✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
中文场景文字识别
项目来源:飞桨学习赛:中文场景文字识别 - 飞桨AI Studio
项目背景
随着OCR领域在结构化数据中取得不错成果及应用,中文场景文字识别技术在人们的日常生活中受到广泛关注,在文档识别、身份证识别、银行卡识别、病例识别、名片识别等领域广泛应用.但由于中文场景中的文字容易受光照变化、低分辨率、字体以及排布多样性、中文字符种类多等影响,对识别经典有一定影响,如何解决这一问题是目前值得关注的。

项目简介:
本项目为基于PaddleOCR的中文场景文字识别,项目主要以CRNN网络为基础框架,结合数据增强及模型微调,采用ResNet34和MobileNetV3模型作为骨干网络,进行训练及预测。以准确度为评价指标,最终生成的预测文件为work中的result.txt文件。
数据集介绍:
本比赛提供的数据训练集(train_img)是5w张,测试集(test_img)为1w张。训练集原始标注文件(train.list)。所有图像经过预处理,将文字区域进行处理,统一为高48像素的图片。
相关技术
PaddleOCR参考: https://github.com/PaddlePaddle/PaddleOCR
项目以PaddleOCR为框架,采用CRNN+CTC网络为主体,具体结果如下图:
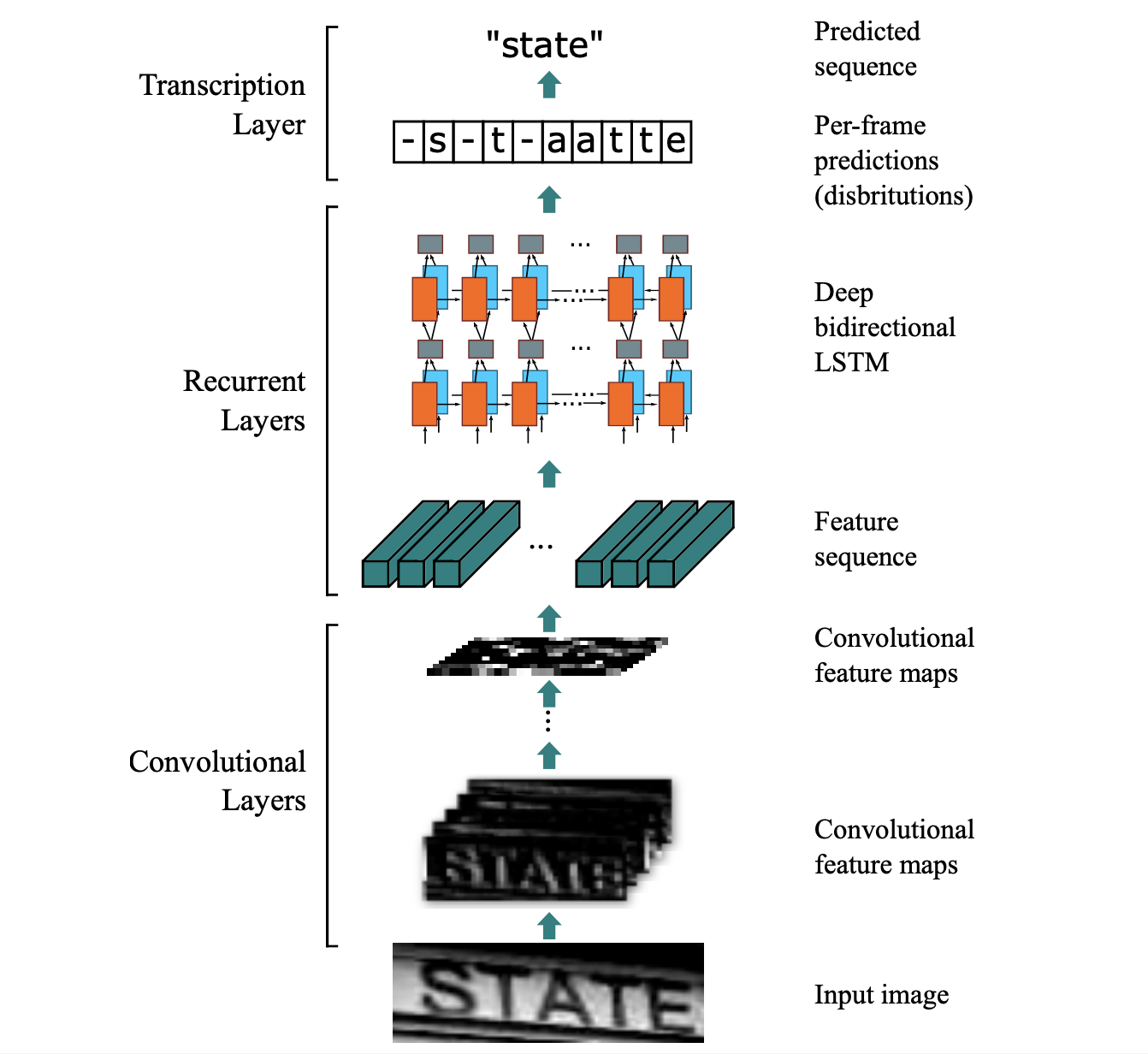
注:本项目最后识别存在一定问题,最近比较忙,后续会处理,流程是对的!
项目流程:
1.PaddleOCR安装
2.数据处理
3.模型调整
4.训练与预测
一、环境安装
1.1安装PaddleOCR
In [ ]
#克隆PaddleOCR项目
!cd ~/work && git clone -b develop https://gitee.com/paddlepaddle/PaddleOCR.gitIn [ ]
#安装提供环境文件requirements.txt
!cd ~/work/PaddleOCR
!pip install -r requirements.txt && python setup.py install二、数据处理
2.1解压数据集
In [ ]
#解压训练集与测试集
!cd ~/data/data62842/ && unzip train_images.zip
!cd ~/data/data62843/ && unzip test_images.zipIn [ ]
#移动数据集
!cd ~/data/data62842/ && mv train_images ../ && mv train_label.csv ../
!cd ~/data/data62843/ && mv test_images ../ In [5]
#查看标签文件
%cd data/data62842
!cat mv train_label.csv | head -n 102.2数据增广
- 首先,考虑使用轻量模型会有一定精度损失,采用经典网络ResNet34。
- 其次,为了进一步增强识别效果及模型泛化行,参考其他项目使用text_render进行数据增广。
- 最后,使用text_renderer进行数据增广,修改text_render/configs/default.yaml配置,以下为更改后的模版,主要将三项做修改,分别是font_color的enable设为True,img_bg的enable设为False,seamless_clone的enable设为True。
数据增广参考本项目:https://aistudio.baidu.com/aistudio/projectdetail/1306342?channelType=0&channel=0
# Small font_size will make text looks like blured/prydown
font_size:
min: 14
max: 23
# choose Text color range
# color boundary is in R,G,B format
font_color:
enable: True
blue:
fraction: 0.5
l_boundary: [0,0,150]
h_boundary: [60,60,255]
brown:
fraction: 0.5
l_boundary: [139,70,19]
h_boundary: [160,82,43]
# By default, text is drawed by Pillow with (https://stackoverflow.com/questions/43828955/measuring-width-of-text-python-pil)
# If `random_space` is enabled, some text will be drawed char by char with a random space
random_space:
enable: false
fraction: 0.3
min: -0.1 # -0.1 will make chars very close or even overlapped
max: 0.1
# Do remap with sin()
# Currently this process is very slow!
curve:
enable: false
fraction: 0.3
period: 360 # degree, sin 函数的周期
min: 1 # sin 函数的幅值范围
max: 5
# random crop text height
crop:
enable: false
fraction: 0.5
# top and bottom will applied equally
top:
min: 5
max: 10 # in pixel, this value should small than img_height
bottom:
min: 5
max: 10 # in pixel, this value should small than img_height
# Use image in bg_dir as background for text
img_bg:
enable: false
fraction: 0.5
# Not work when random_space applied
text_border:
enable: false
fraction: 0.5
# lighter than word color
light:
enable: true
fraction: 0.5
# darker than word color
dark:
enable: true
fraction: 0.5
# https://docs.opencv.org/3.4/df/da0/group__photo__clone.html#ga2bf426e4c93a6b1f21705513dfeca49d
# https://www.cs.virginia.edu/~connelly/class/2014/comp_photo/proj2/poisson.pdf
# Use opencv seamlessClone() to draw text on background
# For some background image, this will make text image looks more real
seamless_clone:
enable: true
fraction: 0.5
perspective_transform:
max_x: 25
max_y: 25
max_z: 3
blur:
enable: true
fraction: 0.03
# If an image is applied blur, it will not be applied prydown
prydown:
enable: true
fraction: 0.03
max_scale: 1.5 # Image will first resize to 1.5x, and than resize to 1x
noise:
enable: true
fraction: 0.3
gauss:
enable: true
fraction: 0.25
uniform:
enable: true
fraction: 0.25
salt_pepper:
enable: true
fraction: 0.25
poisson:
enable: true
fraction: 0.25
line:
enable: false
fraction: 0.05
random_over:
enable: true
fraction: 0.2
under_line:
enable: false
fraction: 0.2
table_line:
enable: false
fraction: 0.3
middle_line:
enable: false
fraction: 0.3
line_color:
enable: false
black:
fraction: 0.5
l_boundary: [0,0,0]
h_boundary: [64,64,64]
blue:
fraction: 0.5
l_boundary: [0,0,150]
h_boundary: [60,60,255]
# These operates are applied on the final output image,
# so actually it can also be applied in training process as an data augmentation method.
# By default, text is darker than background.
# If `reverse_color` is enabled, some images will have dark background and light text
reverse_color:
enable: false
fraction: 0.5
emboss:
enable: false
fraction: 0.1
sharp:
enable: false
fraction: 0.1
In [ ]
!cd ~/work && git clone https://github.com/Sanster/text_renderer
!cd ~/work/text_renderer && pip install -r requirements.txt- CRNN网络主要考虑图片高度。以4为倍数,通过统计训练集的图像尺寸,训练时图片高度设为48。
In [ ]
import glob
import os
import cv2
def get_aspect_ratio(img_set_dir):
m_width = 0
m_height = 0
width_dict = {}
height_dict = {}
images = glob.glob(img_set_dir+'*.jpg')
for image in images:
img = cv2.imread(image)
width_dict[int(img.shape[1])] = 1 if (int(img.shape[1])) not in width_dict else 1 + width_dict[int(img.shape[1])]
height_dict[int(img.shape[0])] = 1 if (int(img.shape[0])) not in height_dict else 1 + height_dict[int(img.shape[0])]
m_width += img.shape[1]
m_height += img.shape[0]
m_width = m_width/len(images)
m_height = m_height/len(images)
aspect_ratio = m_width/m_height
width_dict = dict(sorted(width_dict.items(), key=lambda item: item[1], reverse=True))
height_dict = dict(sorted(height_dict.items(), key=lambda item: item[1], reverse=True))
return aspect_ratio,m_width,m_height,width_dict,height_dict
aspect_ratio,m_width,m_height,width_dict,height_dict = get_aspect_ratio("/home/aistudio/data/train_images/")
print("aspect ratio is: {}, mean width is: {}, mean height is: {}".format(aspect_ratio,m_width,m_height))
print("Width dict:{}".format(width_dict))
print("Height dict:{}".format(height_dict))
import pandas as pd
def Q2B(s):
"""全角转半角"""
inside_code=ord(s)
if inside_code==0x3000:
inside_code=0x0020
else:
inside_code-=0xfee0
if inside_code<0x0020 or inside_code>0x7e: #转完之后不是半角字符返回原来的字符
return s
return chr(inside_code)
def stringQ2B(s):
"""把字符串全角转半角"""
return "".join([Q2B(c) for c in s])
def is_chinese(s):
"""判断unicode是否是汉字"""
for c in s:
if c < u'\u4e00' or c > u'\u9fa5':
return False
return True
def is_number(s):
"""判断unicode是否是数字"""
for c in s:
if c < u'\u0030' or c > u'\u0039':
return False
return True
def is_alphabet(s):
"""判断unicode是否是英文字母"""
for c in s:
if c < u'\u0061' or c > u'\u007a':
return False
return True
def del_other(s):
"""判断是否非汉字,数字和小写英文"""
res = str()
for c in s:
if not (is_chinese(c) or is_number(c) or is_alphabet(c)):
c = ""
res += c
return res
df = pd.read_csv("/home/aistudio/data/train_label.csv", encoding="gbk")
name, value = list(df.name), list(df.value)
for i, label in enumerate(value):
# 全角转半角
label = stringQ2B(label)
# 大写转小写
label = "".join([c.lower() for c in label])
# 删除所有空格符号
label = del_other(label)
value[i] = label
# 删除标签为""的行
data = zip(name, value)
data = list(filter(lambda c: c[1]!="", list(data)))
# 保存到work目录
with open("/home/aistudio/data/train_label.txt", "w") as f:
for line in data:
f.write(line[0] + "\t" + line[1] + "\n")
# 记录训练集中最长标签
label_max_len = 0
with open("/home/aistudio/data/train_label.txt", "r") as f:
for line in f:
name, label = line.strip().split("\t")
if len(label) > label_max_len:
label_max_len = len(label)
print("label max len: ", label_max_len)
def create_label_list(train_list):
classSet = set()
with open(train_list) as f:
next(f)
for line in f:
img_name, label = line.strip().split("\t")
for e in label:
classSet.add(e)
# 在类的基础上加一个blank
classList = sorted(list(classSet))
with open("/home/aistudio/data/label_list.txt", "w") as f:
for idx, c in enumerate(classList):
f.write("{}\t{}\n".format(c, idx))
# 为数据增广提供词库
with open("/home/aistudio/work/text_renderer/data/chars/ch.txt", "w") as f:
for idx, c in enumerate(classList):
f.write("{}\n".format(c))
return classSet
classSet = create_label_list("/home/aistudio/data/train_label.txt")
print("classify num: ", len(classSet))aspect ratio is: 3.451128333333333, mean width is: 165.65416, mean height is: 48.0
Width dict:{48: 741, 96: 539, 44: 392, 42: 381, 144: 365, 45: 345, 43: 323, 72: 318, 88: 318, 40: 312, 52: 301, 36: 298, 50: 297, 120: 294, 54: 288, 84: 286, 51: 283, 32: 283, 24: 281, 100: 277, 64: 276, 80: 276, 76: 275, 102: 272, 81: 270, 90: 269, 56: 268, 66: 267, 78: 266, 37: 262, 82: 261, 41: 259, 89: 258, 92: 257, 46: 256, 60: 251, 86: 249, 168: 246, 53: 246, 105: 243, 61: 242, 57: 241, 128: 241, 112: 240, 85: 239, 39: 237, 91: 237, 68: 235, 98: 234, 192: 233, 93: 233, 75: 232, 74: 229, 34: 229, 33: 229, 70: 228, 25: 226, 87: 226, 104: 224, 110: 224, 58: 223, 132: 221, 62: 221, 49: 221, 101: 221, 108: 221, 126: 218, 150: 218, 94: 217, 73: 217, 129: 216, 28: 216, 30: 215, 69: 215, 99: 212, 160: 211, 38: 210, 136: 209, 109: 207, 26: 207, 55: 206, 35: 205, 118: 205, 116: 204, 115: 203, 174: 201, 117: 200, 148: 200, 106: 200, 122: 199, 113: 198, 67: 197, 77: 197, 172: 195, 114: 195, 156: 194, 130: 191, 140: 190, 138: 190, 83: 187, 103: 186, 124: 186, 147: 185, 59: 183, 139: 182, 146: 180, 123: 180, 176: 179, 27: 179, 97: 177, 65: 176, 161: 174, 162: 173, 137: 173, 154: 172, 158: 171, 133: 171, 31: 169, 240: 169, 125: 168, 29: 168, 169: 166, 186: 166, 141: 166, 121: 165, 165: 164, 152: 161, 134: 161, 157: 160, 153: 160, 135: 159, 166: 156, 149: 155, 177: 154, 189: 154, 63: 151, 163: 151, 142: 150, 181: 149, 107: 146, 183: 145, 111: 145, 173: 144, 170: 144, 79: 144, 178: 143, 184: 143, 216: 141, 164: 141, 171: 137, 204: 137, 159: 136, 185: 135, 127: 134, 196: 134, 187: 132, 200: 131, 210: 130, 194: 130, 151: 127, 208: 126, 155: 126, 145: 125, 180: 125, 131: 123, 71: 123, 198: 121, 182: 120, 217: 119, 220: 119, 188: 118, 201: 116, 195: 115, 202: 114, 228: 111, 179: 111, 175: 111, 206: 110, 256: 109, 232: 109, 222: 109, 205: 108, 252: 106, 197: 105, 211: 104, 219: 103, 214: 102, 119: 100, 234: 100, 288: 99, 47: 99, 218: 99, 213: 99, 203: 98, 225: 97, 264: 97, 209: 96, 242: 96, 190: 96, 199: 96, 236: 94, 226: 94, 224: 93, 193: 91, 229: 91, 246: 89, 212: 87, 243: 86, 249: 86, 207: 84, 262: 84, 231: 82, 268: 82, 245: 81, 237: 81, 235: 80, 230: 78, 221: 78, 233: 78, 260: 75, 250: 74, 261: 74, 244: 74, 248: 74, 167: 74, 273: 73, 227: 72, 274: 72, 247: 70, 336: 70, 270: 67, 276: 67, 241: 66, 253: 65, 223: 64, 300: 64, 272: 64, 277: 64, 265: 64, 267: 63, 279: 61, 282: 60, 254: 60, 271: 60, 259: 60, 258: 59, 278: 59, 292: 59, 280: 59, 238: 58, 255: 58, 312: 58, 95: 57, 215: 57, 284: 57, 251: 56, 283: 56, 304: 54, 296: 54, 306: 54, 266: 53, 290: 53, 285: 52, 360: 52, 269: 52, 143: 51, 384: 51, 297: 50, 324: 49, 291: 49, 330: 49, 320: 49, 313: 49, 309: 49, 302: 48, 257: 47, 340: 46, 328: 45, 318: 45, 314: 45, 368: 45, 333: 45, 325: 45, 308: 44, 281: 43, 332: 43, 275: 43, 369: 42, 310: 42, 295: 41, 341: 41, 191: 41, 303: 41, 322: 40, 342: 40, 298: 40, 294: 40, 293: 40, 289: 39, 400: 39, 378: 39, 286: 38, 346: 38, 321: 38, 432: 37, 307: 37, 338: 37, 316: 37, 299: 37, 331: 36, 327: 36, 323: 36, 329: 35, 344: 35, 305: 34, 348: 34, 339: 34, 317: 32, 311: 31, 375: 31, 349: 31, 396: 31, 263: 31, 361: 31, 373: 30, 372: 30, 381: 30, 347: 30, 301: 30, 434: 29, 345: 29, 326: 29, 403: 29, 362: 29, 334: 29, 402: 28, 337: 28, 480: 28, 387: 28, 351: 28, 366: 28, 376: 27, 315: 27, 352: 27, 404: 27, 239: 27, 377: 26, 354: 26, 389: 26, 358: 26, 405: 26, 394: 25, 319: 25, 363: 25, 386: 25, 364: 25, 391: 24, 388: 24, 408: 24, 464: 24, 353: 24, 382: 24, 365: 24, 371: 23, 379: 23, 429: 23, 416: 23, 374: 23, 393: 23, 390: 23, 355: 23, 392: 22, 444: 22, 457: 22, 468: 22, 423: 22, 401: 22, 406: 21, 395: 21, 528: 21, 357: 21, 398: 21, 477: 21, 436: 21, 425: 20, 356: 20, 459: 20, 343: 20, 447: 20, 438: 20, 445: 20, 414: 19, 411: 19, 496: 19, 413: 18, 367: 18, 418: 18, 417: 18, 410: 18, 359: 18, 385: 17, 419: 17, 412: 17, 428: 17, 380: 17, 453: 17, 424: 16, 483: 16, 370: 16, 430: 16, 427: 16, 473: 16, 472: 16, 350: 15, 420: 15, 399: 15, 510: 15, 454: 15, 462: 15, 450: 15, 422: 15, 437: 15, 397: 14, 544: 14, 439: 14, 440: 14, 287: 14, 474: 14, 460: 14, 446: 13, 433: 13, 465: 13, 493: 13, 471: 13, 456: 13, 451: 13, 421: 13, 481: 13, 488: 13, 492: 13, 537: 13, 409: 13, 461: 13, 509: 13, 535: 13, 558: 12, 426: 12, 458: 12, 335: 12, 482: 12, 562: 12, 415: 11, 505: 11, 512: 11, 504: 11, 616: 11, 549: 11, 441: 11, 484: 11, 645: 11, 536: 11, 490: 11, 476: 11, 435: 11, 572: 11, 539: 11, 486: 10, 556: 10, 443: 10, 580: 10, 592: 10, 552: 10, 523: 10, 448: 10, 506: 10, 452: 10, 538: 10, 612: 10, 550: 10, 534: 10, 514: 10, 570: 10, 469: 10, 495: 10, 522: 10, 576: 10, 442: 10, 499: 10, 407: 9, 491: 9, 520: 9, 517: 9, 524: 9, 529: 9, 601: 9, 467: 9, 568: 9, 546: 9, 470: 9, 516: 9, 463: 9, 487: 9, 508: 9, 383: 9, 485: 9, 518: 8, 532: 8, 553: 8, 574: 8, 571: 8, 466: 8, 478: 8, 497: 8, 640: 8, 542: 8, 634: 8, 501: 8, 475: 8, 573: 8, 560: 8, 489: 7, 531: 7, 540: 7, 593: 7, 603: 7, 545: 7, 557: 7, 533: 7, 547: 7, 507: 7, 502: 7, 449: 7, 664: 7, 565: 7, 513: 7, 688: 6, 615: 6, 559: 6, 625: 6, 530: 6, 543: 6, 628: 6, 600: 6, 525: 6, 605: 6, 577: 6, 720: 6, 578: 6, 521: 6, 759: 6, 515: 6, 585: 6, 503: 6, 519: 6, 724: 6, 567: 6, 498: 6, 661: 5, 548: 5, 638: 5, 587: 5, 654: 5, 805: 5, 618: 5, 622: 5, 744: 5, 598: 5, 586: 5, 455: 5, 630: 5, 566: 5, 624: 5, 610: 5, 617: 5, 731: 5, 660: 5, 583: 5, 704: 5, 639: 5, 594: 5, 651: 5, 554: 5, 589: 5, 655: 5, 595: 5, 656: 4, 563: 4, 511: 4, 584: 4, 826: 4, 613: 4, 646: 4, 680: 4, 644: 4, 620: 4, 686: 4, 658: 4, 588: 4, 663: 4, 678: 4, 500: 4, 792: 4, 666: 4, 619: 4, 564: 4, 699: 4, 800: 4, 590: 4, 742: 4, 604: 4, 770: 4, 732: 4, 736: 4, 606: 4, 643: 4, 797: 4, 431: 4, 872: 4, 714: 4, 627: 4, 608: 4, 648: 4, 602: 4, 635: 4, 691: 4, 692: 4, 777: 4, 810: 4, 629: 4, 551: 4, 672: 4, 668: 4, 659: 4, 763: 3, 626: 3, 859: 3, 681: 3, 793: 3, 667: 3, 581: 3, 675: 3, 870: 3, 609: 3, 631: 3, 989: 3, 614: 3, 756: 3, 708: 3, 637: 3, 541: 3, 729: 3, 754: 3, 494: 3, 713: 3, 611: 3, 868: 3, 816: 3, 711: 3, 746: 3, 807: 3, 676: 3, 689: 3, 607: 3, 679: 3, 685: 3, 632: 3, 673: 3, 526: 3, 597: 3, 842: 3, 569: 3, 725: 3, 925: 3, 702: 3, 761: 3, 555: 3, 780: 3, 696: 3, 697: 3, 751: 3, 657: 3, 591: 3, 841: 3, 830: 2, 848: 2, 669: 2, 835: 2, 1062: 2, 996: 2, 694: 2, 882: 2, 757: 2, 743: 2, 804: 2, 784: 2, 693: 2, 896: 2, 755: 2, 701: 2, 707: 2, 690: 2, 889: 2, 884: 2, 963: 2, 727: 2, 683: 2, 674: 2, 579: 2, 726: 2, 662: 2, 712: 2, 710: 2, 822: 2, 1114: 2, 735: 2, 1008: 2, 734: 2, 878: 2, 865: 2, 967: 2, 799: 2, 932: 2, 665: 2, 931: 2, 682: 2, 723: 2, 914: 2, 817: 2, 698: 2, 733: 2, 760: 2, 821: 2, 916: 2, 903: 2, 1106: 2, 874: 2, 641: 2, 787: 2, 988: 2, 824: 2, 894: 2, 866: 2, 930: 2, 738: 2, 952: 2, 582: 2, 765: 2, 705: 2, 836: 2, 709: 2, 887: 2, 633: 2, 840: 2, 839: 2, 778: 2, 1104: 2, 818: 2, 833: 2, 853: 2, 976: 1, 750: 1, 749: 1, 918: 1, 862: 1, 715: 1, 834: 1, 881: 1, 957: 1, 1076: 1, 728: 1, 561: 1, 962: 1, 621: 1, 1225: 1, 1144: 1, 1083: 1, 767: 1, 1014: 1, 779: 1, 747: 1, 1050: 1, 1066: 1, 892: 1, 1400: 1, 929: 1, 1250: 1, 852: 1, 1113: 1, 861: 1, 1080: 1, 1321: 1, 1044: 1, 1283: 1, 717: 1, 1011: 1, 1092: 1, 1287: 1, 1051: 1, 1003: 1, 796: 1, 814: 1, 753: 1, 1381: 1, 1111: 1, 945: 1, 935: 1, 1237: 1, 527: 1, 876: 1, 789: 1, 895: 1, 906: 1, 649: 1, 670: 1, 987: 1, 827: 1, 1314: 1, 1168: 1, 899: 1, 599: 1, 965: 1, 1194: 1, 831: 1, 684: 1, 946: 1, 934: 1, 721: 1, 1505: 1, 1027: 1, 1073: 1, 636: 1, 908: 1, 813: 1, 1188: 1, 820: 1, 860: 1, 1018: 1, 1409: 1, 768: 1, 966: 1, 758: 1, 1176: 1, 973: 1, 1165: 1, 1282: 1, 1084: 1, 986: 1, 1077: 1, 703: 1, 803: 1, 769: 1, 883: 1, 1514: 1, 776: 1, 823: 1, 978: 1, 730: 1, 1280: 1, 687: 1, 917: 1, 943: 1, 766: 1, 794: 1, 997: 1, 1039: 1, 774: 1, 953: 1, 1010: 1, 825: 1, 785: 1, 1147: 1, 716: 1, 812: 1, 873: 1, 1626: 1, 924: 1, 898: 1, 695: 1, 977: 1, 926: 1, 984: 1, 718: 1, 479: 1, 650: 1, 1203: 1, 652: 1, 1126: 1, 741: 1, 1260: 1, 1624: 1, 900: 1, 941: 1, 773: 1, 790: 1, 706: 1, 737: 1, 1087: 1, 642: 1, 575: 1, 1234: 1, 1097: 1, 772: 1, 947: 1, 596: 1, 771: 1, 745: 1, 847: 1, 647: 1, 979: 1, 819: 1, 764: 1, 748: 1, 1009: 1, 1208: 1, 901: 1, 781: 1, 1071: 1}
Height dict:{48: 50000}
label max len: 77
classify num: 3096
-
生成字符长度为1,2,3,4,5的数据集各2000张,共10000张。
-
部分生成图片示例如:

In [ ]
!cd ~/work/text_renderer && python main.py --length 1 --img_width 32 --img_height 48 --chars_file "./data/chars/ch.txt" --corpus_mode 'random' --num_img 2000
!cd ~/work/text_renderer && python main.py --length 2 --img_width 64 --img_height 48 --chars_file "./data/chars/ch.txt" --corpus_mode 'random' --num_img 2000
!cd ~/work/text_renderer && python main.py --length 3 --img_width 96 --img_height 48 --chars_file "./data/chars/ch.txt" --corpus_mode 'random' --num_img 2000
!cd ~/work/text_renderer && python main.py --length 4 --img_width 128 --img_height 48 --chars_file "./data/chars/ch.txt" --corpus_mode 'random' --num_img 2000
!cd ~/work/text_renderer && python main.py --length 5 --img_width 160 --img_height 48 --chars_file "./data/chars/ch.txt" --corpus_mode 'random' --num_img 2000Total fonts num: 1 Background num: 1 Generate text images in ./output/default 2000/2000 100% Finish generate data: 5.758 s Total fonts num: 1 Background num: 1 Generate more text images in ./output/default. Start index 2000 2000/2000 100% Finish generate data: 8.900 s Total fonts num: 1 Background num: 1 Generate more text images in ./output/default. Start index 4000 2000/2000 100% Finish generate data: 11.872 s Total fonts num: 1 Background num: 1 Generate more text images in ./output/default. Start index 6000 2000/2000 100% Finish generate data: 16.067 s Total fonts num: 1 Background num: 1 Generate more text images in ./output/default. Start index 8000 2000/2000 100% Finish generate data: 19.593 s
- 将生成的数据集与原数据集合并
In [ ]
!cp ~/work/text_renderer/output/default/*.jpg ~/data/train_imagesIn [ ]
import os
with open('work/text_renderer/output/default/tmp_labels.txt','r',encoding='utf-8') as src_label:
with open('data/train_label.txt','a',encoding='utf-8') as dst_label:
lines = src_label.readlines()
for line in lines:
[img,text] = line.split(' ')
print('{}.jpg\t{}'.format(img,text),file=dst_label,end='')三、模型调整
- 加载CRNN预训练模型
- 改变默认输入图片尺寸,变为为height48,width256
- 优化学习率策略,通过cosine_decay和warmup策略加快模型收敛
CRNN模型介绍
- 本项目模型采用文字识别经典CRNN模型(CNN+RNN+CTC),其中部分模型代码经过PaddleOCR源码改编,完成识别模型的搭建、训练、评估和预测过程。训练时可以手动更改config配置文件(数据训练、加载、评估验证等参数),默认采用优化器采用Adam,使用CTC损失函数。本项目采用ResNet34作为骨干网络。
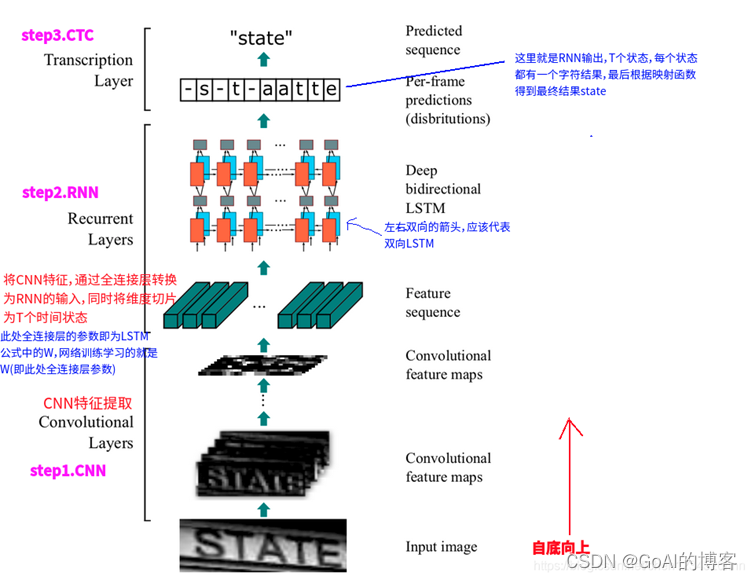
CRNN网络结构包含三部分,从下到上依次为:
(1)卷积层。作用是从输入图像中提取特征序列。
(2)循环层。作用是预测从卷积层获取的特征序列的标签(真实值)分布。
(3)转录层。作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。
In [ ]
!cd ~/work/PaddleOCR && mkdir pretrain_weights && cd pretrain_weights && wget https://paddleocr.bj.bcebos.com/20-09-22/server/rec/ch_ppocr_server_v1.1_rec_pre.tar--2022-09-30 17:16:20-- https://paddleocr.bj.bcebos.com/20-09-22/server/rec/ch_ppocr_server_v1.1_rec_pre.tar Resolving paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 220.181.33.43, 220.181.33.44, 2409:8c04:1001:1002:0:ff:b001:368a Connecting to paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|220.181.33.43|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 297577776 (284M) [application/x-tar] Saving to: ‘ch_ppocr_server_v1.1_rec_pre.tar’ ch_ppocr_server_v1. 100%[===================>] 283.79M 46.8MB/s in 5.3s 2022-09-30 17:16:26 (53.2 MB/s) - ‘ch_ppocr_server_v1.1_rec_pre.tar’ saved [297577776/297577776]
In [ ]
!cd ~/work/PaddleOCR/pretrain_weights && tar -xf ch_ppocr_server_v1.1_rec_pre.tar- 在PaddleOCR/configs/rec中,添加训练配置文件 my_rec_ch_train.yml和my_rec_ch_reader.yml
#my_rec_ch_train.yml
Global:
algorithm: CRNN
use_gpu: true
epoch_num: 201
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/my_rec_ch
save_epoch_step: 50
eval_batch_step: 100000000
train_batch_size_per_card: 64
test_batch_size_per_card: 64
image_shape: [3, 48, 256]
max_text_length: 80
character_type: ch
character_dict_path: ./ppocr/utils/ppocr_keys_v1.txt
loss_type: ctc
distort: true
use_space_char: true
reader_yml: ./configs/rec/my_rec_ch_reader.yml
pretrain_weights: ./pretrain_weights/ch_ppocr_server_v1.1_rec_pre/best_accuracy
checkpoints:
save_inference_dir:
infer_img:
Architecture:
function: ppocr.modeling.architectures.rec_model,RecModel
Backbone:
function: ppocr.modeling.backbones.rec_resnet_vd,ResNet
layers: 34
Head:
function: ppocr.modeling.heads.rec_ctc_head,CTCPredict
encoder_type: rnn
fc_decay: 0.00004
SeqRNN:
hidden_size: 256
Loss:
function: ppocr.modeling.losses.rec_ctc_loss,CTCLoss
Optimizer:
function: ppocr.optimizer,AdamDecay
base_lr: 0.0001
l2_decay: 0.00004
beta1: 0.9
beta2: 0.999
decay:
function: cosine_decay_warmup
step_each_epoch: 1000
total_epoch: 201
warmup_minibatch: 2000
#my_rec_ch_reader.yml
TrainReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
num_workers: 1
img_set_dir: /home/aistudio/data/train_images
label_file_path: /home/aistudio/data/train_label.txt
EvalReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
img_set_dir: /home/aistudio/data/train_images
label_file_path: /home/aistudio/data/train_label.txt
TestReader:
reader_function: ppocr.data.rec.dataset_traversal,SimpleReader
四、训练与预测
4.1 训练模型
- 根据修改后的配置文件,输入以下命令就可以开始训练。
In [33]
!pwd
!cd ~/work/PaddleOCR && python tools/train.py -c configs/rec/my_rec_ch_train.yml4.2导出模型
通过export_model.py导出模型,设置配置文件及导出路径。
In [34]
!cd ~/work/PaddleOCR && python tools/export_model.py -c configs/rec/my_rec_ch_train.yml -o Global.checkpoints=./output/my_rec_ch/iter_epoch_27 Global.save_inference_dir=./inference/CRNN_R342022-09-30 22:57:53,971-INFO: {'Global': {'debug': False, 'algorithm': 'CRNN', 'use_gpu': True, 'epoch_num': 201, 'log_smooth_window': 20, 'print_batch_step': 10, 'save_model_dir': './output/my_rec_ch', 'save_epoch_step': 3, 'eval_batch_step': 100000000, 'train_batch_size_per_card': 64, 'test_batch_size_per_card': 64, 'image_shape': [3, 48, 256], 'max_text_length': 80, 'character_type': 'ch', 'character_dict_path': './ppocr/utils/ppocr_keys_v1.txt', 'loss_type': 'ctc', 'distort': True, 'use_space_char': True, 'reader_yml': './configs/rec/my_rec_ch_reader.yml', 'pretrain_weights': './pretrain_weights/ch_ppocr_server_v1.1_rec_pre/best_accuracy', 'checkpoints': './output/my_rec_ch/iter_epoch_27', 'save_inference_dir': './inference/CRNN_R34', 'infer_img': None}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_resnet_vd,ResNet', 'layers': 34}, 'Head': {'function': 'ppocr.modeling.heads.rec_ctc_head,CTCPredict', 'encoder_type': 'rnn', 'fc_decay': 4e-05, 'SeqRNN': {'hidden_size': 256}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_ctc_loss,CTCLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.0001, 'l2_decay': 4e-05, 'beta1': 0.9, 'beta2': 0.999, 'decay': {'function': 'cosine_decay_warmup', 'step_each_epoch': 1000, 'total_epoch': 201, 'warmup_minibatch': 2000}}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '/home/aistudio/data/train_images', 'label_file_path': '/home/aistudio/data/train_label.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'img_set_dir': '/home/aistudio/data/train_images', 'label_file_path': '/home/aistudio/data/train_label.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader'}}
W0930 22:57:54.222055 22198 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0930 22:57:54.227607 22198 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-30 22:57:57,220-INFO: Finish initing model from ./output/my_rec_ch/iter_epoch_27
inference model saved in ./inference/CRNN_R34/model and ./inference/CRNN_R34/params
save success, output_name_list: ['decoded_out', 'predicts']
4.3预测结果
修改模型路径,运行predict.py:
import sys
import os
from paddleocr import PaddleOCR
import numpy as np
import glob
import time
if __name__=='__main__':
# Preference
img_set_dir = os.path.join('..','data','test_images','')
# Load model
use_gpu = True
use_angle_cls = False
det = False
det_model_dir = os.path.join('PaddleOCR','inference','ch_ppocr_mobile_v1.1_det_infer')
cls_model_dir = os.path.join('PaddleOCR','inference','ch_ppocr_mobile_v1.1_cls_infer')
rec_model_dir = os.path.join('PaddleOCR','inference','CRNN_R34')
ocr = PaddleOCR(use_angle_cls=use_angle_cls, lang="ch",use_gpu=use_gpu,use_space_char=False,gpu_mem=4000,
det = det,
rec_image_shape = '3, 48, 256',
rec_algorithm = 'CRNN',
max_text_length = 80,
det_model_dir = det_model_dir,
cls_model_dir = cls_model_dir,
rec_model_dir = rec_model_dir
)
# Load data in a folder
images = glob.glob(img_set_dir+'*.jpg')
log_file_name = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())
# Print result to a file
with open(log_file_name+'.txt','w') as fid:
print('new_name\tvalue',file=fid)
#Inference in a folder
for image in images:
result = ocr.ocr(image, cls=use_angle_cls,det=det)
if result is None:
print('Test {} failed.'.format(image.replace(img_set_dir,'')))
continue
for info in result:
pred_label = info[0]
print('{}\t{}'.format(image.replace(img_set_dir,''),pred_label),file=fid)
print("Finished predicting {} images!".format(len(images)))
In [35]
!pwd
!python ~/work/predict.py/home/aistudio
最终结果以txt文件保存,命名格式Y-%m-%d-%H-%M-%S,保存在在/home/aistudio/目录下。
In [17]
#查看结果 txt文件生成
%cd /home/aistudio/
!cat 2022-09-30-22-58-06.txt | head -n 2总结与后续:
1.目前只用resnet网络,后续考虑更换更多轻量级网络测试效果;
2.后续继续对数据进行增强操作或结合更多相关数据集,增加模型的泛化性;
3.继续精调整学习率大小及训练策略调整,提升模型的收敛速度及准确度。
参考资料
- PaddleOCR官方教程
- PaddleOCR:中文场景文字识别