数仓概念
⚫ 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
⚫ 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。

数仓专注分析
⚫ 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
⚫ 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用;
⚫ 这也是为什么叫“仓库”,而不叫“工厂”的原因。

数据仓库为何而来,解决什么问题的?
先下结论:为了分析数据而来,分析结果给企业决策提供支撑。
下面以中国人寿保险公司(chinalife)发展为例,阐述数据仓库为何而来?
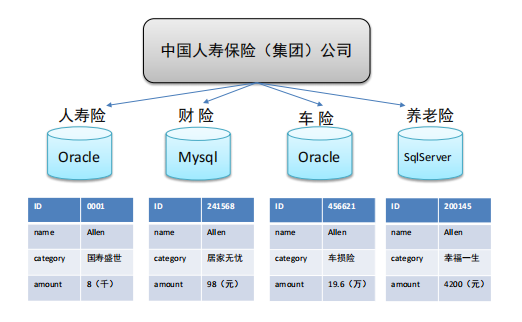
(1)业务数据的存储问题
⚫ 中国人寿保险(集团)公司下辖多条业务线,包括:人寿险、财险、车险,养老险等。各业务线的业务正常运营需
要记录维护包括客户、保单、收付费、核保、理赔等信息。这么多业务数据存储在哪里呢?
⚫ 联机事务处理系统(OLTP)正好可以满足上述业务需求开展, 其主要任务是执行联机事务处理。其基本特征是前台
接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。

关系型数据库(RDBMS)是OLTP典型应用,比如:Oracle、MySQL、SQL Server等。
(2)分析型决策的制定
⚫ 随着集团业务的持续运营,业务数据将会越来越多。由此也产生出许多运营相关的困惑:
能够确定哪些险种正在恶化或已成为不良险种?
能够用有效的方式制定新增和续保的政策吗?
理赔过程有欺诈的可能吗?
现在得到的报表是否只是某条业务线的?集团整体层面数据如何?
…
⚫ 为了能够正确认识这些问题,制定相关的解决措施,瞎拍桌子是肯定不行的。
⚫ 最稳妥办法就是:基于业务数据开展数据分析,基于分析的结果给决策提供支撑。也就是所谓的数据驱动决策的制 定。

OLTP环境开展分析可行吗?
可以,但是没必要
⚫ OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压力明显大于写的压力。如果在OLTP环境直接开展各种分析,有以下问题需要考虑:
⚫ 数据分析也是对数据进行读取操作,会让读取压力倍增;
⚫ OLTP仅存储数周或数月的数据;
⚫ 数据分散在不同系统不同表中,字段类型属性不统一;
数据仓库面世
⚫ 当分析所涉及数据规模较小的时候,在业务低峰期时可以在OLTP系统上开展直接分析。
⚫ 但为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。该平台的目的很简单:面向分析,支持分析,并且和OLTP系统解耦合。
⚫ 基于这种需求,数据仓库的雏形开始在企业中出现了
数据仓库的构建
⚫ 如数仓定义所说,数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。我们把
这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统。当然,数据仓库是OLAP系统的一种实现。
⚫ 中国人寿保险公司就可以基于分析决策需求,构建数仓平台。

数仓主要特征

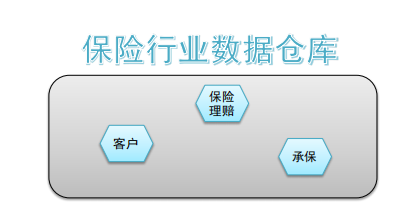
面向主题性(Subject-Oriented)
⚫ 主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上, 它是对应企业中某一宏观分析领域所涉及的分析对象。
⚫ 传统OLTP系统对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域 ,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
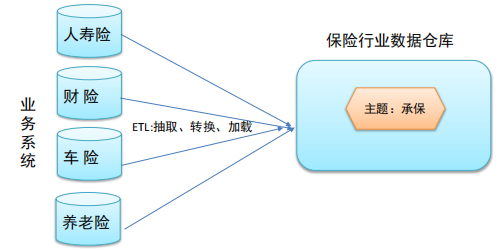
集成性(Integrated)
⚫ 主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。
⚫ 因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库
建设中最关键、最复杂的一步,所要完成的工作有:
⚫ 要统一源数据中所有矛盾之处;
如字段的同名异义、异名同义、单位不统一、字长不一致等等。
⚫ 进行数据综合和计算。
数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
下图说明了保险公司综合数据的简单处理过程,其中数据仓库中与“承保”主题有关的数据来自于多个不同的操作型系统。
⚫ 这些系统内部数据的命名可能不同,数据格式也可能不同。把不同来源的数据存储到数据仓库之前,需要去除这些不一致。
非易失性、非异变性(Non-Volatile)
⚫ 数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
⚫ 数据仓库的数据反映的是一段相当长的时间内历史数据的内容,数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。
⚫ 数据仓库中一般有大量的查询操作,但修改和删除操作很少。
时变性(Time-Variant)
⚫ 数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。
⚫ 当业务变化后会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。
⚫ 从这个角度讲,数据仓库建设是一个项目,更是一个过程 。
数仓开发语言概述
⚫ 数仓作为面向分析的数据平台,其主职工作就是对存储在其中的数据开展分析,那么如何读取数据分析呢?
⚫ 理论上来说,任何一款编程语言只要具备读写数据、处理数据的能力,都可以用于数仓的开发。比如大家耳熟能详的C、java、Python等;
⚫ 关键在于编程语言是否易学、好用、功能是否强大。遗憾的是上面所列出的C、Python等编程语言都需要一定的时
间进行语法的学习,并且学习语法之后还需要结合分析的业务场景进行编码,跑通业务逻辑。
⚫ 不管从学习成本还是开发效率来说,上述所说的编程语言都不是十分友好的。
⚫ 在数据分析领域,不得不提的就是SQL编程语言,应该称之为分析领域主流开发语言。
数仓与SQL
⚫ 虽然SQL语言本身是针对数据库软件设计的,但是在数据仓库领域,尤其是大数据数仓领域,很多数仓软件都会去支持SQL语法;
⚫ 原因在于一是用户学习SQL成本低,二是SQL语言对于数据分析真的十分友好,爱不释手。
SQL语法分类
SQL主要语法分为两个部分:数据定义语言 (DDL)和数据操纵语言 (DML) 。
⚫ DDL语法使我们有能力创建或删除表,以及数据库、索引等各种对象,但是不涉及表中具体数据操作:
CREATE DATABASE - 创建新数据库
CREATE TABLE - 创建新表
⚫ DML语法是我们有能力针对表中的数据进行插入、更新、删除、查询操作:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT - 向数据库表中插入数据
大数据自学相关资料:
Python+大数据开发
Linux入门:
新版Linux零基础快速入门到精通,全涵盖linux系统知识、常用软件环境部署、Shell脚本、云平台实践、大数据集群项目实战等
MySQL数据库:MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
Hadoop入门:大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程
Hive数仓项目:大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
PB内存计算
Python入门:python教程,8天python从入门到精通,学python看这套就够了
Python编程进阶:Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
spark3.2从基础到精通:Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
Hive+Spark离线数仓工业项目实战:全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台