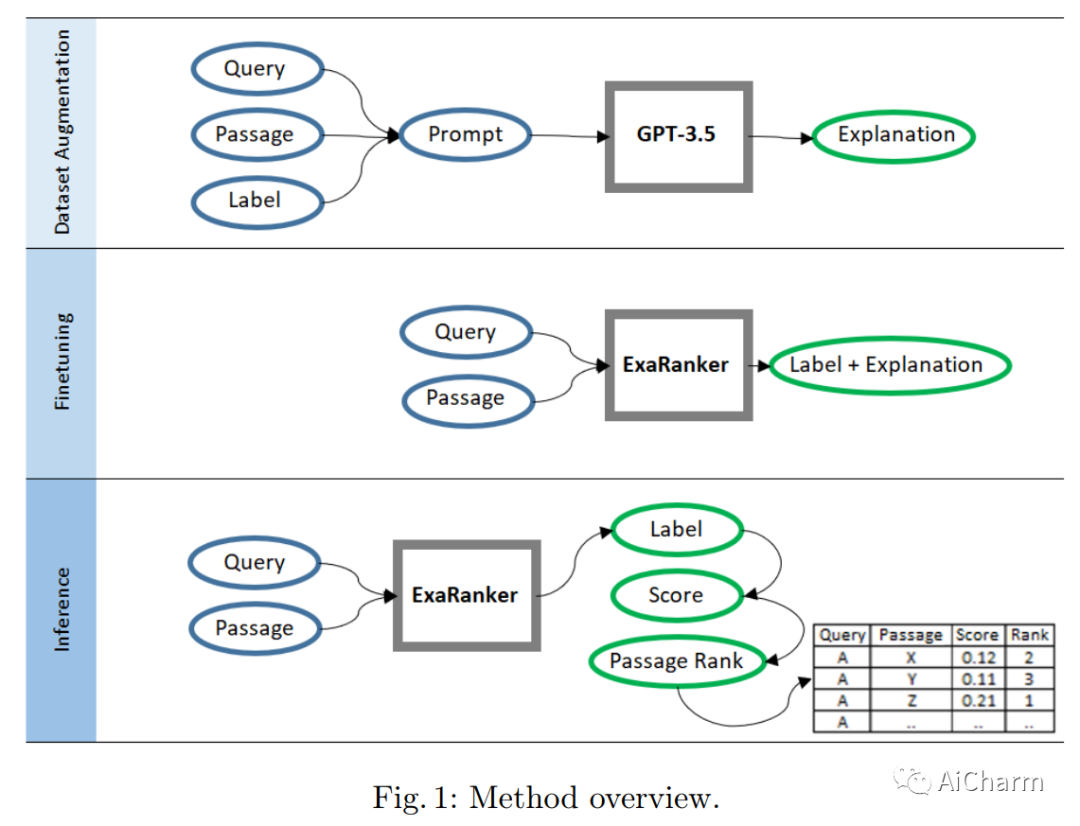
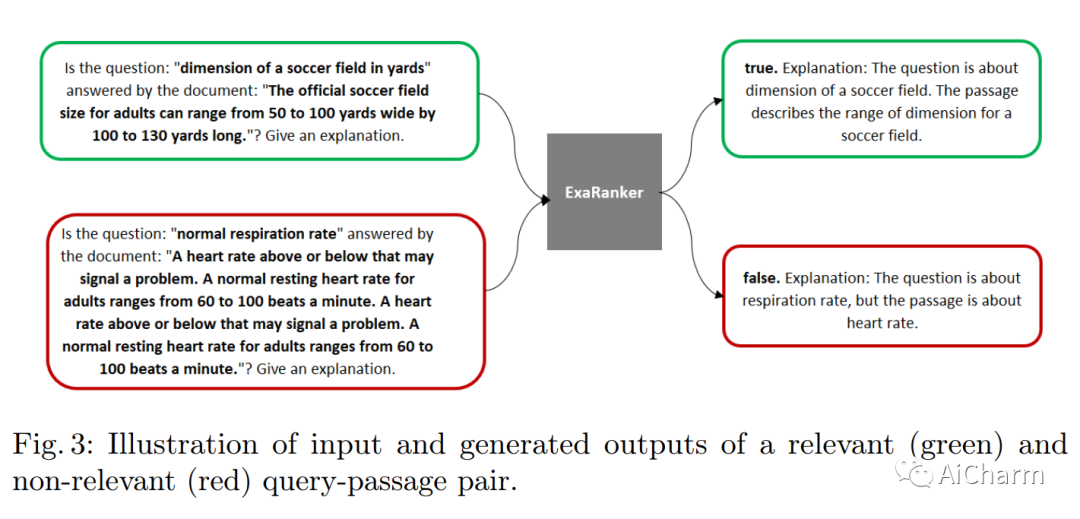
摘要:
最近的工作表明,诱导大型语言模型(LLM)在输出答案之前产生解释是一种有效的策略,可以提高各种推理任务的性能。在这项工作中,我们表明,神经排名器也能从解释中受益。我们使用GPT-3.5等LLMs来增加带有解释的检索数据集,并训练一个序列到序列的排名模型,为给定的查询-文档对输出一个相关性标签和一个解释。我们的模型被称为ExaRanker,在几千个带有合成解释的例子上进行了微调,其表现与在3倍以上没有解释的例子上进行微调的模型相当。此外,ExaRanker模型在排名过程中不产生额外的计算成本,并允许按需请求解释。
Recent work has shown that inducing a large language model (LLM) to generate explanations prior to outputting an answer is an effective strategy to improve performance on a wide range of reasoning tasks. In this work, we show that neural rankers also benefit from explanations. We use LLMs such as GPT-3.5 to augment retrieval datasets with explanations and train a sequence-to-sequence ranking model to output a relevance label and an explanation for a given query-document pair. Our model, dubbed ExaRanker, finetuned on a few thousand examples with synthetic explanations performs on par with models finetuned on 3x more examples without explanations. Furthermore, the ExaRanker model incurs no additional computational cost during ranking and allows explanations to be requested on demand.
3.Semi-Automated Construction of Food Composition Knowledge Base

标题:半自动构建食品成分知识库
作者:Jason Youn, Fangzhou Li, Ilias Tagkopoulos
文章链接:arxiv.org/abs/2301.11322v1
项目代码:github.com/ibpa/semiautomatedfoodkbc

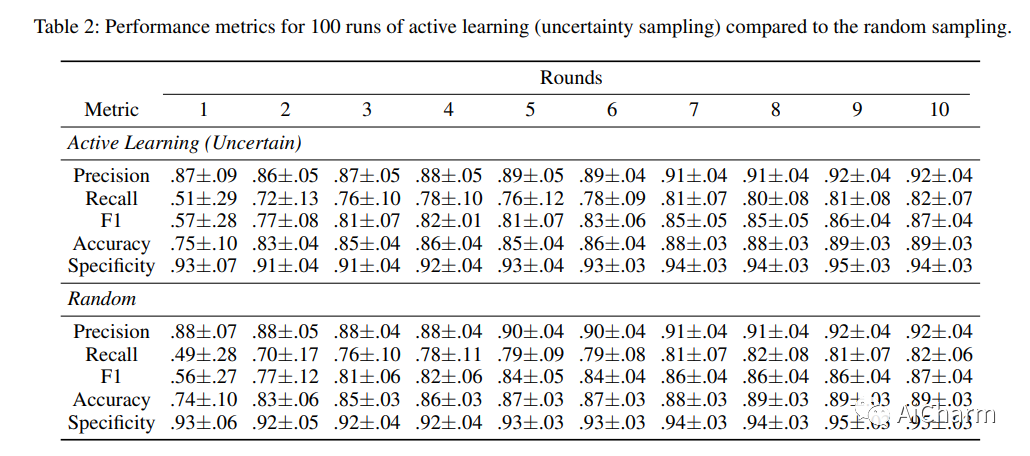
摘要:
食品成分知识库,储存了食品的基本植物、微观和宏观营养素,对研究和工业应用都很有用。尽管许多现有的知识库试图整理这些信息,但它们往往受到耗时的人工整理过程的限制。在食品科学领域之外,利用预先训练好的语言模型的自然语言处理方法最近显示了从非结构化文本中提取知识的可喜成果。在这项工作中,我们提出了一个半自动化的框架,用于从网上的科学文献中构建一个食品成分的知识库。为此,我们在主动学习设置中利用了预先训练好的BioBERT语言模型,从而使有限的训练数据得到最佳利用。我们的工作表明,人在回路中的模型是迈向人工智能辅助食品系统的一步,可以很好地扩展到不断增加的大数据。
A food composition knowledge base, which stores the essential phyto-, micro-, and macro-nutrients of foods is useful for both research and industrial applications. Although many existing knowledge bases attempt to curate such information, they are often limited by time-consuming manual curation processes. Outside of the food science domain, natural language processing methods that utilize pre-trained language models have recently shown promising results for extracting knowledge from unstructured text. In this work, we propose a semi-automated framework for constructing a knowledge base of food composition from the scientific literature available online. To this end, we utilize a pre-trained BioBERT language model in an active learning setup that allows the optimal use of limited training data. Our work demonstrates how human-in-the-loop models are a step toward AI-assisted food systems that scale well to the ever-increasing big data.