目录
前言
目的
思路
代码实现
1. 请求URL,查看源代码
2. 源代码中没有就去抓包工具
3. 拿到视频源链接,继续检索来源
4. 拿到数据和链接,二进制写入到本地
完整源码
运行效果
总结
前言
我们在刷某短视频平台时,有些视频我们想保存到本地观看,但未开放下载渠道,或者我们想下载来收藏或者做成动态壁纸,但是有水印,就很恼火。
网页连接放评论区 网页连接放评论区 网页连接放评论区 网页连接放评论区
就这个问题,我们写一个小小的程序来实现去水印的功能。
目的
给定URL,实现去除水印下载视频的操作。
网页连接放评论区 网页连接放评论区 网页连接放评论区 网页连接放评论区
思路
1. 请求URL,查看源代码
2. 源代码中没有就去抓包工具
3. 拿到视频源链接,继续检索来源
4. 拿到数据和链接,二进制写入到本地
网页连接放评论区 网页连接放评论区 网页连接放评论区 网页连接放评论区
代码实现
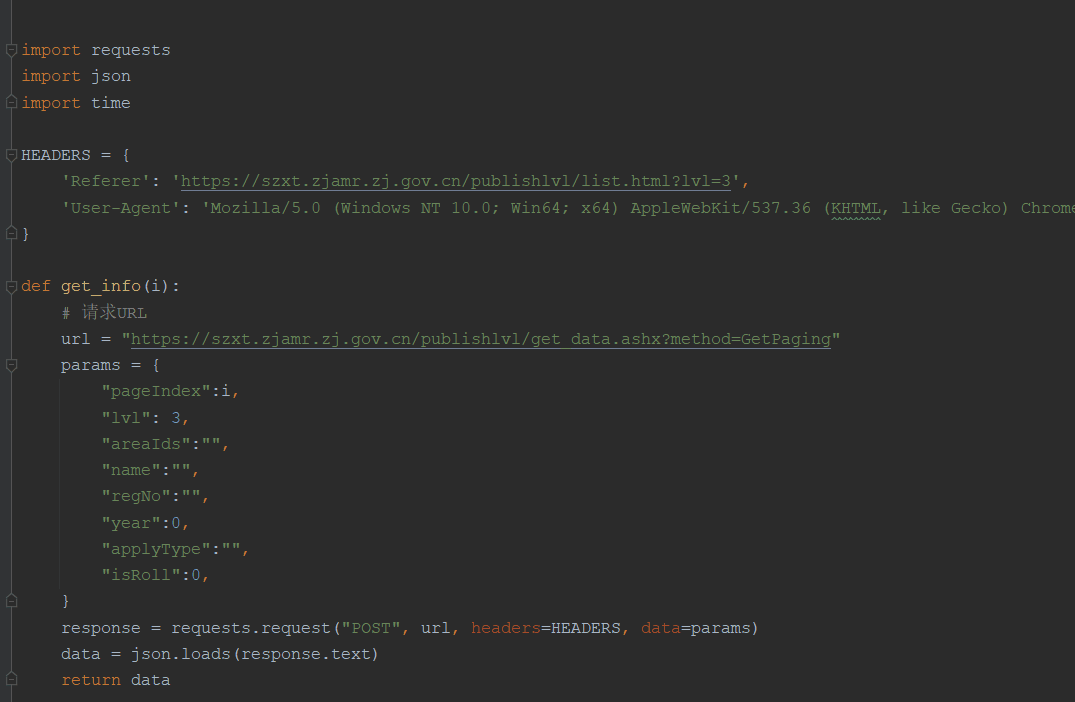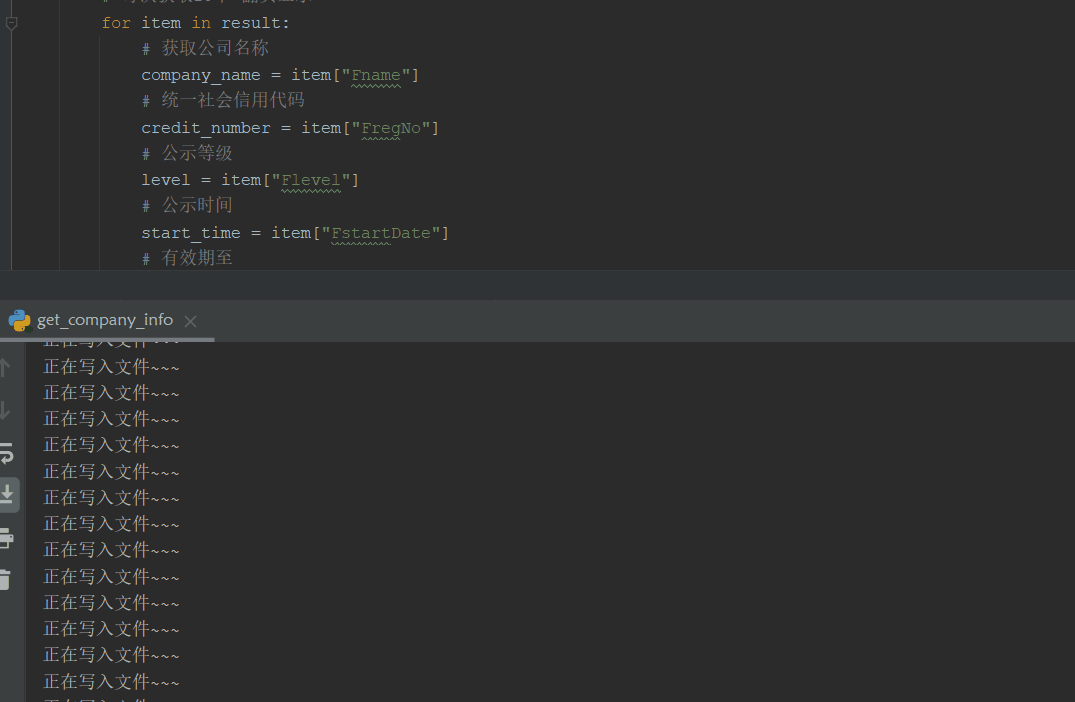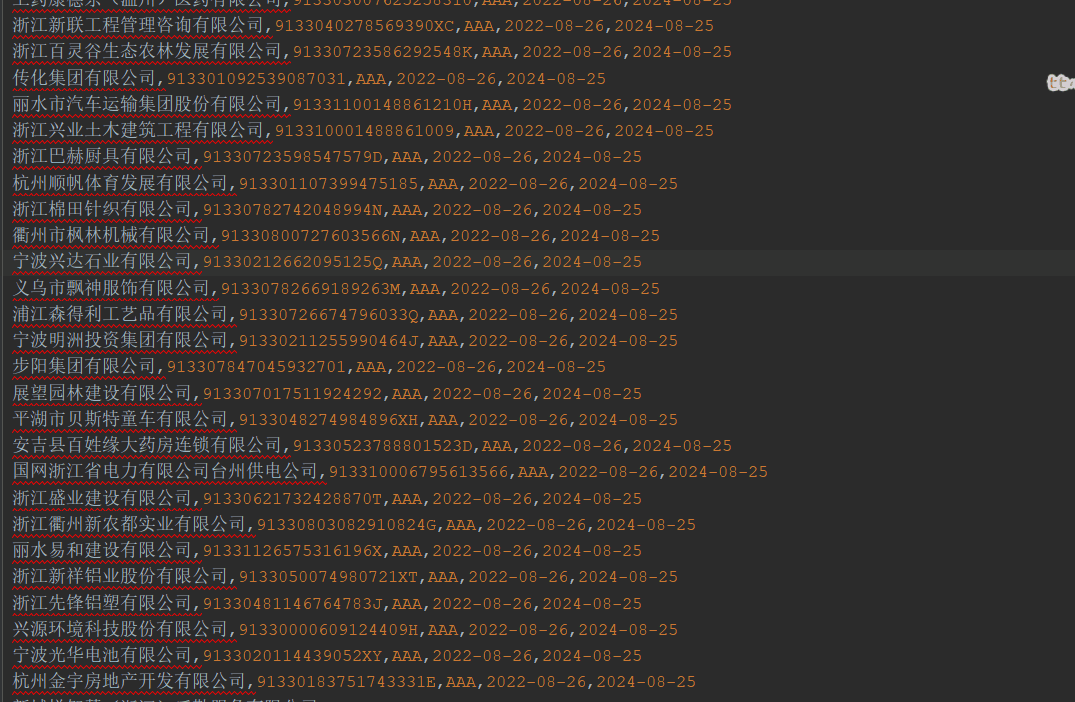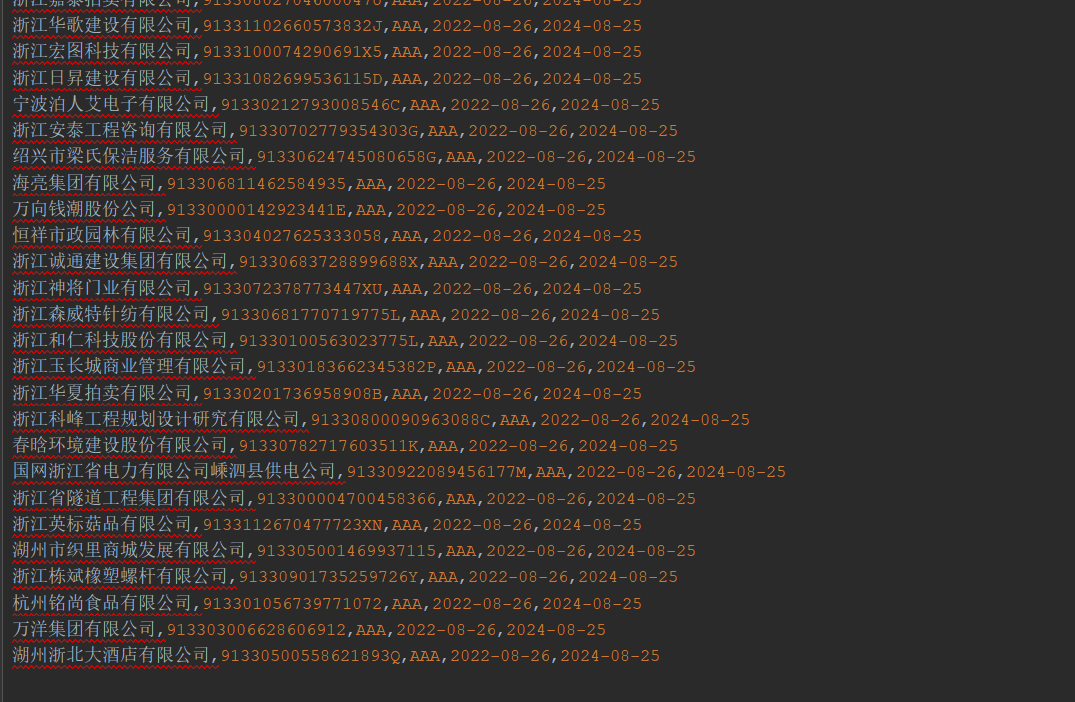
1. 请求URL,查看源代码
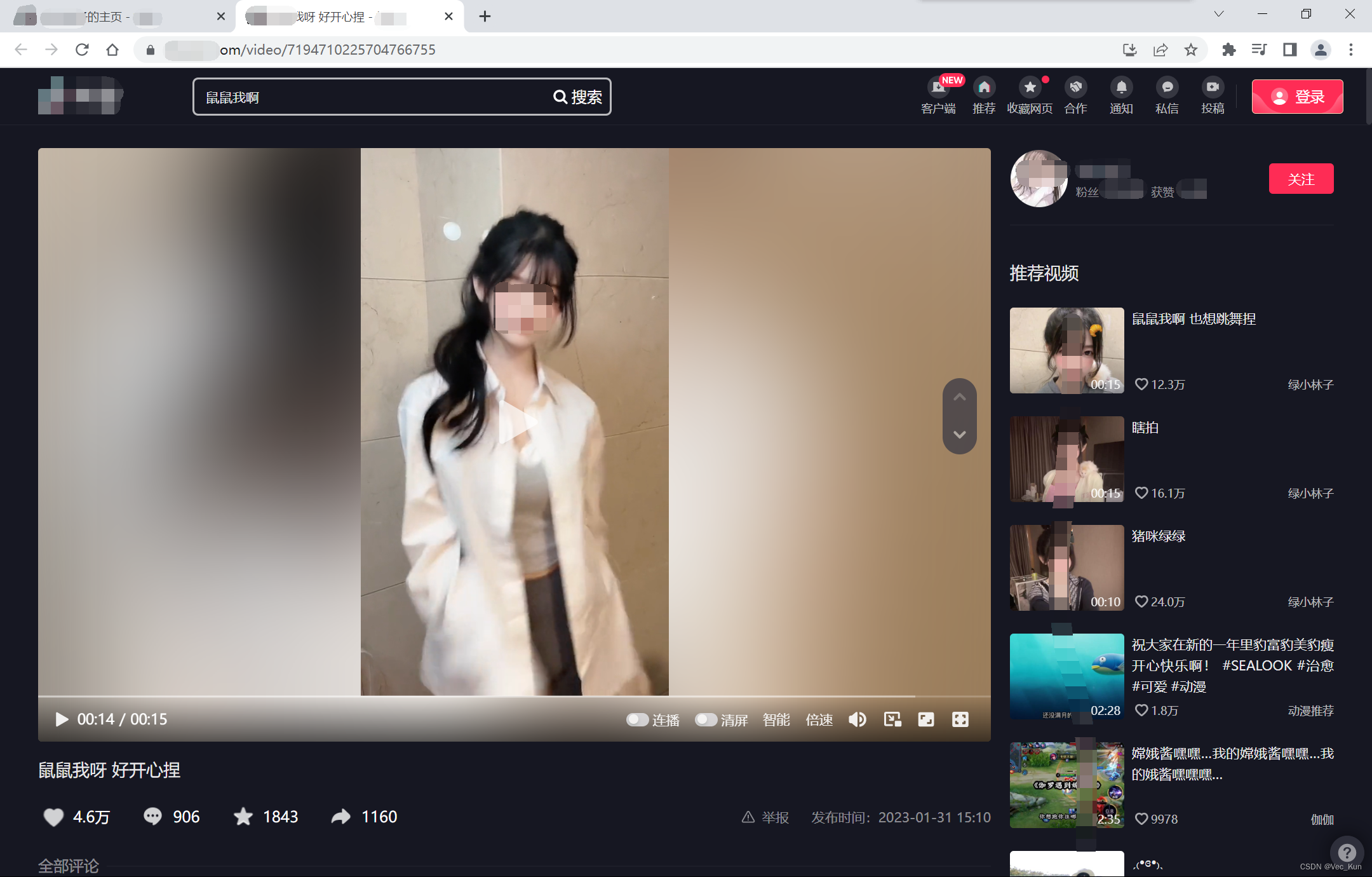
请求到主页,检查元素,看视频是否包含在源代码中,结果发现是没有的。
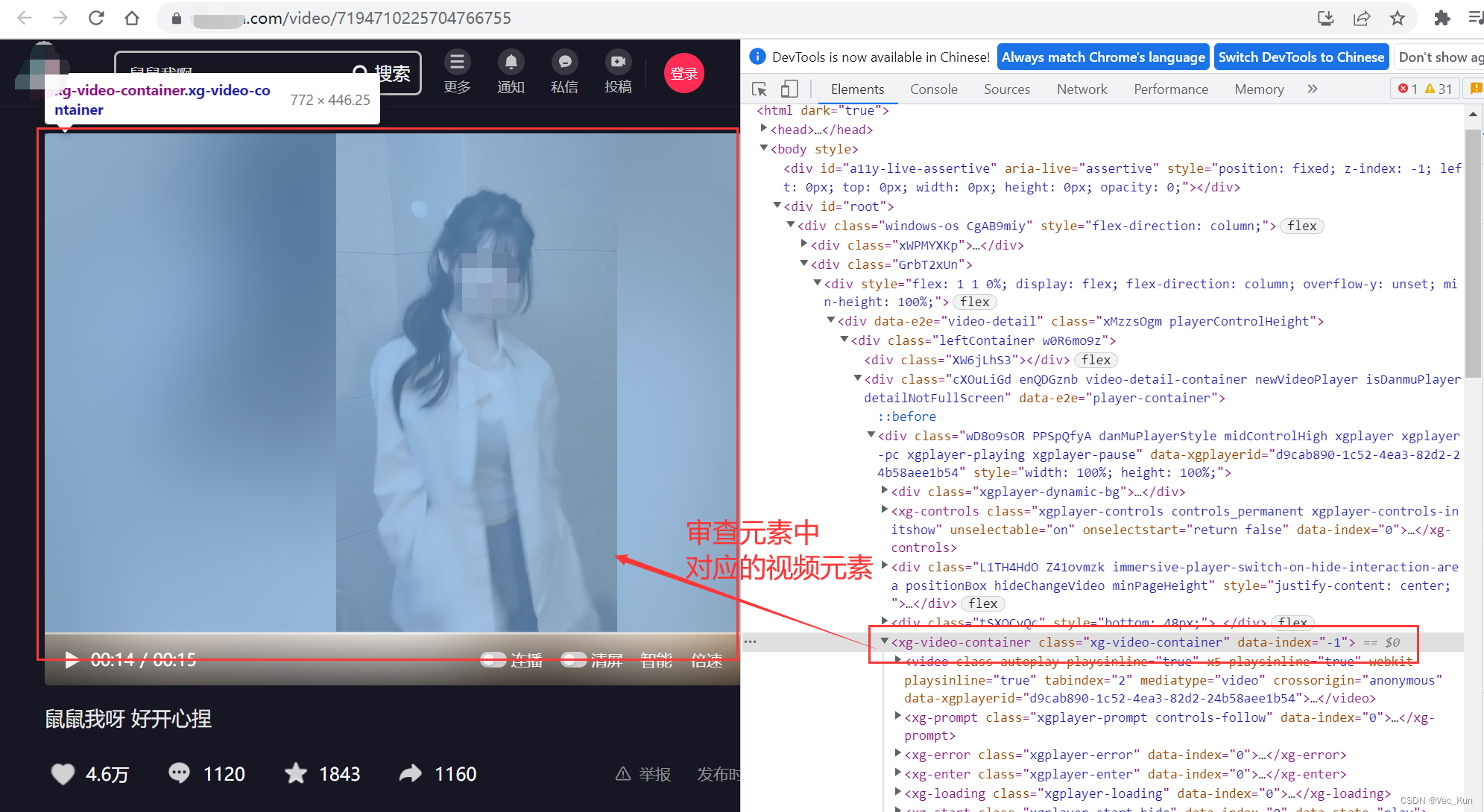
当然,请求URL也少不了必要的请求头,伪装请求头如下:
url = '见评论区'
headers = {
'cookie': 'douyin.com; __ac_nonce=063d749310021f8bd394b; __ac_signature=_02B4Z6wo00f01R8urHgAAIDBnyxWOmwmfMUfDqjAACQfd6; ttwid=1%7CtRZY98IpvYfhjM-VRDQHgX3mgPcfWwWxylxnwwC7fFk%7C0%7C9af2c384c7d2b4e10ec0497fce797af996c72dd3868ec040595de36132c01ad0; home_can_add_dy_2_desktop=%220%22; passport_csrf_token=ee0cbadbf97ac430daac207c46997ca1; passport_csrf_token_default=ee0cbadbf97ac430daac207c46997ca1; strategyABtestKey=%221675053365.079%22; s_v_web_id=verify_ldibiwgl_ycqaypzT_aJxd_4ZEW_9iGD_XkAPFGlhzwd3; AB_LOGIN_GUIDE_TIMESTAMP=%221675053363589%22; msToken=L3xfxnCP4kW9_qabjW3S1cud_5DmI99tIEOw1_lJDMgdp1GJ9KQd6HWXKepYY-7iLlj4SR_V02zL3lYO6FVnXoPPVNneC5bD9cEnYN4nNpXzaNmvq7oA; ttcid=a598309ef5f3442b95f1d979574083f925; tt_scid=Px0Q21O38QIdeziR7nBXUqfZYJaS4qKakt5Zkfio72r9U4XaJdOYTb37LsjIrRLQca96; msToken=xibNm7RgEpzX8c6UaAgkzAOHMr5TcWNmNbfFR1vD-3uNUhtRXEqVQrmPIV6iDsnsA3WhMCTIOGDtST_F9GEyq8In6Dj7ug-RXsQ6dWDIjzE3OXKr5dlj',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)其中最重要的就是Cookie和User-Agent
2. 源代码中没有就去抓包工具
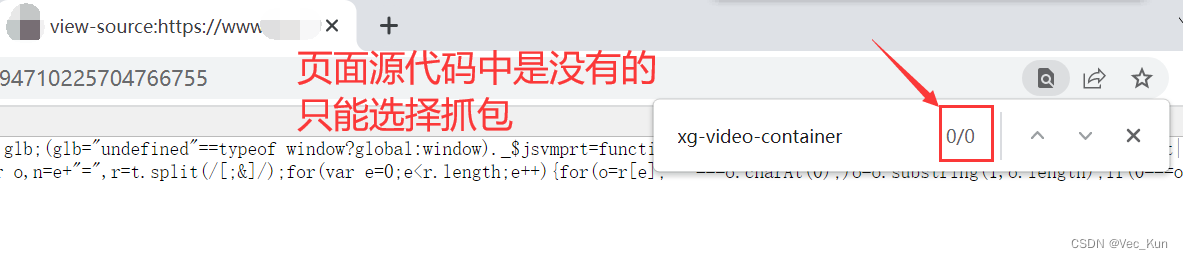
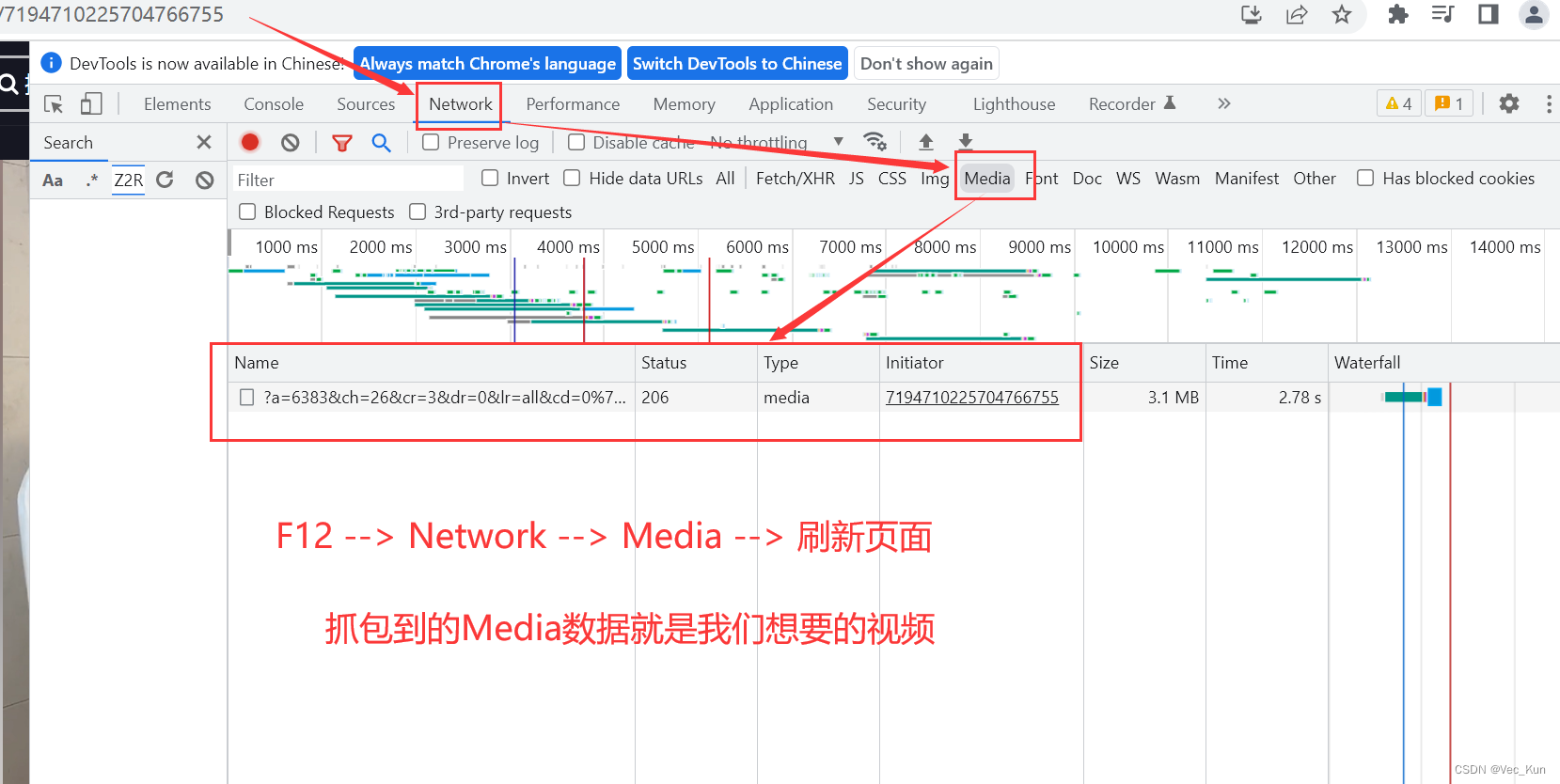
3. 拿到视频源链接,继续检索来源
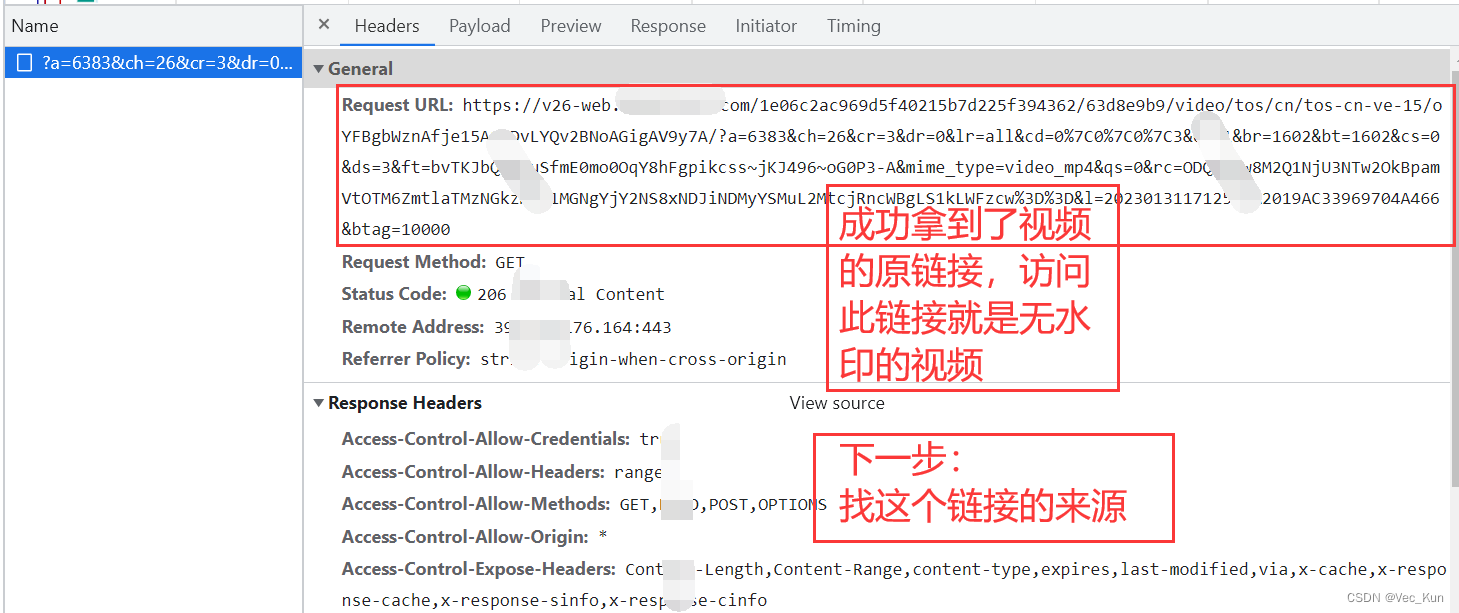
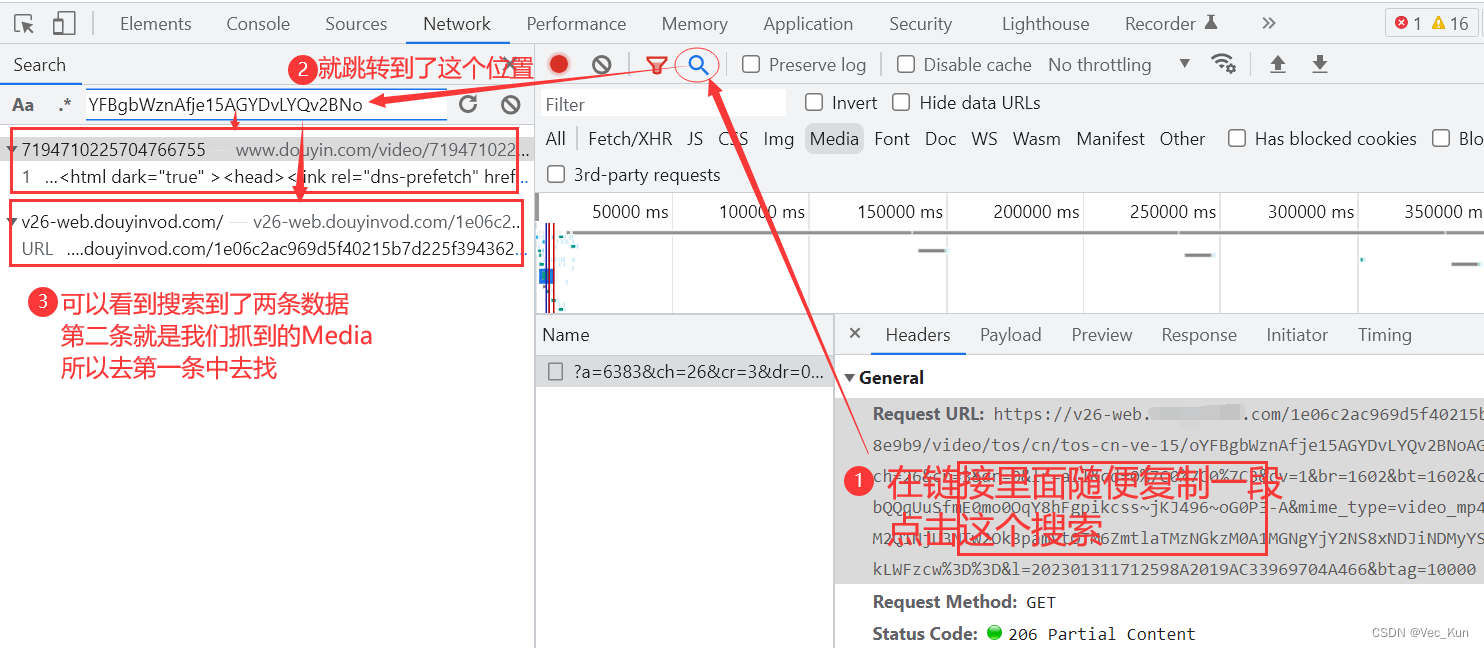
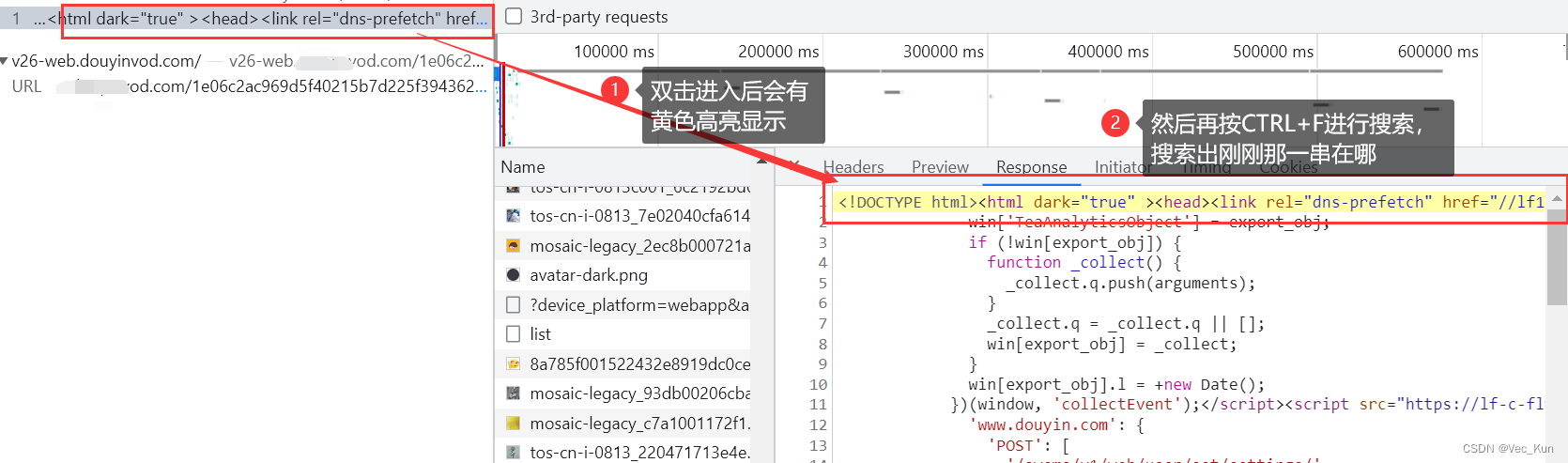
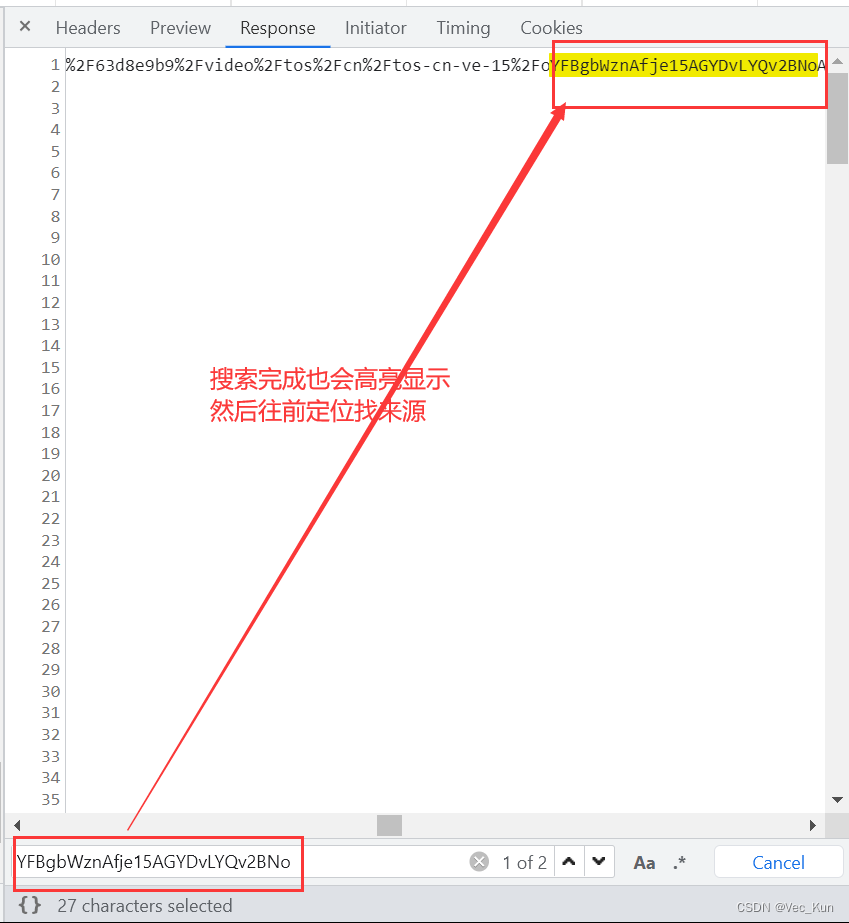
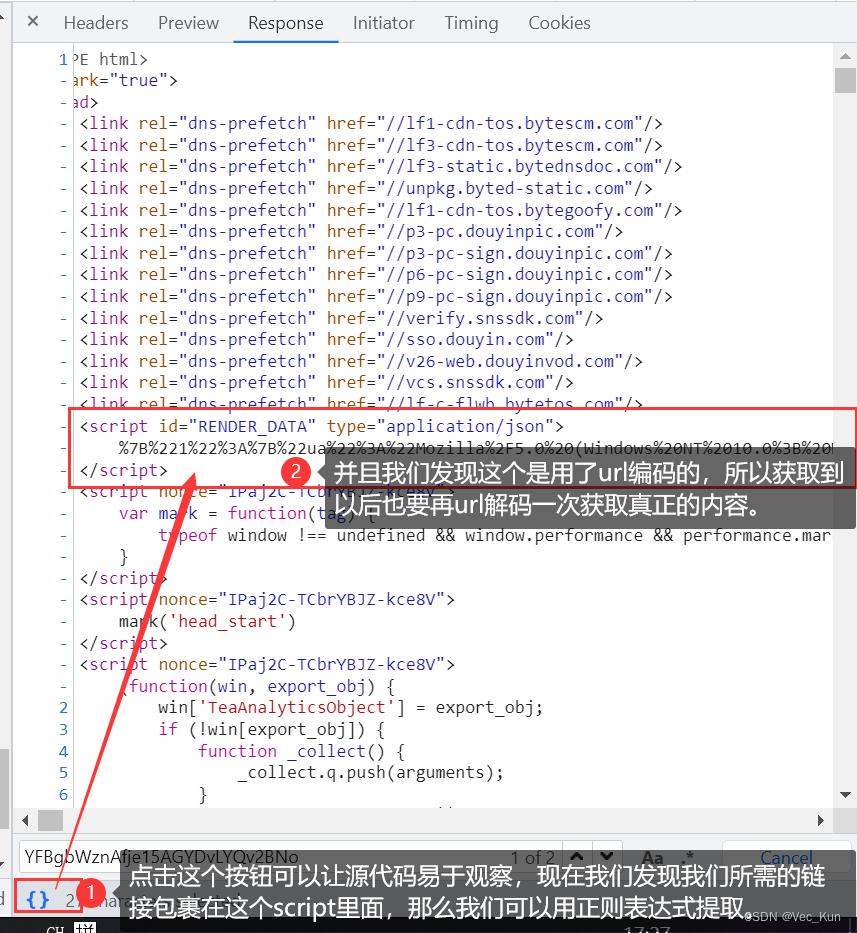
4. 拿到数据和链接,二进制写入到本地
下面可以用正则表达式获取视频标题作为一会保存到本地的文件名
还是用正则抓取刚刚script部分包裹的视频信息,url解码后用pprint将字典美观打印
发现有规律可循,一层一层扒开以后找到了视频url的精准位置
# 正则抓标题
obj = re.compile(r"<span><span><span><span>(?P<title>.*?)</span></span></span></span>", re.S)
title = obj.search(resp.text).group("title")
# print(title)
# 正则抓视频信息
info = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', resp.text)[0]
# print(info)
# url解码
html_data = urllib.parse.unquote(info)
html_data = json.loads(html_data)
# pprint(html_data) # 让字典更加美观
# 字典取值,拿视频播放链接
video_url = 'https:' + html_data['41']['aweme']['detail']['video']['bitRateList'][0]['playAddr'][0]['src']
print(video_url)最后就是最简单的保存视频
# 获取视频二进制数据
video_content = resp = requests.get(url=video_url, headers=headers).content
# 保存视频
if not os.path.exists('./4_video_without_watermark'):
os.mkdir('./4_video_without_watermark')
with open('./4_video_without_watermark/' + title + '.mp4', mode='wb') as f:
f.write(video_content)完整源码
import requests
import re
import json
import urllib
from urllib import parse
import os
from pprint import pprint
"""
常规找视频资源:到Network --> Media里面抓包,就能得到地址
然后在Media里面拿到地址,去全局搜索URL来源
"""
url = '见评论区'
headers = {
'cookie': 'douyin.com; __ac_nonce=063d749310021f8bd394b; __ac_signature=_02B4Z6wo00f01R8urHgAAIDBnyxWOmwmfMUfDqjAACQfd6; ttwid=1%7CtRZY98IpvYfhjM-VRDQHgX3mgPcfWwWxylxnwwC7fFk%7C0%7C9af2c384c7d2b4e10ec0497fce797af996c72dd3868ec040595de36132c01ad0; home_can_add_dy_2_desktop=%220%22; passport_csrf_token=ee0cbadbf97ac430daac207c46997ca1; passport_csrf_token_default=ee0cbadbf97ac430daac207c46997ca1; strategyABtestKey=%221675053365.079%22; s_v_web_id=verify_ldibiwgl_ycqaypzT_aJxd_4ZEW_9iGD_XkAPFGlhzwd3; AB_LOGIN_GUIDE_TIMESTAMP=%221675053363589%22; msToken=L3xfxnCP4kW9_qabjW3S1cud_5DmI99tIEOw1_lJDMgdp1GJ9KQd6HWXKepYY-7iLlj4SR_V02zL3lYO6FVnXoPPVNneC5bD9cEnYN4nNpXzaNmvq7oA; ttcid=a598309ef5f3442b95f1d979574083f925; tt_scid=Px0Q21O38QIdeziR7nBXUqfZYJaS4qKakt5Zkfio72r9U4XaJdOYTb37LsjIrRLQca96; msToken=xibNm7RgEpzX8c6UaAgkzAOHMr5TcWNmNbfFR1vD-3uNUhtRXEqVQrmPIV6iDsnsA3WhMCTIOGDtST_F9GEyq8In6Dj7ug-RXsQ6dWDIjzE3OXKr5dlj',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
# resp = urllib.parse.unquote(resp.text)
# print(resp.text)
# 正则抓标题
obj = re.compile(r"<span><span><span><span>(?P<title>.*?)</span></span></span></span>", re.S)
title = obj.search(resp.text).group("title")
# print(title)
# 正则抓视频信息
info = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', resp.text)[0]
# print(info)
# url解码
html_data = urllib.parse.unquote(info)
html_data = json.loads(html_data)
# pprint(html_data) # 让字典更加美观
# 字典取值,拿视频播放链接
video_url = 'https:' + html_data['41']['aweme']['detail']['video']['bitRateList'][0]['playAddr'][0]['src']
print(video_url)
# 获取视频二进制数据
video_content = resp = requests.get(url=video_url, headers=headers).content
# 保存视频
if not os.path.exists('./4_video_without_watermark'):
os.mkdir('./4_video_without_watermark')
with open('./4_video_without_watermark/' + title + '.mp4', mode='wb') as f:
f.write(video_content)
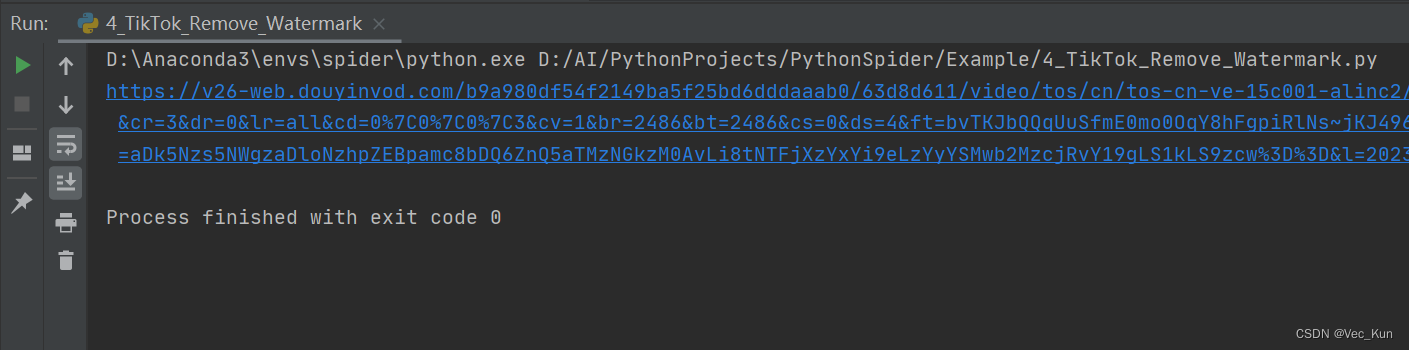
运行效果
运行后输出视频直链,并已经将视频保存到本地指定文件夹。

总结
本节实战了某短视频平台视频去水印的过程,较为综合,适合巩固爬虫基础知识。






![[NSSRound#7 Team]Web学习](https://img-blog.csdnimg.cn/2f598c448fff486b805bede0e0c9a325.png)